Aword-Based Genetic Algorithm for Cryptanalysis of Short Cryptograms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Classical Encryption Techniques
CPE 542: CRYPTOGRAPHY & NETWORK SECURITY Chapter 2: Classical Encryption Techniques Dr. Lo’ai Tawalbeh Computer Engineering Department Jordan University of Science and Technology Jordan Dr. Lo’ai Tawalbeh Fall 2005 Introduction Basic Terminology • plaintext - the original message • ciphertext - the coded message • key - information used in encryption/decryption, and known only to sender/receiver • encipher (encrypt) - converting plaintext to ciphertext using key • decipher (decrypt) - recovering ciphertext from plaintext using key • cryptography - study of encryption principles/methods/designs • cryptanalysis (code breaking) - the study of principles/ methods of deciphering ciphertext Dr. Lo’ai Tawalbeh Fall 2005 1 Cryptographic Systems Cryptographic Systems are categorized according to: 1. The operation used in transferring plaintext to ciphertext: • Substitution: each element in the plaintext is mapped into another element • Transposition: the elements in the plaintext are re-arranged. 2. The number of keys used: • Symmetric (private- key) : both the sender and receiver use the same key • Asymmetric (public-key) : sender and receiver use different key 3. The way the plaintext is processed : • Block cipher : inputs are processed one block at a time, producing a corresponding output block. • Stream cipher: inputs are processed continuously, producing one element at a time (bit, Dr. Lo’ai Tawalbeh Fall 2005 Cryptographic Systems Symmetric Encryption Model Dr. Lo’ai Tawalbeh Fall 2005 2 Cryptographic Systems Requirements • two requirements for secure use of symmetric encryption: 1. a strong encryption algorithm 2. a secret key known only to sender / receiver •Y = Ek(X), where X: the plaintext, Y: the ciphertext •X = Dk(Y) • assume encryption algorithm is known •implies a secure channel to distribute key Dr. -

Index-Of-Coincidence.Pdf
The Index of Coincidence William F. Friedman in the 1930s developed the index of coincidence. For a given text X, where X is the sequence of letters x1x2…xn, the index of coincidence IC(X) is defined to be the probability that two randomly selected letters in the ciphertext represent, the same plaintext symbol. For a given ciphertext of length n, let n0, n1, …, n25 be the respective letter counts of A, B, C, . , Z in the ciphertext. Then, the index of coincidence can be computed as 25 ni (ni −1) IC = ∑ i=0 n(n −1) We can also calculate this index for any language source. For some source of letters, let p be the probability of occurrence of the letter a, p be the probability of occurrence of a € b the letter b, and so on. Then the index of coincidence for this source is 25 2 Isource = pa pa + pb pb +…+ pz pz = ∑ pi i=0 We can interpret the index of coincidence as the probability of randomly selecting two identical letters from the source. To see why the index of coincidence gives us useful information, first€ note that the empirical probability of randomly selecting two identical letters from a large English plaintext is approximately 0.065. This implies that an (English) ciphertext having an index of coincidence I of approximately 0.065 is probably associated with a mono-alphabetic substitution cipher, since this statistic will not change if the letters are simply relabeled (which is the effect of encrypting with a simple substitution). The longer and more random a Vigenere cipher keyword is, the more evenly the letters are distributed throughout the ciphertext. -

