Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Bioinformatic
CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Bioinformatic Comparison of the EVI2A Promoter and Coding Regions A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Biology By Max Weinstein May 2020 The thesis of Max Weinstein is approved: Professor Rheem D. Medh Date Professor Virginia Oberholzer Vandergon Date Professor Cindy Malone, Chair Date California State University Northridge ii Table of Contents Signature Page ii List of Figures v Abstract vi Introduction 1 Ecotropic Viral Integration Site 2A, a Gene within a Gene 7 Materials and Methods 11 PCR and Cloning of Recombinant Plasmid 11 Transformation and Cell Culture 13 Generation of Deletion Constructs 15 Transfection and Luciferase Assay 16 Identification of Transcription Factor Binding Sites 17 Determination of Region for Analysis 17 Multiple Sequence Alignment (MSA) 17 Model Testing 18 Tree Construction 18 Promoter and CDS Conserved Motif Search 19 Results and Discussion 20 Choice of Species for Analysis 20 Mapping of Potential Transcription Factor Binding Sites 20 Confirmation of Plasmid Generation through Gel Electrophoresis 21 Analysis of Deletion Constructs by Transient Transfection 22 EVI2A Coding DNA Sequence Phylogenetics 23 EVI2A Promoter Phylogenetics 23 EVI2A Conserved Leucine Zipper 25 iii EVI2A Conserved Casein kinase II phosphorylation site 26 EVI2A Conserved Sox-5 Binding Site 26 EVI2A Conserved HLF Binding Site 27 EVI2A Conserved cREL Binding Site 28 EVI2A Conserved CREB Binding Site 28 Summary 29 Appendix: Figures 30 Literature Cited 44 iv List of Figures Figure 1. EVI2A is nested within the gene NF1 30 Figure 2 Putative Transcriptions Start Site 31 Figure 3. Gel Electrophoresis of pGC Blue cloned, Restriction Digested Plasmid 32 Figure 4. -

Associated Fibroblasts in Non-Small Cell Lung Cancer
Prognostic gene-expression signature of carcinoma- associated fibroblasts in non-small cell lung cancer Roya Navaba,1, Dan Strumpfa,1, Bizhan Bandarchia,1, Chang-Qi Zhua,1, Melania Pintiliea, Varune Rohan Ramnarinea, Emin Ibrahimova, Nikolina Radulovicha, Lisa Leunga, Malgorzata Barczyka,b, Devang Panchala, Christine Toa, James J. Yuna, Sandy Dera, Frances A. Shepherda,c, Igor Jurisicaa,d,e, and Ming-Sound Tsaoa,e,f,2 aThe Campbell Family Institute for Cancer Research, Ontario Cancer Institute at Princess Margaret Hospital, University Health Network, Toronto, ON, Canada M5G 2M9; bDepartment of Biomedicine, Jonas Lies vei, N-5009 Bergen, Norway; Departments of cMedicine, dComputer Science, and eMedical Biophysics, and fLaboratory of Medicine and Pathobiology, University of Toronto, Toronto, ON, Canada M5A 2N4 Edited* by Tak Wah Mak, The Campbell Family Institute for Breast Cancer Research, Ontario Cancer Institute at Princess Margaret Hospital, University Health Network, Toronto, ON, Canada, and approved March 10, 2011 (received for review September 28, 2010) The tumor microenvironment strongly influences cancer develop- Results ment, progression, and metastasis. The role of carcinoma-associated Cultured CAFs Display Features of Myofibroblasts. By using a study fibroblasts (CAFs) in these processes and their clinical impact has protocol approved by the Institutional Research Ethics Board, not been studied systematically in non-small cell lung carcinoma CAFs and NFs were cultured from 15 surgically resected primary (NSCLC). We established primary cultures of CAFs and matched nor- NSCLCs, and the histologically confirmed normal lung tissue was mal fibroblasts (NFs) from 15 resected NSCLC. We demonstrate that obtained from the same lobe (Table S1A). Both the primary CAFs have greater ability than NFs to enhance the tumorigenicity of cultured CAFs and tumor stromal fibroblasts expressed α-smooth lung cancer cell lines. -

