Chapter 18 the BOXPLOT Procedure
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
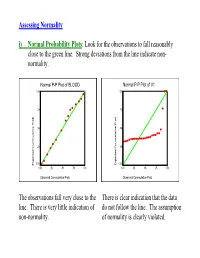
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -

Summarize — Summary Statistics
Title stata.com summarize — Summary statistics Description Quick start Menu Syntax Options Remarks and examples Stored results Methods and formulas References Also see Description summarize calculates and displays a variety of univariate summary statistics. If no varlist is specified, summary statistics are calculated for all the variables in the dataset. Quick start Basic summary statistics for continuous variable v1 summarize v1 Same as above, and include v2 and v3 summarize v1-v3 Same as above, and provide additional detail about the distribution summarize v1-v3, detail Summary statistics reported separately for each level of catvar by catvar: summarize v1 With frequency weight wvar summarize v1 [fweight=wvar] Menu Statistics > Summaries, tables, and tests > Summary and descriptive statistics > Summary statistics 1 2 summarize — Summary statistics Syntax summarize varlist if in weight , options options Description Main detail display additional statistics meanonly suppress the display; calculate only the mean; programmer’s option format use variable’s display format separator(#) draw separator line after every # variables; default is separator(5) display options control spacing, line width, and base and empty cells varlist may contain factor variables; see [U] 11.4.3 Factor variables. varlist may contain time-series operators; see [U] 11.4.4 Time-series varlists. by, collect, rolling, and statsby are allowed; see [U] 11.1.10 Prefix commands. aweights, fweights, and iweights are allowed. However, iweights may not be used with the detail option; see [U] 11.1.6 weight. Options Main £ £detail produces additional statistics, including skewness, kurtosis, the four smallest and four largest values, and various percentiles. meanonly, which is allowed only when detail is not specified, suppresses the display of results and calculation of the variance. -

U3 Introduction to Summary Statistics
Presentation Name Course Name Unit # – Lesson #.# – Lesson Name Statistics • The collection, evaluation, and interpretation of data Introduction to Summary Statistics • Statistical analysis of measurements can help verify the quality of a design or process Summary Statistics Mean Central Tendency Central Tendency • The mean is the sum of the values of a set • “Center” of a distribution of data divided by the number of values in – Mean, median, mode that data set. Variation • Spread of values around the center – Range, standard deviation, interquartile range x μ = i Distribution N • Summary of the frequency of values – Frequency tables, histograms, normal distribution Project Lead The Way, Inc. Copyright 2010 1 Presentation Name Course Name Unit # – Lesson #.# – Lesson Name Mean Central Tendency Mean Central Tendency x • Data Set μ = i 3 7 12 17 21 21 23 27 32 36 44 N • Sum of the values = 243 • Number of values = 11 μ = mean value x 243 x = individual data value Mean = μ = i = = 22.09 i N 11 xi = summation of all data values N = # of data values in the data set A Note about Rounding in Statistics Mean – Rounding • General Rule: Don’t round until the final • Data Set answer 3 7 12 17 21 21 23 27 32 36 44 – If you are writing intermediate results you may • Sum of the values = 243 round values, but keep unrounded number in memory • Number of values = 11 • Mean – round to one more decimal place xi 243 Mean = μ = = = 22.09 than the original data N 11 • Standard Deviation: Round to one more decimal place than the original data • Reported: Mean = 22.1 Project Lead The Way, Inc. -

Descriptive Statistics
Descriptive Statistics Fall 2001 Professor Paul Glasserman B6014: Managerial Statistics 403 Uris Hall Histograms 1. A histogram is a graphical display of data showing the frequency of occurrence of particular values or ranges of values. In a histogram, the horizontal axis is divided into bins, representing possible data values or ranges. The vertical axis represents the number (or proportion) of observations falling in each bin. A bar is drawn in each bin to indicate the number (or proportion) of observations corresponding to that bin. You have probably seen histograms used, e.g., to illustrate the distribution of scores on an exam. 2. All histograms are bar graphs, but not all bar graphs are histograms. For example, we might display average starting salaries by functional area in a bar graph, but such a figure would not be a histogram. Why not? Because the Y-axis values do not represent relative frequencies or proportions, and the X-axis values do not represent value ranges (in particular, the order of the bins is irrelevant). Measures of Central Tendency 1. Let X1,...,Xn be data points, such as the result of n measurements or observations. What one number best characterizes or summarizes these values? The answer depends on the context. Some familiar summary statistics are these: • The mean is given by the arithemetic average X =(X1 + ···+ Xn)/n.(No- tation: We will often write n Xi for X1 + ···+ Xn. i=1 n The symbol i=1 Xi is read “the sum from i equals 1 upto n of Xi.”) 1 • The median is larger than one half of the observations and smaller than the other half. -

Measures of Dispersion for Multidimensional Data
European Journal of Operational Research 251 (2016) 930–937 Contents lists available at ScienceDirect European Journal of Operational Research journal homepage: www.elsevier.com/locate/ejor Computational Intelligence and Information Management Measures of dispersion for multidimensional data Adam Kołacz a, Przemysław Grzegorzewski a,b,∗ a Faculty of Mathematics and Computer Science, Warsaw University of Technology, Koszykowa 75, Warsaw 00–662, Poland b Systems Research Institute, Polish Academy of Sciences, Newelska 6, Warsaw 01–447, Poland article info abstract Article history: We propose an axiomatic definition of a dispersion measure that could be applied for any finite sample of Received 22 February 2015 k-dimensional real observations. Next we introduce a taxonomy of the dispersion measures based on the Accepted 4 January 2016 possible behavior of these measures with respect to new upcoming observations. This way we get two Available online 11 January 2016 classes of unstable and absorptive dispersion measures. We examine their properties and illustrate them Keywords: by examples. We also consider a relationship between multidimensional dispersion measures and mul- Descriptive statistics tidistances. Moreover, we examine new interesting properties of some well-known dispersion measures Dispersion for one-dimensional data like the interquartile range and a sample variance. Interquartile range © 2016 Elsevier B.V. All rights reserved. Multidistance Spread 1. Introduction are intended for use. It is also worth mentioning that several terms are used in the literature as regards dispersion measures like mea- Various summary statistics are always applied wherever deci- sures of variability, scatter, spread or scale. Some authors reserve sions are based on sample data. The main goal of those characteris- the notion of the dispersion measure only to those cases when tics is to deliver a synthetic information on basic features of a data variability is considered relative to a given fixed point (like a sam- set under study. -

Summary Statistics, Distributions of Sums and Means
Summary statistics, distributions of sums and means Joe Felsenstein Department of Genome Sciences and Department of Biology Summary statistics, distributions of sums and means – p.1/18 Quantiles In both empirical distributions and in the underlying distribution, it may help us to know the points where a given fraction of the distribution lies below (or above) that point. In particular: The 2.5% point The 5% point The 25% point (the first quartile) The 50% point (the median) The 75% point (the third quartile) The 95% point (or upper 5% point) The 97.5% point (or upper 2.5% point) Note that if a distribution has a small fraction of very big values far out in one tail (such as the distributions of wealth of individuals or families), the may not be a good “typical” value; the median will do much better. (For a symmetric distribution the median is the mean). Summary statistics, distributions of sums and means – p.2/18 The mean The mean is the average of points. If the distribution is the theoretical one, it is called the expectation, it’s the theoretical mean we would be expected to get if we drew infinitely many points from that distribution. For a sample of points x1, x2,..., x100 the mean is simply their average ¯x = (x1 + x2 + x3 + ... + x100) / 100 For a distribution with possible values 0, 1, 2, 3,... where value k has occurred a fraction fk of the time, the mean weights each of these by the fraction of times it has occurred (then in effect divides by the sum of these fractions, which however is actually 1): ¯x = 0 f0 + 1 f1 + 2 f2 + .. -

Numerical Summary Values for Quantitative Data 35
3.1 Numerical summary values for quantitative data 35 Chapter 3 Descriptive Statistics II: Numerical Summary Values 3.1 Numerical summary values for quantitative data For many purposes a few well–chosen numerical summary values (statistics) will suffice as a description of the distribution of a quantitative variable. A statistic is a numerical characteristic of a sample. More formally, a statistic is a numerical quantity computed from the values of a variable, or variables, corresponding to the units in a sample. Thus a statistic serves to quantify some interesting aspect of the distribution of a variable in a sample. Summary statistics are particularly useful for comparing and contrasting the distribution of a variable for two different samples. If we plan to use a small number of summary statistics to characterize a distribution or to compare two distributions, then we first need to decide which aspects of the distribution are of primary interest. If the distributions of interest are essentially mound shaped with a single peak (unimodal), then there are three aspects of the distribution which are often of primary interest. The first aspect of the distribution is its location on the number line. Generally, when speaking of the location of a distribution we are referring to the location of the “center” of the distribution. The location of the center of a symmetric, mound shaped distribution is clearly the point of symmetry. There is some ambiguity in specifying the location of the center of an asymmetric, mound shaped distribution and we shall see that there are at least two standard ways to quantify location in this context. -