Automating the Development of Chosen Ciphertext Attacks
Automating the Development of Chosen Ciphertext Attacks Gabrielle Beck∗ Maximilian Zinkus∗ Matthew Green Johns Hopkins University Johns Hopkins University Johns Hopkins University [email protected] [email protected] [email protected] Abstract In this work we consider a specific class of vulner- ability: the continued use of unauthenticated symmet- In this work we investigate the problem of automating the ric encryption in many cryptographic systems. While development of adaptive chosen ciphertext attacks on sys- the research community has long noted the threat of tems that contain vulnerable format oracles. Unlike pre- adaptive-chosen ciphertext attacks on malleable en- vious attempts, which simply automate the execution of cryption schemes [17, 18, 56], these concerns gained known attacks, we consider a more challenging problem: practical salience with the discovery of padding ora- to programmatically derive a novel attack strategy, given cle attacks on a number of standard encryption pro- only a machine-readable description of the plaintext veri- tocols [6,7, 13, 22, 30, 40, 51, 52, 73]. Despite repeated fication function and the malleability characteristics of warnings to industry, variants of these attacks continue to the encryption scheme. We present a new set of algo- plague modern systems, including TLS 1.2’s CBC-mode rithms that use SAT and SMT solvers to reason deeply ciphersuite [5,7, 48] and hardware key management to- over the design of the system, producing an automated kens [10, 13]. A generalized variant, the format oracle attack strategy that can entirely decrypt protected mes- attack can be constructed when a decryption oracle leaks sages. -
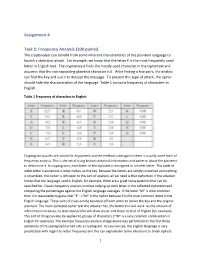
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language. -

Chap 2. Basic Encryption and Decryption
Chap 2. Basic Encryption and Decryption H. Lee Kwang Department of Electrical Engineering & Computer Science, KAIST Objectives • Concepts of encryption • Cryptanalysis: how encryption systems are “broken” 2.1 Terminology and Background • Notations – S: sender – R: receiver – T: transmission medium – O: outsider, interceptor, intruder, attacker, or, adversary • S wants to send a message to R – S entrusts the message to T who will deliver it to R – Possible actions of O • block(interrupt), intercept, modify, fabricate • Chapter 1 2.1.1 Terminology • Encryption and Decryption – encryption: a process of encoding a message so that its meaning is not obvious – decryption: the reverse process • encode(encipher) vs. decode(decipher) – encoding: the process of translating entire words or phrases to other words or phrases – enciphering: translating letters or symbols individually – encryption: the group term that covers both encoding and enciphering 2.1.1 Terminology • Plaintext vs. Ciphertext – P(plaintext): the original form of a message – C(ciphertext): the encrypted form • Basic operations – plaintext to ciphertext: encryption: C = E(P) – ciphertext to plaintext: decryption: P = D(C) – requirement: P = D(E(P)) 2.1.1 Terminology • Encryption with key If the encryption algorithm should fall into the interceptor’s – encryption key: KE – decryption key: K hands, future messages can still D be kept secret because the – C = E(K , P) E interceptor will not know the – P = D(KD, E(KE, P)) key value • Keyless Cipher – a cipher that does not require the -

Shift Cipher Substitution Cipher Vigenère Cipher Hill Cipher
Lecture 2 Classical Cryptosystems Shift cipher Substitution cipher Vigenère cipher Hill cipher 1 Shift Cipher • A Substitution Cipher • The Key Space: – [0 … 25] • Encryption given a key K: – each letter in the plaintext P is replaced with the K’th letter following the corresponding number ( shift right ) • Decryption given K: – shift left • History: K = 3, Caesar’s cipher 2 Shift Cipher • Formally: • Let P=C= K=Z 26 For 0≤K≤25 ek(x) = x+K mod 26 and dk(y) = y-K mod 26 ʚͬ, ͭ ∈ ͔ͦͪ ʛ 3 Shift Cipher: An Example ABCDEFGHIJKLMNOPQRSTUVWXYZ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 • P = CRYPTOGRAPHYISFUN Note that punctuation is often • K = 11 eliminated • C = NCJAVZRCLASJTDQFY • C → 2; 2+11 mod 26 = 13 → N • R → 17; 17+11 mod 26 = 2 → C • … • N → 13; 13+11 mod 26 = 24 → Y 4 Shift Cipher: Cryptanalysis • Can an attacker find K? – YES: exhaustive search, key space is small (<= 26 possible keys). – Once K is found, very easy to decrypt Exercise 1: decrypt the following ciphertext hphtwwxppelextoytrse Exercise 2: decrypt the following ciphertext jbcrclqrwcrvnbjenbwrwn VERY useful MATLAB functions can be found here: http://www2.math.umd.edu/~lcw/MatlabCode/ 5 General Mono-alphabetical Substitution Cipher • The key space: all possible permutations of Σ = {A, B, C, …, Z} • Encryption, given a key (permutation) π: – each letter X in the plaintext P is replaced with π(X) • Decryption, given a key π: – each letter Y in the ciphertext C is replaced with π-1(Y) • Example ABCDEFGHIJKLMNOPQRSTUVWXYZ πBADCZHWYGOQXSVTRNMSKJI PEFU • BECAUSE AZDBJSZ 6 Strength of the General Substitution Cipher • Exhaustive search is now infeasible – key space size is 26! ≈ 4*10 26 • Dominates the art of secret writing throughout the first millennium A.D. -

