Multiwinner Analogues of the Plurality Rule: Axiomatic and Algorithmic Perspectives
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
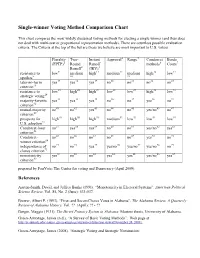
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

Minimax Is the Best Electoral System After All
1 Minimax Is the Best Electoral System After All Richard B. Darlington Department of Psychology, Cornell University Abstract When each voter rates or ranks several candidates for a single office, a strong Condorcet winner (SCW) is one who beats all others in two-way races. Among 21 electoral systems examined, 18 will sometimes make candidate X the winner even if thousands of voters would need to change their votes to make X a SCW while another candidate Y could become a SCW with only one such change. Analysis supports the intuitive conclusion that these 18 systems are unacceptable. The well-known minimax system survives this test. It fails 10 others, but there are good reasons to ignore all 10. Minimax-T adds a new tie-breaker. It surpasses competing systems on a combination of simplicity, transparency, voter privacy, input flexibility, resistance to strategic voting, and rarity of ties. It allows write-ins, machine counting except for write-ins, voters who don’t rate or rank every candidate, and tied ratings or ranks. Eleven computer simulation studies used 6 different definitions (one at a time) of the “best” candidate, and found that minimax-T always soundly beat all other tested systems at picking that candidate. A new maximum-likelihood electoral system named CMO is the theoretically optimum system under reasonable conditions, but is too complex for use in real-world elections. In computer simulations, minimax and minimax-T nearly always pick the same winners as CMO. Comments invited [email protected] Copyright Richard B. Darlington May be distributed free for non-commercial purposes 2 1. -

Multiwinner Analogues of the Plurality Rule: Axiomatic and Algorithmic Perspectives
Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16) Multiwinner Analogues of the Plurality Rule: Axiomatic and Algorithmic Perspectives Piotr Faliszewski Piotr Skowron Arkadii Slinko Nimrod Talmon AGH University University of Oxford University of Auckland TU Berlin Krakow, Poland Oxford, United Kingdom Auckland, New Zealand Berlin, Germany [email protected] [email protected] [email protected] [email protected] Abstract most desired one to the least desired one, and the goal is to pick a committee of a given size k that, in some sense, best We characterize the class of committee scoring rules that sat- matches the voters’ preferences. Naturally, the exact mean- isfy the fixed-majority criterion. In some sense, the commit- ing of the phrase “best matches” depends strongly on the ap- tee scoring rules in this class are multiwinner analogues of the single-winner Plurality rule, which is uniquely character- plication at hand, as well as on the societal conventions and ized as the only single-winner scoring rule that satisfies the understanding of fairness. For example, if we are to choose simple majority criterion. We find that, for most of the rules a size-k parliament, then it is important to guarantee pro- in our new class, the complexity of winner determination is portional representation; if the goal is to pick a group of high (i.e., the problem of computing the winners is NP-hard), products to offer to customers, then it might be important to but we also show some examples of polynomial-time winner maintain diversity of the offer; if we are to shortlist a group determination procedures, exact and approximate. -
![Arxiv:1811.06739V3 [Cs.GT] 3 Jun 2019 St](https://docslib.b-cdn.net/cover/3330/arxiv-1811-06739v3-cs-gt-3-jun-2019-st-4613330.webp)
Arxiv:1811.06739V3 [Cs.GT] 3 Jun 2019 St
MEASURING MAJORITY POWER AND VETO POWER OF VOTING RULES ALEKSEI Y. KONDRATEV AND ALEXANDER S. NESTEROV Abstract. We study voting rules with respect to how they allow or limit a majority from dominating minorities: whether a voting rule makes a majority powerful, and whether minorities can veto the candidates they do not prefer. For a given voting rule, the minimal share of voters that guarantees a victory to one of their most preferred candidates is the measure of majority power, and the minimal share of voters that allows them to veto each of their least preferred candidates is the measure of veto power. We find tight bounds on these minimal shares for voting rules that are popular in the literature and in real elections. We order these rules according to majority power and veto power. The instant-runoff voting has both the highest majority power and the highest veto power and the plurality rule has the lowest. In general, the higher the majority power of a voting rule is, the higher its veto power. The three exceptions are: voting with proportional veto power, Black’s rule, and Borda rule, which have a relatively low level of majority power and a high level of veto power and thus provide minority protection. Our results can shed light on how voting rules provide different incentives for voter participation and candidate nomination. Keywords: majority tyranny, voting system, plurality voting, two-round system, Borda count, voting paradox, minority protection, electoral participation, voting procedure, voting method, voting rule, preferential voting, electoral system JEL Classification D71, D72 Date: 03 June 2019. -

