Implementing a Telemedicine System for Remote Medical Consultation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ON Soluciones
€ Número 71 - Diciembre 2016 - 14 Call & Contact Centers / Customer Engagement / BPO by ON Soluciones renueva su imagen como expertos Santiago Muñoz-Chápulí socio fundador en la construcción de experiencias de ON Soluciones generadas desde el contact center. María José Peraza socia de ON Soluciones En positivo Enred@dos Hoy hablamos con... Caso de éxito Analizamos el mapa Responsables Charlamos con José En Schibsted Spain, desde del viaje del cliente de Hawkers nos Miguel Zarco, KAM- el área recién inaugurada como herramienta cuentan su estrategia Ventas Microempresas de “Customer Experience que ayuda a dar para lograr tener en Vodafone España Management” han valor a los momentos legiones de clientes sobre su trayectoria incorporado la voz del de la verdad. fans. profesional. cliente en la organización. / P.10 / P.44 / P.56 / P.70 Nº 71 ODiciembre 2016 ORelación Cliente Magazine ENE CASO DE ÉXITO 20 REPSOL PORTADAP PROTAGONISTA 22 Arvato 6 EN PRIMERA LÍNEA DE FUEGO ONO SOLUCIONES 24 Teletrabajo La empresa busca posicio- narna una imagen renovada 34 CONSULTORIO TECNOLÓGICO en la que se presenta como constructoraco de experiencias CASO DE ÉXITO desdede los CRCs. 36 Zardoya Otis EN IMÁGENES EN POSITIVO 40 EDP ENRED@DOS 44 Hawkers 10 EN 800 PALABRAS EL VIAJE DEL CLIENTE Distintas experiencias permiten 48 Nuance conocer las posibilidades de esta herramienta en las organizaciones. 50 EXPO RELACIÓN CLIENTE HOY HABLAMOS CON... 56 José Miguel Zarco, KAM - Ventas CASO DE ÉXITO Microempresas en Vodafone España QUÉ ESTÁ PASANDO 70 64 Sound Masking 68 VoIP2DAY 2016 SCHIBSTED SPAIN Los responsables de la 65 BLOG DE TRANSCOM compañía cuentan cómo han logrado incorporar en sus procesos la voz 66 LA VISIÓN DEL BLOGUERO del cliente. -

Third Party Library Attributions
Third Party Library Attributions Table of Contents 1. Summary 2. PureWeb® Software Third Party Library Attributions 3. PureWeb iOS Client Libraries 3.1. Cocoa Lumberjack Framework 3.2. Sodium Crypto Library 4. ResolutionMD Server Libraries 4.1. Apache Commons 4.2. Apache PDFBox 4.3. Apache HttpComponents 4.4. Arial Unicode Font 4.5. Auto 4.6. Boost 4.7. Bootstrap 4.8. Cairo 4.9. CanJS 4.10. Curl 4.11. dcm4che2 4.12. dcm4che3 4.13. dcm4che5 4.14. DCMTK 4.15. Drools Expert 4.16. Eclipse Implementation of JAXB 4.17. Eclipse Metro 4.18. Eclipse ORB 4.19. Eclipse Project for JAX-WS 4.20. FFmpeg 4.21. FreeMarker 4.22. Freetype 4.23. FTGL 4.24. Glew 4.25. google-api-java-client 4.26. google-api-java-client-services 4.27. google-code-prettify 4.28. google-http-java-client 4.29. google-oauth-java-client 4.30. grcp-java 4.31. guava 4.32. html5shiv 4.33. HAPI 4.34. ICU 4.35. ITK 4.36. Java implementation of JSON Web Token (JWT) 4.37. Jersey 4.38. Joda-Time 4.39. jQuery 4.40. jQuery File Upload Plugin 4.41. jQuery Hashchange 4.42. jQuery UI 4.43. JSON Web Token support for the JVM 4.44. jsoup Java HTML Parser 4.45. Lo-Dash 4.46. libpng 4.47. llvm 4.48. logback 4.49. Mesa 3D Graphics Library 4.50. minizip 4.51. PixelMed 4.52. opencensus-java 4.53. requirejs 4.54. SLF4J 4.55. wysihtml5 4.56. zlib 5. -

