Risk Management in the Australian Stockmarket Using Artificial Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Name of the AMC : IIFL ASSET MANAGEMENT LIMITED All Figures
Name of the AMC : IIFL ASSET MANAGEMENT LIMITED All figures - Rs. in Lacs Sr. No. ARN Name of the ARN Holder Total Commission Total Expenses Total Commission + Gross Inflows Net Inflows Whether the Averge Assets under AUM as on Ratio of paid during paid during Expenses paid during distributor is an Management for FY 31-Mar-2019 AUM to FY 2018-19 FY 2018-19 FY 2018-19 associate or group 2018-19 Gross compnay of the Inflows sponsors of the Mutual Fund A B A+B 1 1 BNP Paribas - - - - - - - - 2 2 JM Financial Services Limited 0.01 - 0.01 3.73 3.73 1.52 4.01 1.08 3 5 HDFC Bank Limited - - - - - - - - 4 6 SKP Securities Limited - - - - - - - - 5 7 SPA Capital Services Limited - - - - - - - - 6 9 Way2Wealth Securities Private Limited - - - 2.52 2.52 1.92 2.61 1.04 7 10 Bajaj Capital Ltd. 6.44 - 6.44 540.91 540.29 479.55 564.07 1.04 8 11 SBICAP Securities Limited - - - - - - - - 9 14 Shubhangi Gopal Pai - - - - - - - - 10 16 Bluechip Corporate Investment Centre Ltd - - - - - - - - 11 17 Stock Holding Corporation of India Limited - - - - - - - - 12 18 Karvy Stock Broking Limited 12.23 - 12.23 1,435.72 981.98 915.16 1,022.93 0.71 13 19 Axis Bank Limited 0.08 - 0.08 10.03 10.03 6.43 10.42 1.04 14 20 ICICI Bank Limited 42.05 - 42.05 4,078.27 4,020.20 3,612.52 4,189.04 1.03 15 21 Tata Securities Limited - - - - - - - - 16 22 Hongkong & Shanghai Banking Corporation Ltd. -

Copyrighted Material
Index “A Bust to the Markets” Axis Financial Services (money (Archer), 361 manager), 353 “A Conversation with the Gnomes” (Archer and Treuren), 257 Baby markets, 355 Account types, 107, 109 Baby Pips, 133 Advisory services, 143–144 Back-testing, 345–346, 359 Agent computing, 361 Backup computers, 112 Algorithmic trading, 363 Baht, 333, 334 American style option, 326 Balance of trade, 178–179 AnalyzerXL, 141 Ballooning (pip) spreads, 84, 93, Anti-hedging, 40 111, 190, 334 Anti-hedging regulations, 116. Bands, 11 See also National Futures Bank lot size, 9 Association (NFA) Bank lots, 59 Application program interface Banking hours, 319 (API), 358 Bar charts, 150–152 Application service providers Barron’s, 95 (ASPs), 359 Base currency, 48–49, 67 Archer, Michael Duane, 257, Basic market paradigm (BMP), 361, 363 234–236, 257, 320 Artificial intelligence (AI), 362 Bathtub analysis, 234, 273–274, 280 Asian session, 8 Bear market, 11 “A Simple Cellular Automata Bear swings, 316 Model forCOPYRIGHTED Predicting FX Beginning MATERIAL point (BP), 239, 266 Prices” (Archer), 363 Belgian dentist, 256 Ask price, 29, 52 Bernanke, Ben, 19 ATC brokers, 106 Best FX Trader (money manager), 353 AUDUSD example, 255 Beyond Candlesticks: More Japanese Australian Dollar (AUD), 4 Charting Techniques Revealed Automated order entry, 130 (Nison), 159 Automated trading method, 341 Bickford, James L. “Jim,” 10, 83, 85, Automated trading system, 339, 340 88, 169, 183, 191, 225, 234, Automatic trailing stops, 119 314, 363 405 bindex.indd 405 4/10/2012 4:45:45 PM 406 INDEX Bid price, 29, 52 Central clearinghouse, 16 Bid-ask spread, 13, 52, 117, 368 Centralized exchange, 4 Biofeedback, 211–213, 218, 293, 320 CFTC. -

