Metabolite Genome-Wide Association Study (Mgwas) and Gene-Metabolite
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hypopituitarism May Be an Additional Feature of SIM1 and POU3F2 Containing 6Q16 Deletions in Children with Early Onset Obesity
Open Access Journal of Pediatric Endocrinology Case Report Hypopituitarism may be an Additional Feature of SIM1 and POU3F2 Containing 6q16 Deletions in Children with Early Onset Obesity Rutteman B1, De Rademaeker M2, Gies I1, Van den Bogaert A2, Zeevaert R1, Vanbesien J1 and De Abstract Schepper J1* Over the past decades, 6q16 deletions have become recognized as a 1Department of Pediatric Endocrinology, UZ Brussel, frequent cause of the Prader-Willi-like syndrome. Involvement of SIM1 in the Belgium deletion has been linked to the development of obesity. Although SIM1 together 2Department of Genetics, UZ Brussel, Belgium with POU3F2, which is located close to the SIM1 locus, are involved in pituitary *Corresponding author: De Schepper J, Department development and function, pituitary dysfunction has not been reported frequently of Pediatric Endocrinology, UZ Brussel, Belgium in cases of 6q16.1q16.3 deletion involving both genes. Here we report on a case of a girl with typical Prader-Willi-like symptoms including early-onset Received: December 23, 2016; Accepted: February 21, hyperphagic obesity, hypotonia, short hands and feet and neuro-psychomotor 2017; Published: February 22, 2017 development delay. Furthermore, she suffered from central diabetes insipidus, central hypothyroidism and hypocortisolism. Her genetic defect is a 6q16.1q16.3 deletion, including SIM1 and POU3F2. We recommend searching for a 6q16 deletion in children with early onset hyperphagic obesity associated with biological signs of hypopituitarism and/or polyuria-polydipsia syndrome. The finding of a combined SIM1 and POU3F2 deletion should prompt monitoring for the development of hypopituitarism, if not already present at diagnosis. Keywords: 6q16 deletion; SIM1; POU3F2; Prader-Willi-like syndrome; Hypopituitarism Introduction insipidus and of some specific pituitary hormone deficiencies in children with a combined SIM1 and POU3F2 deficiency. -

Anti-Cdk8 Antibody Produced in Rabbit (C0238)
ANTI-CDK8 Developed in Rabbit, Affinity Isolated Antibody Product Number C 0238 Product Description Reagent Anti-Cyclin-Dependent Kinase 8 (CDK8) is developed in Anti-CDK8, at approximately 1 mg/ml, is supplied as a rabbit using a synthetic peptide corresponding to the solution in phosphate buffered saline, pH 7.4 containing C-terminal region (aa 451-464) of human CDK8. The 0.2% BSA and 15 mM sodium azide. antibody is purified by protein A affinity chromatography. Anti-CDK8 specifically recognizes a 54 kDa protein Precautions and Disclaimer identified as cyclin-dependent kinase 8 (CDK8). Anti- Due to the sodium azide content, a material safety data CDK8 does not crossreact with the other members of sheet (MSDS) for this product has been sent to the CDK family. It detects human, mouse and rat CDK8. It attention of the safety officer of your institution. Consult is used in immunoblotting, immunoprecipitation and the MSDS for information regarding hazardous and safe immunofluorescence applications. handling practices. Cyclin-dependent kinase 8 (CDK8) is a 464-amino acid Storage/Stability protein containing the sequence motifs and 11 Store at –20 °C. For extended storage, upon initial subdomains characteristic of a serine/threonine-specific thawing, freeze the solution in working aliquots. kinase.1 CDKs become activated through binding to Avoid repeated freezing and thawing to prevent cyclins, formation of cyclin-CDK complexes and denaturing the antibody. Storage in “frost-free” reversible phosphorylation reactions. Cyclin-CDK freezers is also not recommended. If slight complexes directly control progression through G1, S, turbidity occurs upon prolonged storage, clarify the G2 and M phases of the cell division cycle. -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Regulatory Functions of the Mediator Kinases CDK8 and CDK19 Charli B
TRANSCRIPTION 2019, VOL. 10, NO. 2, 76–90 https://doi.org/10.1080/21541264.2018.1556915 REVIEW Regulatory functions of the Mediator kinases CDK8 and CDK19 Charli B. Fant and Dylan J. Taatjes Department of Biochemistry, University of Colorado, Boulder, CO, USA ABSTRACT ARTICLE HISTORY The Mediator-associated kinases CDK8 and CDK19 function in the context of three additional Received 19 September 2018 proteins: CCNC and MED12, which activate CDK8/CDK19 kinase function, and MED13, which Revised 13 November 2018 enables their association with the Mediator complex. The Mediator kinases affect RNA polymerase Accepted 20 November 2018 II (pol II) transcription indirectly, through phosphorylation of transcription factors and by control- KEYWORDS ling Mediator structure and function. In this review, we discuss cellular roles of the Mediator Mediator kinase; enhancer; kinases and mechanisms that enable their biological functions. We focus on sequence-specific, transcription; RNA DNA-binding transcription factors and other Mediator kinase substrates, and how CDK8 or CDK19 polymerase II; chromatin may enable metabolic and transcriptional reprogramming through enhancers and chromatin looping. We also summarize Mediator kinase inhibitors and their therapeutic potential. Throughout, we note conserved and divergent functions between yeast and mammalian CDK8, and highlight many aspects of kinase module function that remain enigmatic, ranging from potential roles in pol II promoter-proximal pausing to liquid-liquid phase separation. Introduction and MED13L associate in a mutually exclusive fash- ion with MED12 and MED13 [12], and their poten- The CDK8 kinase exists in a 600 kDa complex tial functional distinctions remain unclear. known as the CDK8 module, which consists of four CDK8 is considered both an oncogene [13–15] proteins (CDK8, CCNC, MED12, MED13). -