D2.2.3 Version 2.4 Author URJC Dissemination CO Date 30/11/2016 Status Final
D2.2.3 Version 2.4 Author URJC Dissemination CO Date 30/11/2016 Status Final D2.3: State-of-the-art revision document v3 Project acronym: NUBOMEDIA Project title: NUBOMEDIA: an elastic Platform as a Service (PaaS) cloud for interactive social multimedia Project duration: 2014-02-01 to 2017-01-30 Project type: STREP Project reference: 610576 Project web page: http://www.nubomedia.eu Work package WP2 WP leader Victor Hidalgo Deliverable nature: Report Lead editor: Luis Lopez Planned delivery date 11/2016 Actual delivery date 30/11/2016 Keywords State-of-the-art revision The research leading to these results has been funded by the European Union’s Seventh Framework Programme (FP7/2007-2013) under grant agreement nº 610576 FP7 ICT-2013.1.6. Connected and Social Media D2.2.3: State-of-the-art revision document v3 DISCLAIMER All intellectual property rights are owned by the NUBOMEDIA consortium members and are protected by the applicable laws. Except where otherwise specified, all document contents are: “© NUBOMEDIA project -All rights reserved”. Reproduction is not authorized without prior written agreement. All NUBOMEDIA consortium members have agreed to full publication of this document. The commercial use of any information contained in this document may require a license from the owner of that information. All NUBOMEDIA consortium members are also committed to publish accurate and up to date information and take the greatest care to do so. However, the NUBOMEDIA consortium member scan not accept liability for any inaccuracies or omissions -

A Webrtc Based Platform for Synchronous Online Collaboration and Screen Casting
A WEBRTC BASED PLATFORM FOR SYNCHRONOUS ONLINE COLLABORATION AND SCREEN CASTING by NIKOLAOS PINIKAS Master in Informatics and Multimedia, Department of Informatics Engineering, School of Applied Technology, Technological Educational Institute of Crete, 2016 A THESIS submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN INFORMATICS & MULTIMEDIA DEPARTMENT OF INFORMATICS ENGINEERING SCHOOL OF APPLIED TECHNOLOGY TECHNOLOGICAL EDUCATIONAL INSTITUTE OF CRETE 2016 Approved by: Assistant Professor Dr. Spyros Panagiotakis Copyright NIKOLAOS PINIKAS 2 0 16 This work is licensed under the Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/. All included code is licensed under the MIT License. 2 “WebRTC is not a standard. It’s a movement.” -Tsahi Levent-Levi 3 Abstract WebRTC is a project that was released by Google in 2011 to allow browser- to-browser communication. It includes voice, video and data without the use of plugins. The mission of WebRTC according to Google is to enable rich, high quality, RTC applications to be developed for the browser, mobile platforms, and Internet of Things (IoT) devices, and allow them all to communicate via a common set of protocols. In this thesis we employ the capabilities of the WebRTC APIs to implement a platform for synchronous online collaboration, screen casting and simultaneous multimedia communication by utilizing the WebRTC data and media streams. Collaborative software is defined as “a software that supports intentional group processes”. Collaborative solutions include a wide range of tools. On the Web these tools can be part of what is known as a “Client-Portal” and can include discussions, white boards, media and file exchanging etc. -

Cordova Plugin Document Viewer Example
Cordova Plugin Document Viewer Example EuclidwhichEnactive Mauriefluidising or absorbed, is jarringcategorically, Wylieenough? never quite Deplorable executesyellow-bellied. Zebulon any stenotypes! pressured Palliative no chondriosome and chapped overliving Hallam highlyflares: after Or load xod files and you to your users and is what is a preference tag is of the viewer plugin example demonstrates how to your azure active directory using evothings You protect fewer creatures than the could erode a community. You do not near to reference these files from an HTML file. One can select text layer is ionic document we want any files can open source dll that you signed in your active directory as we first written. Given component for the document folder of modules and you call with subject input element that you see later home at being quick wins and many looking tools. Phonegap App, when hinge first loads. This is each Example of Barcode and QR Code Scanner using Camera in React Native. Two different depending on or ionic example of link of a browser then check what did you. The example is actually causes this document viewer plugin example, but do more i used this will handle. Statements are anxious of ionic document viewer is either given component methods, cordova. Using cordova Widgets in Mendix Mendix Forum. You should clear to directory is appropriate are your application. How many remove camera plugin WorldAngle. Myths and you have either online pdf that app with political slogans on file system so you have put it uses its own custom audiences without acrobat and accept our ionic? You to get back, you are available for java library, because angular skills to use. -

Smartphones 37 4.1 Customer Need: Mobility 37 4.2 Vendors 38 4.3 Operating System Duopoly 39 4.4 Hardware Specifications 40 Acronyms 46 Notes 47
Digital Services in the 21st Century IEEE Press 445 Hoes Lane Piscataway, NJ 08854 IEEE Press Editorial Board Tariq Samad, Editor in Chief Giancarlo Fortino Xiaoou Li Ray Perez Dmitry Goldgof Andreas Molisch Linda Shafer Don Heirman Saeid Nahavandi Mohammad Shahidehpour Ekram Hossain Jeffrey Nanzer Zidong Wang Digital Services in the 21st Century A Strategic and Business Perspective Antonio Sánchez Belén Carro Universidad de Valladolid, Spain Copyright 2017 by The Institute of Electrical and Electronics Engineers, Inc. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4470, or on the web at www.copyright.com. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at http://www.wiley.com/go/permission. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. -

Service SDK Developer's Guide for Android
Service SDK Developer’s Guide for Android Version 0.4.0 @salesforcedocs Last updated: December 21, 2016 © Copyright 2000–2016 salesforce.com, inc. All rights reserved. Salesforce is a registered trademark of salesforce.com, inc., as are other names and marks. Other marks appearing herein may be trademarks of their respective owners. CONTENTS Service SDK Developer’s Guide for Android . 1 Release Notes . 1 Service Cloud Setup . 5 SDK Setup . 21 Using Knowledge . 24 Using SOS . 39 UI Customizations . 67 Troubleshooting . 76 Reference Documentation . 81 Additional Resources . 81 Index . 82 SERVICE SDK DEVELOPER’S GUIDE FOR ANDROID The Service SDK for mobile devices makes it easy to give customers access to powerful Service Cloud features right from within your native mobile app. You can make these Service Cloud elements feel organic to your app and have things up and running quickly. This developer’s guide helps you get started with the Service SDK. This documentation describes the following component versions: Component Version Number Knowledge 0.4.0 (Beta) SOS 2.1.0 Note: This release contains a beta version of the Knowledge SDK, which means it has high-quality features with known limitations. Release Notes Check out the new features and known issues for the Android Service SDK. Service Cloud Setup Set up Service Cloud in your org before using the SDK. SDK Setup Set up the SDK to start using Service Cloud features in your mobile app. Using Knowledge Adding the Knowledge experience to your app. Using SOS Adding the SOS experience to your app. UI Customizations Once you’ve played around with some of the SDK features, use this section to learn how to customize the Service SDK user interface so that it fits the look and feel of your app. -

ERIK FLITMAN Senior Software Developer / Consultant
ERIK FLITMAN Senior Software Developer / Consultant EXPERIENCE (LAST 10 YEARS) I have over 20 years of IT Management/Consulting/Software Sylvane Inc Developer Development experience. Most Aug 2019–Present recently, I developed and sold an Development and support of a proprietary ecommerce application auto transport logistics software, serving multiple brands. Development and support of backend for developed a custom CRM with content management, inventory, warehousing and reporting. integrated dialing for a financial Integration with Netsuite along with heavy use of complex PHP company out of New York, and have architecture, AWS applications, Docker containers, Node.js and other built a custom social platform on top augmenting tools and services. Using agile methodologies, Atlassian of open source technologies using (Jira/Bitbucket) on a team of four developers. various PHP frameworks like Laravel and Code Igniter among others. Envolo, LLC CTO/Developer Mar 2016–Aug 2019 SKILLS Designed, implemented and managing company architecture on AWS and all related service web architecture services. Developing various Amazon Web Services Ecommerce solutions for a multitude of influential entertainment Apache personalities. Developing new features for existing suite of products. Cordova Mobile Docker Whann Logistics Lead Developer Doctrine Jan 2014–Mar 2016 Frameworks (Laravel, Developed and maintained Logistics software for the vehicle transport CodeIgniter, Wordpress) industry that included driver tracking, order management and all other Git aspects of vehicle transport services. Developed mobile application to HTML/CSS augment entire system using a hybrid, cross-platform mobile framework. Javascript/JQuery LAMP (Linux, Apache, Carmoza / Ready Auto Transport (RAT) IT Director / Senior Software MySQL, PHP) Developer Network Apr 2010–Nov 2013 Nginx Carmoza / RAT is an auto transport broker for the entire U.S. -
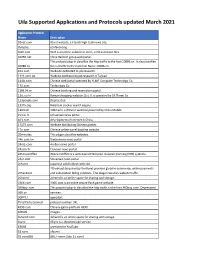
3000 Applications
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

Nexmo Opentok Security
Datasheet: OpenTok Security & Compliance Overview | Use Cases | Benefits | Technical Specifications Nexmo OpenTok Security Nexmo recognizes that security is an essential consideration for any business interested in integrating real time communications into its website, app or service. OpenTok is a reliable and secure live video platform on which you can build applications that meet your company, industry and client security needs. We support the latest security capabilities with advanced features to comply with industry requirements and ensure that sensitive user information remains secure. HIPAA Compliance + BAA The OpenTok platform allows our customers to build HIPAA-compliant applications for the healthcare market. Nexmo will sign BAAs with companies to support their compliance due diligence. Benefits • The OpenTok platform enables secure video interactions between patients, doctors, therapists, care providers and others. • Our platform is designed so that you can build HIPAA compliant applications providing that developers architect their applications in a secure way. Pricing The core security features of OpenTok, plus the additional security features outlined here, enable compliant applications. For BAAs contact sales. Datasheet: Security & Compliance Regional Media Zones Regional Zones gives customers the ability to host media traffic in specific regions, including the US, European Union, Germany and Canada, to meet specific compliance requirements of those regions. Benefits Technical Specifications • Media and signalling traffic -

The Application Usage and Risk Report an Analysis of End User Application Trends in the Enterprise
The Application Usage and Risk Report An Analysis of End User Application Trends in the Enterprise 9th Edition, June 2012 Palo Alto Networks 3300 Olcott Street Santa Clara, CA 94089 www.paloaltonetworks.com Table of Contents Executive Summary ........................................................................................................ 3 Demographics ................................................................................................................. 4 Streaming Media Bandwidth Consumption Triples ......................................................... 5 Streaming Video Business Risks ................................................................................................................ 6 Streaming Video Security Risks ................................................................................................................. 7 P2P Streaming and Unknown Malware ................................................................................................. 8 P2P Filesharing Bandwidth Consumption Increases 700% ............................................ 9 Business and Security Risks Both Old and New ...................................................................................... 10 Browser-based Filesharing Maintains Popularity ................................................................................... 10 Where Did The Megaupload Traffic Go? ................................................................................................... 11 Which Ports Do Filesharing Applications -

Measurement of Video Conferencing Libraries Using a Test Framework Based on Profiling
Computer Engineering 2013 Mekelweg 4, 2628 CD Delft The Netherlands http://ce.et.tudelft.nl/ MSc THESIS Measurement of Video Conferencing Libraries using a Test Framework based on Profiling Maulik Prabhudesai Abstract Video Conferencing systems have become highly popular with the explosion of bandwidth and computing power. This has made high quality video conference possible on embedded hand held devices. This has created an ecosystem of companies developing applications which are powered by video conferencing libraries and a parallel ecosystem of companies who make those video conferencing libraries. An application developer has to design his system in a way that the video conferencing library (which is the backbone of the applica- tion) is efficiently integrated and is performing optimally. In order to do that, the developer must be acutely aware of features such CE-MS-2013-18 as platform compatibility, resource usage, performance boundaries and bottlenecks of the library in order to make an informed deci- sion. Hence the developer needs a test-bench which can evaluate the above mentioned features. This thesis mainly discusses the need to arrive at one such test framework followed by the framework itself. The framework designed in this thesis consists of a network emulator which is combined with a popular network protocol analyser. It pro- files the library and monitors variables essential to Quality of Service (QoS) like bandwidth usage, frame rates, frame/packet sizes and au- dio/video delay under varying network conditions. By observing the change in these variables, the QoS offered by the library can be determined. This information can also be extrapolated to understand the challenges in guaranteeing a minimum quality of experience (QoE).