TII Internet Intelligence Newsletter - November 2013 Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evaluating Exploratory Search Engines : Designing a Set of User-Centered Methods Based on a Modeling of the Exploratory Search Process Emilie Palagi
Evaluating exploratory search engines : designing a set of user-centered methods based on a modeling of the exploratory search process Emilie Palagi To cite this version: Emilie Palagi. Evaluating exploratory search engines : designing a set of user-centered methods based on a modeling of the exploratory search process. Human-Computer Interaction [cs.HC]. Université Côte d’Azur, 2018. English. NNT : 2018AZUR4116. tel-01976017v3 HAL Id: tel-01976017 https://tel.archives-ouvertes.fr/tel-01976017v3 Submitted on 20 Feb 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. THÈSE DE DOCTORAT Evaluation des moteurs de recherche exploratoire : Elaboration d'un corps de méthodes centrées utilisateurs, basées sur une modélisation du processus de recherche exploratoire Emilie PALAGI Wimmics (Inria, I3S) et Data Science (EURECOM) Présentée en vue de l’obtention Devant le jury, composé de : du grade de docteur en Informatique Christian Bastien, Professeur, Université de Loraine d’Université Côte d’Azur Pierre De Loor, Professeur, ENIB Dirigée par : Fabien Gandon -

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -

Final Study Report on CEF Automated Translation Value Proposition in the Context of the European LT Market/Ecosystem
Final study report on CEF Automated Translation value proposition in the context of the European LT market/ecosystem FINAL REPORT A study prepared for the European Commission DG Communications Networks, Content & Technology by: Digital Single Market CEF AT value proposition in the context of the European LT market/ecosystem Final Study Report This study was carried out for the European Commission by Luc MEERTENS 2 Khalid CHOUKRI Stefania AGUZZI Andrejs VASILJEVS Internal identification Contract number: 2017/S 108-216374 SMART number: 2016/0103 DISCLAIMER By the European Commission, Directorate-General of Communications Networks, Content & Technology. The information and views set out in this publication are those of the author(s) and do not necessarily reflect the official opinion of the Commission. The Commission does not guarantee the accuracy of the data included in this study. Neither the Commission nor any person acting on the Commission’s behalf may be held responsible for the use which may be made of the information contained therein. ISBN 978-92-76-00783-8 doi: 10.2759/142151 © European Union, 2019. All rights reserved. Certain parts are licensed under conditions to the EU. Reproduction is authorised provided the source is acknowledged. 2 CEF AT value proposition in the context of the European LT market/ecosystem Final Study Report CONTENTS Table of figures ................................................................................................................................................ 7 List of tables .................................................................................................................................................. -
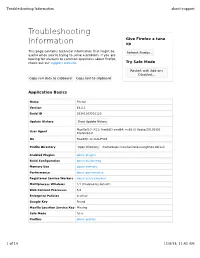
Troubleshooting Information About:Support
Troubleshooting Information about:support Troubleshooting Give Firefox a tune Information up This page contains technical information that might be Refresh Firefox… useful when you’re trying to solve a problem. If you are looking for answers to common questions about Firefox, check out our support website. Try Safe Mode Restart with Add-ons Disabled… Copy raw data to clipboard Copy text to clipboard Application Basics Name Firefox Version 63.0.1 Build ID 20181103201123 Update History Show Update History Mozilla/5.0 (X11; FreeBSD amd64; rv:63.0) Gecko/20100101 User Agent Firefox/63.0 OS FreeBSD 12.0-ALPHA9 Profile Directory Open Directory /home/bapt/.mozilla/firefox/usrg8h44.default Enabled Plugins about:plugins Build Configuration about:buildconfig Memory Use about:memory Performance about:performance Registered Service Workers about:serviceworkers Multiprocess Windows 1/1 (Enabled by default) Web Content Processes 5/4 Enterprise Policies Inactive Google Key Found Mozilla Location Service Key Missing Safe Mode false Profiles about:profiles 1 of 14 11/8/18, 11:42 AM Troubleshooting Information about:support Firefox Features Name Version ID Application Update Service Helper 2.0 [email protected] Firefox Screenshots 33.0.0 [email protected] Form Autofill 1.0 formautofi[email protected] Photon onboarding 1.0 [email protected] Pocket 1.0.5 fi[email protected] Web Compat 2.0.1 [email protected] WebCompat Reporter 1.0.0 [email protected] Extensions Name Version Enabled ID uBlock Origin 1.17.2 true [email protected] -

