Open Journal Systems and Dataverse Integration-- Helping Journals to Upgrade Data Publication for Reusable Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Editorial Project News and Events
Issue 6 July 2010 – January 2011 ■ Editorial Project News ■ Project no. 212879 ■ EU News and Events ■ Useful Links and Documents This e-newsletter can be downloaded at the following address: http://www.euroris-net.eu/ ■ Editorial Research Infrastructures are at the ‘heart” of European Research Area, according to the FP7 Interim Evaluation report, published in October 2010. During the last semester, there were changes in Chairs of both ESFRI and e-IRG, whereas, both an e-IRG blue paper (requested by ESFRI) and ESFRI TWG documents have been produced, to support decision making procedures, which will significantly move RIs forward, despite the worldwide economic crisis. The presentations and discussion held during the International Conference on RIs in Rome (http://www.euroris-net.eu/News/project_news) highlight - among other issues - the socio-economic benefits stemming from Research Infrastructures, built with a global perspective and requiring an international cooperation setting, fully aligned with the European Research and Innovation Strategy. In the current issue, you can read information on the outcomes of important RI events in which EuroRIs- Net actively participated throughout this period, with dynamic contribution both in the dissemination of the benefits of RI programme to research communities, and to the broader dialogue with all FP7 thematic areas covered within the Research Infrastructures programme. ■ Project News and Events 1. International Conference on Research Infrastructures, 30th September 2010, Rome, Italy An International Conference on Research Infrastructures was organized by APRE in collaboration with the European Commission, the Italian Ministry of Research, the National Research Council and the National Institute of Astrophysics, within the framework of the EuroRIs-Net project. -

Open Access Publishing
Open Access The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Suber, Peter. 2012. Open access. Cambridge, Mass: MIT Press. [Updates and Supplements: http://cyber.law.harvard.edu/hoap/ Open_Access_(the_book)] Published Version http://mitpress.mit.edu/books/open-access Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:10752204 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA OPEN ACCESS The MIT Press Essential Knowledge Series Information and the Modern Corporation, James Cortada Intellectual Property Strategy, John Palfrey Open Access, Peter Suber OPEN ACCESS PETER SUBER TheMIT Press | Cambridge, Massachusetts | London, England © 2012 Massachusetts Institute of Technology This work is licensed under the Creative Commons licenses noted below. To view a copy of these licenses, visit creativecommons.org. Other than as provided by these licenses, no part of this book may be reproduced, transmitted, or displayed by any electronic or mechanical means without permission from the publisher or as permitted by law. This book incorporates certain materials previously published under a CC-BY license and copyright in those underlying materials is owned by SPARC. Those materials remain under the CC-BY license. Effective June 15, 2013, this book will be subject to a CC-BY-NC license. MIT Press books may be purchased at special quantity discounts for business or sales promotional use. -

Uso De Open Journal System En Revistas Científicas Peruanas Using Open Journal Systems in Peruvian Scientific Journals
Cultura, 2018, 32, 353-366 Uso(enero de Open- diciembre) Journal System en revistas científicashttps://doi.org/10.24265/cultura.2018.v32.16 peruanas ISSN (Impreso): 1817-0285 ISSN (Digital): 2224-3585 Uso de Open Journal System en revistas científicas peruanas Using Open Journal Systems in Peruvian scientific journals Victoria Yance-Yupari* Escuela Profesional de Psicología, Universidad de San Martín de Porres, Perú Recibido: 2 de setiembre de 2018 Aceptado: 16 de octubre de 2018 Resumen El uso del Open Journal Systems en el Perú se ha incrementado en la difusión y visibilidad de revistas científicas de acceso abierto. Conocer e indagar el uso del software en las revistas publicadas por universidades peruanas es necesario para identificar la vigencia y actividad en la que se encuentran. Este, es un estudio exploratorio que tiene una muestra conformada por 54 universidades peruanas, en la que se encontró 324 títulos, que evidenció la totalidad de revistas en acceso abierto; 71% son publicadas por universidades particulares; 27 títulos no tiene ninguna publicación en la plataforma; la versión 2.0 es utilizada por el 73%; la versión 3.0 la utilizan solo 74 revistas. Palabras clave: Open Journal System, OJS, revistas científicas, Perú. Abstract The use of Open Journal Systems in Peru is recent, and its dissemination and visibility in scientific journals are increasing. Knowing and investigating the use of the software in journals published by Peruvian universities are necessary to identify validity and activity in which they are. In the exploratory -

