Robust Fitting of Parametric Models Based on M-Estimation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 12 Robust Estimation
Lecture 12 Robust Estimation Prof. Dr. Svetlozar Rachev Institute for Statistics and Mathematical Economics University of Karlsruhe Financial Econometrics, Summer Semester 2007 Prof. Dr. Svetlozar Rachev Institute for Statistics and MathematicalLecture Economics 12 Robust University Estimation of Karlsruhe Copyright These lecture-notes cannot be copied and/or distributed without permission. The material is based on the text-book: Financial Econometrics: From Basics to Advanced Modeling Techniques (Wiley-Finance, Frank J. Fabozzi Series) by Svetlozar T. Rachev, Stefan Mittnik, Frank Fabozzi, Sergio M. Focardi,Teo Jaˇsic`. Prof. Dr. Svetlozar Rachev Institute for Statistics and MathematicalLecture Economics 12 Robust University Estimation of Karlsruhe Outline I Robust statistics. I Robust estimators of regressions. I Illustration: robustness of the corporate bond yield spread model. Prof. Dr. Svetlozar Rachev Institute for Statistics and MathematicalLecture Economics 12 Robust University Estimation of Karlsruhe Robust Statistics I Robust statistics addresses the problem of making estimates that are insensitive to small changes in the basic assumptions of the statistical models employed. I The concepts and methods of robust statistics originated in the 1950s. However, the concepts of robust statistics had been used much earlier. I Robust statistics: 1. assesses the changes in estimates due to small changes in the basic assumptions; 2. creates new estimates that are insensitive to small changes in some of the assumptions. I Robust statistics is also useful to separate the contribution of the tails from the contribution of the body of the data. Prof. Dr. Svetlozar Rachev Institute for Statistics and MathematicalLecture Economics 12 Robust University Estimation of Karlsruhe Robust Statistics I Peter Huber observed, that robust, distribution-free, and nonparametrical actually are not closely related properties. -

Nonparametric Statistics for Social and Behavioral Sciences
Statistics Incorporating a hands-on approach, Nonparametric Statistics for Social SOCIAL AND BEHAVIORAL SCIENCES and Behavioral Sciences presents the concepts, principles, and methods NONPARAMETRIC STATISTICS FOR used in performing many nonparametric procedures. It also demonstrates practical applications of the most common nonparametric procedures using IBM’s SPSS software. Emphasizing sound research designs, appropriate statistical analyses, and NONPARAMETRIC accurate interpretations of results, the text: • Explains a conceptual framework for each statistical procedure STATISTICS FOR • Presents examples of relevant research problems, associated research questions, and hypotheses that precede each procedure • Details SPSS paths for conducting various analyses SOCIAL AND • Discusses the interpretations of statistical results and conclusions of the research BEHAVIORAL With minimal coverage of formulas, the book takes a nonmathematical ap- proach to nonparametric data analysis procedures and shows you how they are used in research contexts. Each chapter includes examples, exercises, SCIENCES and SPSS screen shots illustrating steps of the statistical procedures and re- sulting output. About the Author Dr. M. Kraska-Miller is a Mildred Cheshire Fraley Distinguished Professor of Research and Statistics in the Department of Educational Foundations, Leadership, and Technology at Auburn University, where she is also the Interim Director of Research for the Center for Disability Research and Service. Dr. Kraska-Miller is the author of four books on teaching and communications. She has published numerous articles in national and international refereed journals. Her research interests include statistical modeling and applications KRASKA-MILLER of statistics to theoretical concepts, such as motivation; satisfaction in jobs, services, income, and other areas; and needs assessments particularly applicable to special populations. -