Review Article J Med Genet: First Published As 10.1136/Jmg.33.1.2 on 1 January 1996
2 J7 Med Genet 1996;33:2-17 Review article J Med Genet: first published as 10.1136/jmg.33.1.2 on 1 January 1996. Downloaded from Molecular genetics of neurofibromatosis type 1 (NFl) Ming Hong Shen, Peter S Harper, Meena Upadhyaya Abstract several discrete entities.'` At least two dis- Neurofibromatosis type 1 (NF1), also tinctive forms, neurofibromatosis type 1 (NF1) called von Recklinghausen disease or peri- and neurofibromatosis type 2 (NF2), were re- pheral neurofibromatosis, is a common cognised and later confirmed by the cloning of autosomal dominant disorder char- two separate genes, the NF1 gene on chro- acterised by multiple neurofibromas, cafe mosome 1746 and the NF2 gene on chro- au lait spots, and Lisch nodules ofthe iris, mosome 22.78 Other NF related syndromes with a variable clinical expression. The were also reported, such as segmental NF,9 gene responsible for this condition, NF1, Watson syndrome,'0 Noonan syndrome," has been isolated by positional cloning. spinal NF,'2 familial cafe au lait spots It spans over 350kb of genomic DNA in (CLS)," and Schwannomatosis.'4 It remains chromosomal region 17qll.2 and encodes to be determined whether such disorders are an mRNA of 11-13 kb containing at least genetically discrete. 59 exons. NFI is widely expressed in a NFl, also called von Recklinghausen disease variety of human and rat tissues. Four or peripheral neurofibromatosis, is a common alternatively spliced NFI transcripts have autosomal dominant disorder affecting about been identified. Three of these transcript 1 in 3000 to 5000 people. It exhibits full pene- isoforms (each with an extra exon: 9br, trance and a high mutation rate with 30 to 23a, and 48a, respectively) show differ- 50% ofNFl patients representing a new muta- ential expression to some extent in various tion. -

ID AKI Vs Control Fold Change P Value Symbol Entrez Gene Name *In
ID AKI vs control P value Symbol Entrez Gene Name *In case of multiple probesets per gene, one with the highest fold change was selected. Fold Change 208083_s_at 7.88 0.000932 ITGB6 integrin, beta 6 202376_at 6.12 0.000518 SERPINA3 serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 3 1553575_at 5.62 0.0033 MT-ND6 NADH dehydrogenase, subunit 6 (complex I) 212768_s_at 5.50 0.000896 OLFM4 olfactomedin 4 206157_at 5.26 0.00177 PTX3 pentraxin 3, long 212531_at 4.26 0.00405 LCN2 lipocalin 2 215646_s_at 4.13 0.00408 VCAN versican 202018_s_at 4.12 0.0318 LTF lactotransferrin 203021_at 4.05 0.0129 SLPI secretory leukocyte peptidase inhibitor 222486_s_at 4.03 0.000329 ADAMTS1 ADAM metallopeptidase with thrombospondin type 1 motif, 1 1552439_s_at 3.82 0.000714 MEGF11 multiple EGF-like-domains 11 210602_s_at 3.74 0.000408 CDH6 cadherin 6, type 2, K-cadherin (fetal kidney) 229947_at 3.62 0.00843 PI15 peptidase inhibitor 15 204006_s_at 3.39 0.00241 FCGR3A Fc fragment of IgG, low affinity IIIa, receptor (CD16a) 202238_s_at 3.29 0.00492 NNMT nicotinamide N-methyltransferase 202917_s_at 3.20 0.00369 S100A8 S100 calcium binding protein A8 215223_s_at 3.17 0.000516 SOD2 superoxide dismutase 2, mitochondrial 204627_s_at 3.04 0.00619 ITGB3 integrin, beta 3 (platelet glycoprotein IIIa, antigen CD61) 223217_s_at 2.99 0.00397 NFKBIZ nuclear factor of kappa light polypeptide gene enhancer in B-cells inhibitor, zeta 231067_s_at 2.97 0.00681 AKAP12 A kinase (PRKA) anchor protein 12 224917_at 2.94 0.00256 VMP1/ mir-21likely ortholog -

Content Based Search in Gene Expression Databases and a Meta-Analysis of Host Responses to Infection
Content Based Search in Gene Expression Databases and a Meta-analysis of Host Responses to Infection A Thesis Submitted to the Faculty of Drexel University by Francis X. Bell in partial fulfillment of the requirements for the degree of Doctor of Philosophy November 2015 c Copyright 2015 Francis X. Bell. All Rights Reserved. ii Acknowledgments I would like to acknowledge and thank my advisor, Dr. Ahmet Sacan. Without his advice, support, and patience I would not have been able to accomplish all that I have. I would also like to thank my committee members and the Biomed Faculty that have guided me. I would like to give a special thanks for the members of the bioinformatics lab, in particular the members of the Sacan lab: Rehman Qureshi, Daisy Heng Yang, April Chunyu Zhao, and Yiqian Zhou. Thank you for creating a pleasant and friendly environment in the lab. I give the members of my family my sincerest gratitude for all that they have done for me. I cannot begin to repay my parents for their sacrifices. I am eternally grateful for everything they have done. The support of my sisters and their encouragement gave me the strength to persevere to the end. iii Table of Contents LIST OF TABLES.......................................................................... vii LIST OF FIGURES ........................................................................ xiv ABSTRACT ................................................................................ xvii 1. A BRIEF INTRODUCTION TO GENE EXPRESSION............................. 1 1.1 Central Dogma of Molecular Biology........................................... 1 1.1.1 Basic Transfers .......................................................... 1 1.1.2 Uncommon Transfers ................................................... 3 1.2 Gene Expression ................................................................. 4 1.2.1 Estimating Gene Expression ............................................ 4 1.2.2 DNA Microarrays ...................................................... -

Microarray Bioinformatics and Its Applications to Clinical Research
Microarray Bioinformatics and Its Applications to Clinical Research A dissertation presented to the School of Electrical and Information Engineering of the University of Sydney in fulfillment of the requirements for the degree of Doctor of Philosophy i JLI ··_L - -> ...·. ...,. by Ilene Y. Chen Acknowledgment This thesis owes its existence to the mercy, support and inspiration of many people. In the first place, having suffering from adult-onset asthma, interstitial cystitis and cold agglutinin disease, I would like to express my deepest sense of appreciation and gratitude to Professors Hong Yan and David Levy for harbouring me these last three years and providing me a place at the University of Sydney to pursue a very meaningful course of research. I am also indebted to Dr. Craig Jin, who has been a source of enthusiasm and encouragement on my research over many years. In the second place, for contexts concerning biological and medical aspects covered in this thesis, I am very indebted to Dr. Ling-Hong Tseng, Dr. Shian-Sehn Shie, Dr. Wen-Hung Chung and Professor Chyi-Long Lee at Change Gung Memorial Hospital and University of Chang Gung School of Medicine (Taoyuan, Taiwan) as well as Professor Keith Lloyd at University of Alabama School of Medicine (AL, USA). All of them have contributed substantially to this work. In the third place, I would like to thank Mrs. Inge Rogers and Mr. William Ballinger for their helpful comments and suggestions for the writing of my papers and thesis. In the fourth place, I would like to thank my swim coach, Hirota Homma. -
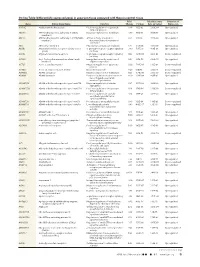
Differentially Expressed Genes in Aneurysm Tissue Compared With
On-line Table: Differentially expressed genes in aneurysm tissue compared with those in control tissue Fold False Discovery Direction of Gene Entrez Gene Name Function Change P Value Rate (q Value) Expression AADAC Arylacetamide deacetylase Positive regulation of triglyceride 4.46 1.33E-05 2.60E-04 Up-regulated catabolic process ABCA6 ATP-binding cassette, subfamily A (ABC1), Integral component of membrane 3.79 9.15E-14 8.88E-12 Up-regulated member 6 ABCC3 ATP-binding cassette, subfamily C (CFTR/MRP), ATPase activity, coupled to 6.63 1.21E-10 7.33E-09 Up-regulated member 3 transmembrane movement of substances ABI3 ABI family, member 3 Peptidyl-tyrosine phosphorylation 6.47 2.47E-05 4.56E-04 Up-regulated ACKR1 Atypical chemokine receptor 1 (Duffy blood G-protein–coupled receptor signaling 3.80 7.95E-10 4.18E-08 Up-regulated group) pathway ACKR2 Atypical chemokine receptor 2 G-protein–coupled receptor signaling 0.42 3.29E-04 4.41E-03 Down-regulated pathway ACSM1 Acyl-CoA synthetase medium-chain family Energy derivation by oxidation of 9.87 1.70E-08 6.52E-07 Up-regulated member 1 organic compounds ACTC1 Actin, ␣, cardiac muscle 1 Negative regulation of apoptotic 0.30 7.96E-06 1.65E-04 Down-regulated process ACTG2 Actin, ␥2, smooth muscle, enteric Blood microparticle 0.29 1.61E-16 2.36E-14 Down-regulated ADAM33 ADAM domain 33 Integral component of membrane 0.23 9.74E-09 3.95E-07 Down-regulated ADAM8 ADAM domain 8 Positive regulation of tumor necrosis 4.69 2.93E-04 4.01E-03 Up-regulated factor (ligand) superfamily member 11 production ADAMTS18 -

