Rui Abreu De Carvalho Ferreira Segurança E Privacidade Em
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -
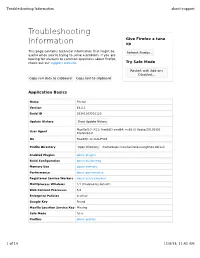
Troubleshooting Information About:Support
Troubleshooting Information about:support Troubleshooting Give Firefox a tune Information up This page contains technical information that might be Refresh Firefox… useful when you’re trying to solve a problem. If you are looking for answers to common questions about Firefox, check out our support website. Try Safe Mode Restart with Add-ons Disabled… Copy raw data to clipboard Copy text to clipboard Application Basics Name Firefox Version 63.0.1 Build ID 20181103201123 Update History Show Update History Mozilla/5.0 (X11; FreeBSD amd64; rv:63.0) Gecko/20100101 User Agent Firefox/63.0 OS FreeBSD 12.0-ALPHA9 Profile Directory Open Directory /home/bapt/.mozilla/firefox/usrg8h44.default Enabled Plugins about:plugins Build Configuration about:buildconfig Memory Use about:memory Performance about:performance Registered Service Workers about:serviceworkers Multiprocess Windows 1/1 (Enabled by default) Web Content Processes 5/4 Enterprise Policies Inactive Google Key Found Mozilla Location Service Key Missing Safe Mode false Profiles about:profiles 1 of 14 11/8/18, 11:42 AM Troubleshooting Information about:support Firefox Features Name Version ID Application Update Service Helper 2.0 [email protected] Firefox Screenshots 33.0.0 [email protected] Form Autofill 1.0 formautofi[email protected] Photon onboarding 1.0 [email protected] Pocket 1.0.5 fi[email protected] Web Compat 2.0.1 [email protected] WebCompat Reporter 1.0.0 [email protected] Extensions Name Version Enabled ID uBlock Origin 1.17.2 true [email protected] -

Latest Code, You’Ll Need to Update Other Things
Ichnaea Release 2.0 unknown Jul 09, 2021 CONTENTS 1 Table of contents 3 1.1 User documentation...........................................3 1.2 Development/Deployment documentation................................ 20 1.3 Algorithms................................................ 69 1.4 Changelog................................................ 80 1.5 Glossary................................................. 108 2 Indices 111 3 Source code and license 113 4 About the name 115 Index 117 i ii Ichnaea, Release 2.0 Ichnaea is a service to provide geolocation coordinates from other sources of data (Bluetooth, cell or WiFi networks, GeoIP, etc.). It uses both Cell-ID and Wi-Fi based positioning (WPS) approaches. Mozilla hosts an instance of this service, called the Mozilla Location Service( MLS). You can interact with the service in two ways: • If you know where you are, submit information about the radio environment to the service to increase its quality. • or locate yourself, based on the radio environment around you. CONTENTS 1 Ichnaea, Release 2.0 2 CONTENTS CHAPTER ONE TABLE OF CONTENTS 1.1 User documentation This section covers information for using the APIs directly as well as through applications and libraries. 1.1.1 Services API The service APIs accept data submission for geolocation stumbling as well as reporting a location based on IP ad- dresses, cell, or WiFi networks. New client developments should use the Region: /v1/country, Geolocate: /v1/geolocate, or Geosubmit Version 2: /v2/geosubmit APIs. Requesting an API Key The api key has a set daily usage limit of about 100,000 requests. As we aren’t offering a commercial service, please note that we do not make any guarantees about the accuracy of the results or the availability of the service. -

Collecting and Processing Geographic Coverage Information of Mobile
Collecting and processing geographic coverage information of mobile networks José Miguel de Carvalho Branco Maia Mestrado Integrado de Engenharia de Redes e Sistemas Informáticos Departamento de Ciência de Computadores 2015 Orientador Sérgio Crisóstomo, Professor Auxiliar, Faculdade de Ciências da Universidade do Porto Coorientador Rui Prior, Professor Auxiliar, Faculdade de Ciências da Universidade do Porto Todas as correções determinadas pelo júri, e só essas, foram efetuadas. O Presidente do Júri, Porto, ______/______/_________ Thanks to all my friends throughout all these years who have done their part to make me who I am. Thanks to my family, for always being there. Thanks to my supervisors, Professor Rui Prior and Professor Sérgio Crisóstomo, for giving me the opportunity to work with them and to learn from them. Obrigado, Muchas gracias, Merci Bien, Tudo é Kanimambo (João Maria Tudela) i ii Abstract Over the last two decades, we have seen an exponential growth in the use of mobile phones. This growth was accompanied by a change in their usage pattern — the access to data services has overtaken voice calling, which was the almost exclusive use of mobile phones. It was also accompanied by a change in the devices themselves, with the market shifting to smartphones. The selection of a mobile service provider can be difficult for the end users, given the lack of unambiguous, accurate and independent information on coverage and quality of the wireless access, including voice and data, with every provider claiming their particular signal quality, network speed and/or pricing is the best. This motivated us to develop a service for measuring mobile network parameters using Android smartphones, and display the data, adequately processed, to the users in a mapping application. -

