DESIGNING FAST and PROGRAMMABLE ROUTERS By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Program Review Department of Computer Science
PROGRAM REVIEW DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF NORTH CAROLINA AT CHAPEL HILL JANUARY 13-15, 2009 TABLE OF CONTENTS 1 Introduction............................................................................................................................. 1 2 Program Overview.................................................................................................................. 2 2.1 Mission........................................................................................................................... 2 2.2 Demand.......................................................................................................................... 3 2.3 Interdisciplinary activities and outreach ........................................................................ 5 2.4 Inter-institutional perspective ........................................................................................ 6 2.5 Previous evaluations ...................................................................................................... 6 3 Curricula ................................................................................................................................. 8 3.1 Undergraduate Curriculum ............................................................................................ 8 3.1.1 Bachelor of Science ................................................................................................. 10 3.1.2 Bachelor of Arts (proposed) ................................................................................... -

A Modeling Framework for Network Processor Systems
A Modeling Framework for Network Processor Systems Patrick Crowley & Jean-Loup Baer Department of Computer Science & Engineering University of Washington Seattle, WA 98195-2350 pcrowley, baer ¡ @cs.washington.edu Abstract cation W at the target line rate and number of inter- faces? This paper introduces a modeling framework for network ¢ If not, where are the bottlenecks? processing systems. The framework is composed of inde- ¢ If yes, can S support application W’ (that is, application pendent application, system and traffic models which de- W plus some new task) under the same constraints? scribe router functionality, system resources/organization ¢ Will a given hardware assist improve system perfor- and packet traffic, respectively. The framework uses the mance relative to a software implementation of the Click Modular router to describe router functionality. Click same task? modules are mapped onto an object-based description of ¢ How sensitive is system performance to input traffic? the system hardware and are profiled to determine maxi- mum packet flow through the system and aggregate resource The framework is composed of independent application, utilization for a given traffic model. This paper presents system and traffic models which describe router function- several modeling examples of uniprocessor and multipro- ality, system resources/organization and packet traffic, re- cessor systems executing IPv4 routing and IPSec VPN en- spectively. The framework uses the Click Modular router cryption/decryption. Model-based performance estimates to describe router functionality. Click modules are mapped are compared to the measured performance of the real sys- onto an object-based description of the system hardware tems being modeled; the estimates are found to be accurate and are profiled and simulated to determine maximum within 10%. -

Deepmatch: Practical Deep Packet Inspection in the Data Plane Using Network Processors
DeepMatch: Practical Deep Packet Inspection in the Data Plane using Network Processors Joel Hypolite John Sonchack Shlomo Hershkop The University of Pennsylvania Princeton University The University of Pennsylvania [email protected] [email protected] [email protected] Nathan Dautenhahn André DeHon Jonathan M. Smith Rice University The University of Pennsylvania The University of Pennsylvania [email protected] [email protected] [email protected] ABSTRACT Server Security Server ApplianceSecurity Restricting data plane processing to packet headers precludes anal- ApplianceSecurity 1 ysis of payloads to improve routing and security decisions. Deep- Applications DPIAppliance Applications DPI filtering DPI Match delivers line-rate regular expression matching on payloads Scalabilityfiltering IDS rules using Network Processors (NPs). It further supports packet re- DPI Challenge 2 rules ordering to match patterns in flows that cross packet boundaries. smartNIC Bottleneck Our evaluation shows that an implementation of DeepMatch, on a DeepMatch 40 Gbps Netronome NFP-6000 SmartNIC, achieves up to line rate for smartNIC + P4 streams of unrelated packets and up to 20 Gbps when searches span P4 DPI rules multiple packets within a flow. In contrast with prior work, this Header Header rules throughput is data-independent and adds no burstiness. DeepMatch 3 Network rules opens new opportunities for programmable data planes. Figure 1: DPI today (left and network) is limited by per- CCS CONCEPTS formance, scalability, and programming/management com- • Networks → Deep packet inspection; Programming inter- plexities (shaded red) inherent to the underlying deploy- faces; Programmable networks; ment models. DeepMatch (right) pushes DPI into the com- modity SmartNICs currently used to accelerate header fil- KEYWORDS tering and integrates DPI with P4, which improves perfor- Network processors, Programmable data planes, P4, SmartNIC mance and scalability while enabling a simpler deployment ACM Reference Format: model. -

