Untangling the Web From
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download Europe Pop
EUROPE LEGEND As built: March 2021. Maps are not to scale. Learn more about our network: teliacarrier.com Point of presence (PoP) Multiple PoPs Telia Carrier fiber Leased network OUR PoPs IN EUROPE Amsterdam Copenhagen Helsinki Milan Prague Tallinn Cessnalaan 50, Interxion 3000 Industriparken 20A, Interxion Iso-Roobertinkatu 21–25, Telia Via Caldera 21, Irideos Nad Elektrarnou 411, CECOLO Söle 14, Telia Johan Huizingalaan 759, Global Switch Horskaetten 3, Global Connect Kansakoulukuja 3, Telia 25 Viale Lombardia, Supernap Kuuse 4, Telia J.W Lucasweg 35, Iron Mountain Metrovej 1, Telia Kiviadankatu 2H, Nebula Via Monzoro 101–105, Data4 Riga 12 Koolhovenlaan, EdgeConnex Sydvestvej 100, Telia Parrukatu 2, Equinix Lielvardes Str. 8a, Telia Timisoara Kuiperbergweg 13, Equinix Sahamyllyntie 4b, Equinix Moscow Zakusalas krastmala 1, Riga TV Tower Calea Torontalului 94, Orange Luttenbergweg 4, Equinix Dresden Sinimäentie 12, Equinix Altufevskaya Shosse 33G, IXcellerate Schepenbergweg 42, Equinix Overbeckstr. 41a, Telia Valimotie 3–5, Telia Butlerova Str. 7, MMTS-9 JSC Rome Udomlya Science Park 120a, Digital Realty Oktyabrskaya Str. 1, Telia Via del Tizii, NAMEX CONSYST-Communication Provider Science Park 121, Interxion Dublin Kiev Viamotornaya Str. 69, DataPro Science Park 610, Equinix Kilcarbery Park, Equinix Gaydara Str. 50, New Telco Ukraine Rotterdam Valencia Science Park 105, NIKHEF Citywest Campus, Equinix Leontovicha Str. B. 9/3, Farlep-Invest Munich Van Nelleweg Rotterdam, 1, Smart DC Calle Villa de Madrid 44, Nixval Tupolevlaan 101, Interxion -

LES CHAÎNES TV by Dans Votre Offre Box Très Haut Débit Ou Box 4K De SFR
LES CHAÎNES TV BY Dans votre offre box Très Haut Débit ou box 4K de SFR TNT NATIONALE INFORMATION MUSIQUE EN LANGUE FRANÇAISE NOTRE SÉLÉCTION POUR VOUS TÉLÉ-ACHAT SPORT INFORMATION INTERNATIONALE MULTIPLEX SPORT & ÉCONOMIQUE EN VF CINÉMA ADULTE SÉRIES ET DIVERTISSEMENT DÉCOUVERTE & STYLE DE VIE RÉGIONALES ET LOCALES SERVICE JEUNESSE INFORMATION INTERNATIONALE CHAÎNES GÉNÉRALISTES NOUVELLE GÉNÉRATION MONDE 0 Mosaïque 34 SFR Sport 3 73 TV Breizh 1 TF1 35 SFR Sport 4K 74 TV5 Monde 2 France 2 36 SFR Sport 5 89 Canal info 3 France 3 37 BFM Sport 95 BFM TV 4 Canal+ en clair 38 BFM Paris 96 BFM Sport 5 France 5 39 Discovery Channel 97 BFM Business 6 M6 40 Discovery Science 98 BFM Paris 7 Arte 42 Discovery ID 99 CNews 8 C8 43 My Cuisine 100 LCI 9 W9 46 BFM Business 101 Franceinfo: 10 TMC 47 Euronews 102 LCP-AN 11 NT1 48 France 24 103 LCP- AN 24/24 12 NRJ12 49 i24 News 104 Public Senat 24/24 13 LCP-AN 50 13ème RUE 105 La chaîne météo 14 France 4 51 Syfy 110 SFR Sport 1 15 BFM TV 52 E! Entertainment 111 SFR Sport 2 16 CNews 53 Discovery ID 112 SFR Sport 3 17 CStar 55 My Cuisine 113 SFR Sport 4K 18 Gulli 56 MTV 114 SFR Sport 5 19 France Ô 57 MCM 115 beIN SPORTS 1 20 HD1 58 AB 1 116 beIN SPORTS 2 21 La chaîne L’Équipe 59 Série Club 117 beIN SPORTS 3 22 6ter 60 Game One 118 Canal+ Sport 23 Numéro 23 61 Game One +1 119 Equidia Live 24 RMC Découverte 62 Vivolta 120 Equidia Life 25 Chérie 25 63 J-One 121 OM TV 26 LCI 64 BET 122 OL TV 27 Franceinfo: 66 Netflix 123 Girondins TV 31 Altice Studio 70 Paris Première 124 Motorsport TV 32 SFR Sport 1 71 Téva 125 AB Moteurs 33 SFR Sport 2 72 RTL 9 126 Golf Channel 127 La chaîne L’Équipe 190 Luxe TV 264 TRACE TOCA 129 BFM Sport 191 Fashion TV 265 TRACE TROPICAL 130 Trace Sport Stars 192 Men’s Up 266 TRACE GOSPEL 139 Barker SFR Play VOD illim. -

Annex 8 Compulsory Licensing of Premium Pay Tv
ANNEX 8 COMPULSORY LICENSING OF PREMIUM PAY TV CHANNELS IN OTHER COUNTRIES 1. Introduction 1.1 Ofcom has sought to portray its proposals to compel Sky to license its premium pay TV channels to other operators as relatively uncontroversial on a number of grounds including that the proposals are a ‘normal’ form of regulation in other countries. For example, Ofcom has stated: “wholesale must-offer obligations have been imposed in a number of other countries, in response to similar concerns to those that we have set out”;1 and “This is not a revolutionary approach… this kind of wholesale must offer has existed in the States for years.”2 1.2 Ofcom’s views on this matter appear impressionistic, rather than being based on a thorough understanding of (a) the nature of compulsory licensing obligations in other countries; or (b) the reasons for those obligations.3 A proper understanding of such matters is required in order to rely on the existence of regulation in other countries as lending support to Ofcom’s own proposals to impose wide-ranging, deterministic and highly intrusive regulation on Sky. 1.3 In this Annex, Sky considers the compulsory licensing obligations that exist in relation to pay TV channels in the countries cited by Ofcom as relevant comparators, namely France, Italy, Spain and the United States.4 We show that the regulation that exists in those countries has little in common either in form or rationale with that which Ofcom proposes. In particular, in spite of the fact that obligations were introduced in France, Italy and Spain in order to remedy demonstrable reductions in competition arising from mergers between pay TV operators, Ofcom’s proposals go far beyond the remedies that were adopted in those countries. -

Numericable / SFR 750 Undrawn RCF at Altice VII 100
“The Future Begins Today” Creating the French Champion in Very High Speed Fixed – Mobile Convergence 7 April 2014 Disclaimer ■ This presentation contains statements about future events, projections, forecasts and expectations that are forward-looking statements. Any statement in this presentation that is not a statement of historical fact is a forward-looking statement that involves known and unknown risks, uncertainties and other factors which may cause our actual results, performance or achievements to be materially different from any future results, performance or achievements expressed or implied by such forward-looking statements. These risk and uncertainties include those discussed or identified in the Document de Base of Numericable Group filed with the Autorité des Marchés Financiers ("AMF") under number I.13-043 on September 18, 2013 and its Actualisation filed with the AMF under number D.13-0888-A01 on October 25, 2013. In addition, past performance of Numericable Group cannot be relied on as a guide to future performance. Numericable Group makes no representation on the accuracy and completeness of any of the forward-looking statements, and, except as may be required by applicable law, assumes no obligations to supplement, amend, update or revise any such statements or any opinion expressed to reflect actual results, changes in assumptions or in Numericable Group's expectations, or changes in factors affecting these statements. Accordingly, any reliance you place on such forward-looking statements will be at your sole risk. ■ This presentation does not contain or constitute an offer of Numericable Group's or Altice's shares for sale or an invitation or inducement to invest in Numericable Group's or Altice's shares in France, the United States of America or any other jurisdiction. -