Voting Criteria
Voting Criteria 21-301 2018 30 April 1 Evaluating voting methods In the last session, we learned about different voting methods. In this session, we will focus on the criteria we use to evaluate whether voting methods are doing their jobs; that is, the criteria we use to determine if a voting system is reasonable and fair. We use all notation as in the previous set of notes. 1. Majority Criterion: If a candidate gets > 50% of the first place votes, that candidate should be the winner. This criterion is quite straightforward. If a candidate is preferred by more than half of the voters, this candidate by all rights should win the election. No other candidate could be more satisfactory for more people than the first choice of more than 50% of the voters. It is immediately obvious that the plurality method and the runoff methods will satisfy this criterion, since their method of determining the winner is fundamentally based on first place votes. For other methods, the criterion is less clear. 2. Condorcet Criterion: If a candidate wins every pairwise comparison, then that candidate should be the winner. This should remind you of the Condorcet method for choosing a winner. Of course, it is immediately obvious that if the Condorcet method produces a winner without having to resolve ties, then that candidate wins the election in that method, so clearly the Condorcet method satisfies the Condorcet criterion. However, it is not clear that the other methods will satisfy this criterion; for example, in Hare method, is it possible to eliminate a candidate that would otherwise be a Condorcet winner? 3. -

Voting and Apportionment 14.3 Apportionment Methods 14.4 Apportionment One of the Most Precious Rights in Our Democracy Is the Right to Vote
304470-ch14_pV1-V59 11/7/06 10:01 AM Page 1 CHAPTER 14 The concept of apportionment or fair division plays a vital role in the operation of corporations, politics, and educational institutions. For example, colleges and universities deal with large issues of apportionment such as the allocation of funds. In Section 14.3, you will encounter many different types of apportionment problems. David Butow/Corbis SABA 14.1 Voting Systems* 14.2 Voting Objections Voting and Apportionment 14.3 Apportionment Methods 14.4 Apportionment One of the most precious rights in our democracy is the right to vote. Objections We have elections to select the president of the United States, senators and representatives, members of the United Nations General Assembly, baseball players to be inducted into the Baseball Hall of Fame, and even “best” performers to receive Oscar and Grammy awards. There are many *Portions of this section were developed by ways of making the final decision in these elections, some simple, some Professor William Webb of Washington more complex. State University and funded by a National Electing senators and governors is simple: Have some primary elec- Science Foundation grant (DUE-9950436) tions and then a final election. The candidate with the most votes in the awarded to Professor V. S. Manoranjan. final election wins. Elections for president, as attested by the controver- sial 2000 presidential election, are complicated by our Electoral College system. Under this system, each state is allocated a number of electors selected by their political parties and equal to the number of its U.S. -

Fairness Criteria Voting Methods
VOTING METHODS FAIRNESS CRITERIA Majority Criterion – If a candidate wins by a Majority – receiving more than half of the first majority, then that candidate should win the place votes election by another method. Evaluation – If the majority winner does not win by another Plurality Method – receiving the most first place method, then this criterion is violated. If votes majority winner does win by another method, then it is not violated. Plurality with Elimination – Check first place votes for a majority. If candidate has a majority, then Head-to-head Criterion – If a candidate wins by declared winner. If not, eliminate the candidate head-to-head (pairwise) over every other with the fewest first place votes and recount. candidate, then that candidate should win the Recount. Continue until a candidate wins by a election. Evaluation – If one candidate wins over majority. all others when paired up and does not win by another method, then the criterion is violated. If Borda Count Method – Voters rank candidates on by another method, the head-to-head winner ballot. Assign 1 point to last place, 2 points to next, still wins, then the criterion is not violated. etc. Total points for each candidate. Candidate with the most points wins. Irrelevant Alternatives Criterion – A candidate wins. In a recount the only changes are that one Pairwise Comparison (Head-to-Head) Method – or more of the candidates are removed. Original Voters rank candidates on ballot. Pair up winner should win. Evaluation – A candidate candidates so each is compared with every other. drops out. Look at the 1st place votes. -

Weak Mutual Majority Criterion for Voting Rules
Weak Mutual Majority Criterion for Voting Rules Aleksei Yu. Kondratev1 and Alexander S. Nesterov2 1 Higher School of Economics, Kantemirovskaya 3, 194100 St.Petersburg, Russia [email protected] 2 Higher School of Economics, Kantemirovskaya 3, 194100 St.Petersburg, Russia [email protected] Abstract We study a novel axiom for voting rules: the weak mutual majority criterion (WMM). A voting rule satisfies WMM if whenever some k candidates receive top k ranks from a qualified majority that consists of more than q = k=(k+1) of voters, the rule selects the winner among these k candidates. WMM lies between the two standard axioms: it is stronger than the majority criterion (here k = 1 and q = 1=2) and weaker than the mutual majority criterion (MM, here for any k the size of majority is fixed q = 1=2). The widespread plurality rule satisfies WMM (but not MM). Moreover, for any k the bound q = k=(k + 1) is tight. The plurality with runoff rule, the Dodgson's rule, the Condorcet least reversal rule, the Simpson's rule, and the Young's rule satisfy WMM, for most of these rules we also find tight bounds on the size of the qualified majority q. The well-known Black's rule and its positional version do not satisfy WMM: for k > 1 its tight bound q = 1. We propose two modifications of the Black's positional rule that satisfy WMM: the qualified mutual majority rule with the tight bound q = k=(k + 1) and the convex median voting rule with the tight bound q = (3k − 1)=(4k). -

Math 017 Lecture Notes
Math 017 Lecture Notes (1.1) Preference Ballots and Schedules Election ingredients: - Set of choices/candidates to choose from - Voters whom make these choices - Ballots lets voters designate their choices (vote on something): ski/snowboard/other (both ways) - Say we only ask for one of the three choices. Define Linear Ballot - We can also design ballots that rank the choices in order of most to least preferable (define Preference Ballot) - Naturally, since there are a limited number of choices for ranking these choices, we can organize ballots by their respective rankings. Define Preference Ballot (draw it) Link this vocabulary to the vote: Preference ballot: voters are asked to rank candidates/choices Linear Ballot: plain vote (disregard lesser choice candidates) Preference Schedule: organize matching ballots Transitivity of Elimination Candidates: preferring choices A over B and B over C implies A is preferred over C o This implies relative preference of a voter is not affected by the elimination of candidate(s) o Eg. Eliminate one of the activities we’ve voted on, show new schedule (1.2) The Plurality Method Plurality Method: Only choose first place votes (most votes wins = plurality candidate) Principle of Majority Rule: In an election with 2 candidates, the candidate with the more than half the votes wins (majority candidate). Harder to accomplish when more than 2 candidates. Plurality candidate not necessarily a majority candidate Democratic Criteria Majority Criterion: If candidate X has majority (>half!) of first-place votes than X should win the election - Majority => plurality but plurality ≠> majority! - Let m = # of votes for majority, then if N = total number of votes, then m = ceil(N/2 +1) - If a majority candidate does not win the election we say the Majority Criterion has been violated (e.g. -