Structure and Mechanism of the RNA Polymerase II Transcription Machinery
Downloaded from genesdev.cshlp.org on October 9, 2021 - Published by Cold Spring Harbor Laboratory Press REVIEW Structure and mechanism of the RNA polymerase II transcription machinery Allison C. Schier and Dylan J. Taatjes Department of Biochemistry, University of Colorado, Boulder, Colorado 80303, USA RNA polymerase II (Pol II) transcribes all protein-coding ingly high resolution, which has rapidly advanced under- genes and many noncoding RNAs in eukaryotic genomes. standing of the molecular basis of Pol II transcription. Although Pol II is a complex, 12-subunit enzyme, it lacks Structural biology continues to transform our under- the ability to initiate transcription and cannot consistent- standing of complex biological processes because it allows ly transcribe through long DNA sequences. To execute visualization of proteins and protein complexes at or near these essential functions, an array of proteins and protein atomic-level resolution. Combined with mutagenesis and complexes interact with Pol II to regulate its activity. In functional assays, structural data can at once establish this review, we detail the structure and mechanism of how enzymes function, justify genetic links to human dis- over a dozen factors that govern Pol II initiation (e.g., ease, and drive drug discovery. In the past few decades, TFIID, TFIIH, and Mediator), pausing, and elongation workhorse techniques such as NMR and X-ray crystallog- (e.g., DSIF, NELF, PAF, and P-TEFb). The structural basis raphy have been complemented by cryoEM, cross-linking for Pol II transcription regulation has advanced rapidly mass spectrometry (CXMS), and other methods. Recent in the past decade, largely due to technological innova- improvements in data collection and imaging technolo- tions in cryoelectron microscopy. -

Highly Frequent Allelic Loss of Chromosome 6Q16-23 in Osteosarcoma: Involvement of Cyclin C in Osteosarcoma
1153-1158 5/11/06 16:31 Page 1153 INTERNATIONAL JOURNAL OF MOLECULAR MEDICINE 18: 1153-1158, 2006 Highly frequent allelic loss of chromosome 6q16-23 in osteosarcoma: Involvement of cyclin C in osteosarcoma NORIHIDE OHATA1, SACHIO ITO2, AKI YOSHIDA1, TOSHIYUKI KUNISADA1, KUNIHIKO NUMOTO1, YOSHIMI JITSUMORI2, HIROTAKA KANZAKI2, TOSHIFUMI OZAKI1, KENJI SHIMIZU2 and MAMORU OUCHIDA2 1Science of Functional Recovery and Reconstruction, 2Department of Molecular Genetics, Graduate School of Medicine, Dentistry and Pharmaceutical Sciences, Okayama University, Shikata-cho 2-5-1, Okayama 700-8558, Japan Received June 13, 2006; Accepted August 14, 2006 Abstract. The molecular pathogenesis of osteosarcoma is very rearrangements (1,2). It has been reported that both RB1 and complicated and associated with chaotic abnormalities on many TP53 pathways are inactivated, and the regulation of cell cycle chromosomal arms. We analyzed 12 cases of osteosarcomas is impaired in most osteosarcomas (1). For example, deletion/ with comparative genomic hybridization (CGH) to identify mutation of the CDKN2A gene encoding both p16INK4A and chromosomal imbalances, and detected highly frequent p14ARF on 9p21 (3-5), amplification of the CDK4 (6), CCND1, chromosomal alterations in chromosome 6q, 8p, 10p and MDM2 genes (4), and other aberrations related to inactivation 10q. To define the narrow rearranged region on chromosome 6 of these pathways have been found. Tumor suppressor genes with higher resolution, loss of heterozygosity (LOH) analysis (TSGs) are suspected to be involved in tumorigenesis of was performed with 21 microsatellite markers. Out of 31 cases, osteosarcoma. Loss of heterozygosity (LOH) studies have 23 cases (74%) showed allelic loss at least with one marker on detected frequent allelic loss at 3q, 13q, 17p and 18q (7). -