Comments from the FUTURE of PRIVACY FORUM to FEDERAL
Comments from THE FUTURE OF PRIVACY FORUM to FEDERAL COMMUNICATIONS COMMISSION Washington, D.C. 20554 WC Docket No. 16-106: Protecting the Privacy of Customers of Broadband and Other Telecommunications Services Jules Polonetsky, CEO John Verdi, Vice President of Policy Stacey Gray, Legal & Policy Fellow THE FUTURE OF PRIVACY FORUM*† May 27, 2016 1400 I St. NW Ste. 450 Washington, DC 20005 www.fpf.org * The Future of Privacy Forum (FPF) is a Washington, DC based think tank that seeks to advance responsible data practices by promoting privacy thought leadership and building consensus among privacy advocates, industry leaders, regulators, legislators and international representatives. † The views herein do not necessarily reflect those of our members or our Advisory Board. Table of Contents Executive Summary .......................................................................................................................1 I. Data Exists on a Spectrum of Identifiability ............................................................................3 Pseudonymous Data .....................................................................................................................4 Not Readily Identifiable Data ......................................................................................................5 Techniques for Practical De-Identification ..................................................................................6 II. Explanation of the Market .......................................................................................................8 -

TII Internet Intelligence Newsletter - November 2013 Edition
TII Internet Intelligence Newsletter - November 2013 Edition http://us7.campaign-archive1.com/?u=1e8eea4e4724fcca7714ef623... “The success of every one of our customers is our priority and we work diligently to produce and maintain the very best training materials in a format that is effective, enjoyable, interesting and easily understood.” Julie Clegg, President Toddington International Inc. TII Logo Toddington International Inc. Online Open Source Intelligence Newsletter NOVEMBER 2013 EDITION IN THIS EDITION: TOR TAILS: ONLINE ANONYMITY AND SECURITY TAKEN TO THE NEXT LEVEL FINDING UNKNOWN FACEBOOK AND TWITTER ACCOUNTS WITH KNOWN EMAIL ADDRESSES AND MOBILE PHONE NUMBERS SUGGESTING A NEW MONEY LAUNDERING MODEL USEFUL SITES AND RESOURCES FOR ONLINE INVESTIGATORS ...ALSO OF INTEREST WELCOME TO THE NOVEMBER EDITION OF THE TII ONLINE RESEARCH AND INTELLIGENCE NEWSLETTER This month we are pleased to bring you articles by guest authors Allan Rush and Mike Ryan as well as our regular listings of Research Resources and articles of interest to the Open Source Intelligence professional. The last 6 weeks have been busy with open and bespoke courses being delivered to private and public sector clients in North America, Europe and Asia. We’ve been seeing an increase in enrollment on our Using the Internet as an Investigative Research Tool™ and the Introduction to Intelligence Analysis e-Learning programs, and interest in our new courses relating to Financial Crime, Online Security and OSINT Project Management has been high, with clients now booking in-house training courses in these subject areas. We’re pleased to be speaking at a number of conferences this next few weeks including the 7th Annual HTCIA Asia Pacific Training Conference running December 2nd - 4th in Hong Kong and the Breaking the Silence: A Violence Against Women Prevention and Response Symposium hosted by the Ending Violence Association of British Columbia, November 27th - 29th in Richmond, BC. -

Practical Linux Forensics by Bruce Nikkel! As a Prepublication Title, This Book May Be Incom- Plete and Some Chapters May Not Have Been Proofread
P R A C T I C A L LINUX FORENSICS A GUIDE FOR DIGITAL INVESTIGATORS BRUCE NIKKEL EARLY ACCESS NO STARCH PRESS EARLY ACCESS PROGRAM: FEEDBACK WELCOME! Welcome to the Early Access edition of the as yet unpublished Practical Linux Forensics by Bruce Nikkel! As a prepublication title, this book may be incom- plete and some chapters may not have been proofread. Our goal is always to make the best books possible, and we look forward to hearing your thoughts. If you have any comments or questions, email us at [email protected]. If you have specific feedback for us, please include the page number, book title, and edition date in your note, and we’ll be sure to review it. We appreciate your help and support! We’ll email you as new chapters become available. In the meantime, enjoy! PR CA T IC A L L INU X FOR E N SI C S BRUCE N IK KE L Early Access edition, 6/18/21 Copyright © 2021 by Bruce Nikkel. ISBN-13: 978-1-7185-0196-6 (print) ISBN-13: 978-1-7185-0197-3 (ebook) Publisher: William Pollock Production Manager: Rachel Monaghan Production Editor: Miles Bond Developmental Editor: Jill Franklin Cover Illustrator: James L. Barry Technical Reviewer: Don Frick Copyeditor: George Hale No Starch Press and the No Starch Press logo are registered trademarks of No Starch Press, Inc. Other product and company names mentioned herein may be the trademarks of their respective owners. Rather than use a trademark symbol with every occurrence of a trade- marked name, we are using the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. -

Mozilla Teams up with Combain to Improve Geolocation
2015-02-28 17:31 CET Mozilla Teams up with Combain to Improve Geolocation Combain Mobile AB, a leader in accurate Cell ID and WiFi positioning, is excited to announce a partnership with Mozilla, the mission-based organization dedicated to promoting openness, innovation and opportunity on the Web. Combain will provide fallback services for Mozilla's Location Service, allowing them to send location queries that don't meet an acceptable level of accuracy to Combain for further refinement. Additionally, the two companies will exchange data gathered from their community stumbling efforts. "We are excited to work with Mozilla and provide world class coverage and accuracy for Mozilla's Location Service" said Bjorn Lindquist, CEO Combain Mobile. "With Mozilla's data and our new positioning algorithms, we will be able to further improve Combain Positioning Service (CPS), which in turn will benefit all Firefox and Firefox OS users globally." Mozilla launched its Mozilla Location Service in 2013, and has been growing its map of the world through the stumbling efforts of a community of volunteers and through data exchange partnerships. Volunteers interested in contributing to the effort to improve Mozilla Location Service are encouraged to turn on geolocation stumbling in their Firefox for Android browser, or install the Mozilla Stumbler app from the Play Store. "This deal is a perfect alignment with Mozilla's goals - to grow a community database that will enable companies like Combain to focus on leveraging their algorithmic work for superior results" said Mark Mayo, Mozilla VP for Cloud Services. "Meanwhile, Combain helps us provide a better geolocation service." Mozilla Location Service enables today geolocation across desktop and mobile devices. -

The Socioeconomic Impact of Internet Tracking
The Socioeconomic Impact of Internet Tracking February 2020 Acknowledgments John Deighton is the Harold M. Brierley Professor of Business Administration, Harvard Business School, Soldiers Field Road, Boston MA 02163. Leora Kornfeld is Principal Research Consultant, Deighton Associates. © 2020 John Deighton, Leora Kornfeld. Published by the authors February 2020, pursuant to an agreement with the Interactive Advertising Bureau, 116 East 27th Street, 7th Floor, New York, New York 10016, which commissioned the work. THE SOCIOECONOMIC IMPACT OF INTERNET TRACKING 1 Table of Contents Introduction ....................................................................................3 Key Findings ...................................................................................4 How Tracking Affects a Web User’s Experience .....................................................5 How Tracking Affects the Economy of the Internet ..................................................8 Defining the Tracking Cookie and Related Devices ..................................................9 First and Third-Party Cookies ................................................................9 Processes That Substitute for or Complement Cookies .........................................10 Functions of Tracking ......................................................................... 11 Tracking’s Role in Programmatic Advertising ..................................................... 13 The Open Web and Walled Gardens ............................................................ -

Univerzita Hradec Králové
Univerzita Hradec Králové Fakulta informatiky a managementu Katedra informačních technologií Studijní program: Aplikovaná informatika Agregace lokálních informací v cestovním ruchu prostřednictvím geosociálních sítí (disertační práce) Autor: Ing. Jiří Kysela Školitel: prof. RNDr. Josef Zelenka, CSc. Pardubice březen 2016 Poděkování Rád bych touto cestou poděkoval svému školiteli doktorského studia prof. RNDr. Josefu Zelenkovi, CSc. za připomínky, rady a vedení při této práci. Obrovské díky patří i mé partnerce za podporu a velkou pomoc jak při psaní disertační práce, tak i po celou dobu studia a také mé dcerce za každodenní dodávání optimismu. Děkuji i mým rodičům a sestře za trvalou podporu při práci na disertaci. Prohlášení Prohlašuji, že jsem disertační práci zpracoval samostatně a uvedl všechny použité prameny a literaturu, ze kterých jsem čerpal. V Pardubicích 30.3. 2016 Jiří Kysela Anotace Disertační práce se zabývá analýzou možností využití agregace a harmonizace informací z odlišně strukturovaných lokálně kontextových služeb v cestovním ruchu. Jde o rozličné geosociální sítě, poskytující uživatelům lokální informace, jež jsou výsledkem kognice tzv. bodů zájmu v okolí dalších uživatelů. Míra pokrytí podniků v cestovním ruchu těmito body zájmu je analyzována v disertační práci a poté kvantifikována míra navýšení pokrytí při agregaci a harmonizaci geosociálních sítí. Její realizace umožní účastníkům cestovního ruchu kdekoliv v terénu prostřednictvím jednotného informačního zdroje maximalizovat zisk informací. Ty jsou vztažené k místu, kde se právě nachází, tedy k místním subjektům či kulturním akcím, a na jejich základě se může turista kdykoliv a kdekoliv pohotově zorientovat v cestovním ruchu. Práce zahrnuje i koncept aplikace lokálně kontextových služeb pro podporu e-turismu zvýšením úrovně informovanosti účastníků lokálního cestovního ruchu a ve výsledku zlepšením nabídky produktů pro účastníka místního cestovního ruchu. -
Application Basics
Application Basics Name Firefox Version 68.0b11 Build ID 20190617172838 Update Channel beta Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) User Agent Gecko/20100101 Firefox/68.0 OS Windows_NT 10.0 Launcher Process Enabled Multiprocess Windows 1/1 Enabled by default Remote Processes 3 Enterprise Policies Inactive Google Location Service Found Key Google Safebrowsing Found Key Mozilla Location Service Found Key Safe Mode true Crash Reports for the Last 3 Days Report ID Submitted Firefox Features Name Version ID Firefox Monitor 3.0 [email protected] Firefox Screenshots 39.0.0 [email protected] Form Autofill 1.0 [email protected] Web Compat 4.2.0 [email protected] WebCompat Reporter 1.1.0 [email protected] Remote Processes Type Count Web Content 2 / 8 Extension 1 Extensions Enabl Name Version ID ed Amazon.d 1.1 true [email protected] e Bing 1.0 true [email protected] DuckDuck 1.0 true [email protected] Go eBay 1.0 true [email protected] Ecosia 1.0 true [email protected] Google 1.0 true [email protected] LEO Eng- 1.0 true [email protected] Deu Wikipedia 1.0 true [email protected] (de) AdBlock 3.30.0 false jid1-NIfFY2CA8fy1tg@jetpack AdBlocker 2.37 false [email protected] Ultimate AdGuard Werbebloc 3.1.3 false [email protected] ker Adobe 18.0.10 false [email protected] Acrobat APKFtech APK 1.3 false [email protected] Download er EPUBRea 2.0.8 false {5384767E-00D9-40E9-B72F-9CC39D655D6F} der -
Welcome to Arvig's Webmail User Guide
Welcome to Arvig’s Webmail User Guide This guide is divided into main subject headings where you will find support and articles such as: how to log in to Webmail, choosing a strong password, composing an email and creating folders in Arvig Webmail. What is Webmail? Webmail is an email service for Arvig customers. You can enjoy a personalized, secure and reliable email experience with a 99.99% performance rating, and it’s easy to use! Mailboxes are protected by an antivirus and spam protection policy which prevents malicious emails from reaching your inbox. You can access your email anywhere in the world through an internet browser on your desktop, laptop, tablet or smartphone. Email Account All email addresses include 1GB of storage, premium anti-spam filtering, premium malware detection, maximum file attachment size of 25MB, and improved Webmail service with calendar, tasks and auto forwarding. More storage is available for an additional small, monthly fee. Email accounts are removed if they have not been used for 180 days or more. See Arvig’s Acceptable Use Policy in the footer of arvig.net for details. If you would like to add an email account and are already an Arvig customer, email [email protected] or chat with us online at arvig.net. If you don’t have Arvig internet service, sign up online at arvig.com or call 888.992.7844. Arvig Webmail Guide Table of Contents Getting Started ...................................................................................................................................................................