Simulating Historical Flood Events at the Continental-Scale: Observational Validation of a Large-Scale Hydrodynamic Model Oliver E
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

E.3-IDNR Roster of Navigable Waterways in Indiana
APPENDIX E.3 IDNR Roster of Navigable Waterways in Indiana Nonrule Policy Documents NATURAL RESOURCES COMMISSION Information Bulletin #3 July 1, 1992 SUBJECT: Roster of Indiana Waterways Declared Navigable I. NAVIGABILITY Property rights relative to Indiana waterways often are determined by whether the waterway is "navigable". Both common law and statutory law make distinctions founded upon whether a river, stream, embayment, or lake is navigable. A landmark decision in Indiana with respect to determining and applying navigability is State v. Kivett, 228 Ind. 629, 95 N.E.2d 148 (1950). The Indiana Supreme Court stated that the test for determining navigability is whether a waterway: was available and susceptible for navigation according to the general rules of river transportation at the time [1816] Indiana was admitted to the Union. It does not depend on whether it is now navigable. .The true test seems to be the capacity of the stream, rather than the manner or extent of use. And the mere fact that the presence of sandbars or driftwood or stone, or other objects, which at times render the stream unfit for transportation, does not destroy its actual capacity and susceptibility for that use. A modified standard for determining navigability applies to a body of water which is artificial. The test for a man-made reservoir, or a similar waterway which did not exist in 1816, is whether it is navigable in fact. Reed v. United States, 604 F. Supp. 1253 (1984). The court observed in Kivett that "whether the waters within the State under which the lands lie are navigable or non-navigable, is a federal" question and is "determined according to the law and usage recognized and applied in the federal courts, even though" the waterway may not be "capable of use for navigation in interstate or foreign commerce." Federal decisions applied to particular issues of navigability are useful precedents, regardless of whether the decisions originated in Indiana or another state. -

Survey of the Freshwater Mussels
ILLINO S UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN PRODUCTION NOTE University of Illinois at Urbana-Champaign Library Large-scale Digitization Project, 2007. bO&C Natural History Survey TLf94S Library I l' 13) SURVEY OF THE FRESHWATER MUSSELS (MOLLUSCA: UNIONIDAE) OF THE WABASH RIVER DRAINAGE PHASE III: WHITE RIVER AND SELECTED TRIBUTARIES Kevin S. Cummings, Christine A. Mayer, and Lawrence M. Page Center for Biodiversity Technical Report 1991 (3) Illinois Natural History Survey 607 E. Peabody Drive Champaign, Illinois 61820 Prepared for Indiana Department of Natural Resources Division of Fish and Wildlife 607 State Office Building Indianapolis, Indiana 46204 Study Funded by a Grant from the Indiana Department of Natural Resources Nongame & Endangered Wildlife Program Endangered Species Act Project E- 1, Study 1 TABLE OF CONTENTS PAGE LIST OF FIGURES..................................................................................................... i LIST OF TABLES ..................................................................................................... iii INTRODUCTION.............................................................................................................2 STUDY AREA AND METHODS.............................................................................. 3 RESULTS AND DISCUSSION.............................................. .................................. 9 SPECIES ACCOUNTS............................... ...............................................................21 RECOMMENDATIONS.......................... -
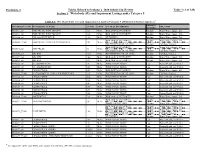
Tables Related to Indiana's 2020 303(D) List Review
Enclosure 3 Tables Related to Indiana’s 2020 303(d) List Review Table 1 (1 of 249) Section 1: Waterbody AUs and Impairment Listings under Category 5 TABLE 1: IN's Waterbody AUs and Impairments Listed in Category 5 (303d list) of Partial Approval.A PRIORITY WATERBODY AU ID WATERBODY AU NAME AU SIZE UNITS CAUSE OF IMPAIRMENT USE_NAME RANKING INA0341_01 FISH CREEK, WEST BRANCH 3.32 Miles BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0341_02 FISH CREEK, WEST BRANCH 2.36 Miles BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0344_01 HIRAM SWEET DITCH 1.32 Miles NUTRIENTS Medium Warm Water Aquatic Life BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0345_T1001 FISH CREEK - UNNAMED TRIBUTARY 3.09 Miles ESCHERICHIA COLI (E. COLI) Medium Full Body Contact BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0346_02 FISH CREEK 7.3 Miles ESCHERICHIA COLI (E. COLI) Medium Full Body Contact INA0352_03 BIG RUN 10.33 Miles ESCHERICHIA COLI (E. COLI) Medium Full Body Contact INA0352_04 BIG RUN 2.46 Miles BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0352_05 BIG RUN 5.91 Miles BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0355_01 ST. JOSEPH RIVER 2.5 Miles PCBS IN FISH TISSUE Low Human Health and Wildlife INA0356_03 ST. JOSEPH RIVER 3.53 Miles PCBS IN FISH TISSUE Low Human Health and Wildlife INA0362_05 CEDAR CREEK 0.83 Miles BIOLOGICAL INTEGRITY Medium Warm Water Aquatic Life INA0363_T1001 MATSON DITCH - UNNAMED TRIBUTARY 2.15 Miles ESCHERICHIA COLI (E. COLI) Medium Full Body Contact INA0364_01 CEDAR CREEK 4.24 -

INRC 1997 Outstanding Rivers List for Indiana
Indiana Register NATURAL RESOURCES COMMISSION Information Bulletin #4 (Second Amendment) SUBJECT: Outstanding Rivers List for Indiana I. INTRODUCTION To help identify the rivers and streams that have particular environmental or aesthetic interest, a special listing has been prepared by the Division of Outdoor Recreation of the Department of Natural Resources. The listing is a corrected and condensed version of a listing compiled by American Rivers and dated October 1990. There are about 2,000 river miles included on the listing, a figure that represents less than 9% of the estimated 24,000 total river miles in Indiana. The Natural Resources Commission has adopted the listing as an official recognition of the resource values of these waters. A river included in the listing qualifies under one or more of the following 22 categories. An asterisk indicates that all or part of the river segment was also included in the "Roster of Indiana Waterways Declared Navigable", 15 IR 2385 (July 1992). In 2006, the commission updated this citation, and Information Bulletin #3 (Second Amendment) was posted in the Indiana Register at 20061011-IR-312060440NRA. A river designated "EUW" is an exceptional use water. A river designated "HQW" is a high quality water, and a river designated "SS" is a salmonoid stream. 1. Designated national Wild and Scenic Rivers. Rivers that Congress has included in the National Wild and Scenic System pursuant to the National Wild and Scenic River Act, Public Law 90-452. 2. National Wild and Scenic Study Rivers. Rivers that Congress has determined should be studied for possible inclusion in the National Wild and Scenic Rivers System. -

Columbus, Indiana City Map Of
I E F G H A B C D CITY MAP OF COLUMBUS, INDIANA Highfield West Spring Hill 11 11 Westgate Northgate Woodland Parks Flatrock River Flatrock Park North Columbus Municipal Airport Haw Creek N Flatrock Park Lowell 0 2000 4000 I.U.P.U.C. 10 IUPUC 3000 5000 Info-Tech 1000 Park Northbrook 10 Corn Brook Park Forest Estates North Ivy Tech Progress Park Autumnwood Sims Homestead Northbrook Addn. Park Carter Crossing Riverview Acres Taylor Sycamore Homestead Bend Mobile Home The Villas Carter of Stonecrest Cemetery Westenedge Park Pinebrooke Adams Park Pepper Tree Breakaway Trails Rocky Ford Village Princeton Parkside Crossing Park School Candlelight Jackson Park Park Forest Arrowood Indian Hills Woodfield Estates Village Chapel Place Pinebrooke Bluff South Canterbury Arbors At Apartments Rosevelt Park Waters Edge Deer- High Vista Washington field Place Parkside The Woods Willowwood 9 Apts. Tudor Rocky Ford Green View Park Forest Park North Par 3 Rost's 2nd Cedar Windsor Place Golf Course 9 Addition Heathfield Ridge Broadmoor North Eastridge Manor Greenbriar Commerce Park Broadmoor Richards Richards Rost's 3rd Addition 3rd Rost's North Meadow School Mead Village Questover Skyview Estates Washington Heather Heights Park Prairie Stream Estates Forest Park Sims West Mead Village Park Cornerstone's Northpark Hillcrest Jefferson Park Forest Park Rost's 3rd Addition 3rd Rost's Madison Park Northern Village Everroad Chapel Square Tipton Park North Shopping Center Park Columbus Village Apts. Grant Park Northside Carriage Middle Everroad Park West Estates B&K School Industrial Foxpointe Park Fairlawn Williamsburg Flintwood Everroad Apartments Schmidt Park Tipton Park School Foxpointe Apts. -

