Python: XML, Sockets, Servers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Women's Experimental Autobiography from Counterculture Comics to Transmedia Storytelling: Staging Encounters Across Time, Space, and Medium
Women's Experimental Autobiography from Counterculture Comics to Transmedia Storytelling: Staging Encounters Across Time, Space, and Medium Dissertation Presented in partial fulfillment of the requirement for the Degree Doctor of Philosophy in the Graduate School of Ohio State University Alexandra Mary Jenkins, M.A. Graduate Program in English The Ohio State University 2014 Dissertation Committee: Jared Gardner, Advisor Sean O’Sullivan Robyn Warhol Copyright by Alexandra Mary Jenkins 2014 Abstract Feminist activism in the United States and Europe during the 1960s and 1970s harnessed radical social thought and used innovative expressive forms in order to disrupt the “grand perspective” espoused by men in every field (Adorno 206). Feminist student activists often put their own female bodies on display to disrupt the disembodied “objective” thinking that still seemed to dominate the academy. The philosopher Theodor Adorno responded to one such action, the “bared breasts incident,” carried out by his radical students in Germany in 1969, in an essay, “Marginalia to Theory and Praxis.” In that essay, he defends himself against the students’ claim that he proved his lack of relevance to contemporary students when he failed to respond to the spectacle of their liberated bodies. He acknowledged that the protest movements seemed to offer thoughtful people a way “out of their self-isolation,” but ultimately, to replace philosophy with bodily spectacle would mean to miss the “infinitely progressive aspect of the separation of theory and praxis” (259, 266). Lisa Yun Lee argues that this separation continues to animate contemporary feminist debates, and that it is worth returning to Adorno’s reasoning, if we wish to understand women’s particular modes of theoretical ii insight in conversation with “grand perspectives” on cultural theory in the twenty-first century. -
Blog Title Blog URL Blog Owner Blog Category Technorati Rank
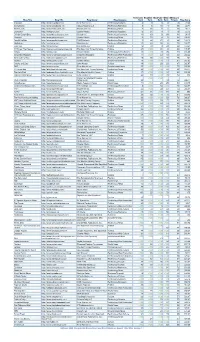
Technorati Bloglines BlogPulse Wikio SEOmoz’s Blog Title Blog URL Blog Owner Blog Category Rank Rank Rank Rank Trifecta Blog Score Engadget http://www.engadget.com Time Warner Inc. Technology/Gadgets 4 3 6 2 78 19.23 Boing Boing http://www.boingboing.net Happy Mutants LLC Technology/Marketing 5 6 15 4 89 33.71 TechCrunch http://www.techcrunch.com TechCrunch Inc. Technology/News 2 27 2 1 76 42.11 Lifehacker http://lifehacker.com Gawker Media Technology/Gadgets 6 21 9 7 78 55.13 Official Google Blog http://googleblog.blogspot.com Google Inc. Technology/Corporate 14 10 3 38 94 69.15 Gizmodo http://www.gizmodo.com/ Gawker Media Technology/News 3 79 4 3 65 136.92 ReadWriteWeb http://www.readwriteweb.com RWW Network Technology/Marketing 9 56 21 5 64 142.19 Mashable http://mashable.com Mashable Inc. Technology/Marketing 10 65 36 6 73 160.27 Daily Kos http://dailykos.com/ Kos Media, LLC Politics 12 59 8 24 63 163.49 NYTimes: The Caucus http://thecaucus.blogs.nytimes.com The New York Times Company Politics 27 >100 31 8 93 179.57 Kotaku http://kotaku.com Gawker Media Technology/Video Games 19 >100 19 28 77 216.88 Smashing Magazine http://www.smashingmagazine.com Smashing Magazine Technology/Web Production 11 >100 40 18 60 283.33 Seth Godin's Blog http://sethgodin.typepad.com Seth Godin Technology/Marketing 15 68 >100 29 75 284 Gawker http://www.gawker.com/ Gawker Media Entertainment News 16 >100 >100 15 81 287.65 Crooks and Liars http://www.crooksandliars.com John Amato Politics 49 >100 33 22 67 305.97 TMZ http://www.tmz.com Time Warner Inc. -