Substitution Ciphers
Foundations of Computer Security Lecture 40: Substitution Ciphers Dr. Bill Young Department of Computer Sciences University of Texas at Austin Lecture 40: 1 Substitution Ciphers Substitution Ciphers A substitution cipher is one in which each symbol of the plaintext is exchanged for another symbol. If this is done uniformly this is called a monoalphabetic cipher or simple substitution cipher. If different substitutions are made depending on where in the plaintext the symbol occurs, this is called a polyalphabetic substitution. Lecture 40: 2 Substitution Ciphers Simple Substitution A simple substitution cipher is an injection (1-1 mapping) of the alphabet into itself or another alphabet. What is the key? A simple substitution is breakable; we could try all k! mappings from the plaintext to ciphertext alphabets. That’s usually not necessary. Redundancies in the plaintext (letter frequencies, digrams, etc.) are reflected in the ciphertext. Not all substitution ciphers are simple substitution ciphers. Lecture 40: 3 Substitution Ciphers Caesar Cipher The Caesar Cipher is a monoalphabetic cipher in which each letter is replaced in the encryption by another letter a fixed “distance” away in the alphabet. For example, A is replaced by C, B by D, ..., Y by A, Z by B, etc. What is the key? What is the size of the keyspace? Is the algorithm strong? Lecture 40: 4 Substitution Ciphers Vigen`ere Cipher The Vigen`ere Cipher is an example of a polyalphabetic cipher, sometimes called a running key cipher because the key is another text. Start with a key string: “monitors to go to the bathroom” and a plaintext to encrypt: “four score and seven years ago.” Align the two texts, possibly removing spaces: plaintext: fours corea ndsev enyea rsago key: monit orsto gotot hebat hroom ciphertext: rcizl qfkxo trlso lrzet yjoua Then use the letter pairs to look up an encryption in a table (called a Vigen`ere Tableau or tabula recta). -

Algorithms and Mechanisms Historical Ciphers
Algorithms and Mechanisms Cryptography is nothing more than a mathematical framework for discussing the implications of various paranoid delusions — Don Alvarez Historical Ciphers Non-standard hieroglyphics, 1900BC Atbash cipher (Old Testament, reversed Hebrew alphabet, 600BC) Caesar cipher: letter = letter + 3 ‘fish’ ‘ilvk’ rot13: Add 13/swap alphabet halves •Usenet convention used to hide possibly offensive jokes •Applying it twice restores the original text Substitution Ciphers Simple substitution cipher: a=p,b=m,c=f,... •Break via letter frequency analysis Polyalphabetic substitution cipher 1. a = p, b = m, c = f, ... 2. a = l, b = t, c = a, ... 3. a = f, b = x, c = p, ... •Break by decomposing into individual alphabets, then solve as simple substitution One-time Pad (1917) Message s e c r e t 18 5 3 17 5 19 OTP +15 8 1 12 19 5 7 13 4 3 24 24 g m d c x x OTP is unbreakable provided •Pad is never reused (VENONA) •Unpredictable random numbers are used (physical sources, e.g. radioactive decay) One-time Pad (ctd) Used by •Russian spies •The Washington-Moscow “hot line” •CIA covert operations Many snake oil algorithms claim unbreakability by claiming to be a OTP •Pseudo-OTPs give pseudo-security Cipher machines attempted to create approximations to OTPs, first mechanically, then electronically Cipher Machines (~1920) 1. Basic component = wired rotor •Simple substitution 2. Step the rotor after each letter •Polyalphabetic substitution, period = 26 Cipher Machines (ctd) 3. Chain multiple rotors Each rotor steps the next one when a full -

Cryptanalysis of the ``Kindle'' Cipher
Introduction PC1 Known-plaintext key-recovery Ciphertext only key-recovery Conclusion . Cryptanalysis of the “Kindle” Cipher Alex Biryukov, Gaëtan Leurent, Arnab Roy University of Luxembourg SAC 2012 A. Biryukov, G. Leurent, A. Roy (uni.lu) Cryptanalysis of the “Kindle” Cipher SAC 2012 1 / 22 Introduction PC1 Known-plaintext key-recovery Ciphertext only key-recovery Conclusion . Cryptography: theory and practice In theory In practice ▶ Random Oracle ▶ Algorithms ▶ ▶ Ideal Cipher AES ▶ SHA2 ▶ Perfect source of ▶ RSA randomness ▶ Modes of operation ▶ CBC ▶ OAEP ▶ ... ▶ . Random Number Generators ▶ Hardware RNG ▶ PRNG A. Biryukov, G. Leurent, A. Roy (uni.lu) Cryptanalysis of the “Kindle” Cipher SAC 2012 2 / 22 Introduction PC1 Known-plaintext key-recovery Ciphertext only key-recovery Conclusion . Cryptography in the real world Several examples of flaws in industrial cryptography: ▶ Bad random source ▶ SLL with 16bit entropy (Debian) ▶ ECDSA with fixed k (Sony) ▶ Bad key size ▶ RSA512 (TI) ▶ Export restrictions... ▶ Bad mode of operation ▶ CBCMAC with the RC4 streamcipher (Microsoft) ▶ TEA with DaviesMeyer (Microsoft) ▶ Bad (proprietary) algorithm ▶ A5/1 (GSM) ▶ CSS (DVD forum) ▶ Crypto1 (MIFARE/NXP) ▶ KeeLoq (Microchip) A. Biryukov, G. Leurent, A. Roy (uni.lu) Cryptanalysis of the “Kindle” Cipher SAC 2012 3 / 22 Introduction PC1 Known-plaintext key-recovery Ciphertext only key-recovery Conclusion . Amazon Kindle ▶ Ebook reader by Amazon ▶ Most popular ebook reader (≈ 50% share) ▶ 4 generations, 7 devices ▶ Software reader for 7 OS, plus cloud reader ▶ Several million devices sold ▶ Amazon sells more ebooks than paper books ▶ Uses crypto for DRM (Digital Rights Management) A. Biryukov, G. Leurent, A. Roy (uni.lu) Cryptanalysis of the “Kindle” Cipher SAC 2012 4 / 22 Introduction PC1 Known-plaintext key-recovery Ciphertext only key-recovery Conclusion . -

Hill Cipher Cryptanalysis a Known Plaintext Attack Means That We Know
Fall 2019 Chris Christensen MAT/CSC 483 Section 9 Hill Cipher Cryptanalysis A known plaintext attack means that we know a bit of ciphertext and the corresponding plaintext – a crib. This is not an unusual situation. Often messages have stereotypical beginnings (e.g., to …, dear …) or stereotypical endings (e.g, stop) or sometimes it is possible (knowing the sender and receiver or knowing what is likely to be the content of the message) to guess a portion of a message. For a 22× Hill cipher, if we know two ciphertext digraphs and the corresponding plaintext digraphs, we can easily determine the key or the key inverse. 1 Example one: Assume that we know that the plaintext of our ciphertext message that begins WBVE is inma. We could either solve for the key or the key inverse; let’s solve for the key inverse. ef23 9 Because WB corresponds to in = , gh2 14 ef22 13 and because VE corresponds to ma = . gh51 These result in two sets of linear congruences modulo 26: 23ef+= 2 9 22ef+= 5 13 and 23gh+= 2 14 22gh+= 5 1 We solve the systems modulo 26 using Mathematica. In[5]:= Solve[23e+2f == 9 && 22e+5f == 13, {e, f}, Modulus -> 26] Out[5]= {{e->1,f->19}} In[6]:= Solve[23g+2h == 14 && 22g+5h == 1, {g, h}, Modulus -> 26] Out[6]= {{g->20,h->11}} 2 Example two: Ciphertext: FAGQQ ILABQ VLJCY QULAU STYTO JSDJJ PODFS ZNLUH KMOW We are assuming that this message was encrypted using a 22× Hill cipher and that we have a crib. -

Ciphertext-Policy Attribute-Based Encryption: an Expressive, Efficient
Ciphertext-Policy Attribute-Based Encryption: An Expressive, Efficient, and Provably Secure Realization Brent Waters ∗ University of Texas at Austin [email protected] Abstract We present a new methodology for realizing Ciphertext-Policy Attribute Encryption (CP- ABE) under concrete and noninteractive cryptographic assumptions in the standard model. Our solutions allow any encryptor to specify access control in terms of any access formula over the attributes in the system. In our most efficient system, ciphertext size, encryption, and decryption time scales linearly with the complexity of the access formula. The only previous work to achieve these parameters was limited to a proof in the generic group model. We present three constructions within our framework. Our first system is proven selectively secure under a assumption that we call the decisional Parallel Bilinear Diffie-Hellman Exponent (PBDHE) assumption which can be viewed as a generalization of the BDHE assumption. Our next two constructions provide performance tradeoffs to achieve provable security respectively under the (weaker) decisional Bilinear-Diffie-Hellman Exponent and decisional Bilinear Diffie- Hellman assumptions. ∗Supported by NSF CNS-0716199, CNS-0915361, and CNS-0952692, Air Force Office of Scientific Research (AFO SR) under the MURI award for \Collaborative policies and assured information sharing" (Project PRESIDIO), Department of Homeland Security Grant 2006-CS-001-000001-02 (subaward 641), a Google Faculty Research award, and the Alfred P. Sloan Foundation. 1 Introduction Public-Key encryption is a powerful mechanism for protecting the confidentiality of stored and transmitted information. Traditionally, encryption is viewed as a method for a user to share data to a targeted user or device. -

Chapter 13 Attacks on Cryptosystems
Chapter 13 Attacks on Cryptosystems Up to this point, we have mainly seen how ciphers are implemented. We have seen how symmetric ciphers such as DES and AES use the idea of substitution and permutation to provide security and also how asymmetric systems such as RSA and Diffie Hellman use other methods. What we haven’t really looked at are attacks on cryptographic systems. An understanding of certain attacks will help you to understand the reasons behind the structure of certain algorithms (such as Rijndael) as they are designed to thwart known attacks. Although we are not going to exhaust all possible avenues of attack, we will get an idea of how cryptanalysts go about attacking ciphers. This section is really split up into two classes of attack1: Cryptanalytic attacks and Implementation attacks. The former tries to attack mathematical weaknesses in the algorithms whereas the latter tries to attack the specific implementation of the cipher (such as a smartcard system). The following attacks can refer to either of the two classes (all forms of attack assume the attacker knows the encryption algorithm): • Ciphertext-only attack: In this attack the attacker knows only the ciphertext to be decoded. The attacker will try to find the key or decrypt one or more pieces of ciphertext (only relatively weak algorithms fail to withstand a ciphertext-only attack). • Known plaintext attack: The attacker has a collection of plaintext-ciphertext pairs and is trying to find the key or to decrypt some other ciphertext that has been encrypted with the same key. • Chosen Plaintext attack: This is a known plaintext attack in which the attacker can choose the plaintext to be encrypted and read the corresponding ciphertext.