THE E-HEALTH OPPORTUNITY for the TELECOMMUNICATION INDUSTRY and PORTUGAL TELECOM – a CASE STUDY Cover
THE E-HEALTH OPPORTUNITY FOR THE TELECOMMUNICATION INDUSTRY AND PORTUGAL TELECOM – A CASE STUDY Cover Francisco Borges d’Almeida Nascimento Master of Science in Business Administration Orientador: Prof. Jorge Lengler, ISCTE Business School, Departamento de Marketing, Operações e Gestão Geral April 2015 THE E-HEALTH OPPORTUNITY FOR THE TELECOMMUNICATION INDUSTRY AND PORTUGAL TELECOM – A CASE STUDY Francisco Borges d’Almeida Nascimento Case Study – E-Health in the telecommunication industry and at PT Abstract Electronic-Health (e-health) is a recent answer to some pressing challenges on health. Aging of western societies and treatments’ rising costs raised doubts about health systems’ sustainability. Individuals, companies and public administration alike are looking for technology to find aid in addressing these challenges. Several industries are tacking those issues offering innovative solutions among which Telecommunication’s. Nonetheless, this industry is facing challenges from over- the-top players menacing its business model. Portugal Telecom shares these challenges and is looking to diversify to guarantee future growth, namely, by developing in e-health solutions. This case study follows two important threads in strategy literature: diversification and the resource-based view, applied Portugal Telecom and the e-health opportunity. As a case study, it aims providing readers a tool to better understand and employ strategic management concepts and frameworks in an applied business context. E-health as an opportunity for growth to Telecommunication companies and Portugal Telecom is described from three points of view: i) an actual market need ii) that may be addressed by Telecommunication companies and iii) should be addressed by those companies as they need to grow. -
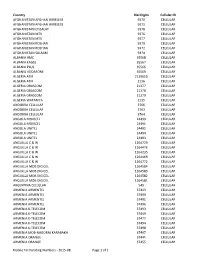
Mobile Terminating Numbers
Country Dial Digits Cellular ID AFGHANISTAN AFGHAN WIRELESS 9370 CELLULAR AFGHANISTAN AFGHAN WIRELESS 9371 CELLULAR AFGHANISTAN ETISALAT 9378 CELLULAR AFGHANISTAN MTN 9376 CELLULAR AFGHANISTAN MTN 9377 CELLULAR AFGHANISTAN ROSHAN 9379 CELLULAR AFGHANISTAN ROSHAN 9372 CELLULAR AFGHANISTAN SALAAM 9374 CELLULAR ALBANIA AMC 35568 CELLULAR ALBANIA EAGLE 35567 CELLULAR ALBANIA PLUS 35566 CELLULAR ALBANIA VODAFONE 35569 CELLULAR ALGERIA ATM 2139619 CELLULAR ALGERIA ATM 2136 CELLULAR ALGERIA ORASCOM 21377 CELLULAR ALGERIA ORASCOM 21378 CELLULAR ALGERIA ORASCOM 21379 CELLULAR ALGERIA WATANIYA 2135 CELLULAR ANDORRA CELLULAR 3766 CELLULAR ANDORRA CELLULAR 3763 CELLULAR ANDORRA CELLULAR 3764 CELLULAR ANGOLA MOVICEL 24499 CELLULAR ANGOLA MOVICEL 24491 CELLULAR ANGOLA UNITEL 24492 CELLULAR ANGOLA UNITEL 24494 CELLULAR ANGOLA UNITEL 24493 CELLULAR ANGUILLA C & W 1264729 CELLULAR ANGUILLA C & W 1264476 CELLULAR ANGUILLA C & W 1264235 CELLULAR ANGUILLA C & W 1264469 CELLULAR ANGUILLA C & W 1264772 CELLULAR ANGUILLA MOB DIGICEL 1264584 CELLULAR ANGUILLA MOB DIGICEL 1264583 CELLULAR ANGUILLA MOB DIGICEL 1264582 CELLULAR ANGUILLA MOB DIGICEL 1264581 CELLULAR ARGENTINA CELLULAR 549 CELLULAR ARMENIA ARMENTEL 37443 CELLULAR ARMENIA ARMENTEL 37499 CELLULAR ARMENIA ARMENTEL 37491 CELLULAR ARMENIA ARMENTEL 37496 CELLULAR ARMENIA K-TELECOM 37493 CELLULAR ARMENIA K-TELECOM 37449 CELLULAR ARMENIA K-TELECOM 37477 CELLULAR ARMENIA K-TELECOM 37494 CELLULAR ARMENIA K-TELECOM 37498 CELLULAR ARMENIA MOB-NAGORNI KARABAKH 37497 CELLULAR ARMENIA ORANGE 37441 CELLULAR ARMENIA -

Mobile Broadband: Pricing and Services”, OECD Digital Economy Papers, No
Please cite this paper as: Otsuka, Y. (2009-06-30), “Mobile Broadband: Pricing and Services”, OECD Digital Economy Papers, No. 161, OECD Publishing, Paris. http://dx.doi.org/10.1787/222123470032 OECD Digital Economy Papers No. 161 Mobile Broadband PRICING AND SERVICES Yasuhiro Otsuka Unclassified DSTI/ICCP/CISP(2008)6/FINAL Organisation de Coopération et de Développement Économiques Organisation for Economic Co-operation and Development 30-Jun-2009 ___________________________________________________________________________________________ English - Or. English DIRECTORATE FOR SCIENCE, TECHNOLOGY AND INDUSTRY COMMITTEE FOR INFORMATION, COMPUTER AND COMMUNICATIONS POLICY Unclassified DSTI/ICCP/CISP(2008)6/FINAL Working Party on Communication Infrastructures and Services Policy MOBILE BROADBAND: PRICING AND SERVICES English - Or. English JT03267481 Document complet disponible sur OLIS dans son format d'origine Complete document available on OLIS in its original format DSTI/ICCP/CISP(2008)6/FINAL FOREWORD This paper was presented to the Working Party on Communication Infrastructures and Services Policy in December 2008. The Working Party agreed to recommend the declassification of the document to the ICCP Committee. The ICCP Committee agreed to declassify the document at its meeting in March 2009. The paper was prepared by Mr. Yasuhiro Otsuka of the OECD’s Directorate for Science, Technology and Industry. It is published under the responsibility of the Secretary-General of the OECD. © OECD/OCDE 2009. 2 DSTI/ICCP/CISP(2008)6/FINAL TABLE OF -

Volte Launches
VoLTE Launches Country Operator VoLTE Status VoLTE Launched Egypt Misr VoLTE Launched 01-Nov-18 United States of America Sprint (SoftBank) VoLTE Launched 07-Oct-18 Egypt Etisalat VoLTE Launched 25-Sep-18 South Africa MTN VoLTE Launched 13-Sep-18 Lebanon Alfa (OTMT) VoLTE Launched 12-Sep-18 Freedom Mobile (Shaw VoLTE Launched Canada Communications) 12-Aug-18 Bulgaria VIVACOM VoLTE Launched 07-Aug-18 Bulgaria Telenor (PPF) VoLTE Launched 31-Jul-18 Luxembourg Tango (Proximus) VoLTE Launched 22-Jul-18 Austria 3 (CK Hutchison) VoLTE Launched 10-Jul-18 Chile Movistar (Telefonica) VoLTE Launched 24-Jun-18 Russian Federation MTS (Sistema) VoLTE Launched 20-Jun-18 Belgium Orange VoLTE Launched 10-Jun-18 Austria T-Mobile (Deutsche Telekom) VoLTE Launched 23-May-18 Poland Play (P4) VoLTE Launched 20-May-18 Georgia MagtiCom VoLTE Launched 01-May-18 Ecuador Movistar (Telefonica) VoLTE Launched 10-Apr-18 Bahamas ALIV VoLTE Launched 31-Mar-18 India Vodafone Idea VoLTE Launched 28-Feb-18 IDC (Interdnestrkom), VoLTE Launched Moldova Transnistria 22-Dec-17 Luxembourg POST Luxembourg VoLTE Launched 13-Dec-17 Kenya Faiba (Jamii Telecom) VoLTE Launched 06-Dec-17 Armenia Ucom VoLTE Launched 04-Dec-17 Swaziland Swazi Mobile VoLTE Launched 15-Nov-17 Canada Videotron (Quebecor Media) VoLTE Launched 01-Nov-17 Bahrain Viva (STC) VoLTE Launched 22-Oct-17 Romania Digi Mobil (RCS & RDS) VoLTE Launched 19-Oct-17 Iran MTN Irancell VoLTE Launched 14-Oct-17 Iceland Nova VoLTE Launched 09-Oct-17 Mexico Telcel (America Movil) VoLTE Launched 29-Sep-17 India Airtel (Bharti -