Floods of March 1964 Along the Ohio River
Floods of March 1964 Along the Ohio River GEOLOGICAL SURVEY WATER-SUPPLY PAPER 1840-A Prepared in cooperation with the States of Kentucky, Ohio, Indiana, Pennsylvania, and West Virginia, and with agencies of the Federal Government Floods of March 1964 Along the Ohio River By H. C. BEABER and J. O. ROSTVEDT FLOODS OF 1964 IN THE UNITED STATES GEOLOGICAL SURVEY WATER-SUPPLY PAPER 1840-A Prepared in cooperation with the States of Kentucky, Ohio, Indiana, Pennsylvania, and West Virginia, and with agencies of the Federal Government UNITED STATES GOVERNMENT PRINTING OFFICE, WASHINGTON : 1965 UNITED STATES DEPARTMENT OF THE INTERIOR STEWART L. UDALL, Secretary GEOLOGICAL SURVEY William T. Pecora, Director For sale by the Superintendent of Documents, U.S. Government Printing Office Washington, D.C. 20402 - Price 65 cents (paper cover) CONTENTS Page Abstract ------------------------------------------------------- Al Introduction.______-_-______--_____--__--_--___-_--__-_-__-__-____ 1 The storms.__---_------------__------------------------_----_--_- 6 The floods.___-__.______--____-._____.__ ._-__-.....__._____ 8 Pennsylvania.. _._-.------._-_-----___-__---_-___-_--_ ..___ 8 West Virginia.--.-._____--_--____--_-----_-----_---__--_-_-__- 11 Ohio.-.------.---_-_-_.__--_-._---__.____.-__._--..____ 11 Muskingum River basin._---___-__---___---________________ 11 Hocking River basin_______________________________________ 12 Scioto River basin______.__________________________________ 13 Little Miami River basin.__-____-_.___._-._____________.__. 13 Kentucky._.__.___.___---___----_------_--_-______-___-_-_-__ -

Flood-Inundation Maps for the Flatrock Rover at Columbus, Indiana, 2012
Prepared in cooperation with the Indiana Department of Transportation Flood-Inundation Maps for the Flatrock River at Columbus, Indiana, 2012 Pamphlet to accompany Scientific Investigations Map 3241 U.S. Department of the Interior U.S. Geological Survey Cover. Illustration showing simulated floods corresponding to streamgage stages of 9, 13, and 20 feet for Flatrock River at Columbus, Indiana. Flood-Inundation Maps for the Flatrock River at Columbus, Indiana, 2012 By William F. Coon Prepared in cooperation with the Indiana Department of Transportation Pamphlet to accompany Scientific Investigations Map 3241 U.S. Department of the Interior U.S. Geological Survey U.S. Department of the Interior KEN SALAZAR, Secretary U.S. Geological Survey Suzette M. Kimball, Acting Director U.S. Geological Survey, Reston, Virginia: 2013 For more information on the USGS—the Federal source for science about the Earth, its natural and living resources, natural hazards, and the environment, visit http://www.usgs.gov or call 1–888–ASK–USGS. For an overview of USGS information products, including maps, imagery, and publications, visit http://www.usgs.gov/pubprod To order this and other USGS information products, visit http://store.usgs.gov Any use of trade, product, or firm names is for descriptive purposes only and does not imply endorsement by the U.S. Government. Although this report is in the public domain, permission must be secured from the individual copyright owners to reproduce any copyrighted materials contained within this report. Suggested citation: -

Low-Flow Characteristics of Indiana Streams
LOW-FLOW CHARACTERISTICS OF INDIANA STREAMS By James A. Stewart U.S. GEOLOGICAL SURVEY Open-File Report 82-1007 Prepared in cooperation with INDIANA STATE BOARD OF HEALTH and the INDIANA DEPARTMENT OF NATURAL RESOURCES Indianapolis, Indiana 1983 UNITED STATES DEPARTMENT OF THE INTERIOR JAMES G. WATT, Secretary GEOLOGICAL SURVEY Dallas L. Peck, Director For additional information Copies of this report can write to: be purchased from: District Chief Open-File Services Section U.S. Geological Survey, WRD Western Distribution Branch 6023 Guion Road, Suite 201 Box 25425, Federal Center Indianapolis, Indiana 46254 Denver, Colorado 80225 (Telephone: (303) 234-5888) CONTENTS Page Abstract................................................................. 1 Introduction............................................................. 1 Purpose and scope.................................................... l Acknowledgments...................................................... 2 Physiography and geology................................................. 2 Northern zone........................................................ 2 Central zone......................................................... 4 Southern zone........................................................ 4 Precipitation............................................................ 5 Low-flow-frequency analysis.............................................. 5 Continuous-record stations........................................... 5 Partial-record stations............................................. -

Bartholomew County, Indiana R
S" ¸ # ¸ ¸ ¸ # # # ¸ # ¸ # ¸ # ¸ # ¸ # ¸ J # S o h h e n l s b ¸ ¸ # o # y ¸ # ¸ e n # lu B r ¸ # ¸ ig e Edinburgh # B iv Shelby R Shelby S" Decatur ¸ " # S Bartholomew Johnson Bartholomew Hope S" w e Taylorsville r m u t o l a o c D S" e h t D r r a i f B t w ¸ o# o d R i ve r ¸ # ¸ # ¸ # ¸ # ¸ # ¸ # ¸ # ¸ # ¸ # ¸ ¸ # w # e m n o w l o o r h t B r a Columbus B S" ¸ # ¸ ¸ # # 5 6 - I § ¨ ¦ ¸ # ¸ # ¸ # ¸ ¸ ¸ ¸ # # # # Elizabethtown S" Bartholomew ¸ # W Jennings h i t e E a s R v t i e F r o r w e s g k m n o i l n o n h t e r J a B ¸ # ¸ # ¸ # ¸ # ¸ # ¸ # ¸ Brown # Jackson s n g o n s i k n c Bartholomew n a e J Jackson J ¸ # ¸ # Source: Esri, DigitalGlobe, GeoEye, i-cubed, USDA, USGS, AEX, Getmapping, Aerogrid, IGN, IGP, swisstopo, and the GIS User Community ¸ Withdrawal Location # ¸ River# Major Lakes ¸ # ¸ WELL INTAKE # 7Q2 Flow (MGD) Interstate ¸ Water Resources # Energy/Mining <10 MGD County ¸ # Industry ¸ Irrigation 10 - 50 MGD S" City # ¸ and Use in # 50 - 100 MGD ¸ # Misc. Miles 100 - 500 MGD ¸ Bartholomew County # Public Supply N 0 1 2 4 Data Sources: U.S. Geological Survey and Indiana Department of Natural Resources Rural Use > 500 MGD Joseph E. Kernan, Governor Department of Natural Resources Division of Water John Goss, Director Aquifer Systems Map 17-B BEDROCK AQUIFER SYSTEMS OF BARTHOLOMEW COUNTY, INDIANA R. 7 E. R. 8 E. -

Evaluation of Scour at Selected Bridge Sites in Indiana
Evaluation of Scour at Selected Bridge Sites in Indiana By ROBERT L. MILLER and JOHN T. WILSON Prepared in cooperation with the INDIANA DEPARTMENT OF TRANSPORTATION U.S. GEOLOGICAL SURVEY Water-Resources Investigations Report 95-4259 Indianapolis, Indiana 1996 U.S. DEPARTMENT OF THE INTERIOR BRUCE BABBITT, Secretary U.S. GEOLOGICAL SURVEY Gordon P. Eaton, Director For additional information, write to: Copies of this report can be purchased from: District Chief U.S. Geological Survey U.S. Geological Survey Earth Science Information Center Water Resources Division Open-File Reports Section 5957 Lakeside Boulevard Box25286, MS 517 Indianapolis, IN 46278-1996 Denver Federal Center Denver, CO 80225 CONTENTS Abstract .................................................................................. 1 Introduction ............................................................................... 2 Purpose and Scope ...................................................................... 3 Approach.............................................................................. 4 Methods of Investigation for Data Collection ..................................................... 4 Historical Scour, Flood Measurements, and Routine Soundings by Site ................................ 9 Bridge 3-02-5261B, S.R. 1 over St. Marys River at Fort Wayne, Indiana............................ 9 Bridge 9-44-4381A, S.R. 9 over Pigeon River at Howe, Indiana .................................. 9 Bridge (11)31A-03-3039B, S.R. 11 over Flatrock River at Columbus, Indiana ...................... -

Fishes of the White River Basin, Indiana
FISHES OF THE WHITE RIVER BASIN, U INDIANA G U.S. Department of the Interior U.S. Geological Survey Since 1875, researchers have reported 158 species of fish belonging to 25 families in the White River Basin. Of these species, 6 have not been reported since 1900 and 10 have not been reported since 1943. Since the 1820's, fish communities in the White River Basin have been affected by the alteration of stream habitat, overfishing, the introduction of non-native species, agriculture, and urbanization. Erosion resulting from conversion of forest land to cropland in the 1800's led to siltation of streambeds and resulted in the loss of some silt- sensitive species. In the early 1900's, the water quality of the White River was seriously degraded for 100 miles by untreated sewage from the City of Indianapolis. During the last 25 years, water quality in the basin has improved because of efforts to control water pollu tion. Fish communities in the basin have responded favorably to the improved water quality. INTRODUCTION In 1991, the U.S. Geological Survey began the National Water- Quality Assessment (NAWQA) Program. The long-term goals of the NAWQA Program are to describe the status and trends in the quality of a large, representative part of the Nation's surface- and ground-water resources and to provide a sound, scientific understanding of the pri mary natural and human factors affecting the quality of these resources (Hirsch and others, 1988). The White River Basin in Indiana was among the first 20 river basins to be studied as part of this program. -

(Rhoadesius) Sloanii (Bundy) (Crustacea: Decapoda: Cambaridae)1
202 LA. UNGAR Vol. 88 BRIEF NOTE Distribution and Status of Orconectes (Rhoadesius) sloanii (Bundy) (Crustacea: Decapoda: Cambaridae)1 F. LEE ST. JOHN, Department of Zoology, The Ohio State University at Newark, University Drive, Newark, OH 43055 ABSTRACT. The distribution of the crayfish, Orconectes sloanii (Bundy), is revised from Rhoades' (1962) re- port. Five county records are added: Dubois, Lawrence, Perry, Rush and Spencer, Indiana; the species has been extirpated from three counties: Miami and Shelby, Ohio, and Shelby, Indiana. Where 0. sloanii is sym- patric with Orconectes (Procericambarus) rusticus (Girard), the number of 0. rusticus collected usually ex- ceeded the number of 0. sloanii. The status of the species as a threatened Ohio crayfish is supported. OHIO J. SCI. 88 (5) 202-204, 1988 INTRODUCTION (1.2 X 1.8 m; 0.64-cm mesh). The crayfish were fixed and pre- served in the field in a mixture of ethyl alcohol (70%), glycerine The range of 0. sloanii is limited to southern and (2%), and water (28%). They are currently housed at The Ohio southwestern Ohio (Hobbs 1972), and a further defini- State University at Newark Crayfish Museum (OSUNCM), Newark, Ohio. Forty-five additional collecting sites were added to the study tion of its range is presented herein. Rhoades (1941) by examining catalogued and uncatalogued specimens in The Ohio collected the first 0. sloanii in Ohio from Shakers State University Museum of Zoology (OSUMZ), Columbus, Ohio. Creek, Warren County, in 1938. Additional Ohio speci- The nomenclature of Hobbs (1974) and Fitzpatrick (1987) is mens were collected from Butler, Darke, Hamilton, followed.