Competitive Bridge Bidding with Deep Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introducion to Duplicate
INTRODUCTION to DUPLICATE INTRODUCTION TO DUPLICATE BRIDGE This book is not about how to bid, declare or defend a hand of bridge. It assumes you know how to do that or are learning how to do those things elsewhere. It is your guide to playing Duplicate Bridge, which is how organized, competitive bridge is played all over the World. It explains all the Laws of Duplicate and the process of entering into Club games or Tournaments, the Convention Card, the protocols and rules of player conduct; the paraphernalia and terminology of duplicate. In short, it’s about the context in which duplicate bridge is played. To become an accomplished duplicate player, you will need to know everything in this book. But you can start playing duplicate immediately after you read Chapter I and skim through the other Chapters. © ACBL Unit 533, Palm Springs, Ca © ACBL Unit 533, 2018 Pg 1 INTRODUCTION to DUPLICATE This book belongs to Phone Email I joined the ACBL on ____/____ /____ by going to www.ACBL.com and signing up. My ACBL number is __________________ © ACBL Unit 533, 2018 Pg 2 INTRODUCTION to DUPLICATE Not a word of this book is about how to bid, play or defend a bridge hand. It assumes you have some bridge skills and an interest in enlarging your bridge experience by joining the world of organized bridge competition. It’s called Duplicate Bridge. It’s the difference between a casual Saturday morning round of golf or set of tennis and playing in your Club or State championships. As in golf or tennis, your skills will be tested in competition with others more or less skilled than you; this book is about the settings in which duplicate happens. -

Acol Bidding Notes
SECTION 1 - INTRODUCTION The following notes are designed to help your understanding of the Acol system of bidding and should be used in conjunction with Crib Sheets 1 to 5 and the Glossary of Terms The crib sheets summarise the bidding in tabular form, whereas these notes provide a fuller explanation of the reasons for making particular bids and bidding strategy. These notes consist of a number of short chapters that have been structured in a logical order to build on the things learnt in the earlier chapters. However, each chapter can be viewed as a mini-lesson on a specific area which can be read in isolation rather than trying to absorb too much information in one go. It should be noted that there is not a single set of definitive Acol ‘rules’. The modern Acol bidding style has developed over the years and different bridge experts recommend slightly different variations based on their personal preferences and playing experience. These notes are based on the methods described in the book The Right Way to Play Bridge by Paul Mendelson, which is available at all good bookshops (and some rubbish ones as well). They feature a ‘Weak No Trump’ throughout and ‘Strong Two’ openings. +++++++++++++++++++++++++++++++++++++ INDEX Section 1 Introduction Chapter 1 Bidding objectives & scoring Chapter 2 Evaluating the strength of your hand Chapter 3 Evaluating the shape of your hand . Section 2 Balanced Hands Chapter 21 1NT opening bid & No Trumps responses Chapter 22 1NT opening bid & suit responses Chapter 23 Opening bids with stronger balanced hands Chapter 24 Supporting responder’s major suit Chapter 25 2NT opening bid & responses Chapter 26 2 Clubs opening bid & responses Chapter 27 No Trumps responses after an opening suit bid Chapter 28 Summary of bidding with Balanced Hands . -
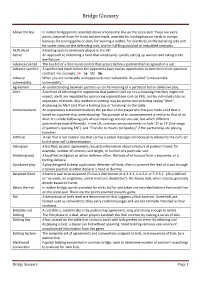
Bridge Glossary
Bridge Glossary Above the line In rubber bridge points recorded above a horizontal line on the score-pad. These are extra points, beyond those for tricks bid and made, awarded for holding honour cards in trumps, bonuses for scoring game or slam, for winning a rubber, for overtricks on the declaring side and for under-tricks on the defending side, and for fulfilling doubled or redoubled contracts. ACOL/Acol A bidding system commonly played in the UK. Active An approach to defending a hand that emphasizes quickly setting up winners and taking tricks. See Passive Advance cue bid The cue bid of a first round control that occurs before a partnership has agreed on a suit. Advance sacrifice A sacrifice bid made before the opponents have had an opportunity to determine their optimum contract. For example: 1♦ - 1♠ - Dbl - 5♠. Adverse When you are vulnerable and opponents non-vulnerable. Also called "unfavourable vulnerability vulnerability." Agreement An understanding between partners as to the meaning of a particular bid or defensive play. Alert A method of informing the opponents that partner's bid carries a meaning that they might not expect; alerts are regulated by sponsoring organizations such as EBU, and by individual clubs or organisers of events. Any method of alerting may be authorised including saying "Alert", displaying an Alert card from a bidding box or 'knocking' on the table. Announcement An explanatory statement made by the partner of the player who has just made a bid that is based on a partnership understanding. The purpose of an announcement is similar to that of an Alert. -

Learning to Communicate Implicitly by Actions
The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20) Learning to Communicate Implicitly by Actions Zheng Tian,1 Shihao Zou,1 Ian Davies,1 Tim Warr,1 Lisheng Wu,1 Haitham Bou Ammar,1,2 Jun Wang1 1University College London, 2Huawei R&DUK {zheng.tian.11, shihao.zou.17, ian.davies.12, tim.warr.17, lisheng.wu.17}@ucl.ac.uk [email protected] [email protected] Abstract for facilitating collaboration in MARL, explicit communica- tion channels come at additional computational and memory In situations where explicit communication is limited, human costs, making them difficult to deploy in decentralized con- collaborators act by learning to: (i) infer meaning behind their trol (Roth, Simmons, and Veloso 2006). partner’s actions, and (ii) convey private information about the state to their partner implicitly through actions. The first Environments where explicit communication is difficult component of this learning process has been well-studied in or prohibited are common. These settings can be synthetic multi-agent systems, whereas the second — which is equally such as those in games, e.g., bridge and Hanabi, but also crucial for successful collaboration — has not. To mimic both frequently appear in real-world tasks such as autonomous components mentioned above, thereby completing the learn- driving and autonomous fleet control. In these situations, ing process, we introduce a novel algorithm: Policy Belief humans rely upon implicit communication as a means of in- Learning (PBL). PBL uses a belief module to model the other formation exchange (Rasouli, Kotseruba, and Tsotsos 2017) agent’s private information and a policy module to form a and are effective in learning to infer the implicit meaning be- distribution over actions informed by the belief module. -

Teamwork Exercises and Technological Problem Solving By
Teamwork Exercises and Technological Problem Solving with First-Year Engineering Students: An Experimental Study Mark R. Springston Dissertation submitted to the faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Curriculum and Instruction Dr. Mark E. Sanders, Chair Dr. Cecile D. Cachaper Dr. Richard M. Goff Dr. Susan G. Magliaro Dr. Tom M. Sherman July 28th, 2005 Blacksburg, Virginia Keywords: Technology Education, Engineering Design Activity, Teams, Teamwork, Technological Problem Solving, and Educational Software © 2005, Mark R. Springston Teamwork Exercises and Technological Problem Solving with First-Year Engineering Students: An Experimental Study by Mark R. Springston Technology Education Virginia Polytechnic Institute and State University ABSTRACT An experiment was conducted investigating the utility of teamwork exercises and problem structure for promoting technological problem solving in a student team context. The teamwork exercises were designed for participants to experience a high level of psychomotor coordination and cooperation with their teammates. The problem structure treatment was designed based on small group research findings on brainstorming, information processing, and problem formulation. First-year college engineering students (N = 294) were randomly assigned to three levels of team size (2, 3, or 4 members) and two treatment conditions: teamwork exercises and problem structure (N = 99 teams). In addition, the study included three non- manipulated, independent variables: team gender, team temperament, and team teamwork orientation. Teams were measured on technological problem solving through two conceptually related technological tasks or engineering design activities: a computer bridge task and a truss model task. The computer bridge score and the number of computer bridge design iterations, both within subjects factors (time), were recorded in pairs over four 30-minute intervals. -

A Gold-Colored Rose
Co-ordinator: Jean-Paul Meyer – Editor: Brent Manley – Assistant Editors: Mark Horton, Brian Senior & Franco Broccoli – Layout Editor: Akis Kanaris – Photographer: Ron Tacchi Issue No. 13 Thursday, 22 June 2006 A Gold-Colored Rose VuGraph Programme Teatro Verdi 10.30 Open Pairs Final 1 15.45 Open Pairs Final 2 TODAY’S PROGRAMME Open and Women’s Pairs (Final) 10.30 Session 1 15.45 Session 2 Rosenblum winners: the Rose Meltzer team IMP Pairs 10.30 Final A, Final B - Session 1 In 2001, Geir Helgemo and Tor Helness were on the Nor- 15.45 Final A, Final B - Session 2 wegian team that lost to Rose Meltzer's squad in the Bermu- Senior Pairs da Bowl. In Verona, they joined Meltzer, Kyle Larsen,Alan Son- 10.30 Session 5 tag and Roger Bates to earn their first world championship – 15.45 Session 6 the Rosenblum Cup. It wasn't easy, as the valiant team captained by Christal Hen- ner-Welland team mounted a comeback toward the end of Contents the 64-board match that had Meltzer partisans worried.The rally fizzled out, however, and Meltzer won handily, 179-133. Results . 2-6 The bronze medal went to Yadlin, 69-65 winners over Why University Bridge? . .7 Welland in the play-off. Left out of yesterday's report were Osservatorio . .8 the McConnell bronze medallists – Katt-Bridge, 70-67 win- Championship Diary . .9 ners over China Global Times. Comeback Time . .10 As the tournament nears its conclusion, the pairs events are The Playing World Represented by Precious Cartier Jewels . -

2000 Bridge Bulletin Index
2000 Bridge Bulletin Index ACBL BRIDGE HALL OF FAME. George Rosenkranz named Blackwood Award winner, Meyer Schleifer receives the von Zedtwitz Award C February. Hall of Fame inducts Lou Bluhm, Harry Fishbein, Charles Solomon, George Rosenkranz, Sidney Lazard, Meyer Schleifer and Ira Rubin C October. ACBL BOARD OF DIRECTORS. Highlights from the Boston Board meeting --- February. Election notice C March C May . Highlights of Cincinnati Board meeting C May. Highlights from the Anaheim meeting C October. Election results for 2000 Board C November. ACBL CHARITY FOUNDATION. 2000 Charity Committee appointees named --- February. ACBL CHARITY GAME. Winners C August. ACBL GOODWILL COMMITTEE. 2000 Appointees named --- February. ACBL HALL OF FAME. Rosenkranz wins Blackwood award; Meyer Schleifer is von Zedtwitz award winner C February. ACBL HONORARY MEMBER OF THE YEAR. Chip Martel named for 2000 --- February. ACBL INSTANT MATCHPOINT GAME. Promo C August, September. Results C December. ACBL INTERNATIONAL FUND GAME. Winners C July, November. ACBL PATRON MEMBER LIST. December. ACBL SENIOR GAME. Winners C May. ACE OF CLUBS. Winners of the 1999 contest --- April. AMERICAN BRIDGE ASSOCIATION. Schedule of upcoming national events --- monthly. ANAHEIM NABC. Promos C April --- July. Meltzer squad wins Spingold; Wei-Sender team takes Wagar; District 9 repeats win in GNT-A; District 19 wins GNT-B title; District 13 victorious in GNT-C contest; Zia, Rosenberg top LM Pairs field; Ping, Leung win Red Ribbon; Nugit squad wins Senior Swiss teams C October. Willenken, Silverstein win Fast Open Pairs; Bach and Burgess take IMP Pairs title; Mixed B-A-M winners; 199er Pairs winners; Five-way tie fir Fishbein Trophy; other NABC highlights C November. -

C.C.Tatham & Associates Ltd
C.C.Tatham & Associates Ltd. Consulting Engineers STEPHENSON ROAD I BRIDGE Town of Bracebridge ond Town of H u ntsville Municipol Closs Environmentol Assessment Proiect File prepared by: prepared for C.C. Tatham & Associates Ltd. The Town of Bracebridge and the Town of Huntsville I Banon Drive Bracebridge, ON P1L 0A1 November 17,2014 Tel: (705) 645-7756 Fax: (705)645-8'159 [email protected] CCTA File 212529-1 Toble of Contents 1 lntroduction and Background 1 1.1 I nhoduction/Backg rou nd I 1.2 Class Environmental Assessment Process 2 1.2.1 Class EA Schedules 2 1.2.2 Class EA Terminology 4 1.2.3 SelectedSchedule 4 2 Need & Justification 6 2.1 Existing Conditions and Background 6 2.1.1 StructuralCondition 7 2.1.2 TrafficConditions 10 2.1.3 Utilities 10 2.1.4 HydraulicAssessment 10 2.1.5 Geometry 11 21.6 BarrierProtection 11 2.2 Problem/Opportun ity Statement 11 3 Gonsultation - Study Commencement 12 3,1 Notification 12 3.2 Public Comments 12 3.3 Agency Comments 13 4 Alternative Solutions '14 4.1 Alternative 1 - Do Nothing 14 4.2 Alternative 2 - Rehabilitate the Bridge 4,3 Alternative 3 - Replace the Bridge 5 Environment lnventory 5.1 Natural Environment 5.2 Social Environment 5.2.1 Archaeological lnvestigation 5.2.2 Cultural Heritage Evaluation Report 5.2.3 Property Acquisition 5.3 Physical Environment 5.3.1 Existing Bridge Structure 5.3.2 Existing Approaches 5,3,3 Traffic Operations 5,3,4 Utilities 5.3.5 Hydraulics 5.3.6 Barriers 5.3.7 Geotechnical Considerations 5.4 Economic Environment 6 Evaluation of Alternative Solutions 6.1 Evaluation -

GIB: Imperfect Information in a Computationally Challenging Game
Journal of Artificial Intelligence Research 14 (2001) 303–358 Submitted 10/00; published 6/01 GIB: Imperfect Information in a Computationally Challenging Game Matthew L. Ginsberg [email protected] CIRL 1269 University of Oregon Eugene, OR 97405 USA Abstract This paper investigates the problems arising in the construction of a program to play the game of contract bridge. These problems include both the difficulty of solving the game’s perfect information variant, and techniques needed to address the fact that bridge is not, in fact, a perfect information game. Gib, the program being described, involves five separate technical advances: partition search, the practical application of Monte Carlo techniques to realistic problems, a focus on achievable sets to solve problems inherent in the Monte Carlo approach, an extension of alpha-beta pruning from total orders to arbitrary distributive lattices, and the use of squeaky wheel optimization to find approximately optimal solutions to cardplay problems. Gib is currently believed to be of approximately expert caliber, and is currently the strongest computer bridge program in the world. 1. Introduction Of all the classic games of mental skill, only card games and Go have yet to see the ap- pearance of serious computer challengers. In Go, this appears to be because the game is fundamentally one of pattern recognition as opposed to search; the brute-force techniques that have been so successful in the development of chess-playing programs have failed al- most utterly to deal with Go’s huge branching factor. Indeed, the arguably strongest Go program in the world (Handtalk) was beaten by 1-dan Janice Kim (winner of the 1984 Fuji Women’s Championship) in the 1997 AAAI Hall of Champions after Kim had given the program a monumental 25 stone handicap. -

Bridge for Dummies‰
01_924261 ffirs.qxp 8/17/06 2:49 PM Page i Bridge FOR DUMmIES‰ 2ND EDITION by Eddie Kantar 01_924261 ffirs.qxp 8/17/06 2:49 PM Page iv 01_924261 ffirs.qxp 8/17/06 2:49 PM Page i Bridge FOR DUMmIES‰ 2ND EDITION by Eddie Kantar 01_924261 ffirs.qxp 8/17/06 2:49 PM Page ii Bridge For Dummies®, 2nd Edition Published by Wiley Publishing, Inc. 111 River St. Hoboken, NJ 07030-5774 www.wiley.com Copyright © 2006 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permis- sion of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, 317-572-3447, fax 317-572-4355, or online at http://www. wiley.com/go/permissions. Trademarks: Wiley, the Wiley Publishing logo, For Dummies, the Dummies Man logo, A Reference for the Rest of Us!, The Dummies Way, Dummies Daily, The Fun and Easy Way, Dummies.com and related trade dress are trademarks or registered trademarks of John Wiley & Sons, Inc. and/or its affiliates in the United States and other countries, and may not be used without written permission. -

Beat Them at the One Level Eastbourne Epic
National Poetry Day Tablet scoring - the rhyme and reason Rosen - beat them at the one level Byrne - Ode to two- suited overcalls Gold - time to jump shift? Eastbourne Epic – winners and pictures English Bridge INSIDE GUIDE © All rights reserved From the Chairman 5 n ENGLISH BRIDGE Major Jump Shifts – David Gold 6 is published every two months by the n Heather’s Hints – Heather Dhondy 8 ENGLISH BRIDGE UNION n Bridge Fiction – David Bird 10 n Broadfields, Bicester Road, Double, Bid or Pass? – Andrew Robson 12 Aylesbury HP19 8AZ n Prize Leads Quiz – Mould’s questions 14 n ( 01296 317200 Fax: 01296 317220 Add one thing – Neil Rosen N 16 [email protected] EW n Web site: www.ebu.co.uk Basic Card Play – Paul Bowyer 18 n ________________ Two-suit overcalls – Michael Byrne 20 n World Bridge Games – David Burn 22 Editor: Lou Hobhouse n Raggett House, Bowdens, Somerset, TA10 0DD Ask Frances – Frances Hinden 24 n Beat Today’s Experts – Bird’s questions 25 ( 07884 946870 n [email protected] Sleuth’s Quiz – Ron Klinger’s questions 27 n ________________ Bridge with a Twist – Simon Cochemé 28 n Editorial Board Pairs vs Teams – Simon Cope 30 n Jeremy Dhondy (Chairman), Bridge Ha Ha & Caption Competition 32 n Barry Capal, Lou Hobhouse, Peter Stockdale Poetry special – Various 34 n ________________ Electronic scoring review – Barry Morrison 36 n Advertising Manager Eastbourne results and pictures 38 n Chris Danby at Danby Advertising EBU News, Eastbourne & Calendar 40 n Fir Trees, Hall Road, Hainford, Ask Gordon – Gordon Rainsford 42 n Norwich NR10 3LX -

Applying Case-Based Reasoning to the Game of Bridge
Applying Case-Based Reasoning to the Game of Bridge Jacob Bellamy-McIntyre A dissertation submitted in partial fulfillment of the requirements for the degree of Postgraduate Diploma of Science in Computer Science, University of Auckland, 2008 1 Abstract Bridge provides a challenging problem for Artificial Intelligence research due to the game being stochastic (from the shuffling of the cards), hidden information (from not being able to see opponents cards) and from the general complexities of the game. Research into Computer Bridge is in its relative infancy, with the American Contract Bridge League holding the first World Championships Computer Bridge competition in 1997. With Bridge being a game that is more probabilistic and intuitive than Chess, it may be a better avenue of research for evaluating human-like intelligence. This paper will explore the possibility of applying Case Base Reasoning to the game of Bridge and will discuss the problems that arise from trying to do so, while comparing Case Base Reasoning to other techniques used in Artificial Intelligence. 2 Table of Contents 1. Case-Based Reasoning 1.1 Introduction ……………………………… 5 1.2 The Domain and Adaptation …………….. 8 1.3 The Case and the Case Base …………….. 10 1.4 The Similarity Function …………………. 11 2. Games in AI 2.1 Introduction ………………………………………….14 2.2 Chess ………………………………………………. 15 2.3 Checkers …………………………………………… 17 2.4 Poker ………………………………………………. 19 2.5 Bridge ……………………………………………… 25 2.6 Other Games ……………………………………... 28 3. The Game of Bridge 3.1 Introduction to Bridge ………………………........... 30 3.2 The Bidding Phase …………………………….…… 30 3.3 Play of the Hand …………………………………... 31 3.4 The Value of a Hand ……………………………….