Residual Learning of Deep CNN for Image Denoising Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
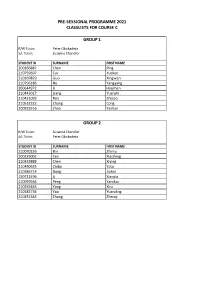
Classlists for C by Group
PRE-SESSIONAL PROGRAMME 2021 CLASSLISTS FOR COURSE C GROUP 1 R/W Tutor: Peter Obukadeta S/L Tutor: Suzanne Chandler STUDENT ID SURNAME FIRST NAME 200166887 Chen Ping 210759697 Cui Yuekun 210169829 Guo Xingwen 210796186 Hu Yangyang 200644972 Li Haozhan 210443017 Liang Yuanzhi 210421093 Ren Zhijiao 210532322 Zhang Cong 200925516 Zhao Yashan GROUP 2 R/W Tutor: Suzanne Chandler S/L Tutor: Peter Obukadeta STUDENT ID SURNAME FIRST NAME 210070226 Bin Zhimu 200329002 Cen Xiaofeng 210333888 Chen Xiying 210450635 Chiba Yota 210386714 Dong Jiahui 190711496 Li Xiaoxia 210059564 Peng Yanduo 210255465 Yang Xiru 210182736 Yao Yuanding 210252383 Zhang Zhenqi GROUP 3 R/W Tutor: Mark Heffernan S/L Tutor: Alan Hart STUDENT ID SURNAME FIRST NAME 210154386 Cai Zhenping 210462580 Ge Xiaodan 210648276 Hirunkhajonrote Kullanut 210182714 Huang Siwei 200141563 Kung Tzu-Ning 200305176 Punsri Punnatorn 200664774 Sayin Humeyra 210186446 Shehata Omar 171003323 Tutberidze Tea 200134624 Wang Shuo 200136019 Xu Ming 200278696 Yan Jiaxin 210357851 Yuan Lai 210029165 Zhang Anru 210219777 Zhang Jiasheng GROUP 4 R/W Tutor: Sherin White S/L Tutor: Alan Hart STUDENT ID SURNAME FIRST NAME 200247588 Chen Chong 200349343 Li Cheng 210622933 Liang Wenxuan 210219618 Liu Huiyuan 210376298 Liu Zeyu 210237531 Mei Lyuke 200132620 Qi Shuyu 210681907 Wang Handuo 200015356 Wu Zhuoyue 200071994 Xie Kaijun GROUP 5 R/W Tutor: Chukwudi Dozie S/L Tutor: Nora Mikso STUDENT ID SURNAME FIRST NAME 210563304 Almalek Ahmed 210186309 Altamimi Saud 210251102 Cheng Han-Yu 210349823 Guo Wenyuan 210239409 -

French Names Noeline Bridge
names collated:Chinese personal names and 100 surnames.qxd 29/09/2006 13:00 Page 8 The hundred surnames Pinyin Hanzi (simplified) Wade Giles Other forms Well-known names Pinyin Hanzi (simplified) Wade Giles Other forms Well-known names Zang Tsang Zang Lin Zhu Chu Gee Zhu Yuanzhang, Zhu Xi Zeng Tseng Tsang, Zeng Cai, Zeng Gong Zhu Chu Zhu Danian Dong, Zhu Chu Zhu Zhishan, Zhu Weihao Jeng Zhu Chu Zhu jin, Zhu Sheng Zha Cha Zha Yihuang, Zhuang Chuang Zhuang Zhou, Zhuang Zi Zha Shenxing Zhuansun Chuansun Zhuansun Shi Zhai Chai Zhai Jin, Zhai Shan Zhuge Chuko Zhuge Liang, Zhan Chan Zhan Ruoshui Zhuge Kongming Zhan Chan Chaim Zhan Xiyuan Zhuo Cho Zhuo Mao Zhang Chang Zhang Yuxi Zi Tzu Zi Rudao Zhang Chang Cheung, Zhang Heng, Ziche Tzuch’e Ziche Zhongxing Chiang Zhang Chunqiao Zong Tsung Tsung, Zong Xihua, Zhang Chang Zhang Shengyi, Dung Zong Yuanding Zhang Xuecheng Zongzheng Tsungcheng Zongzheng Zhensun Zhangsun Changsun Zhangsun Wuji Zou Tsou Zou Yang, Zou Liang, Zhao Chao Chew, Zhao Kuangyin, Zou Yan Chieu, Zhao Mingcheng Zu Tsu Zu Chongzhi Chiu Zuo Tso Zuo Si Zhen Chen Zhen Hui, Zhen Yong Zuoqiu Tsoch’iu Zuoqiu Ming Zheng Cheng Cheng, Zheng Qiao, Zheng He, Chung Zheng Banqiao The hundred surnames is one of the most popular reference Zhi Chih Zhi Dake, Zhi Shucai sources for the Han surnames. It was originally compiled by an Zhong Chung Zhong Heqing unknown author in the 10th century and later recompiled many Zhong Chung Zhong Shensi times. The current widely used version includes 503 surnames. Zhong Chung Zhong Sicheng, Zhong Xing The Pinyin index of the 503 Chinese surnames provides an access Zhongli Chungli Zhongli Zi to this great work for Western people. -

Is Shuma the Chinese Analog of Soma/Haoma? a Study of Early Contacts Between Indo-Iranians and Chinese
SINO-PLATONIC PAPERS Number 216 October, 2011 Is Shuma the Chinese Analog of Soma/Haoma? A Study of Early Contacts between Indo-Iranians and Chinese by ZHANG He Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established, scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin (MSM) and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino- Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out to be refereed, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. -

Gateless Gate Has Become Common in English, Some Have Criticized This Translation As Unfaithful to the Original
Wú Mén Guān The Barrier That Has No Gate Original Collection in Chinese by Chán Master Wúmén Huìkāi (1183-1260) Questions and Additional Comments by Sŏn Master Sǔngan Compiled and Edited by Paul Dōch’ŏng Lynch, JDPSN Page ii Frontspiece “Wú Mén Guān” Facsimile of the Original Cover Page iii Page iv Wú Mén Guān The Barrier That Has No Gate Chán Master Wúmén Huìkāi (1183-1260) Questions and Additional Comments by Sŏn Master Sǔngan Compiled and Edited by Paul Dōch’ŏng Lynch, JDPSN Sixth Edition Before Thought Publications Huntington Beach, CA 2010 Page v BEFORE THOUGHT PUBLICATIONS HUNTINGTON BEACH, CA 92648 ALL RIGHTS RESERVED. COPYRIGHT © 2010 ENGLISH VERSION BY PAUL LYNCH, JDPSN NO PART OF THIS BOOK MAY BE REPRODUCED OR TRANSMITTED IN ANY FORM OR BY ANY MEANS, GRAPHIC, ELECTRONIC, OR MECHANICAL, INCLUDING PHOTOCOPYING, RECORDING, TAPING OR BY ANY INFORMATION STORAGE OR RETRIEVAL SYSTEM, WITHOUT THE PERMISSION IN WRITING FROM THE PUBLISHER. PRINTED IN THE UNITED STATES OF AMERICA BY LULU INCORPORATION, MORRISVILLE, NC, USA COVER PRINTED ON LAMINATED 100# ULTRA GLOSS COVER STOCK, DIGITAL COLOR SILK - C2S, 90 BRIGHT BOOK CONTENT PRINTED ON 24/60# CREAM TEXT, 90 GSM PAPER, USING 12 PT. GARAMOND FONT Page vi Dedication What are we in this cosmos? This ineffable question has haunted us since Buddha sat under the Bodhi Tree. I would like to gracefully thank the author, Chán Master Wúmén, for his grace and kindness by leaving us these wonderful teachings. I would also like to thank Chán Master Dàhuì for his ineptness in destroying all copies of this book; thankfully, Master Dàhuì missed a few so that now we can explore the teachings of his teacher. -

Cha Zhang, Chang−Shui Zhang, Chengcui Zhang, Dengsheng Zhang, Dong Zhang, Dongming Zhang, Hong−Jiang Zhang, Jiang Zhang, Jianning Zhang, Keqi Zhang, Lei Zhang, Li
Z Zeng, Wenjun Zeng, Zhihong Zhai, Yun Zhang, Benyu Zhang, Cha Zhang, Chang−Shui Zhang, Chengcui Zhang, Dengsheng Zhang, Dong Zhang, Dongming Zhang, Hong−Jiang Zhang, Jiang Zhang, Jianning Zhang, Keqi Zhang, Lei Zhang, Li Menu Next Z Zhang, Like Zhang, Meng Zhang, Mingju Zhang, Rong Zhang, Ruofei Zhang, Weigang Zhang, Yongdong Zhang, Yun−Gang Zhang, Zhengyou Zhang, Zhenping Zhang, Zhenqiu Zhang, Zhishou Zhang, Zhongfei (Mark) Zhao, Frank Zhao, Li Zhao, Na Prev Menu Next Z Zheng, Changxi Zheng, Yizhan Zhi, Yang Zhong, Yuzhuo Zhou, Jin Zhu, Jiajun Zhu, Xiaoqing Zhu, Yongwei Zhuang, Yueting Zimmerman, John Zoric, Goranka Zou, Dekun Prev Menu Wenjun Zeng Organization : University of Missouri−Columbia, United States of America Paper(s) : ON THE RATE−DISTORTION PERFORMANCE OF DYNAMIC BITSTREAM SWITCHING MECHANISMS (Abstract) Letter−Z Menu Zhihong Zeng Organization : University of Illinois at Urbana−Champaign, United States of America Paper(s) : AUDIO−VISUAL AFFECT RECOGNITION IN ACTIVATION−EVALUATION SPACE (Abstract) Letter−Z Menu Yun Zhai Organization : University of Central Florida, United States of America Paper(s) : AUTOMATIC SEGMENTATION OF HOME VIDEOS (Abstract) Letter−Z Menu Benyu Zhang Organization : Microsoft Research Asia, China Paper(s) : SUPERVISED SEMI−DEFINITE EMBEDING FOR IMAGE MANIFOLDS (Abstract) Letter−Z Menu Cha Zhang Organization : Microsoft Research, United States of America Paper(s) : HYBRID SPEAKER TRACKING IN AN AUTOMATED LECTURE ROOM (Abstract) Letter−Z Menu Chang−Shui Zhang Organization : Tsinghua University, China -

Social Mobility in China, 1645-2012: a Surname Study Yu (Max) Hao and Gregory Clark, University of California, Davis [email protected], [email protected] 11/6/2012
Social Mobility in China, 1645-2012: A Surname Study Yu (Max) Hao and Gregory Clark, University of California, Davis [email protected], [email protected] 11/6/2012 The dragon begets dragon, the phoenix begets phoenix, and the son of the rat digs holes in the ground (traditional saying). This paper estimates the rate of intergenerational social mobility in Late Imperial, Republican and Communist China by examining the changing social status of originally elite surnames over time. It finds much lower rates of mobility in all eras than previous studies have suggested, though there is some increase in mobility in the Republican and Communist eras. But even in the Communist era social mobility rates are much lower than are conventionally estimated for China, Scandinavia, the UK or USA. These findings are consistent with the hypotheses of Campbell and Lee (2011) of the importance of kin networks in the intergenerational transmission of status. But we argue more likely it reflects mainly a systematic tendency of standard mobility studies to overestimate rates of social mobility. This paper estimates intergenerational social mobility rates in China across three eras: the Late Imperial Era, 1644-1911, the Republican Era, 1912-49 and the Communist Era, 1949-2012. Was the economic stagnation of the late Qing era associated with low intergenerational mobility rates? Did the short lived Republic achieve greater social mobility after the demise of the centuries long Imperial exam system, and the creation of modern Westernized education? The exam system was abolished in 1905, just before the advent of the Republic. Exam titles brought high status, but taking the traditional exams required huge investment in a form of “human capital” that was unsuitable to modern growth (Yuchtman 2010). -

Self-Study Syllabus on Chinese Foreign Policy
Self-Study Syllabus on Chinese Foreign Policy www.mandarinsociety.org PrefaceAbout this syllabus with China’s rapid economic policymakers in Washington, Tokyo, Canberra as the scale and scope of China’s current growth, increasing military and other capitals think about responding to involvement in Africa, China’s first overseas power,Along and expanding influence, Chinese the challenge of China’s rising power. military facility in Djibouti, or Beijing’s foreign policy is becoming a more salient establishment of the Asian Infrastructure concern for the United States, its allies This syllabus is organized to build Investment Bank (AIIB). One of the challenges and partners, and other countries in Asia understanding of Chinese foreign policy in that this has created for observers of China’s and around the world. As China’s interests a step-by-step fashion based on one hour foreign policy is that so much is going on become increasingly global, China is of reading five nights a week for four weeks. every day it is no longer possible to find transitioning from a foreign policy that was In total, the key readings add up to roughly one book on Chinese foreign policy that once concerned principally with dealing 800 pages, rarely more than 40–50 pages will provide a clear-eyed assessment of with the superpowers, protecting China’s for a night. We assume no prior knowledge everything that a China analyst should know. regional interests, and positioning China of Chinese foreign policy, only an interest in as a champion of developing countries, to developing a clearer sense of how China is To understanding China’s diplomatic history one with a more varied and global agenda. -

Lǎoshī Hé Xuéshēng (Teacher and Students)
© Copyright, Princeton University Press. No part of this book may be distributed, posted, or reproduced in any form by digital or mechanical means without prior written permission of the publisher. CHAPTER Lǎoshī hé Xuéshēng 1 (Teacher and Students) Pinyin Text English Translation (A—Dīng Yī, B—Wáng Èr, C—Zhāng Sān) (A—Ding Yi, B—Wang Er, C—Zhang San) A: Nínhǎo, nín guìxìng? A: Hello, what is your honorable surname? B: Wǒ xìng Wáng, jiào Wáng Èr. Wǒ shì B: My surname is Wang. I am called Wang Er. lǎoshī. Nǐ xìng shénme? I am a teacher. What is your last name? A: Wǒ xìng Dīng, wǒde míngzi jiào Dīng Yī. A: My last name is Ding and my full name is Wǒ shì xuéshēng. Ding Yi. I am a student. 老师 老師 lǎoshī n. teacher 和 hé conj. and 学生 學生 xuéshēng n. student 您 nín pron. honorific form of singular you 好 hǎo adj. good 你(您)好 nǐ(nín)hǎo greeting hello 贵 貴 guì adj. honorable 贵姓 貴姓 guìxìng n./v. honorable surname (is) 我 wǒ pron. I; me 姓 xìng n./v. last name; have the last name of … 王 Wáng n. last name Wang 叫 jiào v. to be called 二 èr num. two (used when counting; here used as a name) 是 shì v. to be (any form of “to be”) 10 © Copyright, Princeton University Press. No part of this book may be distributed, posted, or reproduced in any form by digital or mechanical means without prior written permission of the publisher. -

BIOGRAPHICAL SKETCH NAME: Jianhua Zhang Era
OMB No. 0925-0001/0002 (Rev. 08/12 Approved Through 8/31/2015) BIOGRAPHICAL SKETCH Provide the following information for the Senior/key personnel and other significant contributors. Follow this format for each person. DO NOT EXCEED FIVE PAGES. NAME: Jianhua Zhang eRA COMMONS USER NAME (credential, e.g., agency login): JZHANG123 POSITION TITLE: Associate Professor EDUCATION/TRAINING (Begin with baccalaureate or other initial professional education, such as nursing, include postdoctoral training and residency training if applicable. Add/delete rows as necessary.) DEGREE Completion (if Date FIELD OF STUDY INSTITUTION AND LOCATION applicable) MM/YYYY University of Science & Technology of China B.S. 1984 Biology University of Texas Southwestern Medical Center Ph.D. 1991 Cell & Molecular Biology Whitehead Institute for Biomedical Research Postdoc 1995 Molecular Biology A. Personal statement I came to the US in 1985 via a CUSPEA program, trained with Dr. Joseph Sambrook at UT Southwestern on molecular cloning and cellular retinoic acid binding protein structure/function relationships, and from 1991 to 1995 with Dr. Rick Young in the Whitehead Institute on the genetics of RNA polymerase holoenzyme and coactivator functions. From 1996 to 2005 I had been working with genetically engineered mouse models of (i) dopamine receptors, (ii) immediate early gene transcription factor c-fos, and (iii) DNA fragmentation factors in neuroplasticity and apoptosis at the Univ of Cincinnati, by generating and analyzing conventional and conditional mouse knockout and transgenic models. In 2005 I became a tenure track assistant professor in UAB where I focused my research program on how the autophagy-lysosomal pathway plays a role in neuronal function and survival, in the context of Parkinson’s disease. -

Scott J. Brandenberg, Jian Zhang, Yili Huo, and Minxing Zhao, UCLA
Simulation of 3-D Global Bridge Response to Shaking and Lateral Spreading Scott J. Brandenberg, Jian Zhang, Yili Huo, and Minxing Zhao, UCLA PEER Transportation Systems Research Program May 2, 2011 Project Description PEER Transportation Systems Research Program 2/14 1-D site response analyses • Ground Motion Records from 2007 Niigata Earthquake • Records from Centrifuge Test PEER Transportation Systems Research Program 3/14 1-D site response analyses • Records from Numerical Simulation 10 with dilatancy ) 2 5 0 -5 Acceleration (m/s Acceleration Ground surface motion -10 0 10 20 30 Time (second) 1 0.5 0 -0.5 in loose sand -1 Excess Pore Pressure Ratio Pressure Pore Excess 0 10 20 30 Time (second) 10 ) 2 5 0 -5 Acceleration (m/s Acceleration Base input motion No.35 -10 0 10 20 30 Time (second) A liquefied sand layer is not a “base isolator”. PEER Transportation Systems Research Program 4/14 1-D site response analyses • Site Amplification Factor – Baseline Soil Profile liq.liq. noliq.noliq. 10 10 ) ) 2 2 s / s / m m ( ( liq noliq a 1 a 1 S S 0.1 0.1 0.01 0.1 1 10 0.01 0.1 1 10 Period (second) Period (second) = Fa Sa liq/ Sa noliq a 1 1 a F Median of F of Median median curve 0.1 0.01 0.1 1 10 0.01 0.1 1 10 Period (second) Period (second) PEER Transportation Systems Research Program 5/14 1-D site response analyses • Site Amplification Factor – Monte Carlo Simulations a F 1 f o n a i d e M 0.01 0.1 1 10 Period (second) PEER Transportation Systems Research Program 6/14 Modeling of the studied case 6 6 3 3 Disp (m) Disp (m) Disp(m) Disp (m) 0 1 2 0 1 2 -2 -1 0 -2 -1 0 0 0 0 0 7s Bridge and soil layer sketch Depth(m) 14s (m) Depth -3 -3 -3 21s -3 28s 35s -6 -6 (m) Depth -6 Depth(m) 42s -6 49s 56s -9 -9 -9 63s -9 70s Soil layer simplification (a) Left abut (b) Left pier (c) Right pier (d) Right abut Longitudinal displacement profiles with motion No. -

Biographical Sketch of Principal Investigator: Tongguang Zhai ——————————————————————————————————————— A
Biographical Sketch of Principal Investigator: Tongguang Zhai ——————————————————————————————————————— a. Professional Preparation. • 8/1/2000-8/14/2001 Postdoctoral Research Associate University of Kentucky conducting research work on continuous cast Al • 1/21/1995-4/30/2000 Research Fellow University of Oxford, England studying short fatigue crack initiation & propagation • 10/1/1994-12/31/1994 Postdoctoral Assistant Fraunhofer Institute for NDT, Germany ultrasonic NDT and acoustic microscopy of materials • 9/1991-9/1994 Ph.D. student D.Phil (Ph.D), 9/1996 Materials Science, University of Oxford, England • 9/1979-6/1983 Undergraduate B.Sc., 6/1983 Materials Physics, University of Science & Technology Beijing, China b. Appointments. 7/2007—present Associate Professor, Department of Chemical and Materials Engineering University of Kentucky, Lexington, KY 40506-0046, USA 8/2001—6/2007 Assistant Professor, Department of Chemical and Materials Engineering University of Kentucky, Lexington, KY 40506-0046, USA 9/1983—8/1986 Research Engineer, Welding Department Institute of Building and Construction Research, Beijing, China c. Publications (SCI indexed since 2017). 1) Pei Cai, Wei Wen, T. *Zhai (2018), A physics-based model validated experimentally for simulating short fatigue crack growth in 3-D in planar slip alloys, Mater. Sci. Eng. A, vol. 743, pp. 453-463. 2) R.J. Sun, L.H. Li, W. Guo, P. Peng, T. Zhai, Z.G. Che, B. Li, .C. Guo, Y. Zhu (2018), Laser shock peening induced fatigue crack retardation in Ti-17 titanium alloy, Mater. Sci. Eng. A, vol. 737, pp. 94- 104. 3) S.X. Jin, Tungwai Ngai, G.W. Zhangb, T. Zhai, S. Jia, L.J. -

I.D. Jiangnan 241
I.D. THE JIANGNAN REGION, 1645–1659 I.D.1. Archival Documents, Published Included are items concerning Jiangnan logistical support for campaigns in other regions, as well as maritime attacks on Jiangnan. a. MQSL. Ser. 甲, vols. 2–4; ser. 丙, vols. 2, 6-8; ser. 丁, vol. 1; ser. 己, vols. 1–6. b. MQCZ. I: Hongguang shiliao 弘光史料, items 82, 87. III: Hong Chengchou shiliao 洪承疇史料, item 50; Zheng Chenggong shiliao 鄭成 功史料, item 82. c. MQDA. Ser. A, vols. 3–8, 11, 13, 17, 19–26, 28–31, 34–37. d. QNMD. Vol. 2 (see I.B.1.d.). e. QNZS. Bk. 1, vol. 2. f. Hong Chengchou zhangzou wence huiji 洪承疇章奏文冊彙輯. Comp. Wu Shigong 吳世拱. Guoli Beijing daxue yanjiuyuan wenshi congkan 國立北 京大學研究院文史叢刊, no. 4. Shanghai: CP, 1937. Rpts. in MQ, pt. 3, vol. 10. Rep. in 2 vol., TW, no. 261; rpt. TWSL, pt. 4, vol. 61. Hong Chengchou was the Ming Viceroy of Jifu and Liaoning 薊遼 總 督 from 1639 until his capture by the forces of Hungtaiji in the fall of Songshan 松山 in 1642. After the rebel occupation of Beijing and the death of the CZ emperor, Hong assumed official appointment under the Qing and went on to become the most important former Ming official to assist in the Qing conquest of all of China (see Li Guangtao 1948a; Wang Chen-main 1999; Li Xinda 1992). Many of his very numerous surviving memorials have been published in MQSL and MQDA. In the present col- lection of 67 memorials, 13 represent his service as Viceroy of Jiangnan and “Pacifier of the South” 招撫南方 from 1645 through 1648.