Software Self-Healing Using Error Virtualization
Software Self-healing Using Error Virtualization Stylianos Sidiroglou Submitted in partial fulfillment of the Requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2008 c 2008 Stylianos Sidiroglou All Rights Reserved ABSTRACT Stylianos Sidiroglou Software Self-healing Using Error Virtualization Despite considerable efforts in both research and development strategies, software errors and subsequent security vulnerabilities continue to be a significant problem for computer systems. The accepted wisdom is to approach the problem with a multitude of tools such as diligent software development strategies, dynamic bug finders and static analysis tools in an attempt to eliminate as many bugs as possible. Unfortunately, history has shown that it is very hard to achieve bug-free software. The situation is further exacerbated by the exorbitant cost of system down-time which some estimates place at six million dollars per hour. In the absence of perfect software, retrofitting error toleration and recovery techniques, in systems not designed to deal with failures, becomes a necessary complement to proactive approaches. Towards this goal, this dissertation introduces and evaluates a set of techniques for recovering program execution in the presence of faults by effectively retrofitting legacy applications with exception handling techniques, Error Virtualization and AS- SURE . The main premise of the approach is that there is a mapping between faults that may occur during program execution and a finite set of errors that are explicitly handled by the program’s code. Experimental results are presented to support our hypothesis. The results demonstrate that our techniques can recover program execu- tion in the case of failures in 80 to 90% of the examined cases, based on the technique used. -

Enhanced OS-9 Release Notes 58 Networking Notes 58 Protocol Modules 58 Utilities 59 Drivers 60 MAUI Notes 61 SNMP Notes 62 OS-9 Utilities Notes 62 Enhancements
Microware OS-9 Release Notes Version 3.2 www.radisys.com World Headquarters 5445 NE Dawson Creek Drive • Hillsboro, OR 97124 USA Phone: 503-615-1100 • Fax: 503-615-1121 Toll-Free: 800-950-0044 International Headquarters Gebouw Flevopoort • Televisieweg 1A NL-1322 AC • Almere, The Netherlands Phone: 31 36 5365595 • Fax: 31 36 5365620 RadiSys Microware Communications Software Division, Inc. 1500 N.W. 118th Street Des Moines, Iowa 50325 515-223-8000 Revision A December 2001 Copyright and publication information Reproduction notice This manual reflects version 3.2 of Microware OS-9. The software described in this document is intended to Reproduction of this document, in part or whole, by be used on a single computer system. RadiSys Corpo- any means, electrical, mechanical, magnetic, optical, ration expressly prohibits any reproduction of the soft- chemical, manual, or otherwise is prohibited, without written permission from RadiSys Microware ware on tape, disk, or any other medium except for Communications Software Division, Inc. backup purposes. Distribution of this software, in part or whole, to any other party or on any other system may Disclaimer constitute copyright infringements and misappropria- The information contained herein is believed to be tion of trade secrets and confidential processes which accurate as of the date of publication. However, are the property of RadiSys Corporation and/or other RadiSys Corporation will not be liable for any damages parties. Unauthorized distribution of software may including indirect or consequential, from use of the cause damages far in excess of the value of the copies OS-9 operating system, Microware-provided software, involved. -

