Section 7.9, Combining Marks, and Also Section 2.11, Combining Characters
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BIBLIOGRAPHY N Most Diacritic Letters ( C, I, Ö, ˙ S, Etc.) Are
BIBLIOGRAPHY Notes Most diacritic letters (ˇc,ı, ö, s, etc.) are alphabetized as separate letters after ˙ the base letter. The abbreviation “ms. NAN KR” stands for “manuscript in the Archives of the National Center for Manasology and Artistic Culture of the National Academy of Sciences of the Kyrgyz Republic,” followed by the archival shelf number. In the Commentary and footnotes, the form of some of the bibliographic citations of mid-nineteenth century Kirghiz epics (recorded by Radlof from anonymous bards, published under separate headings in his Obraztsy/ Proben [1885], and re-edited by Hatto in The Manas of Wilhelm Radlof [1990]) is nearly identical to the citations of analytical articles on the texts that Hatto published in various journals. These are the references to the Radlovian epic texts, which were coincidentally published by Hatto in his re-edition: “Almambet, Er Kökˇcöand Ak-Erkeˇc”;“Birth of Manas”; “Birth of Semetey”; “Bok-Murun”; “Köz-Kaman”; and “Semetey.” Hatto’s articles are cited as: Hatto, “Almambet, Er Kökˇcöand Ak Erkeˇc”;Hatto, “Birth of Manas”; Hatto, “Köz-Kaman”; Hatto, “Semetey.” Listed below by language are references to the main bibliographic entries of the dictionaries, grammars, and other aids used, sometimes without citation, in the preparation of this edition: Arabic Baranov, Arabsko–russkii slovar’ Steingass, A Learner’s Arabic–English Dictionary Baˇskir Akhmerov, Bashkirsko–russkii slovar’ Chaghatay Budagov, Sravnitel’nyi slovar’ turetsko–tatarskikh narechii Shcherbak, Grammatika starouzbekskogo iazyka Radlov, Opyt/Versuch Eastern Turki Jarring, An Eastern Turki–English Dialect Dictionary (Uyghur) Nadzhip, Uigursko–russkii slovar’ Kalmyk Ramstedt, Kalmückisches Wörterbuch Kirghiz Batmanov, Sovremennyi kirgizskii iazyk Hu and Imart, A Kirghiz Reader Imart, Le kirghiz Iudakhin, Kirgizsko–russkii slovar’ ———, Russko–kirgizskii slovar’ 374 bibliography Kirghiz (cont.) Muqambaev, Qır ˙gıztilinin dialektologiyalıq sözdügü, vol. -

Jssea 42 (2015-2016) 71
Demotic and Hieratic Scholia in Funerary Papyri and their Implications for the Manufacturing Process1 Foy Scalf Abstract: Many ancient Egyptian papyrus manuscripts inscribed with funerary compositions contain annotations within the text and margins. Some of these annotations relate directly to the production process for illustrating and inscribing the manuscripts by providing instructions for scribes and artists. Two overlooked examples, pKhaemhor (MMA 25.3.212) and pRyerson (OIM E9787), allow for new interpretations of parallel texts previously considered as labels or captions. An analysis of the corpus of scholia and marginalia demonstrates specific manufacturing proclivities for selective groups of texts, while simultaneously revealing a wide variety of possible construction sequences and techniques in others. Résumé: Plusieurs manuscrits anciens de papyrus égyptiens sur lesquels sont inscrites des compositions funéraires contiennent des annotations dans le texte et dans les marges. Certaines de ces annotations sont directement liées au processus de production relatif à l’illustration et à l’inscription des manuscrits en donnant des instructions destinées aux scribes et aux artistes. Deux exemples négligés, le pKhaemhor (MMA 25.3.212) et le pRyerson (OIM E9787), permettent de nouvelles interprétations de textes parallèles précédemment considérés comme des étiquettes ou des légendes. Une analyse du corpus des scholia et marginalia démontre des tendances de fabrication spécifiques pour des groupes particuliers de textes, tout en révélant simultanément une grande variété de séquences et de techniques de construction dans d'autres cas. Keywords: Book of the Dead – Funerary Papyri – Scholia – Marginalia – Hieratic – Demotic Mots-clés: Livre des Morts – Papyrus funéraire – Scholia – Marginalia – hiératique – démotique The production of illustrated funerary papyri in ancient Egypt was a complex and expensive process that often involved the efforts of a team of skilled scribes and artisans. -