Karla Alejandra Vizcarra Zevallos Análise Da Função De Genes
Karla Alejandra Vizcarra Zevallos Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Dissertação apresentada ao Pro- grama de Pós‐Graduação Inter- unidades em Biotecnologia USP/ Instituto Butantan/ IPT, para obtenção do Título de Mestre em Ciências. São Paulo 2017 Karla Alejandra Vizcarra Zevallos Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Dissertação apresentada ao Pro- grama de Pós‐Graduação Inter- unidades em Biotecnologia do Instituto de Ciências Biomédicas USP/ Instituto Butantan/ IPT, para obtenção do Título de Mestre em Ciências. Área de concentração: Biotecnologia Orientadora: Profa. Dra. Lygia da Veiga Pereira Carramaschi Versão corrigida. A versão original eletrônica encontra-se disponível tanto na Biblioteca do ICB quanto na Biblioteca Digital de Teses e Dissertações da USP (BDTD) São Paulo 2017 UNIVERSIDADE DE SÃO PAULO Programa de Pós-Graduação Interunidades em Biotecnologia Universidade de São Paulo, Instituto Butantan, Instituto de Pesquisas Tecnológicas Candidato(a): Karla Alejandra Vizcarra Zevallos Título da Dissertação: Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Orientador: Profa. Dra. Lygia da Veiga Pereira Carramaschi A Comissão Julgadora dos trabalhos de Defesa da Dissertação de Mestrado, em sessão pública realizada a ........./......../.........., considerou o(a) candidato(a): ( ) Aprovado(a) ( ) Reprovado(a) Examinador(a): Assinatura: .............................................................................. -

Improving the Detection of Genomic Rearrangements in Short Read Sequencing Data
Improving the detection of genomic rearrangements in short read sequencing data Daniel Lee Cameron orcid.org/0000-0002-0951-7116 Doctor of Philosophy July 2017 Department of Medical Biology, University of Melbourne Bioinformatics Division, Walter and Eliza Hall Institute of Medical Research Submitted in total fulfilment of the requirements of the degree of Doctor of Philosophy Produced on archival quality paper Page i Abstract Genomic rearrangements, also known as structural variants, play a significant role in the development of cancer and in genetic disorders. With the bulk of genetic studies focusing on single nucleotide variants and small insertions and deletions, structural variants are often overlooked. In part this is due to the increased complexity of analysis required, but is also due to the increased difficulty of detection. The identification of genomic rearrangements using massively parallel sequencing remains a major challenge. To address this, I have developed the Genome Rearrangement Identification Software Suite (GRIDSS). In this thesis, I show that high sensitivity and specificity can be achieved by performing reference-guided assembly prior to variant calling and incorporating the results of this assembly into the variant calling process itself. Utilising a novel genome-wide break-end assembly approach, GRIDSS halves the false discovery rate compared to other recent methods on human cell line data. A comparison of assembly approaches reveals that incorporating read alignment information into a positional de Bruijn graph improves assembly quality compared to traditional de Bruijn graph assembly. To characterise the performance of structural variant calling software, I have performed the most comprehensive benchmarking of structural variant calling software to date. -

The Pennsylvania State University the Graduate School Department
The Pennsylvania State University The Graduate School Department of Pharmacology ALTERATIONS IN GENE EXPRESSION AS A RESPONSE OF TUMOR CELLS TO STRESSES A Dissertation in Pharmacology by Kathryn Joyce Huber-Keener 2012 Kathryn Joyce Huber-Keener Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy May 2013 The dissertation of Kathryn Joyce Huber-Keener was reviewed and approved* by the following: Jin-Ming Yang Professor of Pharmacology Dissertation Advisor Chair of Committee Willard M. Freeman Associate Professor of Pharmacology Rongling Wu Professor of Statistics Robert G. Levenson Professor of Pharmacology Andrea Manni Professor of Medicine Jong K. Yun Director of the Pharmacology Graduate Program *Signatures are on file in the Graduate School ii ABSTRACT Solid cancers are the 2nd leading cause of death in adults in the United States. Understanding the mechanisms by which cancer cells survive under stress is pivotal to decreasing this statistic. Cancer cells are constantly under stress, a factor which needs to be taken into consideration during the treatment of solid cancers. Both intrinsic and extrinsic stresses impact the development and progression of neoplasms, down to the level of individual proteins and genes. Stresses like nutrient deficiency, hypoxia, acidity, and the immune response are present during normal tumor growth and throughout treatment. Tumor cells that survive these stresses are more adept at surviving hostile conditions and are more resistant to current therapies. Stress, therefore, shapes the tumor cell population. Gene expression alterations are the driving feature behind the adaptive ability of cancer cells to these stresses, and therefore, careful examination of these gene expression changes must be undertaken in order to develop effective therapies for solid cancers. -

Metabolites OH
H OH metabolites OH Article Metabolite Genome-Wide Association Study (mGWAS) and Gene-Metabolite Interaction Network Analysis Reveal Potential Biomarkers for Feed Efficiency in Pigs Xiao Wang and Haja N. Kadarmideen * Quantitative Genomics, Bioinformatics and Computational Biology Group, Department of Applied Mathematics and Computer Science, Technical University of Denmark, Richard Petersens Plads, Building 324, 2800 Kongens Lyngby, Denmark; [email protected] * Correspondence: [email protected] Received: 1 April 2020; Accepted: 11 May 2020; Published: 15 May 2020 Abstract: Metabolites represent the ultimate response of biological systems, so metabolomics is considered the link between genotypes and phenotypes. Feed efficiency is one of the most important phenotypes in sustainable pig production and is the main breeding goal trait. We utilized metabolic and genomic datasets from a total of 108 pigs from our own previously published studies that involved 59 Duroc and 49 Landrace pigs with data on feed efficiency (residual feed intake (RFI)), genotype (PorcineSNP80 BeadChip) data, and metabolomic data (45 final metabolite datasets derived from LC-MS system). Utilizing these datasets, our main aim was to identify genetic variants (single-nucleotide polymorphisms (SNPs)) that affect 45 different metabolite concentrations in plasma collected at the start and end of the performance testing of pigs categorized as high or low in their feed efficiency (based on RFI values). Genome-wide significant genetic variants could be then used as potential genetic or biomarkers in breeding programs for feed efficiency. The other objective was to reveal the biochemical mechanisms underlying genetic variation for pigs’ feed efficiency. In order to achieve these objectives, we firstly conducted a metabolite genome-wide association study (mGWAS) based on mixed linear models and found 152 genome-wide significant SNPs (p-value < 1.06 10 6) in association with 17 metabolites that included 90 significant SNPs annotated × − to 52 genes. -
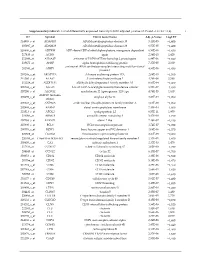
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at -

Bedeutung Und Charakterisierung Der 6Q-Deletion Beim Prostatakarzinom
Bedeutung und Charakterisierung der 6q-Deletion beim Prostatakarzinom Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften (Dr. rer. nat.) am Department Biologie der Fakultät Mathematik, Informatik und Naturwissenschaften der Universität Hamburg Vorgelegt von Martina Kluth Heide-Holstein Hamburg 2015 Gutachter der Dissertation Prof. Dr. Guido Sauter Prof. Dr. Thomas Dobner Datum der Disputation: 22.01.2016 Inhaltsverzeichnis 1Einleitung 1 1.1 Epidemiologie und Ätiologie des Prostatakarzinoms .............. 1 1.2 Früherkennung und Primärdiagnostik des Prostatakarzinoms .............................. 2 1.2.1 Digitale rektale Untersuchung (DRU) .................. 3 1.2.2 Prostataspezifisches Antigen (PSA) ................... 3 1.2.3 Stanzbiopsie der Prostata ........................ 5 1.3 Pathologie und Stadieneinteilung des Prostatakarzinoms ................................ 5 1.4 Therapie des Prostatakarzinoms ......................... 7 1.5 Prognosemarker beim Prostatakarzinom .................... 11 1.6 Genomische Veränderungen beim Prostatakarzinom .............. 12 1.6.1 Punktmutation .............................. 12 1.6.2 Chromosomale Zugewinne ........................ 12 1.6.3 Translokationen .............................. 13 1.6.4 Deletionen ................................. 14 1.7 Die 6q-Deletion beim Prostatakarzinom ..................... 15 1.7.1 Prävalenz der 6q-Deletion beim Prostatakarzinom ........... 15 1.7.2 Assoziation der 6q-Deletion mit dem Tumorphänotyp und der Progno- se des Prostatakarzinoms ........................