Stringdb Package Vignette
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplemental Table S1
Entrez Gene Symbol Gene Name Affymetrix EST Glomchip SAGE Stanford Literature HPA confirmed Gene ID Profiling profiling Profiling Profiling array profiling confirmed 1 2 A2M alpha-2-macroglobulin 0 0 0 1 0 2 10347 ABCA7 ATP-binding cassette, sub-family A (ABC1), member 7 1 0 0 0 0 3 10350 ABCA9 ATP-binding cassette, sub-family A (ABC1), member 9 1 0 0 0 0 4 10057 ABCC5 ATP-binding cassette, sub-family C (CFTR/MRP), member 5 1 0 0 0 0 5 10060 ABCC9 ATP-binding cassette, sub-family C (CFTR/MRP), member 9 1 0 0 0 0 6 79575 ABHD8 abhydrolase domain containing 8 1 0 0 0 0 7 51225 ABI3 ABI gene family, member 3 1 0 1 0 0 8 29 ABR active BCR-related gene 1 0 0 0 0 9 25841 ABTB2 ankyrin repeat and BTB (POZ) domain containing 2 1 0 1 0 0 10 30 ACAA1 acetyl-Coenzyme A acyltransferase 1 (peroxisomal 3-oxoacyl-Coenzyme A thiol 0 1 0 0 0 11 43 ACHE acetylcholinesterase (Yt blood group) 1 0 0 0 0 12 58 ACTA1 actin, alpha 1, skeletal muscle 0 1 0 0 0 13 60 ACTB actin, beta 01000 1 14 71 ACTG1 actin, gamma 1 0 1 0 0 0 15 81 ACTN4 actinin, alpha 4 0 0 1 1 1 10700177 16 10096 ACTR3 ARP3 actin-related protein 3 homolog (yeast) 0 1 0 0 0 17 94 ACVRL1 activin A receptor type II-like 1 1 0 1 0 0 18 8038 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 1 0 0 0 0 19 8751 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 1 0 0 0 0 20 8728 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 1 0 0 0 0 21 81792 ADAMTS12 ADAM metallopeptidase with thrombospondin type 1 motif, 12 1 0 0 0 0 22 9507 ADAMTS4 ADAM metallopeptidase with thrombospondin type 1 -

Noninvasive Sleep Monitoring in Large-Scale Screening of Knock-Out Mice
bioRxiv preprint doi: https://doi.org/10.1101/517680; this version posted January 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Noninvasive sleep monitoring in large-scale screening of knock-out mice reveals novel sleep-related genes Shreyas S. Joshi1*, Mansi Sethi1*, Martin Striz1, Neil Cole2, James M. Denegre2, Jennifer Ryan2, Michael E. Lhamon3, Anuj Agarwal3, Steve Murray2, Robert E. Braun2, David W. Fardo4, Vivek Kumar2, Kevin D. Donohue3,5, Sridhar Sunderam6, Elissa J. Chesler2, Karen L. Svenson2, Bruce F. O'Hara1,3 1Dept. of Biology, University of Kentucky, Lexington, KY 40506, USA, 2The Jackson Laboratory, Bar Harbor, ME 04609, USA, 3Signal solutions, LLC, Lexington, KY 40503, USA, 4Dept. of Biostatistics, University of Kentucky, Lexington, KY 40536, USA, 5Dept. of Electrical and Computer Engineering, University of Kentucky, Lexington, KY 40506, USA. 6Dept. of Biomedical Engineering, University of Kentucky, Lexington, KY 40506, USA. *These authors contributed equally Address for correspondence and proofs: Shreyas S. Joshi, Ph.D. Dept. of Biology University of Kentucky 675 Rose Street 101 Morgan Building Lexington, KY 40506 U.S.A. Phone: (859) 257-2805 FAX: (859) 257-1717 Email: [email protected] Running title: Sleep changes in knockout mice bioRxiv preprint doi: https://doi.org/10.1101/517680; this version posted January 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

The Role of Structural Disorder in Cell Cycle Regulation, Related Clinical Proteomics, 5 Disease Development and Drug Targeting
Review The role of structural disorder in cell cycle regulation, related clinical proteomics, 5 disease development and drug targeting Expert Rev. Proteomics 12(3), 000–000 (2015) 10 1 AQ2 Agnes Tantos , Understanding the molecular mechanisms of the regulation of cell cycle is a central issue in Lajos Kalmar2 and molecular cell biology, due to its fundamental role in the existence of cells. The regulatory Peter Tompa*1,2 circuits that make decisions on when a cell should divide are very complex and particularly subtly balanced in eukaryotes, in which the harmony of many different cells in an organism is 1 Institute of Enzymology, Research essential for life. Several hundred proteins are involved in these processes, and a great deal of 15 Centre for Natural Sciences of the Hungarian Academy of Sciences, studies attests that most of them have functionally relevant intrinsic structural disorder. Budapest, Hungary Structural disorder imparts many functional advantages on these proteins, and we discuss it 2 VIB Department of Structural Biology, in detail that it is involved in all key steps from signaling through the cell membrane to Vrije Universiteit Brussel, Brussels, Belgium regulating transcription of proteins that execute timely responses to an ever-changing *Author for correspondence: environment. 20 [email protected] KEYWORDS: cancer . cell-cycle . checkpoint . post-translational modification . protein disorder . signal transduction 25 of proteins are able to fulfill important func- Cell cycle: the cornerstone of tions without possessing a stable three- multicellular life dimensional structure [3,4]. These proteins, Every postembryonic eukaryotic cell goes termed intrinsically disordered proteins or through the distinct phases of cell cycle, regions (IDPs/IDRs), participate in many reg- G1, S, G2 and M. -

Noelia Díaz Blanco
Effects of environmental factors on the gonadal transcriptome of European sea bass (Dicentrarchus labrax), juvenile growth and sex ratios Noelia Díaz Blanco Ph.D. thesis 2014 Submitted in partial fulfillment of the requirements for the Ph.D. degree from the Universitat Pompeu Fabra (UPF). This work has been carried out at the Group of Biology of Reproduction (GBR), at the Department of Renewable Marine Resources of the Institute of Marine Sciences (ICM-CSIC). Thesis supervisor: Dr. Francesc Piferrer Professor d’Investigació Institut de Ciències del Mar (ICM-CSIC) i ii A mis padres A Xavi iii iv Acknowledgements This thesis has been made possible by the support of many people who in one way or another, many times unknowingly, gave me the strength to overcome this "long and winding road". First of all, I would like to thank my supervisor, Dr. Francesc Piferrer, for his patience, guidance and wise advice throughout all this Ph.D. experience. But above all, for the trust he placed on me almost seven years ago when he offered me the opportunity to be part of his team. Thanks also for teaching me how to question always everything, for sharing with me your enthusiasm for science and for giving me the opportunity of learning from you by participating in many projects, collaborations and scientific meetings. I am also thankful to my colleagues (former and present Group of Biology of Reproduction members) for your support and encouragement throughout this journey. To the “exGBRs”, thanks for helping me with my first steps into this world. Working as an undergrad with you Dr. -

Haploinsufficiency of Cardiac Myosin Binding Protein-C in the Development of Hypertrophic Cardiomyopathy
Loyola University Chicago Loyola eCommons Dissertations Theses and Dissertations 2014 Haploinsufficiency of Cardiac Myosin Binding Protein-C in the Development of Hypertrophic Cardiomyopathy David Barefield Loyola University Chicago Follow this and additional works at: https://ecommons.luc.edu/luc_diss Part of the Physiology Commons Recommended Citation Barefield, David, "Haploinsufficiency of Cardiac Myosin Binding Protein-C in the Development of Hypertrophic Cardiomyopathy" (2014). Dissertations. 1249. https://ecommons.luc.edu/luc_diss/1249 This Dissertation is brought to you for free and open access by the Theses and Dissertations at Loyola eCommons. It has been accepted for inclusion in Dissertations by an authorized administrator of Loyola eCommons. For more information, please contact [email protected]. This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 License. Copyright © 2014 David Barefield LOYOLA UNIVERSITY CHICAGO HAPLOINSUFFICIENCY OF CARDIAC MYOSIN BINDING PROTEIN-C IN THE DEVELOPMENT OF HYPERTROPHIC CARDIOMYOPATHY A DISSERTATION SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY PROGRAM IN CELL AND MOLECULAR PHYSIOLOGY BY DAVID YEOMANS BAREFIELD CHICAGO, IL AUGUST 2014 Copyright by David Yeomans Barefield, 2014 All Rights Reserved. ii ACKNOWLEDGEMENTS The completion of this work would not have been possible without the support of excellent mentors, colleagues, friends, and family. I give tremendous thanks to my mentor, Dr. Sakthivel Sadayappan, who has facilitated my growth as a scientist and as a human being over the past five years. I would like to thank my dissertation committee: Drs. Pieter de Tombe, Kenneth Byron, Leanne Cribbs, Kyle Henderson, and Christine Seidman for their erudite guidance of my project and my development as a scientist. -

Locating Gene Conversions on the X-Chromosome
Sexy Gene Conversions: Locating Gene Conversions on the X-Chromosome Mark J. Lawson1, Liqing Zhang1;2∗ Department of Computer Science, Virginia Tech 2Program in Genetics, Bioinformatics, and Computational Biology ∗To whom correspondence should be addressed; E-mail: [email protected] April 3, 2009 Abstract Gene conversion can have a profound impact on both the short-term and long-term evolution of genes and genomes. Here we examined the gene families that are located on the X-chromosomes of human, chimp, mouse, and rat for evidence of gene conversion. We identified seven gene families (WD repeat protein family, Ferritin Heavy Chain family, RAS-related Protein RAB-40 family, Diphosphoinositol polyphosphate phosphohydrolase family, Transcription Elongation Factor A family, LDOC1 Related family, Zinc Finger Protein ZIC, and GLI family) that show evidence of gene conversion. Through phylogenetic analyses and synteny evidence, we show that gene conversion has played an important role in the evolution of these gene families and that gene conversion has occured independently in both primates and rodents. Comparing the results with those of two gene conversion prediction programs (GENECONV and Partimatrix), we found that both GENECONV and Partimatrix have very high false negative rates (i.e. failed to predict gene conversions), leading to many undetected gene conversions. The combination of phylogenetic analyses with physical synteny evidence exhibits high power in the detection of gene conversions. 1 1 Introduction Gene conversions are the exchange of genetic information between two genes, initiated by a double-strand break in one gene (acceptor) followed by the repair of this gene through the copying of the sequence of a similar gene (donor). -

I FOUR JOINTED BOX ONE, a NOVEL PRO-ANGIOGENIC PROTEIN IN
FOUR JOINTED BOX ONE, A NOVEL PRO-ANGIOGENIC PROTEIN IN COLORECTAL CARCINOMA. BY Nicole Theresa Al-Greene Dissertation Submitted to the Faculty of the Graduate School of Vanderbilt University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY In Cell and Developmental Biology. December, 2013 Nashville Tennessee Approved: R. Daniel Beauchamp Susan Wente James Goldenring Albert Reynolds i DEDICATION To my parents, Karen and John, who have helped me in every way possible, every single day. ii ACKNOWLEDGMENTS. Funding for this work was supported by grants DK052334, CA069457, The GI Cancer SPORE, GM088822, the VICC, the Clinical and Translational Science Award (NCRR/NIH UL1RR024975), the DDRC (P30DK058404), and the Cooperative Human Tissue Network (UO1CA094664) and U01CA094664. I was lucky enough to be allowed to perform research as an undergraduate in the lab of Ken Belanger. I will be forever grateful for that opportunity that sparked my love of research. Equally important was my time as a technician in Len Zon’s lab where I confirmed the fact that I needed to go graduate school and earn my degree. During my time at Vanderbilt I have been helped by so many individuals, and the collaborative nature of everyone I have met with is truly an amazing aspect of the research community here. I am especially thankful for all the technical help and insightful conversations I have had with Natasha Deane, Anna Means, Claudia Andl, Tanner Freeman, Connie Weaver, Keeli Lewis, Jalal Hamaamen, Jenny Zi, John Neff, Christian Kis, Andries Zjistra, Trennis Palmer, Joseph Roland, and Lynn LaPierre. -

Frequent Variations in Cancer-Related Genes May Play Prognostic Role in Treatment of Patients with Chronic Myeloid Leukemia Alexander V
Lavrov et al. BMC Genetics 2016, 17(Suppl 1):14 DOI 10.1186/s12863-015-0308-7 RESEARCH Open Access Frequent variations in cancer-related genes may play prognostic role in treatment of patients with chronic myeloid leukemia Alexander V. Lavrov1,2*, Ekaterina Y. Chelysheva3, Svetlana A. Smirnikhina1, Oleg A. Shukhov3, Anna G. Turkina3, Elmira P. Adilgereeva1 and Sergey I. Kutsev1,2 From The 7th International Young Scientists School “Systems Biology and Bioinformatics” (SBB’2015) Novosibirsk, Russia. 22-25 June 2015 Abstract Background: Genome variability of host genome and cancer cells play critical role in diversity of response to existing therapies and overall success in treating oncological diseases. In chronic myeloid leukemia targeted therapy with tyrosine kinase inhibitors demonstrates high efficacy in most of the patients. However about 15 % of patients demonstrate primary resistance to standard therapy. Whole exome sequencing is a good tool for unbiased search of genetic variations important for prognosis of survival and therapy efficacy in many cancers. We apply this approach to CML patients with optimal response and failure of tyrosine kinase therapy. Results: We analyzed exome variations between optimal responders and failures and found 7 variants in cancer- related genes with different genotypes in two groups of patients. Five of them were found in optimal responders: rs11579366, rs1990236, rs176037, rs10653661, rs3803264 and two in failures: rs3099950, rs9471966. These variants were found in genes associated with cancers (ANKRD35, DNAH9, MAGEC1, TOX3) or participating in cancer-related signaling pathways (THSD1, MORN2, PTCRA). Conclusion: We found gene variants which may become early predictors of the therapy outcome and allow development of new early prognostic tests for estimation of therapy efficacy in CML patients. -

Supplementary Information
Supplementary Information Table S1. Gene Ontology analysis of affected biological processes/pathways/themes in H1 hESCs based on sets of statistically significant differentially expressed genes. Exposures Overrepresented Categories (Upregulation) EASE Score Negative regulation of cell differentiation 0.0049 Lipid biosynthetic process 0.015 Negative regulation of cell proliferation 0.02 5 cGy, 2 h Transcription factor binding 0.037 Regulation of apoptosis 0.038 Positive regulation of anti-apoptosis 0.048 P53 signaling pathway 4.2 × 10−10 Positive regulation of apoptosis 7.5 × 10−8 Response to DNA damage stimulus 1.5 × 10−6 Cellular response to stress 9.6 × 10−6 1 Gy, 2 h Negative regulation of cell proliferation 9.8 × 10−6 Cell cycle arrest 7.0 × 10−4 Negative regulation of cell differentiation 1.5 × 10−3 Regulation of protein kinase activity 0.011 I-kappaB kinase/NF-kappaB cascade 0.025 Metallothionein superfamily 9.9 × 10−18 Induction of apoptosis 8.8 × 10−5 DNA damage response 2.6 × 10−4 1 Gy, 16 h Positive regulation of anti-apoptosis 0.001 Positive regulation of cell death 0.005 Cellular response to stress 0.012 Exposures Overrepresented Categories (Downregulation) EASE Score Alternative splicing 0.016 1 Gy, 2 h Chromatin organization 0.020 Chromatin assembly 2.0 × 10−6 Cholesterol biosynthesis 5.1 × 10−5 Macromolecular complex assembly 9.3 × 10−4 1 Gy, 16 h PPAR signaling pathway 0.007 Hemopoietic organ development 0.033 Immune system development 0.040 S2 Table S2. Gene Ontology analysis of affected biological processes/pathways/themes in H7 based on sets of statistically significant differentially expressed genes. -
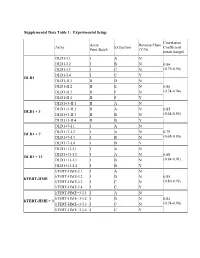
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

Application of Next-Generation Sequencing for the Genomic
Article Application of Next‐Generation Sequencing for the Genomic Characterization of Patients with Smoldering Myeloma Martina Manzoni, Valentina Marchica, Paola Storti, Bachisio Ziccheddu, Gabriella Sammarelli, Giannalisa Todaro, Francesca Pelizzoni, Simone Salerio, Laura Notarfranchi, Alessandra Pompa, Luca Baldini, Niccolò Bolli, Antonino Neri, Nicola Giuliani and Marta Lionetti Supplementary Materials Supplementary Methods Library Design, CAPP‐Seq Library Preparation, and Ultra‐Deep Next‐Generation Sequencing (NGS) The targeted resequencing gene panel included coding exons and splice sites of 56 genes that emerged as drivers from a recent analysis of whole genome/exome data in more than 800 MM patients [1] (target region: 112 kb: ACTG1, BCL7A, BHLHE41, BRAF, BTG1, CCND1, CDKN1B, CYLD, DIS3, DTX1, DUSP2, EGR1, FAM46C, FGFR3, FUBP1, HIST1H1B, HIST1H1D, HIST1H1E, HIST1H2BK, IGLL5, IRF1, IRF4, KLHL6, KMT2B, KRAS, LCE1D, LTB, MAX, NFKB2, NFKBIA, NRAS, PABPC1, PIM1, POT1, PRDM1, PRKD2, PTPN11, RASA2, RB1, RFTN1, RPL10, RPL5, RPRD1B, RPS3A, SAMHD1, SETD2, SP140, TBC1D29, TCL1A, TGDS, TP53, TRAF2, TRAF3, XBP1, ZNF462, ZNF292). Tumor gDNA (median 400 ng) was sheared through enzymatic fragmentation before library construction to obtain 150–200‐bp fragments. Targeted ultra‐deep‐next generation sequencing was performed by using the CAPP‐seq approach, as described in Newman A.M. et al., Nat. Med. 2014 [2]. The NGS libraries were constructed using the KAPA Library Preparation Kit (Kapa Biosystems, Wilmington, MA, USA) and hybrid selection was performed with the custom SeqCap EZ Choice Library (Roche NimbleGen, Madison, WI, USA), allowing for enrichment by the capture of genomic regions of interest up to 7 Mb for human resequencing studies. Multiplexed libraries were sequenced using 200‐bp paired‐end runs on an Illumina MiSeq sequencer (Illumina, Hayward, CA, USA).