Clock Synchronization for Modern Multiprocessors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Washington, Wednesday, January 25, 1950
VOLUME 15 ■ NUMBER 16 Washington, Wednesday, January 25, 1950 TITLE 3— THE PRESIDENT in paragraph (a) last above, to the in CONTENTS vention is insufficient equitably to justify EXECUTIVE ORDER 10096 a requirement of assignment to the Gov THE PRESIDENT ernment of the entire right, title and P roviding for a U niform P atent P olicy Executive Order Pase for the G overnment W ith R espect to interest to such invention, or in any case where the Government has insufficient Inventions made by Government I nventions M ade by G overnment interest in an invention to obtain entire employees; providing, for uni E mployees and for the Administra form patent policy for Govern tion of Such P olicy right, title and interest therein (although the Government could obtain some under ment and for administration of WHEREAS inventive advances in paragraph (a), above), the Government such policy________________ 389 scientific and technological fields fre agency concerned, subject to the ap quently result from governmental ac proval of the Chairman of the Govern EXECUTIVE AGENCIES tivities carried on by Government ment Patents Board (provided for in Agriculture Department employees; and paragraph 3 of this order and herein See Commodity Credit Corpora WHEREAS the Government of the after referred to as the Chairman), shall tion ; Forest Service; Production United States is expending large sums leave title to such invention in the and Marketing Administration. of money annually for the conduct of employee, subject, however, to the reser these activities; -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

Meltdown and Spectre Understanding And
Meltdown and Spectre Prepared by Christopher Clai January 18th, 2018 Understanding and Remediation Strategy Broad Overview The General Law of Cross-Task Information Leakage “In any setting where short-term performance optimizations have global effect, a sufficiently clever task can infer the recent history of other tasks by observing its own performance.” Meltdown and Spectre are two hardware vulnerabilities that target the Central Processing Unit (CPU) of computing systems with cross-task information leakage. They were identified by four separate teams of security researchers who then disclosed the vulnerabilities to the company’s months prior to public disclosure. These vulnerabilities leverage the performance optimization architecture of modern day processors to their advantage. • Meltdown allows an attacker to retrieve kernel memory, which is privileged space in your Operating System that may contain password hashes and private keys for data decryption. • Spectre allows an attacker to retrieve information within the process it operates in, and execute code even if it was isolated in a sandbox within a process. The vulnerabilities require attackers to already have a way into your network, and at most can exfiltrate data from memory. They are unable to cause things such as privilege escalation, holding your data for ransom, or causing business disruption. They data they retrieve however, may be used for that purpose if it contains the information they are seeking. The initial rush of patches and microcode (firmware for CPU) updates have been somewhat brute and simplistic in their methods and only seek to mitigate potential practical exploit paths for these vulnerabilities. Researchers do not believe there will potential to fully prevent these types of exploits. -

Extended Memory 64 Technology Software Developer's Manual
IA-32 Intel® Architecture and Intel® Extended Memory 64 Technology Software Developer’s Manual Documentation Changes November 2004 Notice: The IA-32 Intel® Architecture and Intel® Extended Memory 64 Technology may contain design defects or errors known as errata that may cause the product to deviate from published specifications. Current characterized errata are documented in the specification updates. Document Number: 252046-011 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The IA-32 Intel® Architecture and Intel® Extended Memory 64 Technology may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -

Computers Shouldn't Be Limitations Advertising & Distribution a Handicap Is a Limitation
.. No. 48 July-August 1989 $3.95 T HE MICRO TECHN I CAL J 0 URN A L Tools For The Physically Impaired What's important to people who have handicaps? We asked them. (Their responses may surprise you.) The Adventure Begins page 8 Dallas Vordahl demonstrates what you can do with a computer, a mouthstick, and a very limited amount of head motion. Writing Software For page 16 The Blind Don' t exclude the blind from your next software package. File Transfer Via The page 20 Parallel Port The LIMBO Project page 28 Build a maze-running robot. And More ... Debugging A Processor page 44 Growing Your Own page 66 Software Business Great SOGs page 83 And Much, Much, More 07 a 7447019388 3 U[J!]£?[jj) J/@[J!]£? !fJ©llfU/5Ju O[jj)(]@ (j] /JJ@r:'.JQ£?fj[J!]O /LfI1@@£?(JJ(]@£?J/ (j][jj)@ @[jj)@]O[jj)QQ£?O[jj)@] (]@@ODDD Introducing ... The PC-LabCard Family Only from HSC Electronic Supply Digital 1/0 and Prototype Development IBM PC/XT/AT and it's Counter Card compatible models are moving into Card Industrial/Laboratory applications at • 32 Digital Input Channels • Large breadboard area (3290 holes) - TTL compatible an increasing rate. The reasons for • Independent memory and I/O address - Low loading: 0.2 rnA at O.4V input this include their price/performance decoders built-in • 32 Digital Output Channels ratio and short user learning curve. • Memory and I/O ports are jumper - TTL compatible PC-based data acquisition boards selectable - Driving capacity: Sink 24 rnA, are now taking the place of the • All bus signals are buffered, marked, source 15 rnA and ready for use • Intel 8253 Timer/Counter traditional data loggers or recorders - 3 channels of timer/counter which cost several times more. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
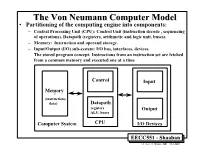
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Intel(R) 64 and IA32 Architectures Software Developer's Manual Vol 3B
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2 NOTE: The Intel® 64 and IA-32 Architectures Software Developer's Manual consists of five volumes: Basic Architecture, Order Number 253665; Instruction Set Reference A-M, Order Number 253666; Instruction Set Reference N-Z, Order Number 253667; System Programming Guide, Part 1, Order Number 253668; System Programming Guide, Part 2, Order Number 253669. Refer to all five volumes when evaluating your design needs. Order Number: 253669-031US June 2009 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANT- ED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR IN- TENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUA- TION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "unde- fined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. -

Philip Gibbs EVENT-SYMMETRIC SPACE-TIME
Event-Symmetric Space-Time “The universe is made of stories, not of atoms.” Muriel Rukeyser Philip Gibbs EVENT-SYMMETRIC SPACE-TIME WEBURBIA PUBLICATION Cyberspace First published in 1998 by Weburbia Press 27 Stanley Mead Bradley Stoke Bristol BS32 0EF [email protected] http://www.weburbia.com/press/ This address is supplied for legal reasons only. Please do not send book proposals as Weburbia does not have facilities for large scale publication. © 1998 Philip Gibbs [email protected] A catalogue record for this book is available from the British Library. Distributed by Weburbia Tel 01454 617659 Electronic copies of this book are available on the world wide web at http://www.weburbia.com/press/esst.htm Philip Gibbs’s right to be identified as the author of this work has been asserted by him in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved, except that permission is given that this booklet may be reproduced by photocopy or electronic duplication by individuals for personal use only, or by libraries and educational establishments for non-profit purposes only. Mass distribution of copies in any form is prohibited except with the written permission of the author. Printed copies are printed and bound in Great Britain by Weburbia. Dedicated to Alice Contents THE STORYTELLER ................................................................................... 11 Between a story and the world ............................................................. 11 Dreams of Rationalism ....................................................................... -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -

United States District Court Southern District Of
Case 3:11-cv-01812-JM-JMA Document 31 Filed 02/20/13 Page 1 of 10 1 2 3 4 5 6 7 8 9 UNITED STATES DISTRICT COURT 10 SOUTHERN DISTRICT OF CALIFORNIA 11 12 In re JIFFY LUBE ) Case No.: 3:11-MD-2261-JM (JMA) INTERNATIONAL, INC. TEXT ) 13 SPAM LITIGATION ) FINAL APPROVAL OF CLASS ) ACTION AND ORDER OF 14 ) DISMISSAL WITH PREJUDICE ) 15 16 Pending before the Court are Plaintiffs’ Motion for Final Approval of Class 17 Action Settlement (Dkt. 90) and Plaintiffs’ Motion for Approval of Attorneys’ Fees and 18 Expenses and Class Representative Incentive Awards (Dkt. 86) (collectively, the 19 “Motions”). The Court, having reviewed the papers filed in support of the Motions, 20 having heard argument of counsel, and finding good cause appearing therein, hereby 21 GRANTS Plaintiffs’ Motions and it is hereby ORDERED, ADJUDGED, and DECREED 22 THAT: 23 1. Terms and phrases in this Order shall have the same meaning as ascribed to 24 them in the Parties’ August 1, 2012 Class Action Settlement Agreement, as amended by 25 the First Amendment to Class Action Settlement Agreement as of September 28, 2012 26 (the “Settlement Agreement”). 27 2. This Court has jurisdiction over the subject matter of this action and over all 28 Parties to the Action, including all Settlement Class Members. 1 3:11-md-2261-JM (JMA) Case 3:11-cv-01812-JM-JMA Document 31 Filed 02/20/13 Page 2 of 10 1 3. On October 10, 2012, this Court granted Preliminary Approval of the 2 Settlement Agreement and preliminarily certified a settlement class consisting of: 3 4 All persons or entities in the United States and its Territories who in April 2011 were sent a text message from short codes 5 72345 or 41411 promoting Jiffy Lube containing language similar to the following: 6 7 JIFFY LUBE CUSTOMERS 1 TIME OFFER: REPLY Y TO JOIN OUR ECLUB FOR 45% OFF 8 A SIGNATURE SERVICE OIL CHANGE! STOP TO 9 UNSUB MSG&DATA RATES MAY APPLY T&C: JIFFYTOS.COM. -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction.