Ciphertext-Policy Attribute-Based Encryption: an Expressive, Efficient
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Classical Encryption Techniques
CPE 542: CRYPTOGRAPHY & NETWORK SECURITY Chapter 2: Classical Encryption Techniques Dr. Lo’ai Tawalbeh Computer Engineering Department Jordan University of Science and Technology Jordan Dr. Lo’ai Tawalbeh Fall 2005 Introduction Basic Terminology • plaintext - the original message • ciphertext - the coded message • key - information used in encryption/decryption, and known only to sender/receiver • encipher (encrypt) - converting plaintext to ciphertext using key • decipher (decrypt) - recovering ciphertext from plaintext using key • cryptography - study of encryption principles/methods/designs • cryptanalysis (code breaking) - the study of principles/ methods of deciphering ciphertext Dr. Lo’ai Tawalbeh Fall 2005 1 Cryptographic Systems Cryptographic Systems are categorized according to: 1. The operation used in transferring plaintext to ciphertext: • Substitution: each element in the plaintext is mapped into another element • Transposition: the elements in the plaintext are re-arranged. 2. The number of keys used: • Symmetric (private- key) : both the sender and receiver use the same key • Asymmetric (public-key) : sender and receiver use different key 3. The way the plaintext is processed : • Block cipher : inputs are processed one block at a time, producing a corresponding output block. • Stream cipher: inputs are processed continuously, producing one element at a time (bit, Dr. Lo’ai Tawalbeh Fall 2005 Cryptographic Systems Symmetric Encryption Model Dr. Lo’ai Tawalbeh Fall 2005 2 Cryptographic Systems Requirements • two requirements for secure use of symmetric encryption: 1. a strong encryption algorithm 2. a secret key known only to sender / receiver •Y = Ek(X), where X: the plaintext, Y: the ciphertext •X = Dk(Y) • assume encryption algorithm is known •implies a secure channel to distribute key Dr. -

A Decade of Lattice Cryptography
Full text available at: http://dx.doi.org/10.1561/0400000074 A Decade of Lattice Cryptography Chris Peikert Computer Science and Engineering University of Michigan, United States Boston — Delft Full text available at: http://dx.doi.org/10.1561/0400000074 Foundations and Trends R in Theoretical Computer Science Published, sold and distributed by: now Publishers Inc. PO Box 1024 Hanover, MA 02339 United States Tel. +1-781-985-4510 www.nowpublishers.com [email protected] Outside North America: now Publishers Inc. PO Box 179 2600 AD Delft The Netherlands Tel. +31-6-51115274 The preferred citation for this publication is C. Peikert. A Decade of Lattice Cryptography. Foundations and Trends R in Theoretical Computer Science, vol. 10, no. 4, pp. 283–424, 2014. R This Foundations and Trends issue was typeset in LATEX using a class file designed by Neal Parikh. Printed on acid-free paper. ISBN: 978-1-68083-113-9 c 2016 C. Peikert All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, mechanical, photocopying, recording or otherwise, without prior written permission of the publishers. Photocopying. In the USA: This journal is registered at the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923. Authorization to photocopy items for in- ternal or personal use, or the internal or personal use of specific clients, is granted by now Publishers Inc for users registered with the Copyright Clearance Center (CCC). The ‘services’ for users can be found on the internet at: www.copyright.com For those organizations that have been granted a photocopy license, a separate system of payment has been arranged. -

Index-Of-Coincidence.Pdf
The Index of Coincidence William F. Friedman in the 1930s developed the index of coincidence. For a given text X, where X is the sequence of letters x1x2…xn, the index of coincidence IC(X) is defined to be the probability that two randomly selected letters in the ciphertext represent, the same plaintext symbol. For a given ciphertext of length n, let n0, n1, …, n25 be the respective letter counts of A, B, C, . , Z in the ciphertext. Then, the index of coincidence can be computed as 25 ni (ni −1) IC = ∑ i=0 n(n −1) We can also calculate this index for any language source. For some source of letters, let p be the probability of occurrence of the letter a, p be the probability of occurrence of a € b the letter b, and so on. Then the index of coincidence for this source is 25 2 Isource = pa pa + pb pb +…+ pz pz = ∑ pi i=0 We can interpret the index of coincidence as the probability of randomly selecting two identical letters from the source. To see why the index of coincidence gives us useful information, first€ note that the empirical probability of randomly selecting two identical letters from a large English plaintext is approximately 0.065. This implies that an (English) ciphertext having an index of coincidence I of approximately 0.065 is probably associated with a mono-alphabetic substitution cipher, since this statistic will not change if the letters are simply relabeled (which is the effect of encrypting with a simple substitution). The longer and more random a Vigenere cipher keyword is, the more evenly the letters are distributed throughout the ciphertext. -

Automating the Development of Chosen Ciphertext Attacks
Automating the Development of Chosen Ciphertext Attacks Gabrielle Beck∗ Maximilian Zinkus∗ Matthew Green Johns Hopkins University Johns Hopkins University Johns Hopkins University [email protected] [email protected] [email protected] Abstract In this work we consider a specific class of vulner- ability: the continued use of unauthenticated symmet- In this work we investigate the problem of automating the ric encryption in many cryptographic systems. While development of adaptive chosen ciphertext attacks on sys- the research community has long noted the threat of tems that contain vulnerable format oracles. Unlike pre- adaptive-chosen ciphertext attacks on malleable en- vious attempts, which simply automate the execution of cryption schemes [17, 18, 56], these concerns gained known attacks, we consider a more challenging problem: practical salience with the discovery of padding ora- to programmatically derive a novel attack strategy, given cle attacks on a number of standard encryption pro- only a machine-readable description of the plaintext veri- tocols [6,7, 13, 22, 30, 40, 51, 52, 73]. Despite repeated fication function and the malleability characteristics of warnings to industry, variants of these attacks continue to the encryption scheme. We present a new set of algo- plague modern systems, including TLS 1.2’s CBC-mode rithms that use SAT and SMT solvers to reason deeply ciphersuite [5,7, 48] and hardware key management to- over the design of the system, producing an automated kens [10, 13]. A generalized variant, the format oracle attack strategy that can entirely decrypt protected mes- attack can be constructed when a decryption oracle leaks sages. -
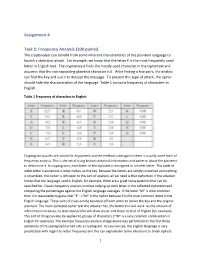
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language. -

Chap 2. Basic Encryption and Decryption
Chap 2. Basic Encryption and Decryption H. Lee Kwang Department of Electrical Engineering & Computer Science, KAIST Objectives • Concepts of encryption • Cryptanalysis: how encryption systems are “broken” 2.1 Terminology and Background • Notations – S: sender – R: receiver – T: transmission medium – O: outsider, interceptor, intruder, attacker, or, adversary • S wants to send a message to R – S entrusts the message to T who will deliver it to R – Possible actions of O • block(interrupt), intercept, modify, fabricate • Chapter 1 2.1.1 Terminology • Encryption and Decryption – encryption: a process of encoding a message so that its meaning is not obvious – decryption: the reverse process • encode(encipher) vs. decode(decipher) – encoding: the process of translating entire words or phrases to other words or phrases – enciphering: translating letters or symbols individually – encryption: the group term that covers both encoding and enciphering 2.1.1 Terminology • Plaintext vs. Ciphertext – P(plaintext): the original form of a message – C(ciphertext): the encrypted form • Basic operations – plaintext to ciphertext: encryption: C = E(P) – ciphertext to plaintext: decryption: P = D(C) – requirement: P = D(E(P)) 2.1.1 Terminology • Encryption with key If the encryption algorithm should fall into the interceptor’s – encryption key: KE – decryption key: K hands, future messages can still D be kept secret because the – C = E(K , P) E interceptor will not know the – P = D(KD, E(KE, P)) key value • Keyless Cipher – a cipher that does not require the -

Multi-Input Functional Encryption with Unbounded-Message Security
Multi-Input Functional Encryption with Unbounded-Message Security Vipul Goyal ⇤ Aayush Jain † Adam O’ Neill‡ Abstract Multi-input functional encryption (MIFE) was introduced by Goldwasser et al. (EUROCRYPT 2014) as a compelling extension of functional encryption. In MIFE, a receiver is able to compute a joint function of multiple, independently encrypted plaintexts. Goldwasser et al. (EUROCRYPT 2014) show various applications of MIFE to running SQL queries over encrypted databases, computing over encrypted data streams, etc. The previous constructions of MIFE due to Goldwasser et al. (EUROCRYPT 2014) based on in- distinguishability obfuscation had a major shortcoming: it could only support encrypting an apriori bounded number of message. Once that bound is exceeded, security is no longer guaranteed to hold. In addition, it could only support selective-security,meaningthatthechallengemessagesandthesetof “corrupted” encryption keys had to be declared by the adversary up-front. In this work, we show how to remove these restrictions by relying instead on sub-exponentially secure indistinguishability obfuscation. This is done by carefully adapting an alternative MIFE scheme of Goldwasser et al. that previously overcame these shortcomings (except for selective security wrt. the set of “corrupted” encryption keys) by relying instead on differing-inputs obfuscation, which is now seen as an implausible assumption. Our techniques are rather generic, and we hope they are useful in converting other constructions using differing-inputs obfuscation to ones using sub-exponentially secure indistinguishability obfuscation instead. ⇤Microsoft Research, India. Email: [email protected]. †UCLA, USA. Email: [email protected]. Work done while at Microsoft Research, India. ‡Georgetown University, USA. Email: [email protected]. -

Algorithms and Complexity Results for Learning and Big Data
Algorithms and Complexity Results for Learning and Big Data BY Ad´ am´ D. Lelkes B.Sc., Budapest University of Technology and Economics, 2012 M.S., University of Illinois at Chicago, 2014 THESIS Submitted as partial fulfillment of the requirements for the degree of Doctor of Philosophy in Mathematics in the Graduate College of the University of Illinois at Chicago, 2017 Chicago, Illinois Defense Committee: Gy¨orgyTur´an,Chair and Advisor Lev Reyzin, Advisor Shmuel Friedland Lisa Hellerstein, NYU Tandon School of Engineering Robert Sloan, Department of Computer Science To my parents and my grandmother / Sz¨uleimnek´esnagymam´amnak ii Acknowledgments I had a very enjoyable and productive four years at UIC, which would not have been possible without my two amazing advisors, Lev Reyzin and Gy¨orgy Tur´an. I would like to thank them for their guidance and support in every aspect of my graduate studies and research and for always being available when I had questions. Gyuri's humility, infinite patience, and meticulous attention to detail, as well as the breadth and depth of his knowledge, set an example for me to aspire to. Lev's energy and enthusiasm for research and his effectiveness at doing it always inspired me; the hours I spent in Lev's office were often the most productive hours of my week. Both Gyuri and Lev served as role models for me both as researchers and as people. Also, I would like to thank Gyuri and his wife R´ozsafor their hospitality. They invited me to their home a countless number of times, which made time in Chicago much more pleasant. -

Shift Cipher Substitution Cipher Vigenère Cipher Hill Cipher
Lecture 2 Classical Cryptosystems Shift cipher Substitution cipher Vigenère cipher Hill cipher 1 Shift Cipher • A Substitution Cipher • The Key Space: – [0 … 25] • Encryption given a key K: – each letter in the plaintext P is replaced with the K’th letter following the corresponding number ( shift right ) • Decryption given K: – shift left • History: K = 3, Caesar’s cipher 2 Shift Cipher • Formally: • Let P=C= K=Z 26 For 0≤K≤25 ek(x) = x+K mod 26 and dk(y) = y-K mod 26 ʚͬ, ͭ ∈ ͔ͦͪ ʛ 3 Shift Cipher: An Example ABCDEFGHIJKLMNOPQRSTUVWXYZ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 • P = CRYPTOGRAPHYISFUN Note that punctuation is often • K = 11 eliminated • C = NCJAVZRCLASJTDQFY • C → 2; 2+11 mod 26 = 13 → N • R → 17; 17+11 mod 26 = 2 → C • … • N → 13; 13+11 mod 26 = 24 → Y 4 Shift Cipher: Cryptanalysis • Can an attacker find K? – YES: exhaustive search, key space is small (<= 26 possible keys). – Once K is found, very easy to decrypt Exercise 1: decrypt the following ciphertext hphtwwxppelextoytrse Exercise 2: decrypt the following ciphertext jbcrclqrwcrvnbjenbwrwn VERY useful MATLAB functions can be found here: http://www2.math.umd.edu/~lcw/MatlabCode/ 5 General Mono-alphabetical Substitution Cipher • The key space: all possible permutations of Σ = {A, B, C, …, Z} • Encryption, given a key (permutation) π: – each letter X in the plaintext P is replaced with π(X) • Decryption, given a key π: – each letter Y in the ciphertext C is replaced with π-1(Y) • Example ABCDEFGHIJKLMNOPQRSTUVWXYZ πBADCZHWYGOQXSVTRNMSKJI PEFU • BECAUSE AZDBJSZ 6 Strength of the General Substitution Cipher • Exhaustive search is now infeasible – key space size is 26! ≈ 4*10 26 • Dominates the art of secret writing throughout the first millennium A.D. -

Cryptanalysis of Boyen's Attribute-Based Encryption Scheme
Cryptanalysis of Boyen’s Attribute-Based Encryption Scheme in TCC 2013 Shweta Agrawal1, Rajarshi Biswas1, Ryo Nishimaki2, Keita Xagawa2, Xiang Xie3, and Shota Yamada4 1 IIT Madras, Chennai, India [email protected], [email protected] 2 NTT Secure Platform Laboratories, Tokyo, Japan [ryo.nishimaki.zk,keita.xagawa.zv]@hco.ntt.co.jp 3 Shanghai Key Laboratory of Privacy-Preserving Computation, China [email protected] 4 National Institute of Advanced Industrial Science and Technology (AIST), Tokyo [email protected] Abstract. In TCC 2013, Boyen suggested the first lattice based con- struction of attribute based encryption (ABE) for the circuit class NC1. Unfortunately, soon after, a flaw was found in the security proof of the scheme. However, it remained unclear whether the scheme is actually insecure, and if so, whether it can be repaired. Meanwhile, the construc- tion has been heavily cited and continues to be extensively studied due to its technical novelty. In particular, this is the first lattice based ABE which uses linear secret sharing schemes (LSSS) as a crucial tool to en- force access control. In this work, we show that the scheme is in fact insecure. To do so, we provide a polynomial-time attack that completely breaks the security of the scheme. We suggest a route to fix the security of the scheme, via the notion of admissible linear secret sharing schemes (LSSS) and instantiate these for the class of DNFs. Subsequent to our work, Datta, Komargodski and Waters (Eurocrypt 2021) provided a construction of admissible LSSS for NC1 and resurrected Boyen’s claimed result. -

Access Control Encryption for General Policies from Standard Assumptions
Access Control Encryption for General Policies from Standard Assumptions Sam Kim David J. Wu Stanford University Stanford University [email protected] [email protected] Abstract Functional encryption enables fine-grained access to encrypted data. In many scenarios, however, it is important to control not only what users are allowed to read (as provided by traditional functional encryption), but also what users are allowed to send. Recently, Damg˚ardet al. (TCC 2016) introduced a new cryptographic framework called access control encryption (ACE) for restricting information flow within a system in terms of both what users can read as well as what users can write. While a number of access control encryption schemes exist, they either rely on strong assumptions such as indistinguishability obfuscation or are restricted to simple families of access control policies. In this work, we give the first ACE scheme for arbitrary policies from standard assumptions. Our construction is generic and can be built from the combination of a digital signature scheme, a predicate encryption scheme, and a (single-key) functional encryption scheme that supports randomized functionalities. All of these primitives can be instantiated from standard assumptions in the plain model and therefore, we obtain the first ACE scheme capable of supporting general policies from standard assumptions. One possible instantiation of our construction relies upon standard number-theoretic assumptions (namely, the DDH and RSA assumptions) and standard lattice assumptions (namely, LWE). Finally, we conclude by introducing several extensions to the ACE framework to support dynamic and more fine-grained access control policies. 1 Introduction In the last ten years, functional encryption [BSW11, O'N10] has emerged as a powerful tool for enforcing fine-grained access to encrypted data. -

Substitution Ciphers
Foundations of Computer Security Lecture 40: Substitution Ciphers Dr. Bill Young Department of Computer Sciences University of Texas at Austin Lecture 40: 1 Substitution Ciphers Substitution Ciphers A substitution cipher is one in which each symbol of the plaintext is exchanged for another symbol. If this is done uniformly this is called a monoalphabetic cipher or simple substitution cipher. If different substitutions are made depending on where in the plaintext the symbol occurs, this is called a polyalphabetic substitution. Lecture 40: 2 Substitution Ciphers Simple Substitution A simple substitution cipher is an injection (1-1 mapping) of the alphabet into itself or another alphabet. What is the key? A simple substitution is breakable; we could try all k! mappings from the plaintext to ciphertext alphabets. That’s usually not necessary. Redundancies in the plaintext (letter frequencies, digrams, etc.) are reflected in the ciphertext. Not all substitution ciphers are simple substitution ciphers. Lecture 40: 3 Substitution Ciphers Caesar Cipher The Caesar Cipher is a monoalphabetic cipher in which each letter is replaced in the encryption by another letter a fixed “distance” away in the alphabet. For example, A is replaced by C, B by D, ..., Y by A, Z by B, etc. What is the key? What is the size of the keyspace? Is the algorithm strong? Lecture 40: 4 Substitution Ciphers Vigen`ere Cipher The Vigen`ere Cipher is an example of a polyalphabetic cipher, sometimes called a running key cipher because the key is another text. Start with a key string: “monitors to go to the bathroom” and a plaintext to encrypt: “four score and seven years ago.” Align the two texts, possibly removing spaces: plaintext: fours corea ndsev enyea rsago key: monit orsto gotot hebat hroom ciphertext: rcizl qfkxo trlso lrzet yjoua Then use the letter pairs to look up an encryption in a table (called a Vigen`ere Tableau or tabula recta).