A Single-Cycle MIPS Processor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

45-Year CPU Evolution: One Law and Two Equations
45-year CPU evolution: one law and two equations Daniel Etiemble LRI-CNRS University Paris Sud Orsay, France [email protected] Abstract— Moore’s law and two equations allow to explain the a) IC is the instruction count. main trends of CPU evolution since MOS technologies have been b) CPI is the clock cycles per instruction and IPC = 1/CPI is the used to implement microprocessors. Instruction count per clock cycle. c) Tc is the clock cycle time and F=1/Tc is the clock frequency. Keywords—Moore’s law, execution time, CM0S power dissipation. The Power dissipation of CMOS circuits is the second I. INTRODUCTION equation (2). CMOS power dissipation is decomposed into static and dynamic powers. For dynamic power, Vdd is the power A new era started when MOS technologies were used to supply, F is the clock frequency, ΣCi is the sum of gate and build microprocessors. After pMOS (Intel 4004 in 1971) and interconnection capacitances and α is the average percentage of nMOS (Intel 8080 in 1974), CMOS became quickly the leading switching capacitances: α is the activity factor of the overall technology, used by Intel since 1985 with 80386 CPU. circuit MOS technologies obey an empirical law, stated in 1965 and 2 Pd = Pdstatic + α x ΣCi x Vdd x F (2) known as Moore’s law: the number of transistors integrated on a chip doubles every N months. Fig. 1 presents the evolution for II. CONSEQUENCES OF MOORE LAW DRAM memories, processors (MPU) and three types of read- only memories [1]. The growth rate decreases with years, from A. -

Cuda C Best Practices Guide
CUDA C BEST PRACTICES GUIDE DG-05603-001_v9.0 | June 2018 Design Guide TABLE OF CONTENTS Preface............................................................................................................ vii What Is This Document?..................................................................................... vii Who Should Read This Guide?...............................................................................vii Assess, Parallelize, Optimize, Deploy.....................................................................viii Assess........................................................................................................ viii Parallelize.................................................................................................... ix Optimize...................................................................................................... ix Deploy.........................................................................................................ix Recommendations and Best Practices.......................................................................x Chapter 1. Assessing Your Application.......................................................................1 Chapter 2. Heterogeneous Computing.......................................................................2 2.1. Differences between Host and Device................................................................ 2 2.2. What Runs on a CUDA-Enabled Device?...............................................................3 Chapter 3. Application Profiling............................................................................. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
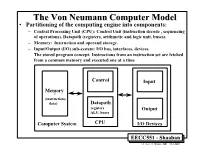
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction. -

Chap01: Computer Abstractions and Technology
CHAPTER 1 Computer Abstractions and Technology 1.1 Introduction 3 1.2 Eight Great Ideas in Computer Architecture 11 1.3 Below Your Program 13 1.4 Under the Covers 16 1.5 Technologies for Building Processors and Memory 24 1.6 Performance 28 1.7 The Power Wall 40 1.8 The Sea Change: The Switch from Uniprocessors to Multiprocessors 43 1.9 Real Stuff: Benchmarking the Intel Core i7 46 1.10 Fallacies and Pitfalls 49 1.11 Concluding Remarks 52 1.12 Historical Perspective and Further Reading 54 1.13 Exercises 54 CMPS290 Class Notes (Chap01) Page 1 / 24 by Kuo-pao Yang 1.1 Introduction 3 Modern computer technology requires professionals of every computing specialty to understand both hardware and software. Classes of Computing Applications and Their Characteristics Personal computers o A computer designed for use by an individual, usually incorporating a graphics display, a keyboard, and a mouse. o Personal computers emphasize delivery of good performance to single users at low cost and usually execute third-party software. o This class of computing drove the evolution of many computing technologies, which is only about 35 years old! Server computers o A computer used for running larger programs for multiple users, often simultaneously, and typically accessed only via a network. o Servers are built from the same basic technology as desktop computers, but provide for greater computing, storage, and input/output capacity. Supercomputers o A class of computers with the highest performance and cost o Supercomputers consist of tens of thousands of processors and many terabytes of memory, and cost tens to hundreds of millions of dollars. -

