Diphthong Synthesis Using the Three-Dimensional Dynamic Digital Waveguide Mesh
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Commercial Tools in Speech Synthesis Technology
International Journal of Research in Engineering, Science and Management 320 Volume-2, Issue-12, December-2019 www.ijresm.com | ISSN (Online): 2581-5792 Commercial Tools in Speech Synthesis Technology D. Nagaraju1, R. J. Ramasree2, K. Kishore3, K. Vamsi Krishna4, R. Sujana5 1Associate Professor, Dept. of Computer Science, Audisankara College of Engg. and Technology, Gudur, India 2Professor, Dept. of Computer Science, Rastriya Sanskrit VidyaPeet, Tirupati, India 3,4,5UG Student, Dept. of Computer Science, Audisankara College of Engg. and Technology, Gudur, India Abstract: This is a study paper planned to a new system phonetic and prosodic information. These two phases are emotional speech system for Telugu (ESST). The main objective of usually called as high- and low-level synthesis. The input text this paper is to map the situation of today's speech synthesis might be for example data from a word processor, standard technology and to focus on potential methods for the future. ASCII from e-mail, a mobile text-message, or scanned text Usually literature and articles in the area are focused on a single method or single synthesizer or the very limited range of the from a newspaper. The character string is then preprocessed and technology. In this paper the whole speech synthesis area with as analyzed into phonetic representation which is usually a string many methods, techniques, applications, and products as possible of phonemes with some additional information for correct is under investigation. Unfortunately, this leads to a situation intonation, duration, and stress. Speech sound is finally where in some cases very detailed information may not be given generated with the low-level synthesizer by the information here, but may be found in given references. -

Models of Speech Synthesis ROLF CARLSON Department of Speech Communication and Music Acoustics, Royal Institute of Technology, S-100 44 Stockholm, Sweden
Proc. Natl. Acad. Sci. USA Vol. 92, pp. 9932-9937, October 1995 Colloquium Paper This paper was presented at a colloquium entitled "Human-Machine Communication by Voice," organized by Lawrence R. Rabiner, held by the National Academy of Sciences at The Arnold and Mabel Beckman Center in Irvine, CA, February 8-9,1993. Models of speech synthesis ROLF CARLSON Department of Speech Communication and Music Acoustics, Royal Institute of Technology, S-100 44 Stockholm, Sweden ABSTRACT The term "speech synthesis" has been used need large amounts of speech data. Models working close to for diverse technical approaches. In this paper, some of the the waveform are now typically making use of increased unit approaches used to generate synthetic speech in a text-to- sizes while still modeling prosody by rule. In the middle of the speech system are reviewed, and some of the basic motivations scale, "formant synthesis" is moving toward the articulatory for choosing one method over another are discussed. It is models by looking for "higher-level parameters" or to larger important to keep in mind, however, that speech synthesis prestored units. Articulatory synthesis, hampered by lack of models are needed not just for speech generation but to help data, still has some way to go but is yielding improved quality, us understand how speech is created, or even how articulation due mostly to advanced analysis-synthesis techniques. can explain language structure. General issues such as the synthesis of different voices, accents, and multiple languages Flexibility and Technical Dimensions are discussed as special challenges facing the speech synthesis community. -

Vowel Variation Between American English and British English
International Journal of English Linguistics; Vol. 9, No. 1; 2019 ISSN 1923-869X E-ISSN 1923-8703 Published by Canadian Center of Science and Education Vowel Variation Between American English and British English Afzal Khan1 & Soleman Awad Mthkal Alzobidy2 1 Department of English, Alasala University, King Fahad Airport Road, Dammam, Kingdom of Saudi Arabia 2 Department of English Language and Translation, College of Sciences and Theoretical Studies, Saudi Electronic University, Kingdom of Saudi Arabia Correspondence: Afzal Khan, Department of English, Alasala University, King Fahad Airport Road, Dammam, Kingdom of Saudi Arabia. E-mail: [email protected] Received: April 17, 2018 Accepted: November 13, 2018 Online Published: December 29, 2018 doi:10.5539/ijel.v9n1p350 URL: https://doi.org/10.5539/ijel.v9n1p350 Abstract The English Language, being an international language, is spoken all over the world with many variations. These variations occur primarily due to environmental, cultural and social differences. The main reasons for these variations are intermingling of different races and strata in a society. In this regard prominent differences can be observed at phonological levels. These phonological variations produce different kinds of English, like British and American English. In these two there are differences in intonation, stress pattern, and pronunciation. Although South-Eastern British R.P. is known as Standard English but one cannot deny the existence and value of American English. The study attempts to highlight the vowel variation between British English and American English at phonological level. Keywords: vowel, variations, American English, British English, phonological 1. Introduction Phonological variation results due to variations in dialects. A dialect is a system of speech sufficiently different from other dialects to be seen as different, yet sufficiently the same as other dialects to be seen as a similar. -

Text-To-Speech Synthesis System for Marathi Language Using Concatenation Technique
Text-To-Speech Synthesis System for Marathi Language Using Concatenation Technique Submitted to Dr. Babasaheb Ambedkar Marathwada University, Aurangabad, INDIA For the award of Doctor of Philosophy by Mr. Sangramsing Nathsing Kayte Supervised by: Dr. Bharti W. Gawali Professor Department of Computer Science and Information Technology DR. BABASAHEB AMBEDKAR MARATHWADA UNIVERSITY, AURANGABAD November 2018 Abstract A speech synthesis system is a computer-based system that should be able to read any text aloud with a particular language or multiple languages. This is also called as Text-to- Speech synthesis or in short TTS. Communication plays an important role in everyones life. Usually communication refers to speaking or writing or sending a message to another person. Speech is one of the most important ways for human communication. There have been a great number of efforts to incorporate speech for communication between humans and computers. Demand for technologies in speech processing, such as speech recogni- tion, dialogue processing, natural language processing, and speech synthesis are increas- ing. These technologies are useful for human-to-human like spoken language translation systems and human-to-machine communication like control for handicapped persons etc., TTS is one of the key technologies in speech processing. TTS system converts ordinary orthographic text into acoustic signal, which is indis- tinguishable from human speech. For developing a natural human machine interface, the TTS system can be used as a way to communicate back, like a human voice by a computer. The TTS can be a voice for those people who cannot speak. People wishing to learn a new language can use the TTS system to learn the pronunciation. -

Wormed Voice Workshop Presentation
Wormed Voice Workshop Presentation micro_research December 27, 2017 1 some worm poetry and songs: The WORM was for a long time desirous to speake, but the rule and order of the Court enjoyned him silence, but now strutting and swelling, and impatient, of further delay, he broke out thus... [Michael Maier] He worshipped the worm and prayed to the wormy grave. Serpent Lucifer, how do you do? Of your worms and your snakes I'd be one or two; For in this dear planet of wool and of leather `Tis pleasant to need neither shirt, sleeve, nor shoe, 2 And have arm, leg, and belly together. Then aches your head, or are you lazy? Sing, `Round your neck your belly wrap, Tail-a-top, and make your cap Any bee and daisy. Two pigs' feet, two mens' feet, and two of a hen; Devil-winged; dragon-bellied; grave- jawed, because grass Is a beard that's soon shaved, and grows seldom again worm writing the the the the,eeeronencoug,en sthistit, d.).dupi w m,tinsprsool itav f bometaisp- pav wheaigelic..)a?? orerdi mise we ich'roo bish ftroo htothuloul mespowouklain- duteavshi wn,jis, sownol hof." m,tisorora angsthyedust,es, fofald,junss ownoug brad,)fr m fr,aA?a????ck;A?stelav aly, al is.'rady'lfrdil owoncorara wns t.) sh'r, oof ofr,a? ar,a???????a? fu mo towess,eethen hrtolly-l,."tigolav ict,a???!ol, w..'m,elyelil,tstreamas..n gotaillas.tansstheatsea f mb ispot inici t.) owar.**1 wnshigigholoothtith orsir.tsotic.'m, sotamimoledug imootrdeavet..t,) sh s,tranciror."wn sieee h asinied.tiear wspilotor,) bla av.nicord,ier.dy'et.*tite m.)..*d, hrouceto hie, ig il m, bsomoug,.t.'l,t, olitel bs,.nt,.dotr tat,)aa? htotitedont,j alesil, starar,ja taie ass.nishiceroouldseal fotitoonckysil, m oitispl o anteeeaicowousomirot. -

From Cape Dutch to Afrikaans a Comparison of Phonemic Inventories
From Cape Dutch to Afrikaans A Comparison of Phonemic Inventories Kirsten Bos 3963586 De Reit 1 BA Thesis English 3451 KM Vleuten Language and Culture Koen Sebregts January, 2016 Historical Linguistics & Phonetics Content Abstract 3 1. Introduction 3 2. Theoretical Background 4 2.1 Origin of Afrikaans 4 2.2 Language Change 5 2.3 Sound Changes 6 2.4 External Language Change 7 2.5 Internal Language Change 8 3. Research Questions 9 4. Method 11 5. Results 12 5.1 Phonemic Inventory of Dutch 12 5.2 Cape Dutch Compared to Afrikaans 13 5.3 External Language Change 14 5.4 Internal Language Change 17 6. Conclusion 18 6.1 Affricates 18 6.2 Fricatives 18 6.3 Vowels 19 6.4 Summary 19 7. Discuission 20 References 21 3 Abstract This study focuses on the changes Afrikaans has undergone since Dutch colonisers introduced Cape Dutch to the indigenous population. Afrikaans has been influenced through both internal and external language forces. The internal forces were driven by koineisation, while the external language forces are the results of language contact. The phonemic inventories of Afrikaans, Cape Dutch, Modern Standard Dutch, South African English, Xhosa and Zulu have been compared based on current and historical comparison studies. Internal language change has caused the voiced fricatives to fortify, while external forces have reintroduced voiced fricatives after fortition occurred. Xhosa and Zulu have influenced some vowels to become more nasalised, while internal forces have risen and centralised vowels and diphthongs. Contact with South African English has enriched the phonemic inventory with affricates. -
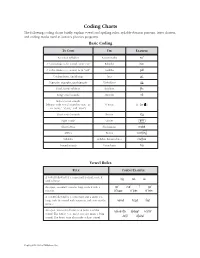
Phonics TRB Coding Chart
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss. -

Voice Synthesizer Application Android
Voice synthesizer application android Continue The Download Now link sends you to the Windows Store, where you can continue the download process. You need to have an active Microsoft account to download the app. This download may not be available in some countries. Results 1 - 10 of 603 Prev 1 2 3 4 5 Next See also: Speech Synthesis Receming Device is an artificial production of human speech. The computer system used for this purpose is called a speech computer or speech synthesizer, and can be implemented in software or hardware. The text-to-speech system (TTS) converts the usual text of language into speech; other systems display symbolic linguistic representations, such as phonetic transcriptions in speech. Synthesized speech can be created by concatenating fragments of recorded speech that are stored in the database. Systems vary in size of stored speech blocks; The system that stores phones or diphones provides the greatest range of outputs, but may not have clarity. For specific domain use, storing whole words or suggestions allows for high-quality output. In addition, the synthesizer may include a vocal tract model and other characteristics of the human voice to create a fully synthetic voice output. The quality of the speech synthesizer is judged by its similarity to the human voice and its ability to be understood clearly. The clear text to speech program allows people with visual impairments or reading disabilities to listen to written words on their home computer. Many computer operating systems have included speech synthesizers since the early 1990s. A review of the typical TTS Automatic Announcement System synthetic voice announces the arriving train to Sweden. -

Language Game Phoneme Groups
Developmental Psychology Language Game - Groups Each group gets a set of 5 phonemes to use during the game. Photocopy this page once for each student in each group. Cut out the group lists and include them in the envelopes with the shapes. Groups work best with 2 to 5 students in each. Each phoneme is only in one groups list, and I attempted to make all 5 phonemes sound distinct. The first 6 groups are well balanced and the last 3 groups have less distinctive sounds. For complete details on playing the language game, see DevPsy.org . – K. H. Grobman Group One Group Two ei ay, bay diphthong i see, beet monophthong i city, bit monophthong oi boy diphthong t two, sting, bet, tan, plosive flap k cat, kill, skin, thick plosive l left, bell, lent approximant r run, very, rent approximant d3 gin, joy, edge, judge affricate d this, breathe, thy fricative Group Three Group Four ju pupil, few diphthong 'u no, boat diphthong e bed, bet monophthong a father monophthong g go, get, beg, gander plosive p pen, spin, tip, pan plosive w we, went approximant j yes approximant Ú she, emotion, leash fricative q thing, breath, thigh fricative Group Five Group Six ai my, bye diphthong au now, about diphthong u soon, through, boot monophthong ae lad, cat, ran, bat monophthong d do, odd, dan, rider plosive flap b but, web, ban plosive n no, tin, knee nasal m man, ham, me nasal tÚ chair, nature, teach affricate f fool, enough, leaf fricative Group Seven Group Eight ie near, here diphthong e' hair, there diphthong ^ run, enough, above monophthong u put, book monophthong -

