Multi-Transcriptomic Analysis Points to Early Organelle Dysfunction in Human Astrocytes in Alzheimer’S Disease
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Anti-Rab11 Antibody (ARG41900)
Product datasheet [email protected] ARG41900 Package: 100 μg anti-Rab11 antibody Store at: -20°C Summary Product Description Goat Polyclonal antibody recognizes Rab11 Tested Reactivity Hu, Ms, Rat, Dog, Mk Tested Application IHC-Fr, IHC-P, WB Host Goat Clonality Polyclonal Isotype IgG Target Name Rab11 Antigen Species Mouse Immunogen Purified recombinant peptides within aa. 110 to the C-terminus of Mouse Rab11a, Rab11b and Rab11c (Rab25). Conjugation Un-conjugated Alternate Names RAB11A: Rab-11; Ras-related protein Rab-11A; YL8 RAB11B: GTP-binding protein YPT3; H-YPT3; Ras-related protein Rab-11B RAB25: RAB11C; CATX-8; Ras-related protein Rab-25 Application Instructions Application table Application Dilution IHC-Fr 1:100 - 1:400 IHC-P 1:100 - 1:400 WB 1:250 - 1:2000 Application Note IHC-P: Antigen Retrieval: Heat mediation was recommended. * The dilutions indicate recommended starting dilutions and the optimal dilutions or concentrations should be determined by the scientist. Positive Control Hepa cell lysate Calculated Mw 24 kDa Observed Size ~ 26 kDa Properties Form Liquid Purification Affinity purification with immunogen. Buffer PBS, 0.05% Sodium azide and 20% Glycerol. Preservative 0.05% Sodium azide www.arigobio.com 1/3 Stabilizer 20% Glycerol Concentration 3 mg/ml Storage instruction For continuous use, store undiluted antibody at 2-8°C for up to a week. For long-term storage, aliquot and store at -20°C. Storage in frost free freezers is not recommended. Avoid repeated freeze/thaw cycles. Suggest spin the vial prior to opening. The antibody solution should be gently mixed before use. Note For laboratory research only, not for drug, diagnostic or other use. -

A Novel Approach to Identify Driver Genes Involved in Androgen-Independent Prostate Cancer
Schinke et al. Molecular Cancer 2014, 13:120 http://www.molecular-cancer.com/content/13/1/120 RESEARCH Open Access A novel approach to identify driver genes involved in androgen-independent prostate cancer Ellyn N Schinke1, Victor Bii1, Arun Nalla1, Dustin T Rae1, Laura Tedrick1, Gary G Meadows1 and Grant D Trobridge1,2* Abstract Background: Insertional mutagenesis screens have been used with great success to identify oncogenes and tumor suppressor genes. Typically, these screens use gammaretroviruses (γRV) or transposons as insertional mutagens. However, insertional mutations from replication-competent γRVs or transposons that occur later during oncogenesis can produce passenger mutations that do not drive cancer progression. Here, we utilized a replication-incompetent lentiviral vector (LV) to perform an insertional mutagenesis screen to identify genes in the progression to androgen-independent prostate cancer (AIPC). Methods: Prostate cancer cells were mutagenized with a LV to enrich for clones with a selective advantage in an androgen-deficient environment provided by a dysregulated gene(s) near the vector integration site. We performed our screen using an in vitro AIPC model and also an in vivo xenotransplant model for AIPC. Our approach identified proviral integration sites utilizing a shuttle vector that allows for rapid rescue of plasmids in E. coli that contain LV long terminal repeat (LTR)-chromosome junctions. This shuttle vector approach does not require PCR amplification and has several advantages over PCR-based techniques. Results: Proviral integrations were enriched near prostate cancer susceptibility loci in cells grown in androgen- deficient medium (p < 0.001), and five candidate genes that influence AIPC were identified; ATPAF1, GCOM1, MEX3D, PTRF, and TRPM4. -

