GEOGRAPHIC DISTRIBUTION of URBAN RETAILS and ITS SPATIAL RELATIONSHIP with SUBWAY NETWORK: a Case Study of Retail POI Data in Shanghai
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spatializing Commodity Chains
Progress in Human Geography 23,3 (1999) pp. 401–420 Spatializing commodity chains Deborah Leslie1 and Suzanne Reimer2 1Department of Geography, Brock University, St Catharines, Ontario L2S 3A1, Canada 2Department of Geography, University of Hull, Hull HU6 7RX, UK Abstract: There has been a growing interest in connecting production and consumption through the study of commodity chains. We identify three distinct approaches to the chain and review debates concerning the merits of a ‘vertical’ rather than a ‘horizontal’ approach. Drawing upon the example of the home furnishings commodity chain, the article highlights the importance of including horizontal factors such as gender and place alongside vertical chains. We consider geographical contingencies which underpin commodity chain dynamics, the role of space in mediating relationships across the chain and the spatialities of different products. Key words: commodity chains, consumer culture, gender, home furnishings industry, space. I Introduction The topic of consumption has begun to receive considerable attention within geography. Rather than suggesting that cultural processes are simply reflective of economic or political factors, recent discussions have begun to emphasize the constitu- tive nature of culture within society (Crang, 1997; du Gay et al., 1997: 2) and to underscore the centrality of consumer cultures to social life (Lury, 1996; Slater, 1997). This ‘turn’ to consumption should not be taken to suggest that the phenomenon is purely contemporary. Rather, commodity cultures are central features of modernity itself (Slater, 1997). None the less, it is only recently that geographers and other social scientists have begun to rethink creatively the implications of consumption for economics and politics (Miller, 1995: 1; 1998). -

Jiangsu(PDF/288KB)
Mizuho Bank China Business Promotion Division Jiangsu Province Overview Abbreviated Name Su Provincial Capital Nanjing Administrative 13 cities and 45 counties Divisions Secretary of the Luo Zhijun; Provincial Party Li Xueyong Committee; Mayor 2 Size 102,600 km Shandong Annual Mean 16.2°C Jiangsu Temperature Anhui Shanghai Annual Precipitation 861.9 mm Zhejiang Official Government www.jiangsu.gov.cn URL Note: Personnel information as of September 2014 [Economic Scale] Unit 2012 2013 National Share (%) Ranking Gross Domestic Product (GDP) 100 Million RMB 54,058 59,162 2 10.4 Per Capita GDP RMB 68,347 74,607 4 - Value-added Industrial Output (enterprises above a designated 100 Million RMB N.A. N.A. N.A. N.A. size) Agriculture, Forestry and Fishery 100 Million RMB 5,809 6,158 3 6.3 Output Total Investment in Fixed Assets 100 Million RMB 30,854 36,373 2 8.2 Fiscal Revenue 100 Million RMB 5,861 6,568 2 5.1 Fiscal Expenditure 100 Million RMB 7,028 7,798 2 5.6 Total Retail Sales of Consumer 100 Million RMB 18,331 20,797 3 8.7 Goods Foreign Currency Revenue from Million USD 6,300 2,380 10 4.6 Inbound Tourism Export Value Million USD 328,524 328,857 2 14.9 Import Value Million USD 219,438 221,987 4 11.4 Export Surplus Million USD 109,086 106,870 3 16.3 Total Import and Export Value Million USD 547,961 550,844 2 13.2 Foreign Direct Investment No. of contracts 4,156 3,453 N.A. -

Changing European Retail Landscapes: New Trends and Challenges
MORAVIAN GEOGRAPHICAL REPORTS 2018, 26(3):2018, 150–159 26(3) Vol. 23/2015 No. 4 MORAVIAN MORAVIAN GEOGRAPHICAL REPORTS GEOGRAPHICAL REPORTS Institute of Geonics, The Czech Academy of Sciences journal homepage: http://www.geonika.cz/mgr.html Figures 8, 9: New small terrace houses in Wieliczka town, the Kraków metropolitan area (Photo: S. Kurek) doi: 10.2478/mgr-2018-0012 Illustrations to the paper by S. Kurek et al. Changing European retail landscapes: New trends and challenges Josef KUNC a *, František KRIŽAN b Abstract During the second half of the 20th century, consumption patterns in the developed market economies have stabilised, while in the transition/EU-accession countries these patterns were accepted with unusual speed and dynamics. Differences, changes and current trends in Western Europe and post-socialist countries in the quantity and concentration of retailing activities have been minimised, whereas some distinctions in the quality of retail environments have remained. Changes have occurred in buying habits, shopping behaviour and consumer preferences basically for all population groups across the generations. This article is a theoretical and conceptual introduction to a Special Issue of the Moravian Geographical Reports (Volume 26, No. 3) on “The contemporary retail environment: shopping behaviour, consumers’ preferences, retailing and geomarketing”. The basic features which have occurred in European retailing environments are presented, together with a comparison (and confrontation) between Western and Eastern Europe. The multidisciplinary nature of retailing opens the discussion not only from a geographical perspective but also from the point of view of other social science disciplines that naturally interconnect in the retail environments. -

Proquest Dissertations
IDENTITY FOR SALE: A Case Study of Gap Inc. MEGHAN J. REES A THESIS SUBMITTED TO THE FACULTY OF GRADUATE STUDIES IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER'S GRADUATE PROGRAM IN GEOGRAPHY YORK UNIVERSITY TORONTO, ONTARIO JULY 2008 Library and Bibliotheque et 1*1 Archives Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A0N4 Ottawa ON K1A0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-45966-9 Our file Notre reference ISBN: 978-0-494-45966-9 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library permettant a la Bibliotheque et Archives and Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par Plntemet, prefer, telecommunication or on the Internet, distribuer et vendre des theses partout dans loan, distribute and sell theses le monde, a des fins commerciales ou autres, worldwide, for commercial or non sur support microforme, papier, electronique commercial purposes, in microform, et/ou autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in et des droits moraux qui protege cette these. this thesis. Neither the thesis Ni la these ni des extraits substantiels de nor substantial extracts from it celle-ci ne doivent etre imprimes ou autrement may be printed or otherwise reproduits sans son autorisation. -

Transportation the Conference Will Be Held in North Zhongshan Road
Transportation The conference will be held in North Zhongshan Road campus of East China Normal University (ECNU). The address is: No. 3663, North Zhongshan Road, Putuo, Shanghai. The hotel where all participants will stay is Yifu Building (逸夫楼) located on the campus. Arrival by flights: There are two airports in Shanghai: the Pudong Airport in east Shanghai and the Hongqiao Airport in west Shanghai. Both are convenient to get to the North Zhongshan Road campus of ECNU. At the airport, you can take taxi or metro to North Zhongshan Road Campus of ECNU. Taxi is recommended in terms of its convenience and time saving. Our students will be there for helping you to find the taxi. By taxi From Pudong Airport: about one hour and 200 CNY when traffic is not busy. From Hongqiao Airport: about 30 minutes and 60 CNY when traffic is not busy. Please print the following tips if you like “请带我去华东师范大学中山北路校区正门” in advance and show it to the taxi driver. The Chinese words in tips mean "Please take me to the main gate of North Zhongshan Road Campus of ECNU". By metro From Pudong Airport: 1. Metro Line 2 (6:00 - 22:00)->Zhongshan Park (中山公园) station (Note: exchange at Guanglan Road station(广兰路)), then take taxi for about 10 minutes and 14 CNY cost to North Zhongshan Road Campus of ECNU, or take the bus 67 for 2 stops and get off at ECNU station(华东师大站)instead. 2. Metro Line 2->Jiangsu Road (江苏路) station-> Metro Line 11->Longde Road (隆德路) station->Metro Line 13-> Jinshajiang Road (金沙江路) Station->10 minutes walk. -