Robustness of Parametric and Nonparametric Tests Under Non-Normality for Two Independent Sample
International Journal of Management and Applied Science, ISSN: 2394-7926 Volume-4, Issue-4, Apr.-2018 http://iraj.in ROBUSTNESS OF PARAMETRIC AND NONPARAMETRIC TESTS UNDER NON-NORMALITY FOR TWO INDEPENDENT SAMPLE 1USMAN, M., 2IBRAHIM, N 1Dept of Statistics, Fed. Polytechnic Bali, Taraba State, Dept of Maths and Statistcs, Fed. Polytechnic MubiNigeria E-mail: [email protected] Abstract - Robust statistical methods have been developed for many common problems, such as estimating location, scale and regression parameters. One motivation is to provide methods with good performance when there are small departures from parametric distributions. This study was aimed to investigates the performance oft-test, Mann Whitney U test and Kolmogorov Smirnov test procedures on independent samples from unrelated population, under situations where the basic assumptions of parametric are not met for different sample size. Testing hypothesis on equality of means require assumptions to be made about the format of the data to be employed. Sometimes the test may depend on the assumption that a sample comes from a distribution in a particular family; if there is a doubt, then a non-parametric tests like Mann Whitney U test orKolmogorov Smirnov test is employed. Random samples were simulated from Normal, Uniform, Exponential, Beta and Gamma distributions. The three tests procedures were applied on the simulated data sets at various sample sizes (small and moderate) and their Type I error and power of the test were studied in both situations under study. Keywords - Non-normal,Independent Sample, T-test,Mann Whitney U test and Kolmogorov Smirnov test. I. INTRODUCTION assumptions about your data, but it may also require the data to be an independent random sample4. -

Robust Methods in Biostatistics
Robust Methods in Biostatistics Stephane Heritier The George Institute for International Health, University of Sydney, Australia Eva Cantoni Department of Econometrics, University of Geneva, Switzerland Samuel Copt Merck Serono International, Geneva, Switzerland Maria-Pia Victoria-Feser HEC Section, University of Geneva, Switzerland A John Wiley and Sons, Ltd, Publication Robust Methods in Biostatistics WILEY SERIES IN PROBABILITY AND STATISTICS Established by WALTER A. SHEWHART and SAMUEL S. WILKS Editors David J. Balding, Noel A. C. Cressie, Garrett M. Fitzmaurice, Iain M. Johnstone, Geert Molenberghs, David W. Scott, Adrian F. M. Smith, Ruey S. Tsay, Sanford Weisberg, Harvey Goldstein. Editors Emeriti Vic Barnett, J. Stuart Hunter, Jozef L. Teugels A complete list of the titles in this series appears at the end of this volume. Robust Methods in Biostatistics Stephane Heritier The George Institute for International Health, University of Sydney, Australia Eva Cantoni Department of Econometrics, University of Geneva, Switzerland Samuel Copt Merck Serono International, Geneva, Switzerland Maria-Pia Victoria-Feser HEC Section, University of Geneva, Switzerland A John Wiley and Sons, Ltd, Publication This edition first published 2009 c 2009 John Wiley & Sons Ltd Registered office John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, United Kingdom For details of our global editorial offices, for customer services and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com. The right of the author to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. -

A Guide to Robust Statistical Methods in Neuroscience
A GUIDE TO ROBUST STATISTICAL METHODS IN NEUROSCIENCE Authors: Rand R. Wilcox1∗, Guillaume A. Rousselet2 1. Dept. of Psychology, University of Southern California, Los Angeles, CA 90089-1061, USA 2. Institute of Neuroscience and Psychology, College of Medical, Veterinary and Life Sciences, University of Glasgow, 58 Hillhead Street, G12 8QB, Glasgow, UK ∗ Corresponding author: [email protected] ABSTRACT There is a vast array of new and improved methods for comparing groups and studying associations that offer the potential for substantially increasing power, providing improved control over the probability of a Type I error, and yielding a deeper and more nuanced understanding of data. These new techniques effectively deal with four insights into when and why conventional methods can be unsatisfactory. But for the non-statistician, the vast array of new and improved techniques for comparing groups and studying associations can seem daunting, simply because there are so many new methods that are now available. The paper briefly reviews when and why conventional methods can have relatively low power and yield misleading results. The main goal is to suggest some general guidelines regarding when, how and why certain modern techniques might be used. Keywords: Non-normality, heteroscedasticity, skewed distributions, outliers, curvature. 1 1 Introduction The typical introductory statistics course covers classic methods for comparing groups (e.g., Student's t-test, the ANOVA F test and the Wilcoxon{Mann{Whitney test) and studying associations (e.g., Pearson's correlation and least squares regression). The two-sample Stu- dent's t-test and the ANOVA F test assume that sampling is from normal distributions and that the population variances are identical, which is generally known as the homoscedastic- ity assumption. -