Multi-Cycle Datapathoperation
Book's Definition of Performance • For some program running on machine X, PerformanceX = 1 / Execution timeX • "X is n times faster than Y" PerformanceX / PerformanceY = n • Problem: – machine A runs a program in 20 seconds – machine B runs the same program in 25 seconds 1 Example • Our favorite program runs in 10 seconds on computer A, which hasa 400 Mhz. clock. We are trying to help a computer designer build a new machine B, that will run this program in 6 seconds. The designer can use new (or perhaps more expensive) technology to substantially increase the clock rate, but has informed us that this increase will affect the rest of the CPU design, causing machine B to require 1.2 times as many clockcycles as machine A for the same program. What clock rate should we tellthe designer to target?" • Don't Panic, can easily work this out from basic principles 2 Now that we understand cycles • A given program will require – some number of instructions (machine instructions) – some number of cycles – some number of seconds • We have a vocabulary that relates these quantities: – cycle time (seconds per cycle) – clock rate (cycles per second) – CPI (cycles per instruction) a floating point intensive application might have a higher CPI – MIPS (millions of instructions per second) this would be higher for a program using simple instructions 3 Performance • Performance is determined by execution time • Do any of the other variables equal performance? – # of cycles to execute program? – # of instructions in program? – # of cycles per second? – average # of cycles per instruction? – average # of instructions per second? • Common pitfall: thinking one of the variables is indicative of performance when it really isn’t. -

CS2504: Computer Organization
CS2504, Spring'2007 ©Dimitris Nikolopoulos CS2504: Computer Organization Lecture 4: Evaluating Performance Instructor: Dimitris Nikolopoulos Guest Lecturer: Matthew Curtis-Maury CS2504, Spring'2007 ©Dimitris Nikolopoulos Understanding Performance Why do we study performance? Evaluate during design Evaluate before purchasing Key to understanding underlying organizational motivation How can we (meaningfully) compare two machines? Performance, Cost, Value, etc Main issue: Need to understand what factors in the architecture contribute to overall system performance and the relative importance of these factors Effects of ISA on performance 2 How will hardware change affect performance CS2504, Spring'2007 ©Dimitris Nikolopoulos Airplane Performance Analogy Airplane Passengers Range Speed Boeing 777 375 4630 610 Boeing 747 470 4150 610 Concorde 132 4000 1250 Douglas DC-8-50 146 8720 544 Fighter Jet 4 2000 1500 What metric do we use? Concorde is 2.05 times faster than the 747 747 has 1.74 times higher throughput What about cost? And the winner is: It Depends! 3 CS2504, Spring'2007 ©Dimitris Nikolopoulos Throughput vs. Response Time Response Time: Execution time (e.g. seconds or clock ticks) How long does the program take to execute? How long do I have to wait for a result? Throughput: Rate of completion (e.g. results per second/tick) What is the average execution time of the program? Measure of total work done Upgrading to a newer processor will improve: response time Adding processors to the system will improve: throughput 4 CS2504, Spring'2007 ©Dimitris Nikolopoulos Example: Throughput vs. Response Time Suppose we know that an application that uses both a desktop client and a remote server is limited by network performance. -

Analysis of Body Bias Control Using Overhead Conditions for Real Time Systems: a Practical Approach∗
IEICE TRANS. INF. & SYST., VOL.E101–D, NO.4 APRIL 2018 1116 PAPER Analysis of Body Bias Control Using Overhead Conditions for Real Time Systems: A Practical Approach∗ Carlos Cesar CORTES TORRES†a), Nonmember, Hayate OKUHARA†, Student Member, Nobuyuki YAMASAKI†, Member, and Hideharu AMANO†, Fellow SUMMARY In the past decade, real-time systems (RTSs), which must in RTSs. These techniques can improve energy efficiency; maintain time constraints to avoid catastrophic consequences, have been however, they often require a large amount of power since widely introduced into various embedded systems and Internet of Things they must control the supply voltages of the systems. (IoTs). The RTSs are required to be energy efficient as they are used in embedded devices in which battery life is important. In this study, we in- Body bias (BB) control is another solution that can im- vestigated the RTS energy efficiency by analyzing the ability of body bias prove RTS energy efficiency as it can manage the tradeoff (BB) in providing a satisfying tradeoff between performance and energy. between power leakage and performance without affecting We propose a practical and realistic model that includes the BB energy and the power supply [4], [5].Itseffect is further endorsed when timing overhead in addition to idle region analysis. This study was con- ducted using accurate parameters extracted from a real chip using silicon systems are enabled with silicon on thin box (SOTB) tech- on thin box (SOTB) technology. By using the BB control based on the nology [6], which is a novel and advanced fully depleted sili- proposed model, about 34% energy reduction was achieved. -