Microgeographies of Retailing and Gentrification
Australian Geographer, Vol. 32, No. 1, pp. 93–107, 2001 Microgeographies of Retailing and Gentri cation GARY BRIDGE & ROBYN DOWLING, University of Bristol, UK; Macquarie University, Australia ABSTRACT It has long been argued that gentri cation is a process of consumption as well as production but, in the main, analyses of consumption and gentri cation have only tangentially or anecdotally considered the retail spaces of gentri ed neighbourhoods. In this paper we investigate the nature of the retail landscapes of gentri cation, using empirical evidence from Sydney, Australia. We point to micro retailscapes that differ between gentri ed neighbourhoods that suggest a divergence of consumption practices between different groups of gentri ers. These consumption practices are considered both in terms of their relations to identity (through food and the conception of the body) and to the spaces of the city. The paper concludes by drawing out the implications for future research on the consumption practices of the new middle class and the working class in an international context. KEY WORDS Gentri cation; retailing; Sydney; new middle class; consumption. Introduction It has long been argued that gentri cation is a process of consumption as well as production (see Lees 1994a; Hamnett 1991). Living in inner-city neighbourhoods, in houses with a certain aesthetic sensibility is not only a strategy of capital, but also a lifestyle choice that expresses the identities of those who belong to a new middle class of professionals and service workers. Mills (1988), for example, has suggested that gentri ers seek to consume a particular home-based aesthetic. -

The 3Rd International Symposium on Liver Diseases with Chinese Integrative Medicine (3Rd ISLD)
The 3rd International Symposium on Liver Diseases with Chinese Integrative Medicine (3rd ISLD) Welcoming Address Distinguished experts, committees, colleagues: The 2016 Annual Conference of the Committee of Liver Disease of Chinese Association of Integrative Medicine — the 3rd International Symposium on Liver Diseases with Chinese Integrative Medicine will be held from October 28th to 29th, 2016 in Shanghai. We are sincerely looking forward to welcoming you in Shanghai. The Committee of Liver Disease of Chinese Association of Integrative Medicine is among the highest level in the field of Chinese integrative medicine that was established in 1986. It promotes scientific research and clinical academic exchanges along with the clinical workers and medical researchers in a wide range of fields including Chinese medicine, Western medicine and Chinese integrative medicine. The committee has successively held National Conference on Hepatic Diseases of Chinese Integrative Medicine for 24 times and International Symposium on Liver Diseases with Chinese Integrative Medicine in Shanghai at 2005 and 2010. The theme of the conference is "Liver Fibrosis and Liver Cancer." It will provide an opportunity for exchanging the progress of prevention and clinical research experience of common chronic liver disease (eg, chronic viral hepatitis, liver fibrosis and cirrhosis, liver cancer, fatty liver disease, alcoholic liver disease, liver disease and nutrition and intestinal) with Chinese integrative medicine being the focus of this conference. We will invite renowed experts all over the world to give special reports. Let us gather in Shanghai at this golden autumn to attend the 3rd International Symposium on Liver Diseases with Chinese Integrative Medicine, to learn and make progress mutually, to promote the development of Chinese integrative medicine of liver disease and to contribute to human health. -