Download Full White Paper
Open Access White Paper University of Oregon SENATE SUB-COMMITTEE ON OPEN ACCESS I. Executive Summary II. Introduction a. Definition and History of the Open Access Movement b. History of Open Access at the University of Oregon c. The Senate Subcommittee on Open Access at the University of Oregon III. Overview of Current Open Access Trends and Practices a. Open Access Formats b. Advantages and Challenges of the Open Access Approach IV. OA in the Process of Research & Dissemination of Scholarly Works at UO a. A Summary of Current Circumstances b. Moving Towards Transformative Agreements c. Open Access Publishing at UO V. Advancing Open Access at the University of Oregon and Beyond a. Barriers to Moving Forward with OA b. Suggestions for Local Action at UO 1 Executive Summary The state of global scholarly communications has evolved rapidly over the last two decades, as libraries, funders and some publishers have sought to hasten the spread of more open practices for the dissemination of results in scholarly research worldwide. These practices have become collectively known as Open Access (OA), defined as "the free, immediate, online availability of research articles combined with the rights to use these articles fully in the digital environment." The aim of this report — the Open Access White Paper by the Senate Subcommittee on Open Access at the University of Oregon — is to review the factors that have precipitated these recent changes and to explain their relevance for members of the University of Oregon community. Open Access History and Trends Recently, the OA movement has gained momentum as academic institutions around the globe have begun negotiating and signing creative, new agreements with for-profit commercial publishers, and as innovations to the business models for disseminating scholarly research have become more widely adopted. -

Riviste Italiane Digitali E Digitalizzate Ad Accesso Libero Un Contributo Per L’Emeroteca Digitale Nazionale
Biblioteca nazionale centrale Roma RIDI Riviste italiane digitali e digitalizzate ad accesso libero Un contributo per l’emeroteca digitale nazionale a cura di Giulio Palanga Work in progress 10 dicembre 2019-27 aprile 2021 PRINCIPALI PIATTAFORME INTERNAZIONALI Annex http://www.annexpublishers.com/ Annex Publishers è stato istituito con l'obiettivo di diffondere le informazioni tra la comunità scientifica. E’ stato inserito nella Lista di Beall degli editori predatori. (82) Dove medical press https://www.dovepress.com/browse_journals.php Editore accademico di riviste scientifiche e mediche, con uffici a Manchester, Londra, Princeton, New Jersey e Auckland. A settembre 2017, Dove Medical Press è stata acquisita da Taylor e Francis Group (92) Elsevier Open Access Journals https://www.elsevier.com/about/open-science/open-access/open-access- journals Elsevier ha stipulato un accordo con il Consorzio della CRUI, Conferenza dei rettori delle Università italiane, per incentivare gli autori italiani FreeMedical Journals http://www.freemedicaljournals.com/ Riviste mediche (5088) Highwire http://highwire.stanford.edu/lists/allsites.dtl Nato dall'Università di Stanford, HighWire è stato fondato all'inizio di Internet (421) Open edition https://journals.openedition.org/ Già: Revue.org. Infrastruttura di ricerca pubblica francese per l’accesso alle piattaforme: OpenEdition Journals, OpenEdition Books, Calenda e Hypothèses 529 PLOS https://www.plos.org/ Public Library of Science è un progetto editoriale per pubblicazioni scientifiche. Cura la pubblicazione di sette riviste, tutte caratterizzate da revisione paritaria e contenuto aperto. L'idea del progetto nacque nel 2000 in seguito alla pubblicazione online di una lettera aperta a firma di Harold Varmus, premio Nobel per la medicina ed ex direttore del National Institutes of Health, Patrick Brown, biochimico presso l'Università di Stanford, e Michael Eisen, biologo ricercatore presso l'Università della California, Berkeley. -

Gigabyte: Publishing at the Speed of Research Scott C
EDITORIAL GigaByte: Publishing at the Speed of Research Scott C. Edmunds1,* and Laurie Goodman1 1 GigaScience, BGI Hong Kong Tech Co Ltd., 26F A Kings Wing Plaza, 1 On Kwan Street, Shek Mun, Sha Tin, NT, Hong Kong, China ABSTRACT Current practices in scientific publishing are unsuitable for rapidly changing fields and for presenting updatable data sets and software tools. In this regard, and as part of our continuing pursuit of pushing scientific publishing to match the needs of modern research, we are delighted to announce the launch of GigaByte, an online open-access, open data journal that aims to be a new way to publish research following the software paradigm: CODE, RELEASE, FORK, UPDATE and REPEAT. Following on the success of GigaScience in promoting data sharing and reproducibility of research, its new sister, GigaByte, aims to take this even further. With a focus on short articles, using a questionnaire-style review process, and combining that with the custom built publishing infrastructure from River Valley Technologies, we now have a cutting edge, XML-first publishing platform designed specifically to make the entire publication process easier, quicker, more interactive, and better suited to the speed needed to communicate modern research. Subjects Computer Sciences, Data Integration, Data Management FUTURE’S PAST In 2012, we launched GigaScience [1] as a new type of journal — one that provides standard scientific publishing linked directly to a database that hosts all the relevant data. Aiming to address Buckheit and Donoho’s 1995 complaint that “an article about computational results is advertising, not scholarship. The actual scholarship is the full software environment, code and data that produced the result.” [2], we were inspired to launch a new type of journal Submitted: 29 May 2020 that focussed on making sure the actual scholarship of all types of research was included Accepted: 01 June 2020 with the article narrative. -

Impact of Social Sciences Blog: Fair Open Access: Returning Control of Scholarly Journals to Their Communities Page 1 of 4
Impact of Social Sciences Blog: Fair Open Access: returning control of scholarly journals to their communities Page 1 of 4 Fair Open Access: returning control of scholarly journals to their communities The problem of how we should transition to open access is now urgent. The current situation is one of exorbitant subscription journals and expensive open-access ones, and to address it requires organised action from academics. The Fair Open Access Alliance, set up to facilitate the conversion of existing subscription journals to open access, is an example of such organisation. Alex Holcombe and Mark C. Wilson outline the group’s five Fair Open Access Principles and encourage all librarians, researchers, and administrators to work together to secure agreement to cancel subscriptions and to pool funds to pay for open access infrastructure. The problem of how the world should transition to open access is now urgent. Growth in subscription fees charged to libraries has continued rising even as open access has grown, and open access has its own costs. The business model for recorded music was disrupted by the rise of illegal file-sharing. In academia however, until recently file sharing of scholarly papers did not occur enough for researchers to forego subscription access to journals. But that may have changed, via a process of paywall-thwarting that reminds us, a bit, of George Lopez’s reaction to Donald Trump’s planned border wall. When Lopez, the Mexican-American comedian, was asked what he thought about Trump’s wall, he replied: “well, I got news for everybody… we’ve got tunnels!”. -
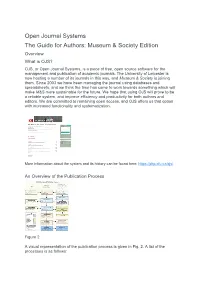
Open Journal Systems the Guide for Authors
Open Journal Systems The Guide for Authors: Museum & Society Edition Overview What is OJS? OJS, or Open Journal Systems, is a piece of free, open source software for the management and publication of academic journals. The University of Leicester is now hosting a number of its journals in this way, and Museum & Society is joining them. Since 2003 we have been managing the journal using databases and spreadsheets, and we think the time has come to work towards something which will make M&S more sustainable for the future. We hope that using OJS will prove to be a reliable system, and improve efficiency and productivity for both authors and editors. We are committed to remaining open access, and OJS offers us that option with increased functionality and systematization. More information about the system and its history can be found here: https://pkp.sfu.ca/ojs/ An Overview of the Publication Process Figure 2 A visual representation of the publication process is given in Fig. 2. A list of the processes is as follows: Author submission Editor assigns submission to Section Editor Section Editor sends submission to Peer Review Section Editor informs Author of editorial decision and review comments Author makes necessary alterations and returns submission Section Editor sends submission to Copy Editor Copy edited submission is returned to Author Author makes necessary alterations and returns submission Section Editor sends to Layout Editor Submission is sent for Proofreading The submission is assigned to an issue, created by the Editors The issue is published. Elements involving the author are indicated in bold. -

E-Journal Archiving: Changing Landscape
12/10/2014 e-Journal Archiving: Changing Landscape Lars Bjørnshauge, Director European Library Relations, SPARC Europe & Managing Director, DOAJ Mark Jordan, Head of Library Systems, Simon Fraser University Library & Public Knowledge Project (PKP) Bernie Reilly, President, Center for Research Libraries Oya Y. Rieger, Associate University Librarian Digital Scholarship & Preservation Services Cornell University Library CNI Fall 2014 Membership Meeting December 8, 2014 1 12/10/2014 Life of eJournals • Subscription cancellations and modifications • Moving from hybrid subscription to digital only • Changes in publishers’ business or service models digital preservation aims to ensure the usability, authenticity, discoverability, and accessibility of content 2 12/10/2014 • How do we factor in preservation status in our selection & collection building efforts? • How much do we know about Portico, Lockss, Clockss, etc. and our roles in the success of these operation? • What does “perpetual access” mean? • 2CUL Study, Spring 2011 –Only 13%-26% of e-journal titles preserved by LOCKSS or Portico • Keepers Registry Study, Fall 2012 –Only 23-27% of e-journals with ISSNs preserved by any of 7 preservation agencies 3 12/10/2014 Scale - Estimate • 200,000 e-serial titles – 121,000 titles in Cornell • 113,000 ISSNs assigned – 22,000 preserved • 13% preserved in Lockss or Portico 4 12/10/2014 Part 2: Mellon-Funded Project Objectives • Establish preservation priorities • Contact aggregators and publishers • Promote: – models for distributed action – model -

Redalyc.Measuring, Rating, Supporting, and Strengthening
Education Policy Analysis Archives/Archivos Analíticos de Políticas Educativas ISSN: 1068-2341 [email protected] Arizona State University Estados Unidos Carvalho Neto, Silvio; Willinsky, John; Alperin, Juan Pablo Measuring, Rating, Supporting, and Strengthening Open Access Scholarly Publishing in Brazil Education Policy Analysis Archives/Archivos Analíticos de Políticas Educativas, vol. 24, 2016, pp. 1-25 Arizona State University Arizona, Estados Unidos Available in: http://www.redalyc.org/articulo.oa?id=275043450033 How to cite Complete issue Scientific Information System More information about this article Network of Scientific Journals from Latin America, the Caribbean, Spain and Portugal Journal's homepage in redalyc.org Non-profit academic project, developed under the open access initiative education policy analysis archives A peer-reviewed, independent, open access, multilingual journal Arizona State University Volume 24 Number 54 May 19, 2016 ISSN 1068-2341 Measuring, Rating, Supporting, and Strengthening Open Access Scholarly Publishing in Brazil Silvio Carvalho Neto Centro Universitário Municipal de Franca Brazil & John Willinsky Stanford University United States & Juan Pablo Alperin Simon Fraser University Canada Citation: Carvalho Neto, S., Willinsky, J. & Alperin, J. P. (2016). Measuring, rating, supporting, and strengthening open access scholarly publishing in Brazil. Education Policy Analysis Archives, 24(54). http://dx.doi.org/10.14507/epaa.24.2391 Abstract: This study assesses the extent and nature of open access scholarly publishing in Brazil, one of the world’s leaders in providing universal access to its research and scholarship. It utilizes Brazil’s Qualis journal evaluation system, along with other relevant data bases to address the association between scholarly quality and open access in the Brazilian context. -

Strategische Und Operative Handlungsoptionen Für Wissenschaftliche Einrichtungen Zur Gestaltung Der Open-Access-Transformation
! ! ! !"#$"%&'()*%+,-.+/0%#$"'1%+2$-.3,-&(/0"'/-%-+ 45#+6'((%-()*$4"3')*%+7'-#')*",-&%-+8,#+ 9%("$3",-&+.%#+:0%-;<))%((;=#$-(4/#>$"'/-+ ! "#$$%&'('#)*! "#$!%$&'()#()!*+,!'-'*+./,01+(!2$'*+,! ")+')&!,-#.)$),-#(%! /"&0!,-#.01! ! +/()+$+/013! '(!*+$!41/&5,561/,01+(!7'-#&383! *+$!9#.:5&*3;<(/=+$,/383!"#!>+$&/(! ! =5(!9+/("!4'.6+&! ! ! ?/+!4$8,/*+(3/(!*+$!9#.:5&*3;<(/=+$,/383!"#!>+$&/(@!! 4$5AB!?$B;C()B!?$B!D':/(+!E#(,3! ! ?/+!?+-'(/(!*+$!41/&5,561/,01+(!7'-#&383@! 4$5AB!?$B!2':$/+&+!F+3"&+$! ! ! 2#3'013+$! %$,3)#3'013+$@!! ! 4$5AB!?$B!4+3+$!D01/$.:'01+$! GH+/3)#3'013+$@!! 4$5AB!?$B!I5&A$'.!95$,3.'((! ! ?'3#.!*+$!?/,6#3'3/5(@!JKB!F'/!LMLJ! !"#$%&'()*+),-#",'. G#,'..+(A',,#()!BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB!NC! O:,3$'03!BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB!NCC! ?'(-,')#()!BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB!NCCC! O:-P$"#(),=+$"+/01(/,!BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB!CQ! R':+&&+(=+$"+/01(/,!BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB!QCC! O::/&*#(),=+$"+/01(/,!BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB!QCCC! -

Open Science and the Role of Publishers in Reproducible Research
Open science and the role of publishers in reproducible research Authors: Iain Hrynaszkiewicz (Faculty of 1000), Peter Li (BGI), Scott Edmunds (BGI) Chapter summary Reproducible computational research is and will be facilitated by the wide availability of scientific data, literature and code which is freely accessible and, furthermore, licensed such that it can be reused, inteGrated and built upon to drive new scientific discoveries without leGal impediments. Scholarly publishers have an important role in encouraGing and mandating the availability of data and code accordinG to community norms and best practices, and developinG innovative mechanisms and platforms for sharinG and publishinG products of research, beyond papers in journals. Open access publishers, in particular the first commercial open access publisher BioMed Central, have played a key role in the development of policies on open access and open data, and increasing the use by scientists of leGal tools – licenses and waivers – which maximize reproducibility. Collaborations, between publishers and funders of scientific research, are vital for the successful implementation of reproducible research policies. The genomics and, latterly, other ‘omics communities historically have been leaders in the creation and wide adoption of policies on public availability of data. This has been throuGh policies, such as Fort Lauderdale and the Bermuda Principles; infrastructure, such as the INSDC databases; and incentives, such as conditions of journal publication. We review some of these policies and practices, and how these events relate to the open access publishinG movement. We describe the implementation and adoption of licenses and waivers prepared by Creative Commons, in science publishinG, with a focus on licensing of research data published in scholarly journals and data repositories.