Measures of Dispersion
MEASURES OF DISPERSION Measures of Dispersion • While measures of central tendency indicate what value of a variable is (in one sense or other) “average” or “central” or “typical” in a set of data, measures of dispersion (or variability or spread) indicate (in one sense or other) the extent to which the observed values are “spread out” around that center — how “far apart” observed values typically are from each other and therefore from some average value (in particular, the mean). Thus: – if all cases have identical observed values (and thereby are also identical to [any] average value), dispersion is zero; – if most cases have observed values that are quite “close together” (and thereby are also quite “close” to the average value), dispersion is low (but greater than zero); and – if many cases have observed values that are quite “far away” from many others (or from the average value), dispersion is high. • A measure of dispersion provides a summary statistic that indicates the magnitude of such dispersion and, like a measure of central tendency, is a univariate statistic. Importance of the Magnitude Dispersion Around the Average • Dispersion around the mean test score. • Baltimore and Seattle have about the same mean daily temperature (about 65 degrees) but very different dispersions around that mean. • Dispersion (Inequality) around average household income. Hypothetical Ideological Dispersion Hypothetical Ideological Dispersion (cont.) Dispersion in Percent Democratic in CDs Measures of Dispersion • Because dispersion is concerned with how “close together” or “far apart” observed values are (i.e., with the magnitude of the intervals between them), measures of dispersion are defined only for interval (or ratio) variables, – or, in any case, variables we are willing to treat as interval (like IDEOLOGY in the preceding charts). -

Section II Descriptive Statistics for Continuous & Binary Data (Including
Section II Descriptive Statistics for continuous & binary Data (including survival data) II - Checklist of summary statistics Do you know what all of the following are and what they are for? One variable – continuous data (variables like age, weight, serum levels, IQ, days to relapse ) _ Means (Y) Medians = 50th percentile Mode = most frequently occurring value Quartile – Q1=25th percentile, Q2= 50th percentile, Q3=75th percentile) Percentile Range (max – min) IQR – Interquartile range = Q3 – Q1 SD – standard deviation (most useful when data are Gaussian) (note, for a rough approximation, SD 0.75 IQR, IQR 1.33 SD) Survival curve = life table CDF = Cumulative dist function = 1 – survival curve Hazard rate (death rate) One variable discrete data (diseased yes or no, gender, diagnosis category, alive/dead) Risk = proportion = P = (Odds/(1+Odds)) Odds = P/(1-P) Relation between two (or more) continuous variables (Y vs X) Correlation coefficient (r) Intercept = b0 = value of Y when X is zero Slope = regression coefficient = b, in units of Y/X Multiple regression coefficient (bi) from a regression equation: Y = b0 + b1X1 + b2X2 + … + bkXk + error Relation between two (or more) discrete variables Risk ratio = relative risk = RR and log risk ratio Odds ratio (OR) and log odds ratio Logistic regression coefficient (=log odds ratio) from a logistic regression equation: ln(P/1-P)) = b0 + b1X1 + b2X2 + … + bkXk Relation between continuous outcome and discrete predictor Analysis of variance = comparing means Evaluating medical tests – where the test is positive or negative for a disease In those with disease: Sensitivity = 1 – false negative proportion In those without disease: Specificity = 1- false positive proportion ROC curve – plot of sensitivity versus false positive (1-specificity) – used to find best cutoff value of a continuously valued measurement DESCRIPTIVE STATISTICS A few definitions: Nominal data come as unordered categories such as gender and color. -

4. Descriptive Statistics
4. Descriptive statistics Any time that you get a new data set to look at one of the first tasks that you have to do is find ways of summarising the data in a compact, easily understood fashion. This is what descriptive statistics (as opposed to inferential statistics) is all about. In fact, to many people the term “statistics” is synonymous with descriptive statistics. It is this topic that we’ll consider in this chapter, but before going into any details, let’s take a moment to get a sense of why we need descriptive statistics. To do this, let’s open the aflsmall_margins file and see what variables are stored in the file. In fact, there is just one variable here, afl.margins. We’ll focus a bit on this variable in this chapter, so I’d better tell you what it is. Unlike most of the data sets in this book, this is actually real data, relating to the Australian Football League (AFL).1 The afl.margins variable contains the winning margin (number of points) for all 176 home and away games played during the 2010 season. This output doesn’t make it easy to get a sense of what the data are actually saying. Just “looking at the data” isn’t a terribly effective way of understanding data. In order to get some idea about what the data are actually saying we need to calculate some descriptive statistics (this chapter) and draw some nice pictures (Chapter 5). Since the descriptive statistics are the easier of the two topics I’ll start with those, but nevertheless I’ll show you a histogram of the afl.margins data since it should help you get a sense of what the data we’re trying to describe actually look like, see Figure 4.2. -

Boxplots for Grouped and Clustered Data in Toxicology
Penultimate version. If citing, please refer instead to the published version in Archives of Toxicology, DOI: 10.1007/s00204-015-1608-4. Boxplots for grouped and clustered data in toxicology Philip Pallmann1, Ludwig A. Hothorn2 1 Department of Mathematics and Statistics, Lancaster University, Lancaster LA1 4YF, UK, Tel.: +44 (0)1524 592318, [email protected] 2 Institute of Biostatistics, Leibniz University Hannover, 30419 Hannover, Germany Abstract The vast majority of toxicological papers summarize experimental data as bar charts of means with error bars. While these graphics are easy to generate, they often obscure essen- tial features of the data, such as outliers or subgroups of individuals reacting differently to a treatment. Especially raw values are of prime importance in toxicology, therefore we argue they should not be hidden in messy supplementary tables but rather unveiled in neat graphics in the results section. We propose jittered boxplots as a very compact yet comprehensive and intuitively accessible way of visualizing grouped and clustered data from toxicological studies together with individual raw values and indications of statistical significance. A web application to create these plots is available online. Graphics, statistics, R software, body weight, micronucleus assay 1 Introduction Preparing a graphical summary is usually the first if not the most important step in a data analysis procedure, and it can be challenging especially with many-faceted datasets as they occur frequently in toxicological studies. However, even in simple experimental setups many researchers have a hard time presenting their results in a suitable manner. Browsing recent volumes of this journal, we have realized that the least favorable ways of displaying toxicological data appear to be the most popular ones (according to the number of publications that use them). -

Length of Stay Outlier Detection Through Cluster Analysis: a Case Study in Pediatrics Daniel Gartnera, Rema Padmanb
Length of Stay Outlier Detection through Cluster Analysis: A Case Study in Pediatrics Daniel Gartnera, Rema Padmanb aSchool of Mathematics, Cardiff University, United Kingdom bThe H. John Heinz III College, Carnegie Mellon University, Pittsburgh, USA Abstract The increasing availability of detailed inpatient data is enabling the develop- ment of data-driven approaches to provide novel insights for the management of Length of Stay (LOS), an important quality metric in hospitals. This study examines clustering of inpatients using clinical and demographic attributes to identify LOS outliers and investigates the opportunity to reduce their LOS by comparing their order sequences with similar non-outliers in the same cluster. Learning from retrospective data on 353 pediatric inpatients admit- ted for appendectomy, we develop a two-stage procedure that first identifies a typical cluster with LOS outliers. Our second stage analysis compares orders pairwise to determine candidates for switching to make LOS outliers simi- lar to non-outliers. Results indicate that switching orders in homogeneous inpatient sub-populations within the limits of clinical guidelines may be a promising decision support strategy for LOS management. Keywords: Machine Learning; Clustering; Health Care; Length of Stay Email addresses: [email protected] (Daniel Gartner), [email protected] (Rema Padman) 1. Introduction Length of Stay (LOS) is an important quality metric in hospitals that has been studied for decades Kim and Soeken (2005); Tu et al. (1995). However, the increasing digitization of healthcare with Electronic Health Records and other clinical information systems is enabling the collection and analysis of vast amounts of data using advanced data-driven methods that may be par- ticularly valuable for LOS management Gartner (2015); Saria et al.