Leading New ICT Building a Smart Urban Rail
Leading New ICT Building A Smart Urban Rail 2017 HUAWEI TECHNOLOGIES CO., LTD. Bantian, Longgang District Shenzhen518129, P. R. China Tel:+86-755-28780808 Huawei Digital Urban Rail Solution Digital Urban Rail Solution LTE-M Solution 04 Next-Generation DCS Solution 10 Urban Rail Cloud Solution 15 Huawei Digital Urban Rail Solution Huawei Digital Urban Rail Solution Huawei LTE-M Solution for Urban Rail Huawei and Alstom the Completed World’s Huawei Digital Urban Rail LTE-M Solution First CBTC over LTE Live Pilot On June 29th, 2015, Huawei and Alstom, one of the world’s leading energy solutions and transport companies, announced the successful completion of the world’s first live pilot test of 4G LTE multi-services based on Communications- based Train Control (CBTC), a railway signalling system based on wireless ground-to-train CBTC PIS CCTV Dispatching communication. The successful pilot, which CURRENT STATUS IN URBAN RAIL covered the unified multi-service capabilities TV Wall ATS Server Terminal In recent years, public Wi-Fi access points have become a OCC of several systems including CBTC, Passenger popular commodity in urban areas. Due to the explosive growth Information System (PIS), and closed-circuit in use of multimedia devices like smart phones, tablets and NMS LTE CN television (CCTV), marks a major step forward in notebooks, the demand on services of these devices in crowded the LTE commercialization of CBTC services. Line/Station Section/Depot Station places such as metro stations has dramatically increased. Huge BBU numbers of Wi-Fi devices on the platforms and in the trains RRU create chances of interference with Wi-Fi networks, which TAU TAU Alstom is the world’s first train manufacturer to integrate LTE 4G into its signalling system solution, the Urbalis Fluence CBTC Train AR IPC PIS AP TCMS solution, which greatly improves the suitability of eLTE, providing a converged ground-to-train wireless communication network Terminal When the CBTC system uses Wi-Fi technology to implement for metro operations. -

Socio-Cultural Retailing: What Can Marketing Learn from This Interdisciplinary Field?
Socio-cultural retailing: What can marketing learn from this interdisciplinary field? Fuentes, Christian; Hagberg, Johan Published in: International Journal of Quality and Service Sciences DOI: 10.1108/IJQSS-10-2012-0018 2013 Link to publication Citation for published version (APA): Fuentes, C., & Hagberg, J. (2013). Socio-cultural retailing: What can marketing learn from this interdisciplinary field? International Journal of Quality and Service Sciences, 5(3), 290-308. https://doi.org/10.1108/IJQSS-10- 2012-0018 Total number of authors: 2 General rights Unless other specific re-use rights are stated the following general rights apply: Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal Read more about Creative commons licenses: https://creativecommons.org/licenses/ Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. LUND UNIVERSITY PO Box 117 221 00 Lund +46 46-222 00 00 -

Five New Towns in Shanghai. Present Situation and Future Perspectives
1 3 Five new towns in Shanghai. 2 Present situation and future perspectives. 4 5 State-of-the Art 2013/2014 Ulf Ranhagen April 2014 Department of Urban Planning at the Swedish Royal Institute of Technology (KTH) © Ulf Ranhagen 2014 Graphic design Olav Heinmets Photos Ulf Ranhagen Printed by US-AB, Universitetsservice TRITA SoM 2014-04 ISSN 1653-6126 ISNR KTH/SoM/14-04/SE ISBN 978-91-7595-068-6 Contents Preface 4 Abstract 5 Introduction 6 The five selected new towns for the study trip 8 Luodian Town – the Swedish New Town 9 Gaoqiao – Holland Village 24 Anting New Town – the German New Town 27 Thames Town – the British New Town 30 Pujiang New Town – the Italian New Town 33 Summary of the analysis of the five new towns 35 Final reflections 38 References 39 Preface I am a Swedish Professor working in the Department of I warmly thank FFNS research foundation for its support of Urban Planning at the Swedish Royal Institute of Technolo- the study. I thank Leon Yu, General Manager of Shanghai gy (KTH) and as Chief Architect at Sweco. I have received Golden Luodian Development Ltd., and Professor Liu Xiao a grant from FFNS research foundation to perform an Ping and Harry den Hartog, author of Shanghai New Towns, overall diagnosis and analysis of the State-of-the-Art of the for giving me valuable information on Luodian New Town. urban environment of new towns in Shanghai, especially The information centers of Anting New Town and Holland the towns developed within the framework of the One City Village also gave me valuable, useful information material for Nine Towns, which was launched in 2001. -