Latest Code, You’Ll Need to Update Other Things
Ichnaea Release 2.0 unknown Jul 09, 2021 CONTENTS 1 Table of contents 3 1.1 User documentation...........................................3 1.2 Development/Deployment documentation................................ 20 1.3 Algorithms................................................ 69 1.4 Changelog................................................ 80 1.5 Glossary................................................. 108 2 Indices 111 3 Source code and license 113 4 About the name 115 Index 117 i ii Ichnaea, Release 2.0 Ichnaea is a service to provide geolocation coordinates from other sources of data (Bluetooth, cell or WiFi networks, GeoIP, etc.). It uses both Cell-ID and Wi-Fi based positioning (WPS) approaches. Mozilla hosts an instance of this service, called the Mozilla Location Service( MLS). You can interact with the service in two ways: • If you know where you are, submit information about the radio environment to the service to increase its quality. • or locate yourself, based on the radio environment around you. CONTENTS 1 Ichnaea, Release 2.0 2 CONTENTS CHAPTER ONE TABLE OF CONTENTS 1.1 User documentation This section covers information for using the APIs directly as well as through applications and libraries. 1.1.1 Services API The service APIs accept data submission for geolocation stumbling as well as reporting a location based on IP ad- dresses, cell, or WiFi networks. New client developments should use the Region: /v1/country, Geolocate: /v1/geolocate, or Geosubmit Version 2: /v2/geosubmit APIs. Requesting an API Key The api key has a set daily usage limit of about 100,000 requests. As we aren’t offering a commercial service, please note that we do not make any guarantees about the accuracy of the results or the availability of the service. -

Collecting and Processing Geographic Coverage Information of Mobile
Collecting and processing geographic coverage information of mobile networks José Miguel de Carvalho Branco Maia Mestrado Integrado de Engenharia de Redes e Sistemas Informáticos Departamento de Ciência de Computadores 2015 Orientador Sérgio Crisóstomo, Professor Auxiliar, Faculdade de Ciências da Universidade do Porto Coorientador Rui Prior, Professor Auxiliar, Faculdade de Ciências da Universidade do Porto Todas as correções determinadas pelo júri, e só essas, foram efetuadas. O Presidente do Júri, Porto, ______/______/_________ Thanks to all my friends throughout all these years who have done their part to make me who I am. Thanks to my family, for always being there. Thanks to my supervisors, Professor Rui Prior and Professor Sérgio Crisóstomo, for giving me the opportunity to work with them and to learn from them. Obrigado, Muchas gracias, Merci Bien, Tudo é Kanimambo (João Maria Tudela) i ii Abstract Over the last two decades, we have seen an exponential growth in the use of mobile phones. This growth was accompanied by a change in their usage pattern — the access to data services has overtaken voice calling, which was the almost exclusive use of mobile phones. It was also accompanied by a change in the devices themselves, with the market shifting to smartphones. The selection of a mobile service provider can be difficult for the end users, given the lack of unambiguous, accurate and independent information on coverage and quality of the wireless access, including voice and data, with every provider claiming their particular signal quality, network speed and/or pricing is the best. This motivated us to develop a service for measuring mobile network parameters using Android smartphones, and display the data, adequately processed, to the users in a mapping application. -