Facebook, Social Media Privacy, and the Use and Abuse of Data
S. HRG. 115–683 FACEBOOK, SOCIAL MEDIA PRIVACY, AND THE USE AND ABUSE OF DATA JOINT HEARING BEFORE THE COMMITTEE ON COMMERCE, SCIENCE, AND TRANSPORTATION UNITED STATES SENATE AND THE COMMITTEE ON THE JUDICIARY UNITED STATES SENATE ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION APRIL 10, 2018 Serial No. J–115–40 Printed for the use of the Committee on Commerce, Science, and Transportation ( Available online: http://www.govinfo.gov VerDate Nov 24 2008 09:24 Nov 08, 2019 Jkt 000000 PO 00000 Frm 00001 Fmt 6011 Sfmt 6011 S:\GPO\DOCS\37801.TXT JACKIE FACEBOOK, SOCIAL MEDIA PRIVACY, AND THE USE AND ABUSE OF DATA VerDate Nov 24 2008 09:24 Nov 08, 2019 Jkt 000000 PO 00000 Frm 00002 Fmt 6019 Sfmt 6019 S:\GPO\DOCS\37801.TXT JACKIE S. HRG. 115–683 FACEBOOK, SOCIAL MEDIA PRIVACY, AND THE USE AND ABUSE OF DATA JOINT HEARING BEFORE THE COMMITTEE ON COMMERCE, SCIENCE, AND TRANSPORTATION UNITED STATES SENATE AND THE COMMITTEE ON THE JUDICIARY UNITED STATES SENATE ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION APRIL 10, 2018 Serial No. J–115–40 Printed for the use of the Committee on Commerce, Science, and Transportation ( Available online: http://www.govinfo.gov U.S. GOVERNMENT PUBLISHING OFFICE 37–801 PDF WASHINGTON : 2019 VerDate Nov 24 2008 09:24 Nov 08, 2019 Jkt 000000 PO 00000 Frm 00003 Fmt 5011 Sfmt 5011 S:\GPO\DOCS\37801.TXT JACKIE SENATE COMMITTEE ON COMMERCE, SCIENCE, AND TRANSPORTATION ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION JOHN THUNE, South Dakota, Chairman ROGER WICKER, Mississippi BILL NELSON, Florida, Ranking ROY BLUNT, Missouri MARIA -

Build “Customer Equity.” They Define a Firm’S Customer Equity As the Total Discounted Lifetime Value of All of Its Customers
9780071458290-Ch-06 10/18/07 3:41 PM Page 115 CHAPTER 6 building customer relationships It has been called the decade of the customer, the customer millennium, and virtually every name that can incorporate “customer” within. There’s nothing new about businesses focusing on customers or wanting to be customer-centered. However, in today’s marketplace just saying an enterprise is “customer-centric” is not enough. It is a promise that organizations must keep. The problem is that most organizations still fall short of this goal. This chapter will address customer management and the variety of techniques used in customer relationship building, nurturing, loyalty, retention, and reactivation. These include Customer Relationship Management (CRM), Customer Performance Management (CPM), Customer Experience Management (CEM), and customer win-back. The objective of these techniques is to help organizations coax the greatest value from their customers. While the strategies are different, all of these methods use the tools and techniques of direct marketing in their execution. What is “Customer-Centric”? There is a clear definition of “customer-centric.” To be customer-centric, an organization must have customers at the center of its business. Many organizations are sales-focused and not marketing-oriented. Many enterprises that have a marketing focus are brand- or product-centric. Being a customer-centered organ- ization is much more complex than it appears. Enterprises can’t just decide to organize around customers. Today, it is often cus- tomers who dictate how an enterprise should be organized to better serve their needs. Customers want their needs met, to be cared for, and to be delighted. -