The Pathogenesis of Neurofibromatosis 1 and Neurofibromatosis 2
Chapter_3_p23-42 10/11/04 5:55 PM Page 23 3 The Pathogenesis of Neurofibromatosis 1 and Neurofibromatosis 2 The neurofibromatoses are genetic disorders. NF1 and NF2 are each caused by a mutation in a known specific gene. The quest to understand how these disorders originate and progress (their pathogenesis) received a significant boost when researchers identified the causative genes. The leading theories about the pathogenesis of NF1 and NF2 are discussed in this chapter. Because the search for the biological cause of schwanno- matosis was still underway when this book went to press, less is known about its pathogenesis (see Chapter 12). N A Search for Answers In 1990, two groups of scientists working separately located the NF1 gene on chromosome 17 and characterized its protein product, neurofi- bromin.1–3 In 1993, another two teams working separately identified the NF2 gene on chromosome 22; one named its protein “merlin”4 and the other “schwannomin.”5 Once the genes were identified, work could begin on better understanding how mutations lead to tumor formation and other manifestations. The search for answers, however, has been daunting. There is proba- bly no single answer to the question, What causes NF1 and NF2? Just as 23 Chapter_3_p23-42 10/11/04 5:55 PM Page 24 24 Neurofibromatosis these disorders cause various types of manifestations, so too there appear to be multiple molecular mechanisms at work. When trying to understand the pathogenesis of a disorder, scientists may combine two techniques that approach the question from different directions. The traditional phenotypical approaches analyze the physical manifestations of the disorders, such as what cells are involved and how they function, and then work backward to determine what gene might cause these abnormalities. -

PB #ISAG2017 1 @Isagofficial #ISAG2017 #ISAG2017
Bioinformatics · Comparative Genomics · Computational Biology Epigenetics · Functional Genomics · Genome Diversity · Geno Genome Sequencing · Immunogenetics · Integrative Geno · Microbiomics · Population Genomics · Systems Biolog Genetic Markers and Selection · Genetics and Dis Gene Editing · Bioinformatics · Comparative Computational Biology · Epigenetics · Fun Genome Diversity · Genome Sequeng Integrative Genomics · Microbiom Population Genomics · Syste Genetic Markers and Sel Genetics and Disease Gene Editing · Bi O’Brien Centre for Science Bioinformati and O’Reilly Hall, University College Dublin, Dublin, Ireland ABSTRACTMINI PROGRAMME BOOK www.isag.us/2017 PB #ISAG2017 1 @isagofficial #ISAG2017 #ISAG2017 Contents ORAL PRESENTATIONS 1 Animal Forensic Genetics Workshop 1 Applied Genetics and Genomics in Other Species of Economic Importance 3 Domestic Animal Sequencing and Annotation 5 Genome Edited Animals 8 Horse Genetics and Genomics 9 Avian Genetics and Genomics 12 Comparative MHC Genetics: Populations and Polymorphism 16 Equine Genetics and Thoroughbred Parentage Testing Workshop 19 Genetics of Immune Response and Disease Resistance 20 ISAG-FAO Genetic Diversity 24 Ruminant Genetics and Genomics 28 Animal Epigenetics 31 Cattle Molecular Markers and Parentage Testing 33 Companion Animal Genetics and Genomics 34 Microbiomes 37 Pig Genetics and Genomics 40 Novel, Groundbreaking Research/Methodology Presentation 44 Applied Genetics of Companion Animals 44 Applied Sheep and Goat Genetics 45 Comparative and Functional Genomics 47 Genetics -