Appendix I: Search Quality and Economies of Scale
Appendix I: search quality and economies of scale Introduction 1. This appendix presents some detailed evidence concerning how general search engines compete on quality. It also examines network effects, scale economies and other barriers to search engines competing effectively on quality and other dimensions of competition. 2. This appendix draws on academic literature, submissions and internal documents from market participants. Comparing quality across search engines 3. As set out in Chapter 3, the main way that search engines compete for consumers is through various dimensions of quality, including relevance of results, privacy and trust, and social purpose or rewards.1 Of these dimensions, the relevance of search results is generally considered to be the most important. 4. In this section, we present consumer research and other evidence regarding how search engines compare on the quality and relevance of search results. Evidence on quality from consumer research 5. We reviewed a range of consumer research produced or commissioned by Google or Bing, to understand how consumers perceive the quality of these and other search engines. The following evidence concerns consumers’ overall quality judgements and preferences for particular search engines: 6. Google submitted the results of its Information Satisfaction tests. Google’s Information Satisfaction tests are quality comparisons that it carries out in the normal course of its business. In these tests, human raters score unbranded search results from mobile devices for a random set of queries from Google’s search logs. • Google submitted the results of 98 tests from the US between 2017 and 2020. Google outscored Bing in each test; the gap stood at 8.1 percentage points in the most recent test and 7.3 percentage points on average over the period. -

The Digital Markets Act: European Precautionary Antitrust
The Digital Markets Act: European Precautionary Antitrust AURELIEN PORTUESE | MAY 2021 The European Commission has set out to ensure digital markets are “fair and contestable.” But in a paradigm shift for antitrust enforcement, its proposal would impose special regulations on a narrowly dened set of “gatekeepers.” Contrary to its intent, this will deter innovation—and hold back small and medium-sized rms—to the detriment of the economy. KEY TAKEAWAYS ▪ The Digital Markets Act (DMA) arbitrarily distinguishes digital from non-digital markets, even though digital distribution is just one of many ways rms reach end users. It should assess competition comprehensively instead of discriminating. ▪ The DMA’s nebulous concept of a digital “gatekeeper” entrenches large digital rms and discourages them from innovating to compete, and it creates a threshold effect for small and mid-sized rms, because it deters successful expansion. ▪ This represents a paradigm shift from ex post antitrust enforcement toward ex ante regulatory compliance—albeit for a narrowly selected set of companies—and a seminal victory for the precautionary principle over innovation. ▪ By distorting innovation incentives instead of enhancing them, the DMA’s model of “precautionary antitrust” threatens the vitality, dynamism, and competitive fairness of Europe’s economy to the detriment of consumers and rms of all sizes. ▪ Given its fundamental aws, the DMA can only be improved at the margins. The rst steps should be leveling the playing eld with reforms that apply to all rms, not just “digital” markets, and eliminating the nebulous “gatekeeper” concept. ▪ Authorities in charge of market-investigation rules need to be separated from antitrust enforcers; they need guidance and capacity for evidence-based fact-nding; and they should analyze competition issues dynamically, focusing on the long term. -

Written Statement for the Record by Megan Gray, General Counsel And
Written Statement for the Record by Megan Gray, General Counsel and Policy Advocate for DuckDuckGo for a hearing entitled "Online Platforms and Market Power, Part 2: Innovation and Entrepreneurship" before The House Judiciary Subcommittee on Antitrust, Commercial and Administrative Law Rep. David Cicilline, Chair Rep. James Sensenbrenner, Ranking Member Tuesday, July 16, 2019 DuckDuckGo is a privacy technology company that helps consumers stay more private online. DuckDuckGo has been competing in the U.S. search market for over a decade, and it is currently the 4th largest search engine in this market (see market share section below). From the vantage point of a company vigorously trying to compete, DuckDuckGo can hopefully provide useful background on the U.S. search market. Features of Competitive General Search Engines A competitive U.S. general search engine in 2019 must have a set of high-quality search features, and ensure none are substandard or shown at the wrong times. This set of mandatory high-quality search features includes: An up-to-date index of most all of the English web pages on the Internet (referred to as “organic links”) Maps Local business answers (e.g., restaurant addresses and phone numbers) News Images Videos Products/shopping Definitions Wikipedia reference Quick answers (calculator, conversions, etc.) Additional niche features may also be necessary to be competitive with particular consumer segments, such as: Up-to-date indexes of web pages in other languages Sports scores Airplane flight information Question/Answer reference (e.g., for computer programming) Lyrics When DuckDuckGo launched in 2008, this list was much smaller, and arguably just one item was a required feature: organic links (sometimes referred to as “the ten blue links”). -

