Appendix A: WGM Methodology 2018
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Check Against Boko Haram Terrorist Recalcitrance Around the Lake
International Journal of History and Cultural Studies (IJHCS) Volume 4, Issue 1, 2018, PP 37-55 ISSN 2454-7646 (Print) & ISSN 2454-7654 (Online) DOI: http://dx.doi.org/10.20431/2454-7654.0402004 www.arcjournals.org Stretching the Hypothetically “Unstretchable” Check against Boko Haram Terrorist Recalcitrance around the Lake Chad Basin Area: A Direct Payoff for Staking the State and State Interest on the Platter of Personal Attention Mark Bolak Funteh* PhD , Associate Professor, the University of Maroua, Cameroon, Africa *Corresponding Author: Mark Bolak Funteh, PhD Associate Professor, the University of Maroua, Cameroon, Africa. Abstract: With the emergence and the scary inhumane actions perpetrated by the terrorist Islamic sect, Boko Haram (BH) around the Lake Chad Basin region, it was certain that checking and annihilating this group would be a matter of a short breath following the military might, war experience of and the security sustaining interest of the inhabitant states. But the massive individual and collective state deployments to bring the phenomenon to book seemed ineffective, hence prolonging the supposedly short fight against these terror belligerents. Many scholars attribute the protracted resistance of the sect to the “asymmetrical” nature of the war, but this assumption has been waved away by many observers and critics of the issue. New approaches to the understanding of why BH and its activities have stayed obstinate to the sophisticated international and local diplomatic and military moves have becomes unavoidable. This paper, written on the basis of published and unpublished sources - actors, observers and eyewitness’s accounts for that matter – is a grass-root dimensional endeavor to the question. -

Boko Haram Beyond the Headlines: Analyses of Africa’S Enduring Insurgency
Boko Haram Beyond the Headlines: Analyses of Africa’s Enduring Insurgency Editor: Jacob Zenn Boko Haram Beyond the Headlines: Analyses of Africa’s Enduring Insurgency Jacob Zenn (Editor) Abdulbasit Kassim Elizabeth Pearson Atta Barkindo Idayat Hassan Zacharias Pieri Omar Mahmoud Combating Terrorism Center at West Point United States Military Academy www.ctc.usma.edu The views expressed in this report are the authors’ and do not necessarily reflect those of the Combating Terrorism Center, United States Military Academy, Department of Defense, or U.S. Government. May 2018 Cover Photo: A group of Boko Haram fighters line up in this still taken from a propaganda video dated March 31, 2016. COMBATING TERRORISM CENTER ACKNOWLEDGMENTS Director The editor thanks colleagues at the Combating Terrorism Center at West Point (CTC), all of whom supported this endeavor by proposing the idea to carry out a LTC Bryan Price, Ph.D. report on Boko Haram and working with the editor and contributors to see the Deputy Director project to its rightful end. In this regard, I thank especially Brian Dodwell, Dan- iel Milton, Jason Warner, Kristina Hummel, and Larisa Baste, who all directly Brian Dodwell collaborated on the report. I also thank the two peer reviewers, Brandon Kend- hammer and Matthew Page, for their input and valuable feedback without which Research Director we could not have completed this project up to such a high standard. There were Dr. Daniel Milton numerous other leaders and experts at the CTC who assisted with this project behind-the-scenes, and I thank them, too. Distinguished Chair Most importantly, we would like to dedicate this volume to all those whose lives LTG (Ret) Dell Dailey have been afected by conflict and to those who have devoted their lives to seeking Class of 1987 Senior Fellow peace and justice. -

B133 Cameroon's Far North Reconstruction Amid Ongoing Conflict
Cameroon’s Far North: Reconstruction amid Ongoing Conflict &ULVLV*URXS$IULFD%ULHILQJ1 1DLUREL%UXVVHOV2FWREHU7UDQVODWHGIURP)UHQFK I. Overview Cameroon has been officially at war with Boko Haram since May 2014. Despite a gradual lowering in the conflict’s intensity, which peaked in 2014-2015, the contin- uing violence, combined with the sharp rise in the number of suicide attacks between May and August 2017, are reminders that the jihadist movement is by no means a spent force. Since May 2014, 2,000 civilians and soldiers have been killed, in addition to the more than 1,000 people kidnapped in the Far North region. Between 1,500 and 2,100 members of Boko Haram have reportedly been killed following clashes with the Cameroonian defence forces and vigilante groups. The fight against Boko Haram has exacerbated the already-delicate economic situation for the four million inhabitants of this regionௗ–ௗthe poorest part of the country even before the outbreak of the conflict. Nevertheless, the local population’s adaptability and resilience give the Cameroonian government and the country’s international partners the opportunity to implement development policies that take account of the diversity and fluidity of the traditional economies of this border region between Nigeria and Chad. The Far North of Cameroon is a veritable crossroads of trading routes and cultures. Besides commerce, the local economy is based on agriculture, livestock farming, fishing, tourism, transportation of goods, handcrafts and hunting. The informal sector is strong, and contraband rife. Wealthy merchants and traditional chiefsௗ–ௗoften members of the ruling party and high-ranking civil servantsௗ–ௗare significant economic actors. -

The Boko Haram Conflict in Cameroon Why Is Peace So Elusive? Pr
Secur nd ity a S e e c r i a e e s P FES Pr. Ntuda Ebode Joseph Vincent Pr. Mark Bolak Funteh Dr. Mbarkoutou Mahamat Henri Mr. Nkalwo Ngoula Joseph Léa THE BOKO HARAM CONFLICT IN CAMEROON Why is peace so elusive? Pr. Ntuda Ebode Joseph Vincent Pr. Mark Bolak Funteh Dr. Mbarkoutou Mahamat Henri Mr. Nkalwo Ngoula Joseph Léa THE BOKO HARAM CONFLICT IN CAMEROON Why is peace so elusive? Translated from the French by Diom Richard Ngong [email protected] © Friedrich Ebert Stiftung, Yaoundé (Cameroun), 2017. Tél. 00 237 222 21 29 96 / 00 237 222 21 52 92 B.P. 11 939 Yaoundé / Fax: 00 237 222 21 52 74 E-mail : [email protected] Site : www.fes-kamerun.org Réalisation éditoriale : PUA : www.aes-pua.com ISBN: 978-9956-532-05-3 Any commercial use of publications, brochures or other printed materials of the Friedrich Ebert Stiftung is strictly forbidden unless otherwise authorized in writing by the publisher This publication is not for sale All rights reserved No part of this book may be reproduced in any form, by print, photo print, microfilm, translation or other means without written permission from the publisher TABLE OF CONTENTS Acknowledgements ………………………………………………….....……………....................…………..................... 5 Abbreviations and acronyms ………………………………………...........…………………………….................... 6 Introduction ………………………………………………………………………....................………………....….................... 7 Chapter I – Background and context of the emergence of Boko Haram in Cameroon ……………………………………………………………………………………....................………….................... 8 A. Historical background to the crisis in the Far North region ……………..……….................... 8 B. Genesis of the Boko Haram conflict ………………………………………………..................................... 10 Chapter II - Actors, challenges and prospects of a complex conflict ……………....... 12 A. Actors and the challenges of the Boko Haram conflict …………………………….....................12 1. -

GE84/275 BR IFIC Nº 2893 Section Spéciale Special Section
Section spéciale Index BR IFIC Nº 2893 Special Section GE84/275 Sección especial Indice International Frequency Information Circular (Terrestrial Services) ITU - Radiocommunication Bureau Circular Internacional de Información sobre Frecuencias (Servicios Terrenales) UIT - Oficina de Radiocomunicaciones Circulaire Internationale d'Information sur les Fréquences (Services de Terre) UIT - Bureau des Radiocommunications Date/Fecha : 16.04.2019 Expiry date for comments / Fecha limite para comentarios / Date limite pour les commentaires : 25.07.2019 Description of Columns / Descripción de columnas / Description des colonnes Intent Purpose of the notification Propósito de la notificación Objet de la notification 1a Assigned frequency Frecuencia asignada Fréquence assignée 4a Name of the location of Tx station Nombre del emplazamiento de estación Tx Nom de l'emplacement de la station Tx B Administration Administración Administration 4b Geographical area Zona geográfica Zone géographique 4c Geographical coordinates Coordenadas geográficas Coordonnées géographiques 6a Class of station Clase de estación Classe de station 1b Vision / sound frequency Frecuencia de portadora imagen/sonido Fréquence image / son 1ea Frequency stability Estabilidad de frecuencia Stabilité de fréquence 1e carrier frequency offset Desplazamiento de la portadora Décalage de la porteuse 7c System and colour system Sistema de transmisión / color Système et système de couleur 9d Polarization Polarización Polarisation 13c Remarks Observaciones Remarques 9 Directivity Directividad -

Cameroon | Displacement Report, Far North Region Round 9 | 26 June – 7 July 2017 Cameroon | Displacement Report, Far North Region, Round 9 │ 26 June — 7 July 2017
Cameroon | Displacement Report, Far North Region Round 9 | 26 June – 7 July 2017 Cameroon | Displacement Report, Far North Region, Round 9 │ 26 June — 7 July 2017 The opinions expressed in the report are those of the authors and do not necessarily reflect the views of the International Organization for Migration (IOM). The designations employed and the presentation of material throughout the report do not imply the expression of any opinion whatsoever on the part of IOM concerning the legal status of any country, territory, city or area, or of its authorities, or concerning its frontiers or boundaries.1 IOM is committed to the principle that humane and orderly migration benefits migrants and society. As an intergovernmental organization, IOM acts with its partners in the international community to: assist in meeting the operational challenges of migration; advance understanding of migration issues; encourage social and economic development through migration; and uphold the human dignity and well-being of migrants. International Organization for Migration UN House Comice Maroua Far North Region Cameroon Cecilia Mann Tel.: +237 691 794 050 E-mail: [email protected] Website: www.globaldtm.info/cameroon/ © IOM 2017 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise without the prior written permission of the publisher. 1 The maps included in this report are illustrative. The representations and the use of borders and geographic names may include errors and do not imply judgment on legal status of territories nor acknowledgement of borders by the Organization. -
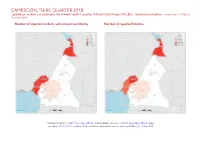
Cameroon, Third Quarter 2018: Update on Incidents According to the Armed Conflict Location & Event Data Project
CAMEROON, THIRD QUARTER 2018: Update on incidents according to the Armed Conflict Location & Event Data Project (ACLED) - Updated 2nd edition compiled by ACCORD, 20 December 2018 Number of reported incidents with at least one fatality Number of reported fatalities National borders: GADM, November 2015b; administrative divisions: GADM, November 2015a; incid- ent data: ACLED, 15 December 2018; coastlines and inland waters: Smith and Wessel, 1 May 2015 CAMEROON, THIRD QUARTER 2018: UPDATE ON INCIDENTS ACCORDING TO THE ARMED CONFLICT LOCATION & EVENT DATA PROJECT (ACLED) - UPDATED 2ND EDITION COMPILED BY ACCORD, 20 DECEMBER 2018 Contents Conflict incidents by category Number of Number of reported fatalities 1 Number of Number of Category incidents with at incidents fatalities Number of reported incidents with at least one fatality 1 least one fatality Violence against civilians 85 64 159 Conflict incidents by category 2 Battles 81 52 284 Development of conflict incidents from September 2016 to September Strategic developments 24 0 0 2018 2 Riots/protests 8 0 0 Methodology 3 Remote violence 4 1 4 Non-violent activities 1 0 0 Conflict incidents per province 4 Total 203 117 447 Localization of conflict incidents 4 This table is based on data from ACLED (datasets used: ACLED, 15 December 2018). Disclaimer 5 Development of conflict incidents from September 2016 to September 2018 This graph is based on data from ACLED (datasets used: ACLED, 15 December 2018). 2 CAMEROON, THIRD QUARTER 2018: UPDATE ON INCIDENTS ACCORDING TO THE ARMED CONFLICT LOCATION & EVENT DATA PROJECT (ACLED) - UPDATED 2ND EDITION COMPILED BY ACCORD, 20 DECEMBER 2018 Methodology Geographic map data is primarily based on GADM, complemented with other sources if necessary. -

Christian Churches and the Boko Haram Insurgency in Cameroon: Dilemmas and Responses
religions Article Christian Churches and the Boko Haram Insurgency in Cameroon: Dilemmas and Responses Lang Michael Kpughe Department of History, Higher Teacher Training College, University of Bamenda, Bambili-Bamenda 39, Cameroon; [email protected] Received: 15 June 2017; Accepted: 1 August 2017; Published: 7 August 2017 Abstract: The spillover of the terrorist activities of Boko Haram, a Nigerian jihadi group, into Cameroon’s north has resulted in security challenges and humanitarian activity opportunities for Christian churches. The insurgents have attacked and destroyed churches, abducted Christians, worsened Muslim-Christian relations, and caused a humanitarian crisis. These ensuing phenomena have adversely affected Christian churches in this region, triggering an aura of responses: coping strategies, humanitarian work among refugees, and inter-faith dialogue. These responses are predicated on Christianity’s potential as a resource for peace, compassion, and love. In this study we emphasize the role of Christian churches in dealing with the Boko Haram insurgency. It opens with a presentation of the religious configuration of Cameroon, followed by a contextualization of Boko Haram insurgency in Cameroon’s north. The paper further examines the brutality meted out on Christians and church property. The final section is an examination of the spiritual, humanitarian, and relief services provided by churches. The paper argues that although Christian churches have suffered at the hands of Boko Haram insurgents, they have engaged in various beneficial responses underpinned by the Christian values of peace and love. Keywords: Cameroon; terrorism; religion; Islam; Boko Haram; Christian Churches; peace 1. Introduction There is a consensus in the available literature that all religions have within the practices ensuing from their foundational beliefs both violent and peaceful tendencies (Bercovitch and Kadayifci-Orellana 2009; Chapman 2007; Fox 1999). -

Cameroon Humanitarian Situation Report
Cameroon Humanitarian Situation Report ©UNICEF Cameroon/2019 SITUATION IN NUMBERS May 2019 Highlights 2,300,000 # of children in need of humanitarian • By May 2019, UNICEF and its partners have distributed assistance 4,300,000 WASH kits to more than 78,000 people in the North-West # of people in need and South-West regions. (Cameroon Humanitarian Needs Overview 2019) • In May, more than 9,000 families have received Long Displacement Lasting Insecticidal Nets (LLIN) through UNICEF’s 444,213 assistance in the North-West and South-West regions. # of Internally Displaced Persons (IDPs) in the North-West and South-West regions • On 20 May, the primary data collection for the education (OCHA Displacement Monitoring, December 2018) need assessment has started in the North-West and South- 237,349 West regions. # of Returnees in the North-West and South- West regions (OCHA Displacement • On 22 May, a case of polio virus type 2 from an Monitoring, December 2018) environmental sample was confirmed in Mada health 372,854 # of IDPs and Returnees in the Far-North district of Logone-et-Chari in the Far-North region. region (IOM Displacement Tracking Matrix 18, April 2019) 102,963 UNICEF’s Response with Partners # of Nigerian Refugees in rural areas (UNHCR Fact Sheet, May 2019) Sector Total UNICEF Total Target Results* Target Results* WASH: People provided with UNICEF Appeal 2019 374,758 29,941 75,000 20,181 access to appropriate sanitation US$ 39.3 million Education: Number of boys and girls (3 to 17 years) affected by 363,300 2,415 217,980 0 crisis receiving learning materials Nutrition**: Number of children Funds aged 6-59 months with SAM 60,255 23,459 65,064 24,413 received admitted for treatment $ 4.5M Carry- Child Protection: Children over $ 3.2 M reached with psychosocial support 563,265 90,966 289,789 39,173 2019 funding through child friendly/safe spaces requirement: C4D: Persons reached with key $39.3 M life- saving & behaviour change 385,000 35,275 messages *Total results are cumulative. -

Rapid Needs Assessment Report Cameroon / Far North / Logone & Chari
Rapid Needs Assessment Report Cameroon / Far North / Logone & Chari International Medical Corps October 2016 Monitoring & Evaluation Department Needs Assessment Report – Logone et Chari International Medical Corps Contents I. Liste des abréviations et sigles ........................................................................................................ 4 II. Remerciements ................................................................................................................................ 5 III. Résumé ........................................................................................................................................ 6 IV. Contexte et justification .............................................................................................................. 7 V. Méthodologie ................................................................................................................................ 14 Objectifs ............................................................................................................................................ 14 Sélection des zones d’évaluation ...................................................................................................... 14 Méthode de collecte de données ....................................................................................................... 15 L’équipe d’évaluation ....................................................................................................................... 19 Techniques d’analyse des données -

Cameroon Humanitarian Situation Report
Cameroon Humanitarian Situation Report ©UNICEF Cameroon/2019 SITUATION IN NUMBERS Highlights August 2019 2,300,000 • More than 118,000 people have benefited from UNICEF’s # of children in need of humanitarian assistance humanitarian assistance in the North-West and South-West 4,300,000 regions since January including 15,800 in August. # of people in need (Cameroon Humanitarian Needs Overview 2019) • The Rapid Response Mechanism (RRM) strategy, Displacement established in the South-West region in June, was extended 530,000 into the North-West region in which 1,640 people received # of Internally Displaced Persons (IDPs) in the North- WASH kits and Long-Lasting Insecticidal Nets (LLINs) in West and South-West regions (OCHA Displacement Monitoring, July 2019) August. 372,854 # of IDPs and Returnees in the Far-North region • In August, 265,694 children in the Far-North region were (IOM Displacement Tracking Matrix 18, April 2019) vaccinated against poliomyelitis during the final round of 105,923 the vaccination campaign launched following the polio # of Nigerian Refugees in rural areas (UNHCR Fact Sheet, July 2019) outbreak in May. UNICEF Appeal 2019 • During the month of August, 3,087 children received US$ 39.3 million psychosocial support in the Far-North region. UNICEF’s Response with Partners Total funding Funds requirement received Sector Total UNICEF Total available 20% $ 4.5M Target Results* Target Results* Carry-over WASH: People provided with 374,758 33,152 75,000 20,181 $ 3.2 M access to appropriate sanitation 2019 funding Education: Number of boys and requirement: girls (3 to 17 years) affected by 363,300 2,415 217,980 0 $39.3 M crisis receiving learning materials Nutrition**: Number of children Funding gap aged 6-59 months with SAM 60,255 39,727 65,064 40,626 $ 31.6M admitted for treatment Child Protection: Children reached with psychosocial support 563,265 160,423 289,789 87,110 through child friendly/safe spaces C4D: Persons reached with key life- saving & behaviour change 385,000 431,034 messages *Total results are cumulative. -

Republique Du Cameroun Republic of Cameroon Details Des Projets Par Region, Departement, Chapitre, Programme Et Action Extreme N
REPUBLIQUE DU CAMEROUN REPUBLIC OF CAMEROON PAIX - TRAVAIL - PATRIE PEACE - WORK - FATHERLAND DETAILS DES PROJETS PAR REGION, DEPARTEMENT, CHAPITRE, PROGRAMME ET ACTION OPERATIONS BOOK PER REGION, DIVISION, HEAD, PROGRAMME AND ACTION Exercice/ Financial year : 2017 Région EXTREME NORD Region FAR NORTH Département DIAMARE Division En Milliers de FCFA In Thousand CFAF Année de Tâches démarrage Localité Montant AE Montant CP Tasks Starting Year Locality Montant AE Montant CP Chapitre/Head MINISTERE DE L'ADMINISTRATION TERRITORIALE ET DE LA DECENTRALISATION 07 MINISTRY OF TERRITORIAL ADMINISTRATION AND DECENTRALIZATION PETTE : Reprogrammation des travaux de construction de la sous-préfecture (Phase 1) PETTE 50 000 50 000 2 017 PETTE : Reprogramming of the construction of the Sub-Divisional Office MAROUA: Règlement de la maîtrise d'œuvre pour la construction résidence Préfet MAROUA 5 350 5 350 MAROUA: Payment of the project management of the construction of the residence of 2 017 the SDO MAROUA: Règlement des travaux de la première phase de construction résidence Préfet MAROUA 80 000 80 000 2 017 MAROUA: Payment of the construction of the residence of the SDO Total Chapitre/Head MINATD 135 350 135 350 Chapitre/Head MINISTERE DE LA JUSTICE 08 MINISTRY OF JUSTICE Cour d'Appel de l'Extrême-Nord : Etudes architecturales et géotechniques pour la MAROUA I 40 000 5 000 construction 2 017 Architectural and geotchnical construction studies of the Court of Appeal of Far-North Total Chapitre/Head MINJUSTICE 40 000 5 000 Chapitre/Head MINISTERE DES MARCHES