Integrating Neurally Enhanced Fundamental Analysis, Technical Analysis and Corporate Governance in the Context of a Stock Market Trading System
Fusion Analysis: Integrating Neurally Enhanced Fundamental Analysis, Technical Analysis and Corporate Governance in the Context of a Stock Market Trading System Safwan Mohd Nor DiA (UiTM), BA (Hons) AFS (UCLan), MFA (LTU), CFTP Thesis submitted in fulfilment of the requirements for the degree of Doctor of Philosophy Finance and Financial Services Discipline Group College of Business Victoria University, Melbourne 2014 Abstract This thesis examines the trading performance of a novel fusion strategy that amalgamates neurally enhanced financial statement analysis (traditional fundamental analysis), corporate governance analysis (new fundamental research) and technical analysis in the context of a full-fledged stock market trading system. In doing so, we build and investigate the trading ability of five mechanical trading systems: (1) (traditional) fundamental analysis; (2) corporate governance analysis; (3) technical analysis; (4) classical fusion analysis (a hybrid of only fundamental and technical rules) and (5) novel fusion analysis (a hybrid of fundamental, corporate governance and technical rules) in an emerging stock market, the Bursa Malaysia. To construct the full-fledged trading systems, we employ a backpropagation algorithm in enhancing buy/sell rules, and also include anti-Martingale (position sizing) and stop loss (risk management) strategies. In providing valid empirical results, we compare the trading performance of each trading system using out-of-sample analysis in the presence of a realistic budget, sample portfolio, short selling restriction, round lot constraint and transaction cost. The effects of data snooping, survivorship and look-ahead biases are also addressed and mitigated. The results show that all the trading systems produce significant returns and are able to outperform the benchmark buy-and-hold strategy. -

THIN FILM ELECTRONICS ASA (A Norwegian Public Limited Liability Company Organized Under the Laws of Norway with Business Registration Number 889 186 232)
THIN FILM ELECTRONICS ASA (a Norwegian public limited liability company organized under the laws of Norway with business registration number 889 186 232) Listing of 68,922,869 Private Placement Shares issued in a Private Placement Listing of up to 679,182,172 Warrant Shares in connection with the potential exercise of Warrants B and Warrants C (collectively the “Warrants”) The information contained in this prospectus (the “Prospectus”) relates to (i) the listing on Oslo Børs, a stock exchange operated by Oslo Børs ASA (the “Oslo Børs”), of 68,922,869 new shares (the “Private Placement Shares”), at a subscription price of NOK 0.82 per Private Placement Share (the “Subscription Price”), each with a nominal value of NOK 0.11, in Thin Film Electronics ASA (“Thinfilm” or the “Company”, and together with its consolidated subsidiaries, the “Group”), issued in a private placement directed towards certain investors for gross proceeds of approximately NOK 56.5 million (the “Private Placement”), and (ii) the listing of up to 679,182,172 shares on Oslo Børs issued in connection with exercise of Warrants B and Warrants C (the “Warrant Shares”), at an exercise price of NOK 0.25 per Warrant Share (the “Exercise Price”), each with a nominal value of NOK 0.11. The Private Placement Shares and the Warrant Shares will collectively be referred to as the “New Shares”. The Private Placement Shares were issued by a resolution by the Company’s Board of Directors (the “Board”) on 1 March 2021, pursuant to an authorization from the Extraordinary General Meeting on 19 August 2020. -

Getting Started in CURRENCY TRADING
FM.qxd 5/6/08 3:08 PM Page i Getting Started in CURRENCY TRADING SECOND EDITION Winning in Today’s Hottest Marketplace Michael Duane Archer John Wiley & Sons, Inc. FM.qxd 5/6/08 3:08 PM Page iv FM.qxd 5/6/08 3:08 PM Page i Getting Started in CURRENCY TRADING SECOND EDITION Winning in Today’s Hottest Marketplace Michael Duane Archer John Wiley & Sons, Inc. FM.qxd 5/6/08 3:08 PM Page ii Copyright © 2008 by Michael D. Archer. All rights reserved Published by John Wiley & Sons, Inc., Hoboken, New Jersey Published simultaneously in Canada A first edition of this book was co-authored by Michael D. Archer and Jim L. Bickford and published by John Wiley & Sons, Inc. in 2005. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Dan- vers, MA 01923, (978) 750-8400, fax (978) 750-4470, or on the web at www.copyright.com. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at http://www.wiley.com/go/permissions. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the ac- curacy or completeness of the contents of this book and specifically disclaim any implied war- ranties of merchantability or fitness for a particular purpose. -

Commission to Distributors for FY 2019-20 Website
Name of the AMC : Mirae Asset Investment Managers (India) Private Limited All figures - Rs. in Lacs Sr. No. ARN Name of the ARN Holder Total Commission Total Expenses Total Commission + Gross Inflows Net Inflows Whether the Averge Assets under AUM as on Ratio of AUM to paid during paid during Expenses paid distributor is an Management for FY 2019- 31-Mar-2020 gross inflows FY 2019-20 FY 2019-20 during FY 2019-20 associate or 20 (AUM as on group company March 31, of the sponsors of 2020/Gross the Mutual Fund Inflows for FY 2019-20) A B A+B 1 2 JM Financial Services Limited 65.93 - 65.93 11,434.51 445.97 No 9,104.59 7,916.09 0.69 2 5 HDFC Bank Limited 108.24 - 108.24 16,839.27 8,889.71 No 30,912.59 26,978.43 1.60 3 6 SKP Securities Limited 14.43 - 14.43 1,367.59 874.94 No 2,203.19 1,908.60 1.40 4 7 SPA Capital Services Limited 17.49 - 17.49 969.33 -462.14 No 2,077.20 1,726.76 1.78 5 9 Way2Wealth Securities Private Limited 6.60 - 6.60 764.04 514.75 No 887.01 809.96 1.06 6 10 Bajaj Capital Ltd. 252.73 - 252.73 14,093.14 8,804.10 No 22,564.16 21,190.08 1.50 7 11SBICAP Securities Limited 2.75 - 2.75 448.13 370.57 No 330.42 422.26 0.94 8 14 Shubhangi Gopal Pai 2.05 - 2.05 341.53 324.02 No 227.52 309.91 0.91 9 16 Bluechip Corporate Investment Centre Ltd 19.21 - 19.21 2,269.94 1,739.34 No 3,293.27 3,264.52 1.44 10 17 Stock Holding Corporation of India Limited 21.07 - 21.07 1,249.06 670.33 No 2,353.49 2,088.82 1.67 11 18 Karvy Stock Broking Limited 187.06 - 187.06 12,877.97 8,103.60 No 19,726.40 16,913.39 1.31 12 19 Axis Bank Limited 12.84 - 12.84 8,904.84 7,551.84 No 2,292.88 6,601.85 0.74 13 20 ICICI Bank Limited 143.61 - 143.61 26,473.17 20,543.75 No 16,455.08 21,143.47 0.80 14 21 Tata Securities Limited 0.30 - 0.30 21,511.36 4.29 No 148.32 43.76 0.00 15 22 Hongkong & Shanghai Banking Corporation Ltd. -

2019Annual Report “Through Clients’ Eyes” Means That We Constantly Strive to Make Decisions That Best Serve Our Clients
2019Annual Report “Through Clients’ Eyes” means that we constantly strive to make decisions that best serve our clients. The Charles Schwab Corporation (NYSE: SCHW) is an investing services firm with a history of innovating and advocating for individual investors and the advisors and institutions who serve them. In addition to historical information, this Annual Report to Stockholders contains “forward-looking statements,” which are identified by words such as “believe,” “expect,” “will,” “may,” “would,” “could,” “should,” “growth,” “build,” “deliver,” “continue,” “remain,” “can,” “drive,” “potential,” “lead,” “position,” “target,” “record,” “investment,” “opportunity,” “objective,” “ensure,” “ongoing,” “are,” “aim,” “anticipate,” “maintain,” “commitment,” “project,” and other similar expressions. In addition, any statements that refer to expectations, projections, or other characterizations of future events or circumstances are forward-looking statements. These forward- looking statements, which reflect management’s beliefs, objectives, and expectations as of the date hereof, are estimates based on the best judgment of the company’s senior management. These statements relate to, among other things: stockholder value and rewards; growth in the company’s client base, accounts, assets, revenues, earnings and profits; investments to fuel and support growth, serve clients, and drive scale and efficiency; operating efficiency; the acquisition of certain assets of USAA’s Investment Management Company, including the related referral agreement, -
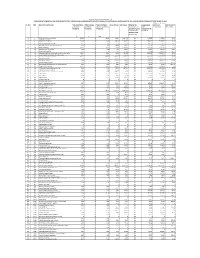
2020-2021 in Accordance with Sebi Circular No
Principal Asset Management Pvt. Ltd. DISCLOSURE OF COMMISSION PAID TO DISTRIBUTORS FOR F.Y.2020-2021 IN ACCORDANCE WITH SEBI CIRCULAR NO. CIR/IMD/DF/13/2011 DATED AUGUST 22, 2011 AND CIR/IMD/DF/21/2012 DATED SEPTEMBER 13, 2012 All figures - Rs. in Lacs Sr. No. ARN Name of the ARN Holder Total Commission Total Expenses Total Commission + Gross Inflows Net Inflows Whether the Averge Assets AUM as on Ratio of Aum to paid during paid during Expenses paid during distributor is an under 31-Mar-2021 Gross Inflows FY 2020-21 FY 2020-21 FY 2019-20 associate or group Management for compnay of the FY 2020-21 sponsors of the Mutual Fund A B A+B 1 2 JM Financial Services Limited 89.61 0 89.61 736.97 -2,547.92 No 7,780.28 7,728.67 10.49 2 5 HDFC Bank Limited 87.76 0 87.76 787.02 -1,626.68 No 8,610.57 9,686.94 12.31 3 6 SKP Securities Limited 2.99 0 2.99 148.60 82.74 No 339.97 480.76 3.24 4 7 SPA Capital Services Limited 3.61 0 3.61 42.15 -29.39 No 398.53 449.51 10.67 5 9 Way2Wealth Securities Private Limited 4.99 0 4.99 104.48 -30.47 No 551.31 653.95 6.26 6 10 Bajaj Capital Ltd. 53.45 0 53.45 746.92 -1,009.05 No 5,027.91 5,407.76 7.24 7 11 SBICAP Securities Limited 1.49 0 1.49 7.26 -10.51 No 127.91 149.13 20.54 8 14 Shubhangi Gopal Pai 1.12 0 1.12 1.06 -17.08 No 84.30 100.27 94.15 9 16 Bluechip Corporate Investment Centre Private limited 12.07 0 12.07 90.34 -207.28 No 2,432.41 2,803.91 31.04 10 17 Stock Holding Corporation of India Limited 3.86 0 3.86 37.54 -44.56 No 455.73 516.48 13.76 11 18 Karvy Stock Broking Limited 100.23 0 100.23 1,289.36 -1,969.74 No 9,807.19 10,350.53 8.03 12 19 Axis Bank Limited 1.41 0 1.41 142.07 56.33 No 686.91 942.52 6.63 13 20 ICICI Bank Limited 1.44 0 1.44 15.92 -102.44 No 1,214.63 1,462.13 91.86 14 21 Tata Securities Limited 0.16 0 0.16 0.83 -2.06 No 116.52 138.01 166.57 15 22 Hongkong & Shanghai Banking Corporation Ltd. -

Intermarket Trading Strategies
visit for more: http://trott.tv Your Source For Knowledge P1: JYS FM JWBK304-Katsanos November 22, 2008 14:21 Printer: Yet to come To my wife Erifili v P1: JYS FM JWBK304-Katsanos November 22, 2008 14:21 Printer: Yet to come Intermarket Trading Strategies i P1: JYS FM JWBK304-Katsanos November 22, 2008 14:21 Printer: Yet to come For other titles in the Wiley Trading Series please see www.wiley.com/finance ii P1: JYS FM JWBK304-Katsanos November 22, 2008 14:21 Printer: Yet to come INTERMARKET TRADING STRATEGIES Markos Katsanos A John Wiley and Sons, Ltd., Publication iii P1: JYS FM JWBK304-Katsanos November 22, 2008 14:21 Printer: Yet to come Copyright C 2008 Markos Katsanos Published by John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England Telephone (+44) 1243 779777 Email (for orders and customer service enquiries): [email protected] Visit our Home Page on www.wiley.com All Rights Reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except under the terms of the Copyright, Designs and Patents Act 1988 or under the terms of a licence issued by the Copyright Licensing Agency Ltd, Saffron House, 6–10 Kirby Street, London, ECIN 8TS, UK, without the permission in writing of the Publisher. Requests to the Publisher should be addressed to the Permissions Department, John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England, or emailed to [email protected], or faxed to (+44) 1243 770620. -

The Rise of Wealthtech
WWW.DRAKESTAR.COM JULY 2020 Sector Report THE RISE OF WEALTHTECH Julian Ostertag, Managing Partner and Christophe Morvan, Managing Partner Member of the Executive Committee [email protected] [email protected] +33 1700 876 10 +49 89 1490 265 20 Michael Metzger, Partner Antonia Georgieva, Partner [email protected] [email protected] +1 310 696 4011 +1 917 755 5518 Kasper Kruse Petersen, Partner [email protected] +44 203 2057 360 In the USA, all securities transacted through Drake Star Securities LLC. In the USA, Drake Star Securities LLC. Is regulated by FINRA and is a member of SIPC Drake Star Partners is the marketing name for the global investment bank Drake Star Partners Limited and its subsidiaries and affiliates. In the USA, all securities are transacted through Drake Star Securities LLC. In the USA, Drake Star Securities LLC is regulated by FINRA and is a member of SIPC. © 2020 Drake Star Partners. This report is published solely for informational purposes and is not to be construed as an offer to sell or the solicitation of an offer to buy any security. The information herein is based on sources we believe to be reliable but is not guaranteed by us and we assume no liability for its use. Any opinions expressed herein are statements of our judgment on this date and are subject to change without notice. Citations and sources are available upon request through https://www.drakestar.com/contact. Interviews were conducted by Drake Star Partners via email correspondence between March and May 2020. -

Name of the AMC : Motilal Oswal Asset Management Company Limited
Name of the AMC : Motilal Oswal Asset Management Company Limited All figures - Rs. in Lacs Sr. No. ARN Name of the ARN Holder Total Commission Total Expenses Total Commission + Gross Inflows Net Inflows Whether the distributor Averge Assets AUM as on paid during paid during Expenses paid during is an associate or group under 31-Mar-2021 FY 2020-21 FY 2020-21 FY 2020-21 compnay of the sponsors Management for of the Mutual Fund FY 2020-21 A B A+B 1 2 JM Financial Services Limited 76.90 - 76.90 1,603.18 -262.90 No 7,064.01 9,579.65 2 5 HDFC Bank Limited 143.13 - 143.13 15,310.12 786.26 No 19,813.57 27,261.07 3 6 SKP Securities Limited 5.39 - 5.39 432.31 34.01 No 616.99 915.28 4 7 SPA Capital Services Limited 18.94 - 18.94 133.43 -393.93 No 1,497.90 1,065.53 5 9 Way2Wealth Securities Private Limited 2.51 - 2.51 99.28 -37.35 No 280.38 370.13 6 10 Bajaj Capital Ltd. 67.60 - 67.60 2,825.95 -36.29 No 6,177.50 8,415.72 7 11 SBICAP Securities Limited 5.32 - 5.32 248.93 17.43 No 612.22 853.38 8 14 Shubhangi Gopal Pai - - - 0.00 0.00 No - - 9 16 Bluechip Corporate Investment Centre Private limited - - - 57.60 -18.43 No 240.28 328.74 10 17 Stock Holding Corporation of India Limited 3.99 - 3.99 193.02 90.03 No 535.79 808.08 11 18 Karvy Stock Broking Limited 62.00 - 62.00 1,931.48 -720.42 No 5,720.51 7,476.57 12 19 Axis Bank Limited 28.38 - 28.38 3,931.04 2,276.13 No 2,623.13 4,677.52 13 20 ICICI Bank Limited 62.97 - 62.97 18,472.24 15,117.54 No 7,825.20 18,976.38 14 21 Tata Securities Limited 0.02 - 0.02 3.95 2.48 No 1.35 2.96 15 22 Hongkong & Shanghai Banking Corporation Ltd. -

Copyrighted Material
Index “A Bust to the Markets” Axis Financial Services (money (Archer), 361 manager), 353 “A Conversation with the Gnomes” (Archer and Treuren), 257 Baby markets, 355 Account types, 107, 109 Baby Pips, 133 Advisory services, 143–144 Back-testing, 345–346, 359 Agent computing, 361 Backup computers, 112 Algorithmic trading, 363 Baht, 333, 334 American style option, 326 Balance of trade, 178–179 AnalyzerXL, 141 Ballooning (pip) spreads, 84, 93, Anti-hedging, 40 111, 190, 334 Anti-hedging regulations, 116. Bands, 11 See also National Futures Bank lot size, 9 Association (NFA) Bank lots, 59 Application program interface Banking hours, 319 (API), 358 Bar charts, 150–152 Application service providers Barron’s, 95 (ASPs), 359 Base currency, 48–49, 67 Archer, Michael Duane, 257, Basic market paradigm (BMP), 361, 363 http://www.pbookshop.com234–236, 257, 320 Artificial intelligence (AI), 362 Bathtub analysis, 234, 273–274, 280 Asian session, 8 Bear market, 11 “A Simple Cellular Automata Bear swings, 316 Model forCOPYRIGHTED Predicting FX Beginning MATERIAL point (BP), 239, 266 Prices” (Archer), 363 Belgian dentist, 256 Ask price, 29, 52 Bernanke, Ben, 19 ATC brokers, 106 Best FX Trader (money manager), 353 AUDUSD example, 255 Beyond Candlesticks: More Japanese Australian Dollar (AUD), 4 Charting Techniques Revealed Automated order entry, 130 (Nison), 159 Automated trading method, 341 Bickford, James L. “Jim,” 10, 83, 85, Automated trading system, 339, 340 88, 169, 183, 191, 225, 234, Automatic trailing stops, 119 314, 363 405 bindex.indd 405 4/10/2012 4:45:45 PM 406 INDEX Bid price, 29, 52 Central clearinghouse, 16 Bid-ask spread, 13, 52, 117, 368 Centralized exchange, 4 Biofeedback, 211–213, 218, 293, 320 CFTC.