(NF1) As a Breast Cancer Driver
INVESTIGATION Comparative Oncogenomics Implicates the Neurofibromin 1 Gene (NF1) as a Breast Cancer Driver Marsha D. Wallace,*,† Adam D. Pfefferle,‡,§,1 Lishuang Shen,*,1 Adrian J. McNairn,* Ethan G. Cerami,** Barbara L. Fallon,* Vera D. Rinaldi,* Teresa L. Southard,*,†† Charles M. Perou,‡,§,‡‡ and John C. Schimenti*,†,§§,2 *Department of Biomedical Sciences, †Department of Molecular Biology and Genetics, ††Section of Anatomic Pathology, and §§Center for Vertebrate Genomics, Cornell University, Ithaca, New York 14853, ‡Department of Pathology and Laboratory Medicine, §Lineberger Comprehensive Cancer Center, and ‡‡Department of Genetics, University of North Carolina, Chapel Hill, North Carolina 27514, and **Memorial Sloan-Kettering Cancer Center, New York, New York 10065 ABSTRACT Identifying genomic alterations driving breast cancer is complicated by tumor diversity and genetic heterogeneity. Relevant mouse models are powerful for untangling this problem because such heterogeneity can be controlled. Inbred Chaos3 mice exhibit high levels of genomic instability leading to mammary tumors that have tumor gene expression profiles closely resembling mature human mammary luminal cell signatures. We genomically characterized mammary adenocarcinomas from these mice to identify cancer-causing genomic events that overlap common alterations in human breast cancer. Chaos3 tumors underwent recurrent copy number alterations (CNAs), particularly deletion of the RAS inhibitor Neurofibromin 1 (Nf1) in nearly all cases. These overlap with human CNAs including NF1, which is deleted or mutated in 27.7% of all breast carcinomas. Chaos3 mammary tumor cells exhibit RAS hyperactivation and increased sensitivity to RAS pathway inhibitors. These results indicate that spontaneous NF1 loss can drive breast cancer. This should be informative for treatment of the significant fraction of patients whose tumors bear NF1 mutations. -

Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Renuka Nayak University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Computational Biology Commons, and the Genomics Commons Recommended Citation Nayak, Renuka, "Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress" (2010). Publicly Accessible Penn Dissertations. 1559. https://repository.upenn.edu/edissertations/1559 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/1559 For more information, please contact [email protected]. Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Abstract Genes interact in networks to orchestrate cellular processes. Here, we used coexpression networks based on natural variation in gene expression to study the functions and interactions of human genes. We asked how these networks change in response to stress. First, we studied human coexpression networks at baseline. We constructed networks by identifying correlations in expression levels of 8.9 million gene pairs in immortalized B cells from 295 individuals comprising three independent samples. The resulting networks allowed us to infer interactions between biological processes. We used the network to predict the functions of poorly-characterized human genes, and provided some experimental support. Examining genes implicated in disease, we found that IFIH1, a diabetes susceptibility gene, interacts with YES1, which affects glucose transport. Genes predisposing to the same diseases are clustered non-randomly in the network, suggesting that the network may be used to identify candidate genes that influence disease susceptibility. -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein