H2-For-The-Arts Documentation Release 2020 Raffaella D'auria
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IBM Cloud Unit 2016 IBM Cloud Unit Leadership Organization
IBM Cloud Technical Academy IBM Cloud Unit 2016 IBM Cloud Unit Leadership Organization SVP IBM Cloud Robert LeBlanc GM Cloud Platform GM Cloud GM Cloud Managed GM Cloud GM Cloud Object Integration Services Video Storage Offering Bill Karpovich Mike Valente Braxton Jarratt Line Execs Line Execs Marie Wieck John Morris GM Strategy, GM Client Technical VP Development VP Service Delivery Business Dev Engagement Don Rippert Steve Robinson Harish Grama Janice Fischer J. Comfort (GM & CTO) J. Considine (Innovation Lab) Function Function Leadership Leadership VP Marketing GM WW Sales & VP Finance VP Human Quincy Allen Channels Resources Steve Cowley Steve Lasher Sam Ladah S. Carter (GM EcoD) GM Design VP Enterprise Mobile GM Digital Phil Gilbert Phil Buckellew Kevin Eagan Missions Missions Enterprise IBM Confidential IBM Hybrid Cloud Guiding Principles Choice with! Hybrid ! DevOps! Cognitive Powerful, Consistency! Integration! Productivity! Solutions! Accessible Data and Analytics! The right Unlock existing Automation, tooling Applications and Connect and extract workload in the IT investments and composable systems that insight from all types right place and Intellectual services to increase have the ability to of data Property speed learn Three entry points 1. Create! 2. Connect! 3. Optimize! new cloud apps! existing apps and data! any app! 2016 IBM Cloud Offerings aligned to the Enterprise’s hybrid cloud needs IBM Cloud Platform IBM Cloud Integration IBM Cloud Managed Offerings Offerings Services Offerings Mission: Build true cloud platform -
Securebox Azure
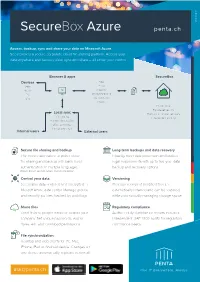
General Electronics E-Commerce General Web General General General Electronics General Location Electronics E-Commerce Electronics Electronics Arrows General Web Electronics E-Commerce E-Commerce E-Commerce Web Location GeneraE-Col mmerce Weather Web Arrows WeWeb b Electronics Location Weather Miscellaneous Location Arrows Location Location Arrows Arrows Miscellaneous Electronics E-Commerce Arrows Weather Weather Weather Miscellaneous Web 28/03/2019 Weather SecureBox Azure penta.ch General Miscellaneous Access, backup, sync and share your data on Microsoft Azure SecureBox is a secure corporate cloud file sharing platform. Access your data anywhere and backup, view, sync and share – all under your control. Miscellaneous E-Commerce Browser & apps General SecureBox Devices Files Tablet Email Mobile Calendar PC Word processing Mac Spreadsheets Miscellaneous Photos Private cloud Bank-level security Local sync Backups & disaster recovery File sharing Independent auditing Password protection Editing permissions Link expiry dates Internal users External users SecureLo filecati sharingon and backup Long-term backups and data recovery The secure alternative to public cloud Instantly meet data protection and backup file sharing and backup with bank-level legal requirements with up to five-year data authentication. In multiple languages. backup and recovery options. English, French, German, Italian, Spanish and Arabic Web Control your data Versioning SecureBox data is stored and encrypted in Previous version of modified files are Microsft Azure data center. Manage groups automatically retained and can be restored, and security policies, backed by audit logs. while automatically managing storage space. Share files Regulatory compliance Send Arrolinks to wspeople inside or outside your Auditor-ready compliance reports included. company. Set unique passwords, expiry IndependentElec ISAEtr onic3402 auditss for regulatory dates, edit and download permissions. -

Mimioclassroom User Guide for Windows
MimioClassroom User Guide For Windows mimio.com © 2012 Sanford, L.P. All rights reserved. Revised 12/4/2012. No part of this document or the software may be reproduced or transmitted in any form or by any means or translated into another language without the prior written consent of Sanford, L.P. Mimio, MimioClassroom, MimioTeach, MimioCapture, MimioVote, MimioView, MimioHub, MimioPad, and MimioStudio are registered marks in the United States and other countries. All other trademarks are the property of their respective holders. Contents About MimioClassroom 1 MimioStudio 1 MimioTeach 1 Mimio Interactive 1 MimioCapture 2 Mimio Capture Kit 2 MimioVote 2 MimioView 2 MimioPad 2 Minimum System Requirements 2 Using this Guide 3 MimioStudio 7 About MimioStudio 7 About MimioStudio Notebook 7 About MimioStudio Tools 7 About MimioStudio Gallery 9 Getting Started with MimioStudio 9 Accessing MimioStudio Notebook 9 Accessing MimioStudio Tools 10 Accessing MimioStudio Gallery 10 Using MimioStudio Notebook 10 Working with Pages 11 Creating an Activity 14 Creating an Activity - Step 1: Define 14 Creating an Activity - Step 2: Select 14 Creating an Activity - Step 3: Refine 15 Creating an Activity - Step 4: Review 16 Working with an Activity 17 Writing an Objective 17 Attaching Files 18 Using MimioStudio Tools 18 Creating Objects 18 Manipulating Objects 21 Adding Actions to Objects 25 Using MimioStudio Gallery 26 iii Importing Gallery Items into a Notebook 27 Customizing the Content of the Gallery 27 Exporting a Gallery Folder to a Gallery File 29 Working -

Wandisco Fusion® Microsoft Azure Data Box
WANDISCO FUSION® MICROSOFT AZURE DATA BOX Use WANdisco Fusion with Data Box for bulk transfer of changing data WANdisco Fusion is the only solution that enables Microsoft customers to use the bulk transfer capabilities of the Azure Data Box to transfer static and changing Guaranteed data consistency information from Big Data applications to Azure Cloud with guaranteed data consistency. Users can continue to Take advantage of the storage on Azure Data Box for write to their local cluster while the Azure Data Box is in bulk data transfer while continuing to write to a local transit so when the Azure Data Box is subsequently being cluster and replicate those changes while the Azure uploaded, any changes are replicated to the Azure Cloud Data Box is uploaded to the Azure Cloud. with guaranteed consistency. Easy and intuitive step-by-step operation • Applications write to Azure Data Box using the same API that they use to interact with the Azure Cloud. No downtime and • WANdisco Fusion for Azure Data Box requires no change to applications which can continue to use the no business disruption API as they would normally. Write data to a local HDFS-compatible endpoint • Replication is continuous and recovers from on-premises and replicate to a storage location in intermittent network or system failures automatically. Microsoft Azure with no modification or disruption to applications on-premises. AZURE 2 STORAGE Cost saving MICROSOFT 1 3 AZURE DATA BOX Avoid the high network costs common to large scale data transfers and benefit from a range of FUSION applications available in Azure Cloud. -

1) Installation 2) Configuration
rclone 1) Installation........................................................................................................................................1 2) Configuration...................................................................................................................................1 2.1) Server setup..............................................................................................................................1 2.2) Client setup...............................................................................................................................2 2.3) Server setup - part 2..................................................................................................................2 2.4) Client verification.....................................................................................................................3 2.5) rclone - part 1............................................................................................................................3 2.6) rclone - part 2............................................................................................................................4 3) Backup configuration.......................................................................................................................5 4) Usage................................................................................................................................................5 1) Installation https://rclone.org/install/ Script installation To install rclone on Linux/macOS/BSD -

Ranger Environment Documentation
Ranger Environment Documentation Drew Dolgert May 18, 2010 Contents 1 Introduction 2 1.1 Ranger Hardware ....................................... 2 2 Connect 3 2.1 Login Nodes ........................................... 3 2.2 Exercise: Use SSH to Connect ................................ 3 2.2.1 SSH from Linux or Mac ................................ 3 2.2.2 SSH from Windows .................................. 3 2.3 Starting: Read Examples of Sessions ............................ 4 2.4 Further Exercise: Using X-Windows to Connect ...................... 5 2.4.1 Opening a Connection From Mac .......................... 5 2.4.2 Opening a Connection From Linux ......................... 6 2.4.3 Opening a Connection From Windows ....................... 6 2.5 Exercise: Connect with VNC ................................. 9 2.6 Further Exercise: Choose Your Shell ............................ 9 2.7 Advanced: Make Login Faster ................................ 10 2.7.1 Making Shortcuts on Windows ............................ 10 2.7.2 Setup SSH Keys for No Password Login ....................... 10 3 Using Module 10 3.1 About the Module Command ................................. 10 3.2 Discussion Exercise: Learn Modules ............................ 11 3.3 Modules List .......................................... 11 3.4 Exercise: Compilation with Modules ............................ 15 3.5 Further Exercise: Module Dependencies .......................... 15 4 Running in Batch 17 4.1 Text Editors ........................................... 17 4.1.1 VI Cheat Sheet -

Introduction to Programming Systems an X Window System COS 217 Computing Environment
Princeton University COS 217: Introduction to Programming Systems An X Window System COS 217 Computing Environment The handout from the first precept entitled A Minimal COS 217 Computing Environment describes how to create and use a computing environment that is sufficient for COS 217. If you're satisfied with that environment, then you can ignore the rest of this document. The minimal computing environment has some disadvantages. Probably the biggest is that it can't handle input from pointing devices (mice, touchpads, and so forth). In particular, you might find it difficult to get comfortable with Emacs editing in the absence of a pointing device. A reasonable alternative to the minimal environment is the X Window System environment. Essentially, the X Window System integrates the local computer's windowing system with a remote Linux system. The web page http://en.wikipedia.org/wiki/X_Window_System provides details. The biggest advantage of the X Window System environment is that it allows you to use a pointing device when editing with Emacs. Its biggest disadvantages are that (1) setup is more difficult, and (2) it doesn't work well off campus, that is, with a lower-bandwidth network. The instructions given below describe how to connect your computer to CourseLab using the X Window System environment. When thus connected to CourseLab: Issuing a command of the form emacs filename displays a new window for Emacs. You can use a pointing device to manipulate that window. The shell hangs until you terminate your Emacs session. Issuing a command of the form emacs filename & (note the trailing ampersand) displays a new window for Emacs. -

SUSE® Linux Enterprise Desktop 12 and the Workstation Extension: What's New ?
SUSE® Linux Enterprise Desktop 12 and the Workstation Extension: What's New ? Frédéric Crozat <[email protected]> Enterprise Desktop Release Manager Scott Reeves <[email protected]> Enterprise Desktop Development Manager Agenda • Design Criteria • Desktop Environment in SUSE Linux Enterprise 12 • GNOME Shell • Desktop Features and Applications 2 Design Criteria SUSE Linux Enterprise Desktop Interoperability Ease of Use Security Ease of Management Lower Costs 4 SUSE Linux Enterprise Desktop 12 • Focus on technical workstation ‒ Developers and System administrators • One tool for the job • Main desktop applications will be shipped: ‒ Mail client, Office Suite, Graphical Editors, ... • SUSE Linux Enterprise Workstation Extension ‒ Extend SUSE Linux Enterprise Server with packages only available on SUSE Linux Enterprise Desktop. (x86-64 only) 5 Desktop in SUSE Linux Enterprise 12 As Part of the Common Code Base SUSE Linux Enterprise 12 Desktop Environment • SUSE Linux Enterprise 12 contains one primary desktop environment • Additional light-weight environment for special use-cases: ‒ Integrated Systems • Desktop environment is shared between the server and desktop products 7 SUSE Linux Enterprise 12 Desktop Environment • GNOME 3 is the main desktop environment ‒ SLE Classic mode by default ‒ GNOME 3 Classic Mode and GNOME 3 Shell Mode also available • SUSE Linux Enterprise 12 ships also lightweight IceWM ‒ Targeted at Integrated Systems • QT fully supported: ‒ QT5 supported for entire SLE12 lifecycle ‒ QT4 supported, will be removed in future -

El-Arte-De-La-Linea-De-Comandos
Traducido por Lyx Drymer Maxxcan Zorro Fanta Suggie y Frangor de El Binario 2 Indice´ general 0.1. El arte de la l´ınea de comandos . .4 0.1.1. Meta . .4 0.1.2. Fundamentos . .5 0.1.3. De uso diario . .6 0.1.4. Procesamiento de archivos y datos . .8 0.1.5. Depuracion´ del sistema . 10 0.1.6. Comandos concatenados . 11 0.1.7. Oscuro pero util´ . 13 0.1.8. Solo MacOS . 15 0.1.9. Mas´ recursos . 16 0.1.10. Advertencia . 16 0.1.11. Licencia . 16 3 4 INDICE´ GENERAL 0.1. El arte de la lınea´ de comandos La soltura del uso de la consola es una destreza a menudo abandonada y considerada arcaica, pero mejorara´ tu flexibilidad y productividad como si fueras un i ngeniero de una forma obvia y sutil. Esta es una seleccion´ de notas y consejos de como usar la l´ınea de comandos de consola que encontre´ util´ cuando trabajaba en Linux. Algunos consejos son basicos,´ y otros bastante espec´ıficos, sofiscitados, u .oscuros”. Esta pagina´ no es larga, pero si usas y recuerdas todos los puntos, sabras´ lo suficiente. Figura 1: curl -s ‘https://raw.githubusercontent.com/jlevy/the-art-of-command- line/master/README.md’q j egrep -o ‘nw+’ j tr -d “’ j cowsay -W50 0.1.1. Meta Objetivo: Esta gu´ıa es tanto para el principiante como para el experimentado. Los objeti- vos son amplitud (todo importa), especificidad (dar ejemplos concretos del uso mas´ comun),´ y brevedad (evitar lo que no sea esencial o que se puedan encontrar facil-´ mente en otro lugar). -

Scaling a Game-Sharing Platform Introduction
Level Up and SIMMER.io Down Scaling a Game-sharing Platform Introduction Much like gaming, starting a business means a lot of trial and error. In the beginning, you’re just trying to get your bearings and figure out which enemy to fend off first. After a few hours (or a few years on the market), it’s time to level up. SIMMER.io, a community site that makes sharing Unity WebGL games easy for indie game developers, leveled up in a big way to make their business sustainable for the long haul. When the site was founded in September 2017, the development team focused on getting the platform built and out the door, not on what egress costs would look like down the road. As it grew into a home for 80,000+ developers and 30,000+ games, though, those costs started to encroach on their ability to sustain and grow the business. We spoke with the SIMMER.io development team about their experience setting up a multi-cloud solution—including their use of the Bandwidth Alliance between Cloudflare and Backblaze B2 Cloud Storage to reduce egress to $0—to prepare the site for continued growth. © 2021 Backblaze Inc. All rights reserved. 500 Ben Franklin Ct. San Mateo, CA 94401 USA How to Employ a Multi-cloud Approach for Scaling a Web Application In 2017, sharing games online with static hosting through a service like AWS S3 was possible but certainly not easy. As one SIMMER.io team member put it, “No developer in the world would want to go through that.” The team saw a clear market opportunity. -

Initial Definition of Protocols and Apis
Initial definition of protocols and APIs Project acronym: CS3MESH4EOSC Deliverable D3.1: Initial Definition of Protocols and APIs Contractual delivery date 30-09-2020 Actual delivery date 16-10-2020 Grant Agreement no. 863353 Work Package WP3 Nature of Deliverable R (Report) Dissemination Level PU (Public) Lead Partner CERN Document ID CS3MESH4EOSC-20-006 Hugo Gonzalez Labrador (CERN), Guido Aben (AARNET), David Antos (CESNET), Maciej Brzezniak (PSNC), Daniel Muller (WWU), Jakub Moscicki (CERN), Alessandro Petraro (CUBBIT), Antoon Prins Authors (SURFSARA), Marcin Sieprawski (AILLERON), Ron Trompert (SURFSARA) Disclaimer: The document reflects only the authors’ view and the European Commission is not responsible for any use that may be made of the information it contains. This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 863353 Table of Contents 1 Introduction ............................................................................................................. 3 2 Core APIS .................................................................................................................. 3 2.1 Open Cloud Mesh (OCM) ...................................................................................................... 3 2.1.1 Introduction .......................................................................................................................................... 3 2.1.2 Advancing OCM .................................................................................................................................... -

Release Notes for Xfree86® 4.8.0 the Xfree86 Project, Inc December 2008
Release Notes for XFree86® 4.8.0 The XFree86 Project, Inc December 2008 Abstract This document contains information about the various features and their current sta- tus in the XFree86 4.8.0 release. 1. Introduction to the 4.x Release Series XFree86 4.0 was the first official release of the XFree86 4 series. The current release (4.8.0) is the latest in that series. The XFree86 4.x series represents a significant redesign of the XFree86 X server,with a strong focus on modularity and configurability. 2. Configuration: aQuickSynopsis Automatic configuration was introduced with XFree86 4.4.0 which makes it possible to start XFree86 without first creating a configuration file. This has been further improved in subsequent releases. If you experienced any problems with automatic configuration in a previous release, it is worth trying it again with this release. While the initial automatic configuration support was originally targeted just for Linux and the FreeBSD variants, as of 4.5.0 it also includes Solaris, NetBSD and OpenBSD support. Full support for automatic configuration is planned for other platforms in futurereleases. If you arerunning Linux, FreeBSD, NetBSD, OpenBSD, or Solaris, try Auto Configuration by run- ning: XFree86 -autoconfig If you want to customise some things afterwards, you can cut and paste the automatically gener- ated configuration from the /var/log/XFree86.0.log file into an XF86Config file and make your customisations there. If you need to customise some parts of the configuration while leav- ing others to be automatically detected, you can combine a partial static configuration with the automatically detected one by running: XFree86 -appendauto If you areusing a platform that is not currently supported, then you must try one of the older methods for getting started like "xf86cfg", which is our graphical configuration tool.