Présentation Powerpoint
VIVENDI – A p r i l 2 0 1 4 April 7, 2014 HERVE PHILIPPE Chief Financial Officer Vivendi selects the Altice/Numericable offer for SFR IMPORTANT NOTICE: Investors are strongly urged to read the important disclaimers at the end of this presentation VIVENDI – A p r i l 2 0 1 4 VALUE REALIZATION EXCEEDING €17 BILLION FOR SFR Vivendi to sell SFR to Altice/Numericable, representing a total value in excess of €17 billion for 100% of SFR ― Vivendi to receive €13.5 billion in cash at closing ― Vivendi could potentially receive a €750 million earn-out payment based on the achievement of EBITDA – Capex objective Opportunity to participate in future upside ― Vivendi to retain a 20% stake in SFR-Numericable with clear governance and liquidity rights Closing of the transaction expected by end 2014 A significant step in Vivendi’s strategy to focus on media and content Strengthened financial position allowing enhanced value creation 2 VIVENDI – A p r i l 2 0 1 4 VIVENDI IS DELIVERING THE BEST DEAL FOR SFR On February 24, 2014, Vivendi received an approach from Altice regarding a potential combination between SFR and Numericable Formal expressions of interest on SFR received from Altice/Numericable and Bouygues on March 5, as Vivendi was still pursuing its project of demerging SFR Offers thoroughly reviewed by Vivendi’s Management and Supervisory Board ― Special Committee established by the Supervisory Board, under chairmanship of Mr. Lachmann, to review over eight working sessions options available to Vivendi On March 14, decision by Vivendi’s -

Countries Where Internet Packs Are Available
Countries where Internet packs are available Country Carrier Postpaid Prepaid Display name Telecom Albania AMC AL; AMC Mobile; AL 01; 276 Albania + + (AMC) 01 Albania Vodafone + + VODAFONE AL; AL-02; 276-02 Australia Vodafone + + Vodafone AU; 4G Austria H3G (Orange, Drei) + + One; 232-05; Orange A Austria A1 (Mobilkom) + + A1 Belarus LIFE:) (Best) + + life:) BY; BeST; BeST BY Belarus Mobilkom (Velcom) + + A1; 257 01 Belarus MTS + + 257 02; BY 02; MTS BY Belgium Base (KPN) + + BASE; Bel 20; 206-20 Bulgaria A1 (Mobilkom) (Mtel) + + Mtel; 284 01 Canada Rogers + + Rogers; 302 72; CAN72 China China Mobile + + CMCC; China Mobile UNICOM; China Unicom; CHN China China Unicom + + CUGSM; CUGSM; 460 01 Congo Vodacom (ICE) + + VodaCom T-Mobile (Hrvatske Croatia + + 219 01; HT HR; T-Mobile Telekomunikacije) Croatia A1 (Mobilkom) (VIP) + + A1 HR; HR 10; 219 10 Czech Republic Vodafone + + Vodafone CZ; CZ-03; 230 03 Denmark Telia Danmark Mobile + + TELIA DK Estonia Telia (EMT) + + EE EMT; 248 01 Finland ELISA (Radiolinja) + + FI elisa Finland Telia (SONERA) + + Telia FI France SFR + + F SFR Georgia Geocell + + Geocell; Geo-Geocell; 282 01 Georgia Magticom + + MagtiCom; 28202 Call Center For postpaid subscribers: For prepaid subscribers: | (+99450) 6565000 | (+99450) 2002111 Countries where Internet packs are available Country Carrier Postpaid Prepaid Display name Veon Georgia (Mo- Georgia + + Beeline GE; GEO 04 bitel,Beeline) T-D1; D1; T-Mobile D;telekom.de; Germany T-Mobile + + D1-Telekom Germany Vodafone (D2 GmbH) + + Vodafone.de; Vodafone GH Vodafone; -

Global Pay TV Revenues Down, Subscriptions Up
Global pay TV revenues down, subscriptions up Global pay TV revenues peaked in 2016 at $202 billion. Revenues will fall to $152 billion in 2025. This is lower than 2010’s $175 billion - despite the number of pay TV subscribers rising by 345 million between 2010 and 2025. Revenues fell by $9 billion in both 2018 and 2019. Pay TV revenues by top countries ($ million) 200,000 180,000 160,000 140,000 120,000 100,000 80,000 60,000 40,000 20,000 0 2019 2020 2025 Others 70,158 70,835 69,559 Canada 5,990 5,698 5,130 UK 6,637 6,349 5,780 India 5,168 5,415 5,995 China 9,537 9,379 9,348 USA 88,512 79,241 56,019 Source: Digital TV Research Ltd The top five countries will account for 54% of global pay TV revenues by 2025; down from 62% in 2019. The US will lose $23 billion between 2019 and 2025. US pay TV revenues peaked in 2015, at $105 billion, but will drop to $56 billion in 2025. The UK and Canada will each lose nearly $1 billion – but India will add $0.8 billion. Despite poor results in some countries, there is still plenty of life left in pay TV. Digital TV Research forecasts 34 million additional pay TV subscribers between 2019 and 2025. This takes the global total to 1.06 billion. The number of pay TV subscribers passed 1 billion in 2018. China will continue to supply a third of the world’s pay TV subscribers, with 328 million expected by end-2025. -

Offres Mobiles Tarifs Depuis L'international
OFFRES MOBILES TARIFS DEPUIS L'INTERNATIONAL 8 TARIFS DEPUIS L'INTERNATIONAL En fonction de votre offre, vous avez la possibilité d'appeler ou d'envoyer des SMS à travers le monde grâce au Roaming. A noter : Vous devez être équipés d’une carte DUAL SIM que vous pouvez récupérer en boutique SFR. Cette carte SIM est marquée d’un point rouge. Si vous avez une ancienne carte SIM, n’hésitez pas à changer votre carte en vous rapprochant de vos Espaces SFR. Pour vérifier la version de 10votre 20carte SIM, appelez gratuitement votre Service Client au : 10 97 LE ROAMING0 POUR 805 510 LES 510 FORFAITS ET LES COMPTES BLOQUÉS976 COMBIEN COÛTENT TaillesLES minimum APPELS : ÉMIS DEPUIS L'EUROPE ? 0 801 123 456 0 801 123 456 OCEAN INDIEN OCEAN INDIEN RESTE DU VERS ZONE EUROPE0 801 123 456 0 801 123 456 ZONE 1 ZONE 2 MONDE 0 801 123 456 0 801 123 456 Compte bloqué INITIAL 4G Compte bloqué NRJ STYLÉ 2€/min 0,99€/min 2,50€/min Communications incluses (facturé hors (facturé hors (facturé hors Forfait SÉRÉNITÉ 4G dans le forfait** forfait*) forfait*) forfait*) OFFRES Forfait INTENSE 4G GRAND PUBLIC Forfait ABSOLU 4G Forfait EXCELLENCE 4G FIRST Appels décomptés de votre forfait au tarif local, ESSENTIEL 4G puis hors forfait 2€/min 0,99€/min 2,50€/min ESSENTIEL+ 4G (facturé hors (facturé hors (facturé hors forfait*) forfait*) forfait*) OFFRES Communications incluses POWER+ 4G dans le forfait** SFR BUSINESS PREMIUM 4G COMBIEN COÛTENT LES APPELS ÉMIS DEPUIS L'OCEAN INDIEN & LE RESTE DU MONDE ? Vers J’appelle dans le pays visité Zone Europe Zone Reste du Monde Depuis Océan Indien - Zone 1 0,49€/min 0,99€/min 2,50€/min Océan Indien - Zone 2 0,65€/min 2,00€/min 2,50€/min Zone reste du Monde 2,50€/min 2,50€/min 2,50€/min La facturation de ces tarifs se fait à la seconde après un premier palier de 30 secondes.