Business Incubator of Tongji University Science Park
1. To create a knowledge-based service innovation cluster by the radiation effect of the Tongji knowledge-based economic circle. 2. To boost the development of joint production and Business Incubator of Tongji research and construct a chain-wide innovation and start-up service system. University Science Park 3. To build a dream together with entrepreneurs by the concept of seamless collaboration team service. Location: Yangpu District, Shanghai General Introduction Address: Room 105, 65 Chifeng Road, Yangpu District, Shanghai Business Incubator of Tongji University Science Park Number of Incubated foreign invested enterprises, was established in December 2003, located in Tongji joint ventures or overseas talent startups: 30 University South Campus in Chifeng Road. It is the national Website: www.tj-ibi.com high-tech business service center and vice president unit of Major industries: Modern design, energy saving and Shanghai Science and Technology Incubator Association. environmental protection, electronic With more than 1,400 registered enterprises reside in information, rail transportation,etc. incubation sites, it covers an incubation area of 20,000 square meters. As the incubation platform of Tongji University National University Science and Technology Park, the company is Results list specialized in the incubation of small and medium enterprises of science and technology, providing the enterprises residence services and business incubation services. Performance List 55 enterprises in the park have been identified as high-tech enterprises, 9 identified as the Shanghai Little Giant Cultivating Enterprises, 4 as Shanghai Little Giant Enterprises, and 16 as Yangpu District Little Giant Enterprises. Resident enterprises have over 1000 intellectual property rights. There are 3 companies have been listed on the NEEQ and 1 company has been listed in the Shanghai Equity Trading Center. -
Global Transmission Report
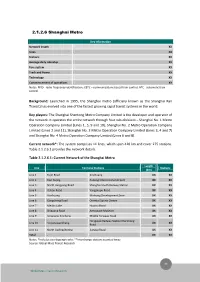
2.1.2.6 Shanghai Metro Key Information Network length XX Lines XX Stations XX Average daily ridership XX Fare system XX Track and Power XX Technology XX Commencement of operations XX Notes: RFID - radio-frequency identification; CBTC – communications based train control; ATC - automatic train control Background: Launched in 1995, the Shanghai metro (officially known as the Shanghai Rail Transit) has evolved into one of the fastest growing rapid transit systems in the world. Key players: The Shanghai Shentong Metro Company Limited is the developer and operator of the network. It operates the entire network through four sub-divisions – Shanghai No. 1 Metro Operation Company Limited (Lines 1, 5, 9 and 10), Shanghai No. 2 Metro Operation Company Limited (Lines 2 and 11), Shanghai No. 3 Metro Operation Company Limited (Lines 3, 4 and 7) and Shanghai No. 4 Metro Operation Company Limited (Lines 6 and 8). Current network*: The system comprises 11 lines, which span 420 km and cover 275 stations. Table 2.1.2.6.1 provides the network details. Table 2.1.2.6.1: Current Network of the Shanghai Metro Length Line Terminal Stations Stations (km) Line 1 Fujin Road Xinzhuang XX XX Line 2 East Xujing Pudong International Airport XX XX Line 3 North Jiangyang Road Shanghai South Railway Station XX XX Line 4 Yishan Road Yangshupu Road XX XX Line 5 Xinzhuang Minhang Development Zone XX XX Line 6 Gangcheng Road Oriental Sports Centre XX XX Line 7 Meilan Lake Huamu Road XX XX Line 8 Shiguang Road Aerospace Museum XX XX Line 9 Songjiang Xincheng Middle Yanggao Road XX XX Hongqiao Railway Station/Hanzhong Line 10 Xinjiangwancheng XX XX Road Line 11 North Jiading/Anting Jiangsu Road XX XX Total - - XX XX Notes: *Includes overlapping tracks; **Interchange stations counted twice Source: Global Mass Transit Research 44 Global Mass Transit Research Ridership: In 2010, the system carried 1.9 billion passengers, translating into an average daily ridership of 5.2 million passengers.