Comments from the FUTURE of PRIVACY FORUM to FEDERAL
Comments from THE FUTURE OF PRIVACY FORUM to FEDERAL COMMUNICATIONS COMMISSION Washington, D.C. 20554 WC Docket No. 16-106: Protecting the Privacy of Customers of Broadband and Other Telecommunications Services Jules Polonetsky, CEO John Verdi, Vice President of Policy Stacey Gray, Legal & Policy Fellow THE FUTURE OF PRIVACY FORUM*† May 27, 2016 1400 I St. NW Ste. 450 Washington, DC 20005 www.fpf.org * The Future of Privacy Forum (FPF) is a Washington, DC based think tank that seeks to advance responsible data practices by promoting privacy thought leadership and building consensus among privacy advocates, industry leaders, regulators, legislators and international representatives. † The views herein do not necessarily reflect those of our members or our Advisory Board. Table of Contents Executive Summary .......................................................................................................................1 I. Data Exists on a Spectrum of Identifiability ............................................................................3 Pseudonymous Data .....................................................................................................................4 Not Readily Identifiable Data ......................................................................................................5 Techniques for Practical De-Identification ..................................................................................6 II. Explanation of the Market .......................................................................................................8 -

Evaluating the Suitability of Web Search Engines As Proxies for Knowledge Discovery from the Web
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 96 ( 2016 ) 169 – 178 20th International Conference on Knowledge Based and Intelligent Information and Engineering Systems, KES2016, 5-7 September 2016, York, United Kingdom Evaluating the suitability of Web search engines as proxies for knowledge discovery from the Web Laura Martínez-Sanahuja*, David Sánchez UNESCO Chair in Data Privacy, Department of Computer Engineering and Mathematics, Universitat Rovira i Virgili Av.Països Catalans, 26, 43007 Tarragona, Catalonia, Spain Abstract Many researchers use the Web search engines’ hit count as an estimator of the Web information distribution in a variety of knowledge-based (linguistic) tasks. Even though many studies have been conducted on the retrieval effectiveness of Web search engines for Web users, few of them have evaluated them as research tools. In this study we analyse the currently available search engines and evaluate the suitability and accuracy of the hit counts they provide as estimators of the frequency/probability of textual entities. From the results of this study, we identify the search engines best suited to be used in linguistic research. © 20162016 TheThe Authors. Authors. Published Published by by Elsevier Elsevier B.V. B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/). Peer-review under responsibility of KES International. Peer-review under responsibility of KES International Keywords: Web search engines; hit count; information distribution; knowledge discovery; semantic similarity; expert systems. 1. Introduction Expert and knowledge-based systems rely on data to build the knowledge models required to perform inferences or answer questions. -

OSINT Handbook September 2020
OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 Aleksandra Bielska Noa Rebecca Kurz, Yves Baumgartner, Vytenis Benetis 2 Foreword I am delighted to share with you the 2020 edition of the OSINT Tools and Resources Handbook. Once again, the Handbook has been revised and updated to reflect the evolution of this discipline, and the many strategic, operational and technical challenges OSINT practitioners have to grapple with. Given the speed of change on the web, some might question the wisdom of pulling together such a resource. What’s wrong with the Top 10 tools, or the Top 100? There are only so many resources one can bookmark after all. Such arguments are not without merit. My fear, however, is that they are also shortsighted. I offer four reasons why. To begin, a shortlist betrays the widening spectrum of OSINT practice. Whereas OSINT was once the preserve of analysts working in national security, it now embraces a growing class of professionals in fields as diverse as journalism, cybersecurity, investment research, crisis management and human rights. A limited toolkit can never satisfy all of these constituencies. Second, a good OSINT practitioner is someone who is comfortable working with different tools, sources and collection strategies. The temptation toward narrow specialisation in OSINT is one that has to be resisted. Why? Because no research task is ever as tidy as the customer’s requirements are likely to suggest. Third, is the inevitable realisation that good tool awareness is equivalent to good source awareness. Indeed, the right tool can determine whether you harvest the right information.