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Early-Alphabets-3.Pdf
Early Alphabets Alphabetic characteristics 1 Cretan Pictographs 11 Hieroglyphics 16 The Phoenician Alphabet 24 The Greek Alphabet 31 The Latin Alphabet 39 Summary 53 GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS 1 / 53 Alphabetic characteristics 3,000 BCE Basic building blocks of written language GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 2 / 53 Early visual language systems were disparate and decentralized 3,000 BCE Protowriting, Cuneiform, Heiroglyphs and far Eastern writing all functioned differently Rebuses, ideographs, logograms, and syllabaries · GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 3 / 53 HIEROGLYPHICS REPRESENTING THE REBUS PRINCIPAL · BEE & LEAF · SEA & SUN · BELIEF AND SEASON GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 4 / 53 PETROGLYPHIC PICTOGRAMS AND IDEOGRAPHS · CIRCA 200 BCE · UTAH, UNITED STATES GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 5 / 53 LUWIAN LOGOGRAMS · CIRCA 1400 AND 1200 BCE · TURKEY GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 6 / 53 OLD PERSIAN SYLLABARY · 600 BCE GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 7 / 53 Alphabetic structure marked an enormous societal leap 3,000 BCE Power was reserved for those who could read and write · GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 8 / 53 What is an alphabet? Definition An alphabet is a set of visual symbols or characters used to represent the elementary sounds of a spoken language. –PM · GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 9 / 53 What is an alphabet? Definition They can be connected and combined to make visual configurations signifying sounds, syllables, and words uttered by the human mouth. -

National Rappel Operations Guide
National Rappel Operations Guide 2019 NATIONAL RAPPEL OPERATIONS GUIDE USDA FOREST SERVICE National Rappel Operations Guide i Page Intentionally Left Blank National Rappel Operations Guide ii Table of Contents Table of Contents ..........................................................................................................................ii USDA Forest Service - National Rappel Operations Guide Approval .............................................. iv USDA Forest Service - National Rappel Operations Guide Overview ............................................... vi USDA Forest Service Helicopter Rappel Mission Statement ........................................................ viii NROG Revision Summary ............................................................................................................... x Introduction ...................................................................................................... 1—1 Administration .................................................................................................. 2—1 Rappel Position Standards ................................................................................. 2—6 Rappel and Cargo Letdown Equipment .............................................................. 4—1 Rappel and Cargo Letdown Operations .............................................................. 5—1 Rappel and Cargo Operations Emergency Procedures ........................................ 6—1 Documentation ................................................................................................ -

Sinitic Language and Script in East Asia: Past and Present
SINO-PLATONIC PAPERS Number 264 December, 2016 Sinitic Language and Script in East Asia: Past and Present edited by Victor H. Mair Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established, scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin (MSM) and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino- Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out to be refereed, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. -

Old Cyrillic in Unicode*
Old Cyrillic in Unicode* Ivan A Derzhanski Institute for Mathematics and Computer Science, Bulgarian Academy of Sciences [email protected] The current version of the Unicode Standard acknowledges the existence of a pre- modern version of the Cyrillic script, but its support thereof is limited to assigning code points to several obsolete letters. Meanwhile mediæval Cyrillic manuscripts and some early printed books feature a plethora of letter shapes, ligatures, diacritic and punctuation marks that want proper representation. (In addition, contemporary editions of mediæval texts employ a variety of annotation signs.) As generally with scripts that predate printing, an obvious problem is the abundance of functional, chronological, regional and decorative variant shapes, the precise details of whose distribution are often unknown. The present contents of the block will need to be interpreted with Old Cyrillic in mind, and decisions to be made as to which remaining characters should be implemented via Unicode’s mechanism of variation selection, as ligatures in the typeface, or as code points in the Private space or the standard Cyrillic block. I discuss the initial stage of this work. The Unicode Standard (Unicode 4.0.1) makes a controversial statement: The historical form of the Cyrillic alphabet is treated as a font style variation of modern Cyrillic because the historical forms are relatively close to the modern appearance, and because some of them are still in modern use in languages other than Russian (for example, U+0406 “I” CYRILLIC CAPITAL LETTER I is used in modern Ukrainian and Byelorussian). Some of the letters in this range were used in modern typefaces in Russian and Bulgarian. -

National Diploma in Calligraphy Helpful Hints for FOUNDATION Diploma Module A
National Diploma in Calligraphy Helpful hints for FOUNDATION Diploma Module A THE LETTERFORM ANALYSIS “In A4 format make an analysis of the letter-forms of an historical manuscript which reflects your chosen basic hand. Your analysis should include x-height, letter formation and construction, heights of ascenders and descenders, etc. This can be in the form of notes added to enlarged photocopies of a relevant historical manuscript, together with your own lettering studies” At this first level, you will be working with one basic hand only and its associated capitals. This will be either Foundational (Roundhand) in which case study the Ramsey Psalter, or Formal Italic, where you can study a hand by Arrighi or Francisco Lucas, or other fine Italian scribe. Find enlarged detailed illustrations from ‘Historical Scripts by Stan Knight, or A Book of Scripts, by A Fairbank, or search the internet. Stan Knight’s book is the ‘bible’ because the enlargements are clear and at least 5mm or larger body height – this is the ideal. Show by pencil lines & measurements on the enlargement how you have worked out the pen angle, nib-widths, ascender & descender heights and shape of O, arch formations etc, use a separate sheet to write down this information, perhaps as numbered or bullet points, such as: 1. Pen angle 2. 'x'height 3. 'o'form 4, 5,6 Number of strokes to each letter, their order, direction: - make a general observation, and then refer the reader to the alphabet (s) you will have written (see below), on which you will have added the stroke order and directions to each letter by numbered pencil arrows. -
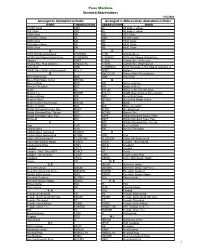
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

Typing in Greek Sarah Abowitz Smith College Classics Department
Typing in Greek Sarah Abowitz Smith College Classics Department Windows 1. Down at the lower right corner of the screen, click the letters ENG, then select Language Preferences in the pop-up menu. If these letters are not present at the lower right corner of the screen, open Settings, click on Time & Language, then select Region & Language in the sidebar to get to the proper screen for step 2. 2. When this window opens, check if Ελληνικά/Greek is in the list of keyboards on your computer under Languages. If so, go to step 3. Otherwise, click Add A New Language. Clicking Add A New Language will take you to this window. Look for Ελληνικά/Greek and click it. When you click Ελληνικά/Greek, the language will be added and you will return to the previous screen. 3. Now that Ελληνικά is listed in your computer’s languages, click it and then click Options. 4. Click Add A Keyboard and add the Greek Polytonic option. If you started this tutorial without the pictured keyboard menu in step 1, it should be in the lower right corner of your screen now. 5. To start typing in Greek, click the letters ENG next to the clock in the lower right corner of the screen. Choose “Greek Polytonic keyboard” to start typing in greek, and click “US keyboard” again to go back to English. Mac 1. Click the apple button in the top left corner of your screen. From the drop-down menu, choose System Preferences. When the window below appears, click the “Keyboard” icon.