Whole-Genome Microarray Detects Deletions and Loss of Heterozygosity of Chromosome 3 Occurring Exclusively in Metastasizing Uveal Melanoma
Anatomy and Pathology Whole-Genome Microarray Detects Deletions and Loss of Heterozygosity of Chromosome 3 Occurring Exclusively in Metastasizing Uveal Melanoma Sarah L. Lake,1 Sarah E. Coupland,1 Azzam F. G. Taktak,2 and Bertil E. Damato3 PURPOSE. To detect deletions and loss of heterozygosity of disease is fatal in 92% of patients within 2 years of diagnosis. chromosome 3 in a rare subset of fatal, disomy 3 uveal mela- Clinical and histopathologic risk factors for UM metastasis noma (UM), undetectable by fluorescence in situ hybridization include large basal tumor diameter (LBD), ciliary body involve- (FISH). ment, epithelioid cytomorphology, extracellular matrix peri- ϩ ETHODS odic acid-Schiff-positive (PAS ) loops, and high mitotic M . Multiplex ligation-dependent probe amplification 3,4 5 (MLPA) with the P027 UM assay was performed on formalin- count. Prescher et al. showed that a nonrandom genetic fixed, paraffin-embedded (FFPE) whole tumor sections from 19 change, monosomy 3, correlates strongly with metastatic death, and the correlation has since been confirmed by several disomy 3 metastasizing UMs. Whole-genome microarray analy- 3,6–10 ses using a single-nucleotide polymorphism microarray (aSNP) groups. Consequently, fluorescence in situ hybridization were performed on frozen tissue samples from four fatal dis- (FISH) detection of chromosome 3 using a centromeric probe omy 3 metastasizing UMs and three disomy 3 tumors with Ͼ5 became routine practice for UM prognostication; however, 5% years’ metastasis-free survival. to 20% of disomy 3 UM patients unexpectedly develop metas- tases.11 Attempts have therefore been made to identify the RESULTS. Two metastasizing UMs that had been classified as minimal region(s) of deletion on chromosome 3.12–15 Despite disomy 3 by FISH analysis of a small tumor sample were found these studies, little progress has been made in defining the key on MLPA analysis to show monosomy 3. -

Supplemental Table S1
Entrez Gene Symbol Gene Name Affymetrix EST Glomchip SAGE Stanford Literature HPA confirmed Gene ID Profiling profiling Profiling Profiling array profiling confirmed 1 2 A2M alpha-2-macroglobulin 0 0 0 1 0 2 10347 ABCA7 ATP-binding cassette, sub-family A (ABC1), member 7 1 0 0 0 0 3 10350 ABCA9 ATP-binding cassette, sub-family A (ABC1), member 9 1 0 0 0 0 4 10057 ABCC5 ATP-binding cassette, sub-family C (CFTR/MRP), member 5 1 0 0 0 0 5 10060 ABCC9 ATP-binding cassette, sub-family C (CFTR/MRP), member 9 1 0 0 0 0 6 79575 ABHD8 abhydrolase domain containing 8 1 0 0 0 0 7 51225 ABI3 ABI gene family, member 3 1 0 1 0 0 8 29 ABR active BCR-related gene 1 0 0 0 0 9 25841 ABTB2 ankyrin repeat and BTB (POZ) domain containing 2 1 0 1 0 0 10 30 ACAA1 acetyl-Coenzyme A acyltransferase 1 (peroxisomal 3-oxoacyl-Coenzyme A thiol 0 1 0 0 0 11 43 ACHE acetylcholinesterase (Yt blood group) 1 0 0 0 0 12 58 ACTA1 actin, alpha 1, skeletal muscle 0 1 0 0 0 13 60 ACTB actin, beta 01000 1 14 71 ACTG1 actin, gamma 1 0 1 0 0 0 15 81 ACTN4 actinin, alpha 4 0 0 1 1 1 10700177 16 10096 ACTR3 ARP3 actin-related protein 3 homolog (yeast) 0 1 0 0 0 17 94 ACVRL1 activin A receptor type II-like 1 1 0 1 0 0 18 8038 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 1 0 0 0 0 19 8751 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 1 0 0 0 0 20 8728 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 1 0 0 0 0 21 81792 ADAMTS12 ADAM metallopeptidase with thrombospondin type 1 motif, 12 1 0 0 0 0 22 9507 ADAMTS4 ADAM metallopeptidase with thrombospondin type 1 -

