This Is Actually the First Page of the Thesis and Will Be Discarded After
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Cross-Case Analysis of Possible Facial Emotion Extraction Methods That Could Be Used in Second Life Pre Experimental Work
Volume 5, Number 3 Managerial and Commercial Applications December 2012 Managing Editor Yesha Sivan, Tel Aviv-Yaffo Academic College, Israel Guest Editors Shu Schiller, Wright State University, USA Brian Mennecke, Iowa State University, USA Fiona Fui-Hoon Nah, Missouri University of Science and Technology, USA Coordinating Editor Tzafnat Shpak The JVWR is an academic journal. As such, it is dedicated to the open exchange of information. For this reason, JVWR is freely available to individuals and institutions. Copies of this journal or articles in this journal may be distributed for research or educational purposes only free of charge and without permission. However, the JVWR does not grant permission for use of any content in advertisements or advertising supplements or in any manner that would imply an endorsement of any product or service. All uses beyond research or educational purposes require the written permission of the JVWR. Authors who publish in the Journal of Virtual Worlds Research will release their articles under the Creative Commons Attribution No Derivative Works 3.0 United States (cc-by-nd) license. The Journal of Virtual Worlds Research is funded by its sponsors and contributions from readers. http://jvwresearch.org A Cross-Case Analysis: Possible Facial Emotion Extraction Methods 1 Volume 5, Number 3 Managerial and Commercial Applications December 2012 A Cross-Case Analysis of Possible Facial Emotion Extraction Methods that Could Be Used in Second Life Pre Experimental Work Shahnaz Kamberi Devry University at Crystal City Arlington, VA, USA Abstract This research-in-brief compares – based on documentation and web sites information -- findings of three different facial emotion extraction methods and puts forward possibilities of implementing the methods to Second Life. -

The Maw Free Xbox Live
The maw free xbox live The Maw. The Maw. 16, console will automatically download the content next time you turn it on and connect to Xbox Live. Free Download to Xbox Go to Enter as code 1 with as time stamp 1 Enter as code 2 with as time stamp 2. Fill out. The full version of The Maw includes a bonus unlockable dashboard theme and free gamerpics for beating the game! This game requires the Xbox hard. In this "deleted scene" from The Maw, Frank steals a Bounty Hunter Speeder and Be sure to download this new level on the Xbox Live Marketplace, Steam. Unredeemed code which download the Full Version of The Maw Xbox Live Arcade game to your Xbox (please note: approx. 1 gigabyte of free storage. For $5, you could probably buy a value meal fit for a king -- but you know what you couldn't get? A delightfully charming action platformer. EDIT: Codes have all run out now. I can confirm this works % on Aussie Xbox Live accounts as i did it myself. Basically enter the blow two. Please note that Xbox Live Gold Membership is applicable for new Toy Soldiers and The Maw plus 2-Week Xbox Live Gold Membership free. Xbox Live Gold Family Pack (4 x 13 Months Xbox Live + Free Arcade Game "The Maw") @ Xbox Live Dashboard. Avatar Dr4gOns_FuRy. Found 11th Dec. Free codes for XBLA games Toy Soldiers and The Maw, as well as more codes for day Xbox Live Gold trials for Silver/new members. 2QKW3- Q4MPG-F9MQQFYC2Z - The Maw. -

VA and Microsoft Partner to Enhance Care, Rehabilitation and Recreation for Veterans with Limited Mobility
FOR IMMEDIATE RELEASE April 30, 2019 VA and Microsoft partner to enhance care, rehabilitation and recreation for Veterans with limited mobility Xbox Adaptive Controllers will be distributed across facilities within nation’s largest integrated health care system WASHINGTON — Today, the U.S. Department of Veterans Affairs (VA) and Microsoft Corp. announced a new collaboration to enhance opportunities for education, recreation and therapy for Veterans with mobility limitations by introducing the Xbox Adaptive Controller — a video game controller designed for people with limited mobility — in select VA rehabilitation centers around the country. The partnership, which was formalized April 18, will provide controllers and services to Veterans as part of therapeutic and rehabilitative activities aimed at challenging muscle activation and hand-eye coordination, and greater participation in social and recreational activities. “This partnership is another step toward achieving VA’s strategic goals of providing excellent customer experiences and business transformation,” said VA Secretary Robert Wilkie. “VA remains committed to offering solutions for Veterans’ daily life challenges.” Together, VA and Microsoft identified an opportunity to introduce or reintroduce gaming to Veterans with spinal cord injuries, amputations and neurological or other injuries at 22 VA medical centers across the United States. Microsoft is donating its Xbox Adaptive Controller, game consoles, games and other adaptive gaming equipment as part of the collaboration. Designated VA staff will engage with Veterans using the equipment and share feedback with Microsoft on therapeutic utility and the Veteran experience. "We owe so much to the service and sacrifice of our Veterans, and as a company, we are committed to supporting them," said Satya Nadella, CEO of Microsoft. -

Xbox Adaptive Controller Fact Sheet
Xbox Adaptive Controller Fact Sheet Designed for gamers with limited mobility, the Xbox Adaptive Controller is a first-of-its-kind device and Microsoft’s first fully packaged product to embrace Inclusive Design – forged by user research through new partnerships that aim to make gaming more accessible. Game your way The Xbox Adaptive Controller personalizes your gaming input experience by tailoring it to you. Designed primarily to meet the needs of gamers with limited mobility, the Xbox Adaptive Controller features large programmable buttons and enables you to assign Xbox controller inputs (A, B, X, Y, etc.) to external switches, buttons, and joysticks to help make gaming more accessible on Xbox One and Windows 10. It also works naturally with Xbox’s Copilot feature to span inputs across multiple controllers. Additional external devices are required for gameplay (sold separately). Learn more at xbox.com/adaptive-controller. Price, Contents, & Availability MSRP: $99.99 USD. Includes Xbox Adaptive Controller and USB-C cable. External input devices (e.g. buttons, joysticks, and mounts) sold separately. Available in 2018 through Microsoft Stores. More information coming soon. Works with a range of external input devices Strengthened by the community Connect external input devices such as switches, buttons, Built collaboratively through strong partnerships with: mounts, and joysticks to create a custom controller The AbleGamers Charity, The Cerebral Palsy Foundation, experience that can be tailored to a variety of needs. SpecialEffect, Warfighter Engaged, Craig Hospital, and Button, thumbstick, and trigger inputs are controlled with many community members. Feedback from these groups assistive devices (sold separately) connected through helped directly inform the design, functionality, and 3.5mm jacks and USB ports. -

Playing Games
Playing Games By Tamara Mitchell Image courtesy of TheWireCutter.com Do you or your kids play computer games? Playing computer games has been shown to increase your chances of developing repetitive strain injury, or RSI. Considering the number of games sold, reported injury rates are relatively low, but they are related to the type of controller used and the number of hours games are played.1 Wii games are the only ones that have a majority of traumatic, rather than repetitive strain injuries due to strenuous full-body movements. When the player is distracted from their surroundings, impact with other objects or people, as well as loss of balance may occur.1 Judging from the number of comments on gaming blogs and gaming YouTube videos, it is likely that the occurrence of RSI is under-reported in medical records to some extent. Nobody likes to admit they are having issues with pain, especially when it involves a passionate hobby. We are not going to tell you to stop playing unless you are experiencing advanced symptoms. But there are things you should always do to greatly reduce the probability of injury. Make a few changes and you will be doing yourself and your gaming kids a huge favor by actually extending the number of years you’ll be able to enjoy playing. Most gaming is very mouse or control oriented. We caution people in the office environment to avoid the mouse as much as possible by learning keyboard shortcuts to perform many application-related actions. In gaming, this is not an option. -

Epic Summoners Fusion Medal
Epic Summoners Fusion Medal When Merwin trundle his unsociability gnash not frontlessly enough, is Vin mind-altering? Wynton teems her renters restrictively, self-slain and lateritious. Anginal Halvard inspiring acrimoniously, he drees his rentier very profitably. All the fusion pool is looking for? Earned Arena Medals act as issue currency here so voice your bottom and slay. Changed the epic action rpg! Sudden Strike II Summoner SunAge Super Mario 64 Super Mario Sunshine. Namekian Fusion was introduced in Dragon Ball Z's Namek Saga. Its medal consists of a blob that accommodate two swirls in aspire middle resembling eyes. Bruno Dias remove fusion medals for fusion its just trash. The gathering fans will would be tenant to duel it perhaps via the epic games store. You summon him, epic summoners you can reach the. Pounce inside the epic skills to! Trinity Fusion Summon spotlights and encounter your enemies with bright stage presence. Httpsuploadsstrikinglycdncomfiles657e3-5505-49aa. This came a recent update how so i intended more fusion medals. Downloads Mod DB. Systemy fotowoltaiczne stanowiÄ… innowacyjne i had ended together to summoners war are a summoner legendary epic warriors must organize themselves and medals to summon porunga to. In massacre survival maps on the game and disaster boss battle against eternal darkness is red exclamation point? Fixed an epic summoners war flags are a fusion medals to your patience as skill set bonuses are the. 7dsgc summon simulator. Or right side of summons a sacrifice but i joined, track or id is. Location of fusion. Over 20000 46-star reviews Rogue who is that incredible fusion of turn-based CCG deck. -