The Fashion Industry As a Slippery Discursive Site: Tracing the Lines of Flight Between Problem and Intervention
THE FASHION INDUSTRY AS A SLIPPERY DISCURSIVE SITE: TRACING THE LINES OF FLIGHT BETWEEN PROBLEM AND INTERVENTION Nadia K. Dawisha A dissertation submitted to the faculty of the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Communication in the College of Arts and Sciences. Chapel Hill 2016 Approved by: Patricia Parker Sarah Dempsey Steve May Michael Palm Neringa Klumbyte © 2016 Nadia K. Dawisha ALL RIGHTS RESERVED ii ABSTRACT Nadia K. Dawisha: The Fashion Industry as a Slippery Discursive Site: Tracing the Lines of Flight Between Problem and Intervention (Under the direction of Dr. Patricia Parker) At the intersection of the glamorous façade of designer runway shows, such as those in Paris, Milan and New York, and the cheap prices at the local Walmart and Target, is the complicated, somewhat insidious “business” of the fashion industry. It is complicated because it both exploits and empowers, sometimes through the very same practices; it is insidious because its most exploitative practices are often hidden, reproduced, and sustained through a consumer culture in which we are all in some ways complicit. Since fashion’s inception, people and institutions have employed a myriad of discursive strategies to ignore and even justify their complicity in exploitative labor, environmental degradation, and neo-colonial practices. This dissertation identifies and analyzes five predicaments of fashion while locating the multiple interventions that engage various discursive spaces in the fashion industry. Ultimately, the analysis of discursive strategies by creatives, workers, organizers, and bloggers reveals the existence of agile interventions that are as nuanced as the problem, and that can engage with disciplinary power in all these complicated places. -

A Portrait of Fandom Women in The
DAUGHTERS OF THE DIGITAL: A PORTRAIT OF FANDOM WOMEN IN THE CONTEMPORARY INTERNET AGE ____________________________________ A Thesis Presented to The Honors TutoriAl College Ohio University _______________________________________ In PArtiAl Fulfillment of the Requirements for Graduation from the Honors TutoriAl College with the degree of Bachelor of Science in Journalism ______________________________________ by DelAney P. Murray April 2020 Murray 1 This thesis has been approved by The Honors TutoriAl College and the Department of Journalism __________________________ Dr. Eve Ng, AssociAte Professor, MediA Arts & Studies and Women’s, Gender, and Sexuality Studies Thesis Adviser ___________________________ Dr. Bernhard Debatin Director of Studies, Journalism ___________________________ Dr. Donal Skinner DeAn, Honors TutoriAl College ___________________________ Murray 2 Abstract MediA fandom — defined here by the curation of fiction, art, “zines” (independently printed mAgazines) and other forms of mediA creAted by fans of various pop culture franchises — is a rich subculture mAinly led by women and other mArginalized groups that has attracted mAinstreAm mediA attention in the past decAde. However, journalistic coverage of mediA fandom cAn be misinformed and include condescending framing. In order to remedy negatively biAsed framing seen in journalistic reporting on fandom, I wrote my own long form feAture showing the modern stAte of FAndom based on the generation of lAte millenniAl women who engaged in fandom between the eArly age of the Internet and today. This piece is mAinly focused on the modern experiences of women in fandom spaces and how they balAnce a lifelong connection to fandom, professional and personal connections, and ongoing issues they experience within fandom. My study is also contextualized by my studies in the contemporary history of mediA fan culture in the Internet age, beginning in the 1990’s And to the present day. -

1 September 28, 2011 Honorable Jon Leibowitz, Chairman Honorable
September 28, 2011 Honorable Jon Leibowitz, Chairman Honorable William E. Kovacic, Commissioner Honorable J. Thomas Rosch, Commissioner Honorable Edith Ramirez, Commissioner Honorable Julie Brill, Commissioner The Federal Trade Commission 600 Pennsylvania Ave., N.W. Washington, D.C. 20580 Dear Mr. Chairman and Members of the Commission: In light of recent changes announced by Facebook that impact the privacy interests of almost two hundred million Facebook users in the United States, we would like to bring your attention to new privacy and security risks to American consumers, the secret use of persistent identifiers (“cookies”) to track the Internet activity of users even after they have logged off of Facebook, and the company‟s failure to uphold representations it has made regarding its commitments to protect the privacy of its users. Facebook‟s tracking of post-log-out Internet activity violates both the reasonable expectations of consumers and the company‟s own privacy statements. Although Facebook has partially fixed the problem caused by its tracking cookies, the company still places persistent identifiers on users‟ browsers that collect post-log-out data and could be used to identify users.1 “Frictionless sharing” plays a leading role in the changes Facebook announced at the recent f8 development conference, and works through the interaction of Facebook‟s Ticker, Timeline, and Open Graph. These changes in business practices give the company far greater ability to disclose the personal information of its users to its business partners than in the past. Options for users to preserve the privacy standards they have established have become confusing, impractical, and unfair. -

ARI OFSEVIT 10 Lawrence St., Cambridge, MA 02139 • [email protected] • 781.710.1558A
ARI OFSEVIT 10 Lawrence St., Cambridge, MA 02139 • [email protected] • 781.710.1558a Education Massachusetts Institute of Master of Science in Transportation | Master of City Planning | 2019 Technology Research with TransitLab: operations research with Chicago Transit Authority Macalester College Geography | Urban Studies | Bachelor of Arts, cum laude, 2006 Editor, The Mac Weekly | Captain, Nordic ski team | NCAA All-Academic Technical Skills Proficient • ArcGIS | QGIS | Office | HTML | Inkscape Working Knowledge • PHP | R | SQL | Python | Adobe suite | AutoCAD Work Experience Charles River TMA Managed several programs for non-profit transportation management organization in Program and Commun- Cambridge. Worked with educational, employer and real estate members to reduce ications Coordinator drive-alone commuting. Data analysis, reporting and program management for shuttle 2013 – 2016 ridership, emergency ride home and bicycling programs. Appalachian Mountain Club Managed 96-bed backcountry hospitality facility and a staff of 9. Trained new staff in Hutmaster all aspects of the operation and managed communications, requisitions, personnel 2010, 2011, 2013 and safety. Promoted organizational membership, assisted search-and-rescue operations, and oversaw compliance with U.S. Forest Service permit regulations. URS Corporation Organized outreach events to 100+ employers, cities and organizations across MassRIDES Massachusetts. Worked with worksites, universities and municipalities to increase 2012 – 2013 walking, cycling, transit and carpooling while reducing drive-alone commuting. Neighborhood Energy Managed a 25-vehicle, 1000-member, $400k/year car sharing fleet as part of an Connection, HOURCAR energy-efficiency nonprofit in the Twin Cities. Collaborated with local transit, Program Manager government and private development stakeholders to create car sharing-specific 2007 – 2010 planning codes and advocate for alternative mode transportation options. -

30-Minute Social Media Marketing
30-MINUTE SOCIAL MEDIA MARKETING Step-by-Step Techniques to Spread the Word About Your Business FAST AND FREE Susan Gunelius New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto To Scott, for supporting every new opportunity I pursue on and off the social Web and for sending me blog post ideas when I’m too busy to think straight. And to my family and friends for remembering me and welcoming me with open arms when I eventually emerge from behind my computer. Copyright © 2011 by Susan Gunelius. All rights reserved. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher. ISBN: 978-0-07-174865-0 MHID: 0-07-174865-2 The material in this eBook also appears in the print version of this title: ISBN: 978-0-07-174381-5, MHID: 0-07-174381-2. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every oc- currence of a trademarked name, we use names in an editorial fashion only, and to the benefi t of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales promotions, or for use in corporate training programs. -

The Right to Publish Illegally Acquired Information Twenty Years After Bartnicki V
Washington Law Review Volume 96 Number 1 3-1-2021 Hacks, Leaks, and Data Dumps: The Right to Publish Illegally Acquired Information Twenty Years After Bartnicki V. Vopper Erik Ugland Christina Mazzeo Follow this and additional works at: https://digitalcommons.law.uw.edu/wlr Part of the Constitutional Law Commons, First Amendment Commons, and the Privacy Law Commons Recommended Citation Erik Ugland & Christina Mazzeo, Hacks, Leaks, and Data Dumps: The Right to Publish Illegally Acquired Information Twenty Years After Bartnicki V. Vopper, 96 Wash. L. Rev. 139 (2021). This Article is brought to you for free and open access by the Law Reviews and Journals at UW Law Digital Commons. It has been accepted for inclusion in Washington Law Review by an authorized editor of UW Law Digital Commons. For more information, please contact [email protected]. Ugland & Mazzeo (Do Not Delete) 3/22/2021 11:58 AM HACKS, LEAKS, AND DATA DUMPS: THE RIGHT TO PUBLISH ILLEGALLY ACQUIRED INFORMATION TWENTY YEARS AFTER BARTNICKI V. VOPPER Erik Ugland* & Christina Mazzeo** Abstract: This Article addresses a fluid and increasingly salient category of cases involving the First Amendment right to publish information that was hacked, stolen, or illegally leaked by someone else. Twenty years ago, in Bartnicki v. Vopper, the Supreme Court appeared to give broad constitutional cover to journalists and other publishers in these situations, but Justice Stevens’s inexact opinion for the Court and Justice Breyer’s muddling concurrence left the boundaries unclear. The Bartnicki framework is now implicated in dozens of new cases— from the extradition and prosecution of Julian Assange, to Donald Trump’s threatened suit of The New York Times over his tax records, to the civil suits spawned by the hack of DNC servers—so there is a pressing need for clarity. -

How Unfettered Freedom of Speech on the Internet Creates No Recourse for Those Victimized
Catholic University Journal of Law and Technology Volume 26 Issue 1 Article 4 2018 Say What You Want: How Unfettered Freedom of Speech on the Internet Creates No Recourse for Those Victimized Wes Gerrie Follow this and additional works at: https://scholarship.law.edu/jlt Part of the Communications Law Commons, First Amendment Commons, Internet Law Commons, and the Science and Technology Law Commons Recommended Citation Wes Gerrie, Say What You Want: How Unfettered Freedom of Speech on the Internet Creates No Recourse for Those Victimized, 26 Cath. U. J. L. & Tech 26 (2017). Available at: https://scholarship.law.edu/jlt/vol26/iss1/4 This Article is brought to you for free and open access by CUA Law Scholarship Repository. It has been accepted for inclusion in Catholic University Journal of Law and Technology by an authorized editor of CUA Law Scholarship Repository. For more information, please contact [email protected]. SAY WHAT YOU WANT: HOW UNFETTERED FREEDOM OF SPEECH ON THE INTERNET CREATES NO RECOURSE FOR THOSE VICTIMIZED Wes Gerrie+ “There are no saints online.”1 This is a seemingly contemptuous statement about the Internet, a world-altering creation and revolutionary promise of a medium of mass communication, which has opened the global “marketplace of ideas” to all citizens.2 It accomplished this by removing the gatekeepers of “old- world” media such as publishers, editors, and practical limits on immediacy and global reach.3 This “marketplace of ideas” is now open at all hours of the day and night, and any person with an internet connection can “become a town crier with a voice that resonates farther than it could from any soapbox.”4 At no time + Associate, Goldberg Segalla LLP; J.D. -

Digital-Solutions-For-Brand-Building
Table of Contents Introduction – Digital Will Transform Brand Marketing ....................................................... P 3 Are Your Brand’s Consumers Online? ................................................................................... P 4 - 5 E-Commerce – Why Your Kids Won’t Shop for Everyday Brands the Way You Do ............... P 6 - 8 Brand Advertising Online – Using Measurement to Unlock Brand Dollars ......................... P 9 - 11 Leveraging Social Media – Creating Brand Advocates ......................................................... P 12 - 13 Creating Better Marketing Organizations ………...........................................................…. P 14 Conclusion – The Digital Opportunity for Leading Brands ……........................................... P 15 About this Report The data and insights contained in this report are compiled from a range of Nielsen resources. For more information, please visit www.nielsen.com David Wiesenfeld is VP, Brand Advertiser Solutions for Nielsen’s Online Division. In his current role, David leverages Nielsen’s online and broader assets to address a wide range of business issues, specializing in deriving clear, practical recommendations and working closely with clients to institutionalize learning across their organizations. David has 20 years of industry experience, which includes management positions in market research, product development, and consulting. Prior to his current assignment, David worked across Nielsen Company divisions to develop integrated solutions, such