RAMP: Research Accelerator for Multiple Processors
Technical Report UCB//CSD-05-1412, September 2005 RAMP: Research Accelerator for Multiple Processors - A Community Vision for a Shared Experimental Parallel HW/SW Platform Arvind (MIT), Krste Asanovic´ (MIT), Derek Chiou (UT Austin), James C. Hoe (CMU), Christoforos Kozyrakis (Stanford), Shih-Lien Lu (Intel), Mark Oskin (U Washington), David Patterson (UC Berkeley), Jan Rabaey (UC Berkeley), and John Wawrzynek (UC Berkeley) Project Summary Desktop processor architectures have crossed a critical threshold. Manufactures have given up attempting to extract ever more performance from a single core and instead have turned to multi-core designs. While straightforward approaches to the architecture of multi-core processors are sufficient for small designs (2–4 cores), little is really known how to build, program, or manage systems of 64 to 1024 processors. Unfortunately, the computer architecture community lacks the basic infrastructure tools required to carry out this research. While simulation has been adequate for single-processor research, significant use of simplified modeling and statistical sampling is required to work in the 2–16 processing core space. Invention is required for architecture research at the level of 64–1024 cores. Fortunately, Moore’s law has not only enabled these dense multi-core chips, it has also enabled extremely dense FPGAs. Today, for a few hundred dollars, undergraduates can work with an FPGA prototype board with almost as many gates as a Pentium. Given the right support, the research community can capitalize on this opportunity too. Today, one to two dozen cores can be programmed into a single FPGA. With multiple FPGAs on a board and multiple boards in a system, large complex architectures can be explored. -

Computer “Performance”
Computer “Performance” Readings: 1.6-1.8 BIPS (Billion Instructions Per Second) vs. GHz (Giga Cycles Per Second) Throughput (jobs/seconds) vs. Latency (time to complete a job) Measuring “best” in a computer Hyper 3.0 GHz The PowerBook G4 outguns Pentium Pipelined III-based notebooks by up to 30 percent.* Technology * Based on Adobe Photoshop tests comparing a 500MHz PowerBook G4 to 850MHz Pentium III-based portable computers 58 Performance Example: Homebuilders Builder Time per Houses Per House Dollars Per House Month Options House Self-build 24 months 1/24 Infinite $200,000 Contractor 3 months 1 100 $400,000 Prefab 6 months 1,000 1 $250,000 Which is the “best” home builder? Homeowner on a budget? Rebuilding Haiti? Moving to wilds of Alaska? Which is the “speediest” builder? Latency: how fast is one house built? Throughput: how long will it take to build a large number of houses? 59 Computer Performance Primary goal: execution time (time from program start to program completion) 1 Performance ExecutionTime To compare machines, we say “X is n times faster than Y” Performance ExecutionTime n x y Performancey ExecutionTimex Example: Machine Orange and Grape run a program Orange takes 5 seconds, Grape takes 10 seconds Orange is _____ times faster than Grape 60 Execution Time Elapsed Time counts everything (disk and memory accesses, I/O , etc.) a useful number, but often not good for comparison purposes CPU time doesn't count I/O or time spent running other programs can be broken up into system time, and user time Example: Unix “time” command linux15.ee.washington.edu> time javac CircuitViewer.java 3.370u 0.570s 0:12.44 31.6% Our focus: user CPU time time spent executing the lines of code that are "in" our program 61 CPU Time CPU execution time CPU clock cycles =*Clock period for a program for a program CPU execution time CPU clock cycles 1 =* for a program for a program Clock rate Application example: A program takes 10 seconds on computer Orange, with a 400MHz clock.