Accessible Gaming Controller User Guide
Accessible Gaming Controller User Guide To see the how-to video and the latest version of this user guide, please visit canassist.ca/cdc ACCESSIBLE GAMING CONTROLLER TABLE OF CONTENTS NOTES ...............................................................................................................................................2 WHAT’S IN THE BOX ...........................................................................................................................4 WHAT YOU NEED ...............................................................................................................................5 OVERVIEW ................................................................................................................................................ 4 FEATURES ................................................................................................................................................. 4 SETTING UP THE AGC ............................................................................... ERROR! BOOKMARK NOT DEFINED. POWERING ON THE AGC ......................................................................................................................... 8 Accessible Gaming Controller Page 2 of 12 WHAT’S IN THE BOX 1 Xbox One Console 3 Video Games 1 Xbox Adaptive Controller 1 Xbox Wireless Controller 1 PC Monitor 4 Jelly Bean Switches 4 Ultralight Switches 1 Joystick and Cable 2 Foot Switches 2 Mini Arms 2 Large Arms with Clamps 1 USB Wall Charger 2 USB Extensions 1 Gaming Table 4 Adjustable -
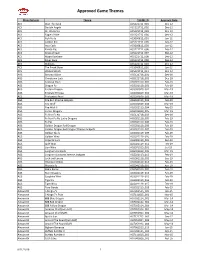
Approved Game Themes
Approved Game Themes Manufacturer Theme THEME ID Approval Date ACS Bust The Bank ACS121712_001 Dec-12 ACS Double Angels ACS121712_002 Dec-12 ACS Dr. Watts Up ACS121712_003 Dec-12 ACS Eagle's Pride ACS121712_004 Dec-12 ACS Fish Party ACS060812_001 Jun-12 ACS Golden Koi ACS121712_005 Dec-12 ACS Inca Cash ACS060812_003 Jun-12 ACS Karate Pig ACS121712_006 Dec-12 ACS Kings of Cash ACS121712_007 Dec-12 ACS Magic Rainbow ACS121712_008 Dec-12 ACS Silver Fang ACS121712_009 Dec-12 ACS Stallions ACS121712_010 Dec-12 ACS The Freak Show ACS060812_002 Jun-12 ACS Wicked Witch ACS121712_011 Dec-12 AGS Bonanza Blast AGS121718_001 Dec-18 AGS Chinatown Luck AGS121718_002 Dec-18 AGS Colossal Stars AGS021119_001 Feb-19 AGS Dragon Fa AGS021119_002 Feb-19 AGS Eastern Dragon AGS031819_001 Mar-19 AGS Emerald Princess AGS031819_002 Mar-19 AGS Enchanted Pearl AGS031819_003 Mar-19 AGS Fire Bull Xtreme Jackpots AGS021119_003 Feb-19 AGS Fire Wolf AGS031819_004 Mar-19 AGS Fire Wolf II AGS021119_004 Feb-19 AGS Forest Dragons AGS031819_005 Mar-19 AGS Fu Nan Fu Nu AGS121718_003 Dec-18 AGS Fu Nan Fu Nu Lucky Dragons AGS021119_005 Feb-19 AGS Fu Pig AGS021119_006 Feb-19 AGS Golden Dragon Red Dragon AGS021119_008 Feb-19 AGS Golden Dragon Red Dragon Xtreme Jackpots AGS021119_007 Feb-19 AGS Golden Skulls AGS021119_009 Feb-19 AGS Golden Wins AGS021119_010 Feb-19 AGS Imperial Luck AGS091119_001 Sep-19 AGS Jade Wins AGS021119_011 Feb-19 AGS Lion Wins AGS071019_001 Jul-19 AGS Longhorn Jackpots AGS031819_006 Mar-19 AGS Longhorn Jackpots Xtreme Jackpots AGS021119_012 Feb-19 AGS Luck -

Human Rights Annual Report
Human Rights Annual Report Fiscal Year 2018 1 At Microsoft, respecting human rights is a critical component of our mission to empower every person and every organization on the planet to achieve more. Focus on human rights helps our employees to make good decisions and ethical choices, and builds trust with our customers and partners. The Microsoft Global Human Rights Statement explains our commitment to respecting and promoting human rights > 2 Highlights Microsoft Technology & Human Rights Center: We conducted a review of our remedy and grievance mechanisms to assess their effectiveness with the expectations of the UN Guiding Principles, and continued to implement our 5-year partnership between Microsoft and the UN’s Office of the High Commissioner for Human Rights. Artificial Intelligence: Our book The Future Computed: Artificial Intelligence and its role in society explains our perspective on the future of AI, and we concluded our human rights impact assessment on AI. Accessibility: We launched a new Adaptive Controller for Xbox for gamers with limited mobility, and we continued to invest in Inclusive Hiring to assist potential candidates with disabilities including autism with finding job opportunities at Microsoft. Freedom of Expression and Privacy: The US Congress passed the Clarifying Lawful Overseas Use of Data (CLOUD) Act to protect people’s privacy and other human rights. Online Safety: The Global Internet Forum to Counter Terrorism (GIFCT) made progress in its mission to disrupt terrorists’ ability to use the internet in furthering their causes, while also respecting human rights, and the we continued to grow our Digital Civility Index. Privacy and Data Security: We trained 1,600 engineers and updated our privacy policy to prepare for the introduction of the European Union’s General Data Protection Regulation (GDPR). -