Protein Interaction Network of Alternatively Spliced Isoforms from Brain Links Genetic Risk Factors for Autism
ARTICLE Received 24 Aug 2013 | Accepted 14 Mar 2014 | Published 11 Apr 2014 DOI: 10.1038/ncomms4650 OPEN Protein interaction network of alternatively spliced isoforms from brain links genetic risk factors for autism Roser Corominas1,*, Xinping Yang2,3,*, Guan Ning Lin1,*, Shuli Kang1,*, Yun Shen2,3, Lila Ghamsari2,3,w, Martin Broly2,3, Maria Rodriguez2,3, Stanley Tam2,3, Shelly A. Trigg2,3,w, Changyu Fan2,3, Song Yi2,3, Murat Tasan4, Irma Lemmens5, Xingyan Kuang6, Nan Zhao6, Dheeraj Malhotra7, Jacob J. Michaelson7,w, Vladimir Vacic8, Michael A. Calderwood2,3, Frederick P. Roth2,3,4, Jan Tavernier5, Steve Horvath9, Kourosh Salehi-Ashtiani2,3,w, Dmitry Korkin6, Jonathan Sebat7, David E. Hill2,3, Tong Hao2,3, Marc Vidal2,3 & Lilia M. Iakoucheva1 Increased risk for autism spectrum disorders (ASD) is attributed to hundreds of genetic loci. The convergence of ASD variants have been investigated using various approaches, including protein interactions extracted from the published literature. However, these datasets are frequently incomplete, carry biases and are limited to interactions of a single splicing isoform, which may not be expressed in the disease-relevant tissue. Here we introduce a new interactome mapping approach by experimentally identifying interactions between brain-expressed alternatively spliced variants of ASD risk factors. The Autism Spliceform Interaction Network reveals that almost half of the detected interactions and about 30% of the newly identified interacting partners represent contribution from splicing variants, emphasizing the importance of isoform networks. Isoform interactions greatly contribute to establishing direct physical connections between proteins from the de novo autism CNVs. Our findings demonstrate the critical role of spliceform networks for translating genetic knowledge into a better understanding of human diseases. -

Primate Specific Retrotransposons, Svas, in the Evolution of Networks That Alter Brain Function
Title: Primate specific retrotransposons, SVAs, in the evolution of networks that alter brain function. Olga Vasieva1*, Sultan Cetiner1, Abigail Savage2, Gerald G. Schumann3, Vivien J Bubb2, John P Quinn2*, 1 Institute of Integrative Biology, University of Liverpool, Liverpool, L69 7ZB, U.K 2 Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK 3 Division of Medical Biotechnology, Paul-Ehrlich-Institut, Langen, D-63225 Germany *. Corresponding author Olga Vasieva: Institute of Integrative Biology, Department of Comparative genomics, University of Liverpool, Liverpool, L69 7ZB, [email protected] ; Tel: (+44) 151 795 4456; FAX:(+44) 151 795 4406 John Quinn: Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK, [email protected]; Tel: (+44) 151 794 5498. Key words: SVA, trans-mobilisation, behaviour, brain, evolution, psychiatric disorders 1 Abstract The hominid-specific non-LTR retrotransposon termed SINE–VNTR–Alu (SVA) is the youngest of the transposable elements in the human genome. The propagation of the most ancient SVA type A took place about 13.5 Myrs ago, and the youngest SVA types appeared in the human genome after the chimpanzee divergence. Functional enrichment analysis of genes associated with SVA insertions demonstrated their strong link to multiple ontological categories attributed to brain function and the disorders. SVA types that expanded their presence in the human genome at different stages of hominoid life history were also associated with progressively evolving behavioural features that indicated a potential impact of SVA propagation on a cognitive ability of a modern human. -

Noninvasive Sleep Monitoring in Large-Scale Screening of Knock-Out Mice
bioRxiv preprint doi: https://doi.org/10.1101/517680; this version posted January 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Noninvasive sleep monitoring in large-scale screening of knock-out mice reveals novel sleep-related genes Shreyas S. Joshi1*, Mansi Sethi1*, Martin Striz1, Neil Cole2, James M. Denegre2, Jennifer Ryan2, Michael E. Lhamon3, Anuj Agarwal3, Steve Murray2, Robert E. Braun2, David W. Fardo4, Vivek Kumar2, Kevin D. Donohue3,5, Sridhar Sunderam6, Elissa J. Chesler2, Karen L. Svenson2, Bruce F. O'Hara1,3 1Dept. of Biology, University of Kentucky, Lexington, KY 40506, USA, 2The Jackson Laboratory, Bar Harbor, ME 04609, USA, 3Signal solutions, LLC, Lexington, KY 40503, USA, 4Dept. of Biostatistics, University of Kentucky, Lexington, KY 40536, USA, 5Dept. of Electrical and Computer Engineering, University of Kentucky, Lexington, KY 40506, USA. 6Dept. of Biomedical Engineering, University of Kentucky, Lexington, KY 40506, USA. *These authors contributed equally Address for correspondence and proofs: Shreyas S. Joshi, Ph.D. Dept. of Biology University of Kentucky 675 Rose Street 101 Morgan Building Lexington, KY 40506 U.S.A. Phone: (859) 257-2805 FAX: (859) 257-1717 Email: [email protected] Running title: Sleep changes in knockout mice bioRxiv preprint doi: https://doi.org/10.1101/517680; this version posted January 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

1 UST College of Science Department of Biological Sciences
UST College of Science Department of Biological Sciences 1 Pharmacogenomics of Myofascial Pain Syndrome An Undergraduate Thesis Submitted to the Department of Biological Sciences College of Science University of Santo Tomas In Partial Fulfillment of the Requirements for the Degree of Bachelor of Science in Biology Jose Marie V. Lazaga Marc Llandro C. Fernandez May 2021 UST College of Science Department of Biological Sciences 2 PANEL APPROVAL SHEET This undergraduate research manuscript entitled: Pharmacogenomics of Myofascial Pain Syndrome prepared and submitted by Jose Marie V. Lazaga and Marc Llandro C. Fernandez, was checked and has complied with the revisions and suggestions requested by panel members after thorough evaluation. This final version of the manuscript is hereby approved and accepted for submission in partial fulfillment of the requirements for the degree of Bachelor of Science in Biology. Noted by: Asst. Prof. Marilyn G. Rimando, PhD Research adviser, Bio/MicroSem 602-603 Approved by: Bio/MicroSem 603 panel member Bio/MicroSem 603 panel member Date: Date: UST College of Science Department of Biological Sciences 3 DECLARATION OF ORIGINALITY We hereby affirm that this submission is our own work and that, to the best of our knowledge and belief, it contains no material previously published or written by another person nor material to which a substantial extent has been accepted for award of any other degree or diploma of a university or other institute of higher learning, except where due acknowledgement is made in the text. We also declare that the intellectual content of this undergraduate research is the product of our work, even though we may have received assistance from others on style, presentation, and language expression. -

Mouse Rab11fip2 Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Rab11fip2 Knockout Project (CRISPR/Cas9) Objective: To create a Rab11fip2 knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Rab11fip2 gene (NCBI Reference Sequence: NM_001164367 ; Ensembl: ENSMUSG00000040022 ) is located on Mouse chromosome 19. 5 exons are identified, with the ATG start codon in exon 2 and the TAG stop codon in exon 5 (Transcript: ENSMUST00000171986). Exon 2 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 2 starts from the coding region. Exon 2 covers 33.33% of the coding region. The size of effective KO region: ~443 bp. The KO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele gRNA region 5' gRNA region 3' 1 2 5 Legends Exon of mouse Rab11fip2 Knockout region Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section upstream of Exon 2 is aligned with itself to determine if there are tandem repeats. No significant tandem repeat is found in the dot plot matrix. So this region is suitable for PCR screening or sequencing analysis. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 913 bp section downstream of Exon 2 is aligned with itself to determine if there are tandem repeats. -

Distribution of Membrane-Bound Monoamine Oxidase in Bacteria
APPLIED AND ENVIRONMENTAL MICROBIOLOGY, Oct. 1979, p. 565-569 Vol. 38, No. 4 0099-2240/79/10-0565/05$02.00/0 Distribution of Membrane-Bound Monoamine Oxidase in Bacteria YOSHIKATSU MUROOKA,* NOBUYUKI DOI, AND TOKUYA HARADA The Institute ofScientific and Industrial Research, Osaka University, Yamadakami, Suita, Osaka (565), Japan Received for publication 22 March 1979 The distribution of membrane-bound monoamine oxidase in 30 strains of various bacteria was studied. Monoamine oxidase was determined by using an ammonia-selective electrode; analyses were sensitive and easy to perform. The enzyme was found in some strains of the family Enterobacteriaceae, such as Klebsiella, Enterobacter, Escherichia, Salmonella, Serratia, and Proteus. Among strains of other families of bacteria tested, only Pseudomonas aeruginosa IFO 3901, Micrococcus luteus IFO 12708, and Brevibacterium ammoniagenes IAM 1641 had monoamine oxidase activity. In all of these bacteria except B. ammoniagenes, monoamine oxidase was induced by tyramine and was highly specific for tyramine, octopamine, dopamine, and norepinephrine. The enzyme in two strains oxidized histamine or benzylamine. Correlations between the distri- butions of membrane-bound monoamine oxidase and arylsulfatase synthesized in the presence of tyramine were discussed. Monoamine oxidase catalyzes the oxidative monoamine oxidase had broad substrate speci- deamination of monoamines by the following ficity, the enzyme in bacteria can be assayed reaction: R-CH2NH2 + 02+ H20 -+ R-CHO + conveniently by potentiometric measurement of NH3 + H202. ammonia formation with an ammonia-selective The enzyme usually has a broad substrate electrode by the method used for the brain en- specificity in animals and plays a major role in zyme by Meyerson et al. -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine -
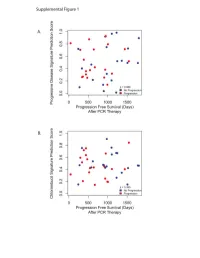
Supplementary Data
Progressive Disease Signature Upregulated probes with progressive disease U133Plus2 ID Gene Symbol Gene Name 239673_at NR3C2 nuclear receptor subfamily 3, group C, member 2 228994_at CCDC24 coiled-coil domain containing 24 1562245_a_at ZNF578 zinc finger protein 578 234224_at PTPRG protein tyrosine phosphatase, receptor type, G 219173_at NA NA 218613_at PSD3 pleckstrin and Sec7 domain containing 3 236167_at TNS3 tensin 3 1562244_at ZNF578 zinc finger protein 578 221909_at RNFT2 ring finger protein, transmembrane 2 1552732_at ABRA actin-binding Rho activating protein 59375_at MYO15B myosin XVB pseudogene 203633_at CPT1A carnitine palmitoyltransferase 1A (liver) 1563120_at NA NA 1560098_at AKR1C2 aldo-keto reductase family 1, member C2 (dihydrodiol dehydrogenase 2; bile acid binding pro 238576_at NA NA 202283_at SERPINF1 serpin peptidase inhibitor, clade F (alpha-2 antiplasmin, pigment epithelium derived factor), m 214248_s_at TRIM2 tripartite motif-containing 2 204766_s_at NUDT1 nudix (nucleoside diphosphate linked moiety X)-type motif 1 242308_at MCOLN3 mucolipin 3 1569154_a_at NA NA 228171_s_at PLEKHG4 pleckstrin homology domain containing, family G (with RhoGef domain) member 4 1552587_at CNBD1 cyclic nucleotide binding domain containing 1 220705_s_at ADAMTS7 ADAM metallopeptidase with thrombospondin type 1 motif, 7 232332_at RP13-347D8.3 KIAA1210 protein 1553618_at TRIM43 tripartite motif-containing 43 209369_at ANXA3 annexin A3 243143_at FAM24A family with sequence similarity 24, member A 234742_at SIRPG signal-regulatory protein gamma