Fairness Criteria
There is no consistently fair way to choose the winner of an election. A voting method that is democratic and always fair is a mathematical impossibility. Arrow's Impossibility Theorem Kenneth Arrow 1952 Fairness Criteria The Fairness Criteria are things that should always be true according to common sense, but aren't always true in reality. Majority Criterion Book : If there is a choice that has a majority of the first-place votes in an election, then that choice should be the winner of the election. Translation : If someone gets the majority of the votes, then they should win. Condorcet Criterion Book : If there is a choice that in a head-to-head comparison is preferred by the voters over every other choice, then that choice should be the winner of the election. Translation : If Bob is preferred over Jon in a one-on-one comparison and Bob is preferred over Stacey and Bob is preferred over Shelley, then Bob should win the election. Monotonicity Criterion Book : If choice X is a winner of an election and, in a reelection, the only changes in the ballots are changes that only favor X, then X should remain a winner of the election. Translation : Bob wins an election. For some reason there is a reelection. Some people change their minds and rank Bob higher in their preference ballots. Bob should still win the election. Independence of Irrelevant Alternatives Criterion Book : If candidate or alternative X is a winner of an election and one (or more) of the other candidates or alternatives is removed and the ballots recounted, then X should still be a winner of the election. -

Liberal Democrats
Liberal Democrats From Wikipedia, the free encyclopedia This article is about the British political party. For similarly named parties in other countries, see Liberal Democratic Party. For the system of government, see Liberal democracy. Liberal Democrats Leader Nick Clegg MP Deputy Leader Simon Hughes MP President Tim Farron[1] MP Founded 2 March 1988 Merger of Liberal Party and SDP Preceded by SDP-Liberal Alliance 8-10 Great George Street, Headquarters London, SW1P 3AE [2] Youth wing Liberal Youth Membership (2010) 65,038[3] Liberalism Social liberalism Cultural liberalism Economic liberalism[4] Internal ideological trends: Ideology • Green politics • Green Liberalism • Civil libertarianism • Internationalism[5] • Social democracy • Community politics[6] Radical centre to Centre- Political position left[7][8][9] International Liberal International affiliation European Liberal Democrat European affiliation and Reform Party European Alliance of Liberals and Parliament Group Democrats for Europe [10] Official colours Yellow 57 / 650 House of Commons [11] 79 / 738 House of Lords [12][13] European 12 / 72 [14] Parliament London Assembly 3 / 25 Scottish Parliament 5 / 129 5 / 60 Welsh Assembly [15][16] 3,078 / 21,871 Local government [17] Website libdems.org.uk Politics of the United Kingdom Political parties Elections The Liberal Democrats are a social liberal political party in the United Kingdom which supports constitutional and electoral reform,[18] progressive taxation,[19] wealth taxation,[20] human rights laws,[21] cultural liberalism,[22] banking reform[23] and civil liberties (the party president's book of office is John Stuart Mill's 1859 On Liberty). The party was formed in 1988 by a merger of the Liberal Party and the Social Democratic Party. -

Mathematics and Social Choice Theory Topic 4 – Voting Methods
Mathematics and Social Choice Theory Topic 4 { Voting methods with more than 2 alternatives 4.1 Social choice procedures 4.2 Analysis of voting methods 4.3 Arrow's Impossibility Theorem 4.4 Cumulative voting and proportional representation 4.5 Fair majority voting - eliminate Gerrymandering 1 4.1 Social choice procedures • A group of voters are collectively trying to choose among several al- ternatives, with the social choice (the \winner") being the alternative receiving the most votes (based on a specified voting method). • How to take in the information of individual comparisons among the alternatives in the determination of the winner? • What are the intuitive criteria to judge whether a social choice is \reasonably" acceptable? Is the choice the least unpopular, broadly acceptable, winning in all one-for-one contests, etc? 2 Example 3 candidates are running for the Senate. By some means, we gather the information on the \preference order" of the voters. 22% 23% 15% 29% 7% 4% DDHHJJ HJDJHD JHJDDH Topchoice only 45% for D, 44% forHJ and 11% for ; D emerges as the "close'" winner. One-for-one contest H scores (15 + 29 + 7)% = 51% betweenHDD and scores (22 + 23 + 4)% = 49%. 3 General framework Set A whose elements are called alternatives (or candidates); a; b; c, etc. Set P whose elements are called people (or voters); p1; p2; p3, etc. • Each person p in P has arranged the alternatives in a list according to his preference. • A social choice procedure is a fixed \receipt" for choosing an alter- native based on the preference orderings of the individuals.