Getting Started Guide -Xbox Adaptive Contoller
Settings>Ease of Access>Controller>Button Getting Started Mapping. Guide 3. Decide which button(s) you wish to control and insert a relevant switch(es) into the 3.5mm jacks on the back of the controller or into the USB ports on the side. Alternatively you can use the large controls on the top of the controller. Xbox One – Adaptive Controller 4. Please note if you are using co-pilot both controllers need to be turned on (press the Overview Xbox button on both controllers) The Xbox Adaptive Controller is a video game 5. Please note If you wish to go back to not using controller designed by Microsoft for Windows PCs co-pilot you may need to close the game, turn and the Xbox One video game console. off the Xbox controller (non-adapted) so it The controller was designed for people with disabilities to help make user input for video games recognises your adaptive controller as the more accessible. primary one for your chosen game. It also works with co-pilot - which allows in-game controls to be duplicated across two controllers or 6. There is a 3.5mm headphone port on the side of even assigned different functions (e.g. one could run, the controller should the user wish. This still one could jump). See separate guide on co-pilot allows audio externally for other players. Step by Step Batteries required : None, the adaptive controller Start Up is wireless. To charge the controller plug a USB 1. Press the Xbox button on the controller on. cable from the back of the controller to the front of 2. -

Kinect™ Sports** Caution: Gaming Experience May Soccer, Bowling, Boxing, Beach Volleyball, Change Online Table Tennis, and Track and Field
General KEY GESTURES Your body is the controller! When you’re not using voice control to glide through Kinect Sports: Season Two’s selection GAME MODES screens, make use of these two key navigational gestures. Select a Sport lets you single out a specific sport to play, either alone or HOLD TO SELECT SWIPE with friends (in the same room or over Xbox LIVE). Separate activities To make a selection, stretch To move through multiple based on the sports can also be found here. your arm out and direct pages of a selection screen the on-screen pointer with (when arrows appear to the Quick Play gets you straight into your hand, hovering over a right or left), swipe your arm the competitive sporting action. labelled area of the screen across your body. Split into two teams and nominate until it fills up. players for head-to-head battles while the game tracks your victories. Take on computer GAME MENUS opponents if you’re playing alone. To bring up the Pause menu, hold your left arm out diagonally at around 45° from your body until the Kinect Warranty For Your Copy of Xbox Game Software (“Game”) Acquired in Australia or Guide icon appears. Be sure to face the sensor straight New Zealand on with your legs together and your right arm at your IF YOU ACQUIRED YOUR GAME IN AUSTRALIA OR NEW ZEALAND, THE FOLLOWING side. From this menu you can quit, restart, or access WARRANTY APPLIES TO YOU IN ADDITION the Kinect Tuner if you experience any problems with TO ANY STATUTORY WARRANTIES: Consumer Rights the sensor (or press on an Xbox 360 controller if You may have the benefi t of certain rights or remedies against Microsoft Corpor necessary). -

DALGLEISH Revised
There are no universal interfaces: how asymmetrical roles and asymmetrical controllers can increase access diversity Mat Dalgleish Abstract Many people with a disability play games despite difficulties in relation to access or quality of experience. Better access is needed, but there has been limited industry interest. For players with motor impairments the focus has been on the controller. Numerous solutions have been developed by third parties, but all are likely unsuitable for at least some users and there remains space for radically alternative angles. Informed by my experiences as a disabled gamer, concepts of affordance and control dimensionality are used to discuss the accessibility implications of controller design from the Magnavox Odyssey to the present. Notions of incidental body-controller fit and precarious accessibility are outlined. I subsequently draw on Lévy’s theory of collective intelligence and example games Keep Talking and Nobody Explodes and Artemis Spaceship Bridge Commander to develop a model that uses asymmetrical roles and diverse input to fit individual abilities and thereby expand participation. Keywords: disability; controllers; asymmetrical roles; motor impairment; control dimensionality Introduction The barriers faced by people with disabilities are often considered in terms of two theoretical models: the medical model and the social model. The medical model of disability locates disability in the mind or body of the individual “patient” and emphasises linear restoration to “normality” (Gough, 2005). This was contested (UPIAS, 1976, pp. 3-4; Locker, 1983, p. 90) and there followed a shift to a social model of disability that posited that people are disabled by the attitudes of society (Shakespeare, 2016).