Foundations of Hybrid and Embedded Systems and Software
FINAL REPORT FOUNDATIONS OF HYBRID AND EMBEDDED SYSTEMS AND SOFTWARE NSF/ITR PROJECT – AWARD NUMBER: CCR-0225610 UNIVERSITY OF CALIFORNIA, BERKELEY November 26, 2010 PERIOD OF PERFORMANCE COVERED: November 14, 2002 – August 31, 2010 1 Contents 1 Participants 3 1.1 People ....................................... 3 1.2 PartnerOrganizations: . ... 9 1.3 Collaborators:.................................. 9 2 Activities and Findings 14 2.1 ProjectActivities ............................... .. 14 2.1.1 ITREvents ................................ 16 2.1.2 HybridSystemsTheory . .. .. 16 2.1.3 DeepCompositionality . 16 2.1.4 RobustHybridSystems . .. .. 16 2.1.5 Hybrid Systems and Systems Biology . .. 16 2.2 ProjectFindings................................. 16 3 Outreach 16 3.1 Project Training and Development . .... 16 3.2 OutreachActivities .............................. .. 16 3.2.1 Curriculum Development for Modern Systems Science (MSS)..... 16 3.2.2 Undergrad Course Insertion and Transfer . ..... 16 3.2.3 GraduateCourses............................. 16 4 Publications and Products 16 4.1 Technicalreports ................................ 16 4.2 PhDtheses .................................... 16 4.3 PhDtheses .................................... 16 4.4 Conferencepapers................................ 16 4.5 Books ....................................... 16 4.6 Journalarticles ................................. 16 4.6.1 The 2009-2010 Chess seminar series . ... 16 4.6.2 WorkshopsandInvitedTalks . 16 4.6.3 GeneralDissemination . 16 4.7 OtherSpecificProducts -

IXP1200 Hardware Reference Manual
Intel® IXP1200 Network Processor Family Hardware Reference Manual December 2001 Part Number: 278303-009 Intel® IXP1200 Network Processor Family Revision History Revision Date Revision Description 8/30/99 001 Beta 1 release. 10/29/99 002 Beta 3 release. 3/2/00 003 Beta 4 release. 6/5/00 004 Version 1.0 release. 9/27/00 005 Version 1.1 release. 12/20/00 006 Version 1.2 release. 6/1/01 007 Version 1.3 SDK release. 8/10/01 008 Version 2.0 SDK release. Miscellaneous changes. 12/07/01 009 Version 2.01 SDK release. Miscellaneous changes. Information in this document is provided in connection with Intel® products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel’s Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The IXP1200 may contain design defects or errors known as errata which may cause the product to deviate from published specifications. -

Paving the Way for NFV Acceleration: a Taxonomy, Survey and Future Directions
1 Paving the Way for NFV Acceleration: A Taxonomy, Survey and Future Directions XINCAI FEI, FANGMING LIU (CORRESPONDING AUTHOR), QIXIA ZHANG, and HAI JIN, National Engineering Research Center for Big Data Technology and System, Key Laboratory of Services Computing Technology and System, Ministry of Education, School of Computer Science and Technology, Huazhong University of Science and Technology, China HONGXIN HU, Clemson University, USA As a recent innovation, network functions virtualization (NFV), with its core concept of replacing hardware middleboxes with software network functions (NFs) implemented in commodity servers, promises cost savings and flexibility benefits. However, transitioning NFs from special-purpose hardware to commodity servers has turned out to be more challenging than expected, as it inevitably incurs performance penalties due to bottlenecks in both software and hardware. To achieve performance comparable to hardware middleboxes, there is a strong demand for a speedup in NF processing, which plays a crucial role in the success of NFV. In this article, we study the performance challenges that exist in general-purpose servers and simultaneously summarize the typical performance bottlenecks in NFV. Through reviewing the progress in the field of NFV acceleration, we present a new taxonomy of the state-of-the-art efforts according to various acceleration approaches. We discuss the surveyed works and identify the respective advantages and disadvantages in each category. We then discuss the products, solutions and projects emerged in industry. We also present a gap analysis to improve current solutions and highlight promising research trends that can be explored in the future. CCS Concepts: • Computer systems organization → Network Functions Virtualization; NFV Accelera- tion; • Networks → Carrier Networks; Additional Key Words and Phrases: Network Functions Virtualization, NFV acceleration, high performance ACM Reference Format: Xincai Fei, Fangming Liu (corresponding author), Qixia Zhang, Hai Jin, and Hongxin Hu. -
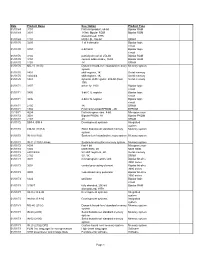
Date Product Name Description Product Type 01/01/69 3101 First
Date Product Name Description Product Type 01/01/69 3101 first Intel product, 64-bit Bipolar RAM 01/01/69 3301 1K-bit, Bipolar ROM Bipolar ROM discontinued, 1976 01/01/69 1101 MOS LSI, 256-bit SRAM 01/01/70 3205 1-of-8 decoder Bipolar logic circuit 01/01/70 3404 6-bit latch Bipolar logic circuit 01/01/70 3102 partially decoded, 256-bit Bipolar RAM 01/01/70 3104 content addressable, 16-bit Bipolar RAM 01/01/70 1103 1K DRAM 01/01/70 MU-10 (1103) Dynamic board-level standard memory Memory system system 01/01/70 1401 shift register, 1K Serial memory 01/01/70 1402/3/4 shift register, 1K Serial memory 01/01/70 1407 dynamic shift register, 200-bit (Dual Serial memory 100) 01/01/71 3207 driver for 1103 Bipolar logic circuit 01/01/71 3405 3-bit CTL register Bipolar logic circuit 01/01/71 3496 4-bit CTL register Bipolar logic circuit 01/01/71 2105 1K DRAM 01/01/71 1702 First commercial EPROM - 2K EPROM 11/15/71 4004 first microprocessor, 4-bit Microprocessor 01/01/72 3601 Bipolar PROM, 1K Bipolar PROM 01/01/72 2107 4K DRAM 01/01/72 SIM 4, SIM 8 Development systems Integrated system 01/01/72 CM-50 (1101A) Static board-level standard memory Memory system system 01/01/72 IN-10 (1103) System-level standard memory system Memory system 01/01/72 IN-11 (1103) Univac System-level custom memory system Memory system 01/01/72 8008 first 8-bit Microprocessor 01/01/72 1302 MOS ROM, 2K MOS ROM 01/01/72 2401/2/3/4 5V shift registers, 2K Serial memory 01/01/72 2102 5V, 1K SRAM 01/01/73 3001 microprogram control unit Bipolar bit-slice 3000 series 01/01/73 3002 central -

Utilizing IXP1200 Hardware and Software for Packet Filtering
Calhoun: The NPS Institutional Archive DSpace Repository Theses and Dissertations 1. Thesis and Dissertation Collection, all items 2004-12 Utilizing IXP1200 hardware and software for packet filtering Lindholm, Jeffery L. Monterey, California. Naval Postgraduate School http://hdl.handle.net/10945/1222 Downloaded from NPS Archive: Calhoun NAVAL POSTGRADUATE SCHOOL MONTEREY, CALIFORNIA THESIS UTILIZING IXP1200 HARDWARE AND SOFTWARE FOR PACKET FILTERING by Jeffery L. Lindholm December 2004 Thesis Advisor: Su Wen Co-Advisor: John Gibson Approved for public release; distribution is unlimited THIS PAGE INTENTIONALLY LEFT BLANK REPORT DOCUMENTATION PAGE Form Approved OMB No. 0704-0188 Public reporting burden for this collection of information is estimated to average 1 hour per response, including the time for reviewing instruction, searching existing data sources, gathering and maintaining the data needed, and completing and reviewing the collection of information. Send comments regarding this burden estimate or any other aspect of this collection of information, including suggestions for reducing this burden, to Washington headquarters Services, Directorate for Information Operations and Reports, 1215 Jefferson Davis Highway, Suite 1204, Arlington, VA 22202-4302, and to the Office of Management and Budget, Paperwork Reduction Project (0704-0188) Washington DC 20503. 1. AGENCY USE ONLY (Leave blank) 2. REPORT DATE 3. REPORT TYPE AND DATES COVERED December 2004 Master’s Thesis 4. TITLE AND SUBTITLE: Title (Mix case letters) 5. FUNDING NUMBERS Utilizing IXP1200 Hardware and Software for Packet Filtering 6. AUTHOR(S) Jeffery L. Lindholm 7. PERFORMING ORGANIZATION NAME(S) AND ADDRESS(ES) 8. PERFORMING Naval Postgraduate School ORGANIZATION REPORT Monterey, CA 93943-5000 NUMBER 9. SPONSORING /MONITORING AGENCY NAME(S) AND ADDRESS(ES) 10. -

Building a Foundation for the Future of Software Practices Within the Multi-Core Domain
Building a Foundation for the Future of Software Practices within the Multi-Core Domain by Celina Berg B.Sc., University of Victoria, 2005 M.Sc., University of Victoria, 2006 A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY in the Department of Computer Science ⃝c Celina Berg, 2011 University of Victoria All rights reserved. This dissertation may not be reproduced in whole or in part, by photocopying or other means, without the permission of the author. ii Building a Foundation for the Future of Software Practices within the Multi-Core Domain by Celina Berg B.Sc., University of Victoria, 2005 M.Sc., University of Victoria, 2006 Supervisory Committee Dr. M.Y. Coady, Supervisor (Department of Computer Science) Dr. H.A. M¨uller,Departmental Member (Department of Computer Science) Dr. A. Thomo, Departmental Member (Department of Computer Science) Dr. A. Gulliver, Outside Member (Department of Electrical and Computer Engineering) iii Supervisory Committee Dr. M.Y. Coady, Supervisor (Department of Computer Science) Dr. H.A. M¨uller,Departmental Member (Department of Computer Science) Dr. A. Thomo, Departmental Member (Department of Computer Science) Dr. A. Gulliver, Outside Member (Department of Electrical and Computer Engineering) ABSTRACT Multi-core programming presents developers with a dramatic paradigm shift. Where the conceptual models of sequential programming largely supported the de- coupling of source from underlying architecture, it is now unwise to develop new patterns, abstractions and parallel software in complete isolation from issues of mod- ern hardware utilization. Challenging issues historically associated with complex systems code are now compounded within the parallel domain. -

Design of Efficient FPGA Circuits for Matching Complex Patterns in Network Intrusion Detection Systems
Design of Efficient FPGA Circuits for Matching Complex Patterns in Network Intrusion Detection Systems A Thesis Presented to The Academic Faculty By Christopher R. Clark In Partial Fulfillment Of the Requirements for the Degree Master of Science in Electrical and Computer Engineering Georgia Institute of Technology December 2003 Design of Efficient FPGA Circuits for Matching Complex Patterns in Network Intrusion Detection Systems Approved by: Dr. David E. Schimmel, Advisor School of ECE Dr. Sudhakar Yalamanchili School of ECE Dr. Wenke Lee College of Computing December 8, 2003 TABLE OF CONTENTS TABLE OF CONTENTS iii LIST OF TABLES v LIST OF FIGURES vi SUMMARY vii 1 BACKGROUND AND RELATED WORK 1 1.1 Pattern Matching in Network Intrusion Detection 1 1.2 Pattern Matching in Software 3 1.2.1 Single Pattern Algorithms 3 1.2.2 Multiple Pattern Algorithms 5 1.2.3 Intrusion Detection Algorithms 7 1.3 Pattern Matching with Reconfigurable Hardware 12 1.3.1 Introduction 12 1.3.2 Brute-Force Approach 14 1.3.3 Finite Automata Approaches 15 2 INTRODUCTION 21 2.1 Motivation 21 2.2 The HardIDS Project 22 3 IMPLEMENTATION 24 3.1 Efficient Circuit Design 24 3.2 High-Throughput Circuit Design 28 3.3 Support for Complex Patterns 30 iii 3.3.1 Case Insensitivity 30 3.3.2 Bounded-length Wildcards 31 3.4 Approximate Pattern Matching 34 3.5 Protocol Analysis 36 3.6 Automated Circuit Generation 38 3.7 System Integration 38 4 EVALUATION 40 4.1 Comparison of Circuit Design Approaches 40 4.1.1 Capacity Scalability 41 4.1.2 Throughput Scalability 44 4.2 Comparison