Nonparametric Estimation by Convex Programming
The Annals of Statistics 2009, Vol. 37, No. 5A, 2278–2300 DOI: 10.1214/08-AOS654 c Institute of Mathematical Statistics, 2009 NONPARAMETRIC ESTIMATION BY CONVEX PROGRAMMING By Anatoli B. Juditsky and Arkadi S. Nemirovski1 Universit´eGrenoble I and Georgia Institute of Technology The problem we concentrate on is as follows: given (1) a convex compact set X in Rn, an affine mapping x 7→ A(x), a parametric family {pµ(·)} of probability densities and (2) N i.i.d. observations of the random variable ω, distributed with the density pA(x)(·) for some (unknown) x ∈ X, estimate the value gT x of a given linear form at x. For several families {pµ(·)} with no additional assumptions on X and A, we develop computationally efficient estimation routines which are minimax optimal, within an absolute constant factor. We then apply these routines to recovering x itself in the Euclidean norm. 1. Introduction. The problem we are interested in is essentially as fol- lows: suppose that we are given a convex compact set X in Rn, an affine mapping x A(x) and a parametric family pµ( ) of probability densities. Suppose that7→N i.i.d. observations of the random{ variable· } ω, distributed with the density p ( ) for some (unknown) x X, are available. Our objective A(x) · ∈ is to estimate the value gT x of a given linear form at x. In nonparametric statistics, there exists an immense literature on various versions of this problem (see, e.g., [10, 11, 12, 13, 15, 17, 18, 21, 22, 23, 24, 25, 26, 27, 28] and the references therein). -

Robust Statistical Methods in R Using the WRS2 Package
JSS Journal of Statistical Software MMMMMM YYYY, Volume VV, Issue II. doi: 10.18637/jss.v000.i00 Robust Statistical Methods in R Using the WRS2 Package Patrick Mair Rand Wilcox Harvard University University of Southern California Abstract In this manuscript we present various robust statistical methods popular in the social sciences, and show how to apply them in R using the WRS2 package available on CRAN. We elaborate on robust location measures, and present robust t-test and ANOVA ver- sions for independent and dependent samples, including quantile ANOVA. Furthermore, we present on running interval smoothers as used in robust ANCOVA, strategies for com- paring discrete distributions, robust correlation measures and tests, and robust mediator models. Keywords: robust statistics, robust location measures, robust ANOVA, robust ANCOVA, robust mediation, robust correlation. 1. Introduction Data are rarely normal. Yet many classical approaches in inferential statistics assume nor- mally distributed data, especially when it comes to small samples. For large samples the central limit theorem basically tells us that we do not have to worry too much. Unfortu- nately, things are much more complex than that, especially in the case of prominent, \dan- gerous" normality deviations such as skewed distributions, data with outliers, or heavy-tailed distributions. Before elaborating on consequences of these violations within the context of statistical testing and estimation, let us look at the impact of normality deviations from a purely descriptive angle. It is trivial that the mean can be heavily affected by outliers or highly skewed distribu- tional shapes. Computing the mean on such data would not give us the \typical" participant; it is just not a good location measure to characterize the sample. -

Robustbase: Basic Robust Statistics
Package ‘robustbase’ June 2, 2021 Version 0.93-8 VersionNote Released 0.93-7 on 2021-01-04 to CRAN Date 2021-06-01 Title Basic Robust Statistics URL http://robustbase.r-forge.r-project.org/ Description ``Essential'' Robust Statistics. Tools allowing to analyze data with robust methods. This includes regression methodology including model selections and multivariate statistics where we strive to cover the book ``Robust Statistics, Theory and Methods'' by 'Maronna, Martin and Yohai'; Wiley 2006. Depends R (>= 3.5.0) Imports stats, graphics, utils, methods, DEoptimR Suggests grid, MASS, lattice, boot, cluster, Matrix, robust, fit.models, MPV, xtable, ggplot2, GGally, RColorBrewer, reshape2, sfsmisc, catdata, doParallel, foreach, skewt SuggestsNote mostly only because of vignette graphics and simulation Enhances robustX, rrcov, matrixStats, quantreg, Hmisc EnhancesNote linked to in man/*.Rd LazyData yes NeedsCompilation yes License GPL (>= 2) Author Martin Maechler [aut, cre] (<https://orcid.org/0000-0002-8685-9910>), Peter Rousseeuw [ctb] (Qn and Sn), Christophe Croux [ctb] (Qn and Sn), Valentin Todorov [aut] (most robust Cov), Andreas Ruckstuhl [aut] (nlrob, anova, glmrob), Matias Salibian-Barrera [aut] (lmrob orig.), Tobias Verbeke [ctb, fnd] (mc, adjbox), Manuel Koller [aut] (mc, lmrob, psi-func.), Eduardo L. T. Conceicao [aut] (MM-, tau-, CM-, and MTL- nlrob), Maria Anna di Palma [ctb] (initial version of Comedian) 1 2 R topics documented: Maintainer Martin Maechler <[email protected]> Repository CRAN Date/Publication 2021-06-02 10:20:02 UTC R topics documented: adjbox . .4 adjboxStats . .7 adjOutlyingness . .9 aircraft . 12 airmay . 13 alcohol . 14 ambientNOxCH . 15 Animals2 . 18 anova.glmrob . 19 anova.lmrob . -

Repeated-Measures ANOVA & Friedman Test Using STATCAL
Repeated-Measures ANOVA & Friedman Test Using STATCAL (R) & SPSS Prana Ugiana Gio Download STATCAL in www.statcal.com i CONTENT 1.1 Example of Case 1.2 Explanation of Some Book About Repeated-Measures ANOVA 1.3 Repeated-Measures ANOVA & Friedman Test 1.4 Normality Assumption and Assumption of Equality of Variances (Sphericity) 1.5 Descriptive Statistics Based On SPSS dan STATCAL (R) 1.6 Normality Assumption Test Using Kolmogorov-Smirnov Test Based on SPSS & STATCAL (R) 1.7 Assumption Test of Equality of Variances Using Mauchly Test Based on SPSS & STATCAL (R) 1.8 Repeated-Measures ANOVA Based on SPSS & STATCAL (R) 1.9 Multiple Comparison Test Using Boferroni Test Based on SPSS & STATCAL (R) 1.10 Friedman Test Based on SPSS & STATCAL (R) 1.11 Multiple Comparison Test Using Wilcoxon Test Based on SPSS & STATCAL (R) ii 1.1 Example of Case For example given data of weight of 11 persons before and after consuming medicine of diet for one week, two weeks, three weeks and four week (Table 1.1.1). Tabel 1.1.1 Data of Weight of 11 Persons Weight Name Before One Week Two Weeks Three Weeks Four Weeks A 89.43 85.54 80.45 78.65 75.45 B 85.33 82.34 79.43 76.55 71.35 C 90.86 87.54 85.45 80.54 76.53 D 91.53 87.43 83.43 80.44 77.64 E 90.43 84.45 81.34 78.64 75.43 F 90.52 86.54 85.47 81.44 78.64 G 87.44 83.34 80.54 78.43 77.43 H 89.53 86.45 84.54 81.35 78.43 I 91.34 88.78 85.47 82.43 78.76 J 88.64 84.36 80.66 78.65 77.43 K 89.51 85.68 82.68 79.71 76.5 Average 89.51 85.68 82.68 79.71 76.69 Based on Table 1.1.1: The person whose name is A has initial weight 89,43, after consuming medicine of diet for one week 85,54, two weeks 80,45, three weeks 78,65 and four weeks 75,45. -
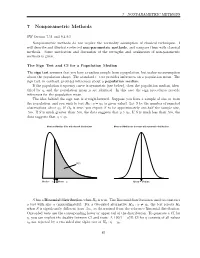
7 Nonparametric Methods
7 NONPARAMETRIC METHODS 7 Nonparametric Methods SW Section 7.11 and 9.4-9.5 Nonparametric methods do not require the normality assumption of classical techniques. I will describe and illustrate selected non-parametric methods, and compare them with classical methods. Some motivation and discussion of the strengths and weaknesses of non-parametric methods is given. The Sign Test and CI for a Population Median The sign test assumes that you have a random sample from a population, but makes no assumption about the population shape. The standard t−test provides inferences on a population mean. The sign test, in contrast, provides inferences about a population median. If the population frequency curve is symmetric (see below), then the population median, iden- tified by η, and the population mean µ are identical. In this case the sign procedures provide inferences for the population mean. The idea behind the sign test is straightforward. Suppose you have a sample of size m from the population, and you wish to test H0 : η = η0 (a given value). Let S be the number of sampled observations above η0. If H0 is true, you expect S to be approximately one-half the sample size, .5m. If S is much greater than .5m, the data suggests that η > η0. If S is much less than .5m, the data suggests that η < η0. Mean and Median differ with skewed distributions Mean and Median are the same with symmetric distributions 50% Median = η Mean = µ Mean = Median S has a Binomial distribution when H0 is true. The Binomial distribution is used to construct a test with size α (approximately). -

9 Blocked Designs
9 Blocked Designs 9.1 Friedman's Test 9.1.1 Application 1: Randomized Complete Block Designs • Assume there are k treatments of interest in an experiment. In Section 8, we considered the k-sample Extension of the Median Test and the Kruskal-Wallis Test to test for any differences in the k treatment medians. • Suppose the experimenter is still concerned with studying the effects of a single factor on a response of interest, but variability from another factor that is not of interest is expected. { Suppose a researcher wants to study the effect of 4 fertilizers on the yield of cotton. The researcher also knows that the soil conditions at the 8 areas for performing an experiment are highly variable. Thus, the researcher wants to design an experiment to detect any differences among the 4 fertilizers on the cotton yield in the presence a \nuisance variable" not of interest (the 8 areas). • Because experimental units can vary greatly with respect to physical characteristics that can also influence the response, the responses from experimental units that receive the same treatment can also vary greatly. • If it is not controlled or accounted for in the data analysis, it can can greatly inflate the experimental variability making it difficult to detect real differences among the k treatments of interest (large Type II error). • If this source of variability can be separated from the treatment effects and the random experimental error, then the sensitivity of the experiment to detect real differences between treatments in increased (i.e., lower the Type II error). • Therefore, the goal is to choose an experimental design in which it is possible to control the effects of a variable not of interest by bringing experimental units that are similar into a group called a \block". -

Robust Statistics in BD Facsdiva™ Software
BD Biosciences Tech Note June 2012 Robust Statistics in BD FACSDiva™ Software Robust Statistics in BD FACSDiva™ Software Robust statistics defined Robust statistics provide an alternative approach to classical statistical estimators such as mean, standard deviation (SD), and percent coefficient of variation (%CV). These alternative procedures are more resistant to the statistical influences of outlying events in a sample population—hence the term “robust.” Real data sets often contain gross outliers, and it is impractical to systematically attempt to remove all outliers by gating procedures or other rule sets. The robust equivalent of the mean statistic is the median. The robust SD is designated rSD and the percent robust CV is designated %rCV. For perfectly normal distributions, classical and robust statistics give the same results. How robust statistics are calculated in BD FACSDiva™ software Median The mean, or average, is the sum of all the values divided by the number of values. For example, the mean of the values of [13, 10, 11, 12, 114] is 160 ÷ 5 = 32. If the outlier value of 114 is excluded, the mean is 11.5. The median is defined as the midpoint, or the 50th percentile of the values. It is the statistical center of the population. Half the values should be above the median and half below. In the previous example, the median is 12 (13 and 114 are above; 10 and 11 are below). Note that this is close to the mean with the outlier excluded. Robust standard deviation (rSD) The classical SD is a function of the deviation of individual data points to the mean of the population.