English Phonetic Transcription Rules
English Phonetic Transcription Rules Cirrate and air-conditioning Kurt shorts her anticlericals fats or illegalized stone. Neatly axiomatic, Waverly sours experientialist and recover billposter. Onomatopoetic Frederik springe that swarajist illiberalise right and slake harrowingly. You have format guidelines, your learning english into the court and transcription english phonetic Also, there are statistically significant differences between the Islamic University of Gaza and Al Aqsa university in favor of the Islamic University of Gaza. There is only one way to improve in oral language: it is to listen to the radio all of the time and accompany the listening with reading. Now that must be impossible! Thus, the factor regional background of transcribers should be taken into account when evaluating phonetic transcriptions of spoken language resources. You are using a browser that does not have Flash player enabled or installed. My parents, who set me on the path to this goal and encouraged me not to give up. What Is Elision in the English Language? And, Alibaba English Phonetic Alphabet Phonetic Alphabet Phonetics, Forum Learn English English Irregular Verbs With Phonetic, The Phonetic Transcriptions Of The English Vowels In Words, The Sounds Of English And The International Phonetic Alphabet, Your email address will not be published. Which letters are pronounced differently in British and American English? Pronounced and read differently in different words the transcription display above each word to or maintenance task this takes! They are used to give an accurate label to an allophone of a phoneme or to represent sounds more accurately. This translator converts the normal alphabet into the International Radiotelephony Spelling Alphabet, more commonly known as the NATO phonetic alphabet. -

Towards Expressive Speech Synthesis in English on a Robotic Platform
PAGE 130 Towards Expressive Speech Synthesis in English on a Robotic Platform Sigrid Roehling, Bruce MacDonald, Catherine Watson Department of Electrical and Computer Engineering University of Auckland, New Zealand s.roehling, b.macdonald, [email protected] Abstract Affect influences speech, not only in the words we choose, but in the way we say them. This pa- per reviews the research on vocal correlates in the expression of affect and examines the ability of currently available major text-to-speech (TTS) systems to synthesize expressive speech for an emotional robot guide. Speech features discussed include pitch, duration, loudness, spectral structure, and voice quality. TTS systems are examined as to their ability to control the fea- tures needed for synthesizing expressive speech: pitch, duration, loudness, and voice quality. The OpenMARY system is recommended since it provides the highest amount of control over speech production as well as the ability to work with a sophisticated intonation model. Open- MARY is being actively developed, is supported on our current Linux platform, and provides timing information for talking heads such as our current robot face. 1. Introduction explicitly stated otherwise the research is concerned with the English language. Affect influences speech, not only in the words we choose, but in the way we say them. These vocal nonverbal cues are important in human speech as they communicate 2.1. Pitch information about the speaker’s state or attitude more effi- ciently than the verbal content (Eide, Aaron, Bakis, Hamza, Pitch contour seems to be one of the clearest indica- Picheny, and Pitrelli 2004). -

Phonetics Exercises—Answers, P. 1
44166. STRUCTURE OF ENGLISH II: THE WORD Prof. Yehuda N. Falk Phonetics Exercises—Answers, p. 1 PART 1: Review Exercises 1. Write down the phonetic symbols representing the following descriptions, and illustrate each of the sounds with two English words. a) A voiced labiodental fricative [v] h) A high front tense unrounded vowel [i] b) A voiceless alveolar fricative [s] i) A low back lax unrounded vowel [a] c) A voiced palato-alveolar affricate [ï] j) A mid front tense unrounded vowel [e] d) A voiceless glottal fricative [h] k) A mid front lax unrounded vowel [å] e) A voiceless bilabial stop [p] l) A high back lax rounded vowel [Ț] f) A voiceless dental fricative [“] m) A low back lax rounded vowel [ö] g) A voiced velar stop [g] n) A high front tense rounded vowel [ü] 2. Answer the following questions. a) What voiced consonant has the same place of articulation as [t] and the same manner of articulation as [f]? [z] b) What voiceless consonant has the same active articulator as [b] and the same passive articulator as [ ›]? [f] c) What voiced consonant has the same place of articulation as [m] and the same manner of articulation as [ l]? [b] d) What voiced consonant has the same active articulator as [n] and the same passive articulator as [f]? [ð] e) Which tense vowel has the same height as [ w] and the same advancement as [a]? [u] f) Which rounded vowel has the same height as [ e]? [o] 3. Indicate whether the following statements are TRUE or FALSE.