Improving the Detection of Genomic Rearrangements in Short Read Sequencing Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Hypopituitarism May Be an Additional Feature of SIM1 and POU3F2 Containing 6Q16 Deletions in Children with Early Onset Obesity
Open Access Journal of Pediatric Endocrinology Case Report Hypopituitarism may be an Additional Feature of SIM1 and POU3F2 Containing 6q16 Deletions in Children with Early Onset Obesity Rutteman B1, De Rademaeker M2, Gies I1, Van den Bogaert A2, Zeevaert R1, Vanbesien J1 and De Abstract Schepper J1* Over the past decades, 6q16 deletions have become recognized as a 1Department of Pediatric Endocrinology, UZ Brussel, frequent cause of the Prader-Willi-like syndrome. Involvement of SIM1 in the Belgium deletion has been linked to the development of obesity. Although SIM1 together 2Department of Genetics, UZ Brussel, Belgium with POU3F2, which is located close to the SIM1 locus, are involved in pituitary *Corresponding author: De Schepper J, Department development and function, pituitary dysfunction has not been reported frequently of Pediatric Endocrinology, UZ Brussel, Belgium in cases of 6q16.1q16.3 deletion involving both genes. Here we report on a case of a girl with typical Prader-Willi-like symptoms including early-onset Received: December 23, 2016; Accepted: February 21, hyperphagic obesity, hypotonia, short hands and feet and neuro-psychomotor 2017; Published: February 22, 2017 development delay. Furthermore, she suffered from central diabetes insipidus, central hypothyroidism and hypocortisolism. Her genetic defect is a 6q16.1q16.3 deletion, including SIM1 and POU3F2. We recommend searching for a 6q16 deletion in children with early onset hyperphagic obesity associated with biological signs of hypopituitarism and/or polyuria-polydipsia syndrome. The finding of a combined SIM1 and POU3F2 deletion should prompt monitoring for the development of hypopituitarism, if not already present at diagnosis. Keywords: 6q16 deletion; SIM1; POU3F2; Prader-Willi-like syndrome; Hypopituitarism Introduction insipidus and of some specific pituitary hormone deficiencies in children with a combined SIM1 and POU3F2 deficiency. -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Gene Expression Profiles Complement the Analysis of Genomic Modifiers of the Clinical Onset of Huntington Disease
bioRxiv preprint doi: https://doi.org/10.1101/699033; this version posted July 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Gene expression profiles complement the analysis of genomic modifiers of the clinical onset of Huntington disease Galen E.B. Wright1,2,3; Nicholas S. Caron1,2,3; Bernard Ng1,2,4; Lorenzo Casal1,2,3; Xiaohong Xu5; Jolene Ooi5; Mahmoud A. Pouladi5,6,7; Sara Mostafavi1,2,4; Colin J.D. Ross3,7 and Michael R. Hayden1,2,3* 1Centre for Molecular Medicine and Therapeutics, Vancouver, British Columbia, Canada; 2Department of Medical Genetics, University of British Columbia, Vancouver, British Columbia, Canada; 3BC Children’s Hospital Research Institute, Vancouver, British Columbia, Canada; 4Department of Statistics, University of British Columbia, Vancouver, British Columbia, Canada; 5Translational Laboratory in Genetic Medicine (TLGM), Agency for Science, Technology and Research (A*STAR), Singapore; 6Department of Medicine, Yong Loo Lin School of Medicine, National University of Singapore, Singapore; 7Department of Physiology, Yong Loo Lin School of Medicine, National University of Singapore, Singapore; 8Faculty of Pharmaceutical Sciences, University of British Columbia, Vancouver, British Columbia, Canada; *Corresponding author ABSTRACT Huntington disease (HD) is a neurodegenerative disorder that is caused by a CAG repeat expansion in the HTT gene. In an attempt to identify genomic modifiers that contribute towards the age of onset of HD, we performed a transcriptome wide association study assessing heritable differences in genetically determined expression in diverse tissues, employing genome wide data from over 4,000 patients. -

Karla Alejandra Vizcarra Zevallos Análise Da Função De Genes
Karla Alejandra Vizcarra Zevallos Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Dissertação apresentada ao Pro- grama de Pós‐Graduação Inter- unidades em Biotecnologia USP/ Instituto Butantan/ IPT, para obtenção do Título de Mestre em Ciências. São Paulo 2017 Karla Alejandra Vizcarra Zevallos Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Dissertação apresentada ao Pro- grama de Pós‐Graduação Inter- unidades em Biotecnologia do Instituto de Ciências Biomédicas USP/ Instituto Butantan/ IPT, para obtenção do Título de Mestre em Ciências. Área de concentração: Biotecnologia Orientadora: Profa. Dra. Lygia da Veiga Pereira Carramaschi Versão corrigida. A versão original eletrônica encontra-se disponível tanto na Biblioteca do ICB quanto na Biblioteca Digital de Teses e Dissertações da USP (BDTD) São Paulo 2017 UNIVERSIDADE DE SÃO PAULO Programa de Pós-Graduação Interunidades em Biotecnologia Universidade de São Paulo, Instituto Butantan, Instituto de Pesquisas Tecnológicas Candidato(a): Karla Alejandra Vizcarra Zevallos Título da Dissertação: Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Orientador: Profa. Dra. Lygia da Veiga Pereira Carramaschi A Comissão Julgadora dos trabalhos de Defesa da Dissertação de Mestrado, em sessão pública realizada a ........./......../.........., considerou o(a) candidato(a): ( ) Aprovado(a) ( ) Reprovado(a) Examinador(a): Assinatura: .............................................................................. -

SUPPLEMENTARY APPENDIX MLL Partial Tandem Duplication Leukemia Cells Are Sensitive to Small Molecule DOT1L Inhibition
SUPPLEMENTARY APPENDIX MLL partial tandem duplication leukemia cells are sensitive to small molecule DOT1L inhibition Michael W.M. Kühn, 1* Michael J. Hadler, 1* Scott R. Daigle, 2 Richard P. Koche, 1 Andrei V. Krivtsov, 1 Edward J. Olhava, 2 Michael A. Caligiuri, 3 Gang Huang, 4 James E. Bradner, 5 Roy M. Pollock, 2 and Scott A. Armstrong 1,6 1Human Oncology and Pathogenesis Program, Memorial Sloan Kettering Cancer Center, New York, NY; 2Epizyme, Inc., Cambridge, MA; 3The Compre - hensive Cancer Center, The Ohio State University, Columbus, OH; 4Divisions of Experimental Hematology and Cancer Biology, Cincinnati Children's Hospital Medical Center, Cincinnati, OH; 5Department of Medical Oncology, Dana-Farber Cancer Institute, Harvard Medical School, Boston, MA; 6Department of Pe - diatrics, Memorial Sloan Kettering Cancer Center, New York, NY, USA Correspondence: [email protected] doi:10.3324/haematol.2014.115337 SUPPLEMENTAL METHODS, TABLES, RESULTS, AND FIGURE LEGENDS MLL-PTD leukemia cells are sensitive to small molecule DOT1L inhibition Michael J. Hadler1,*, Michael W.M. Kühn1,*, Scott R. Daigle3, Richard P. Koche1, Andrei V. Krivtsov1, Edward J. Olhava3, Michael A. Caligiuri4, Gang Huang5, James E. Bradner6, Roy M. Pollock3, and Scott A. Armstrong1,2 1Human Oncology and Pathogenesis Program, Memorial Sloan Kettering Cancer Center, New York, NY, USA; 2Department of Pediatrics, Memorial Sloan Kettering Cancer Center, New York, NY, USA; 3Epizyme, Inc., Cambridge, MA, USA; 4The Comprehensive Cancer Center, The Ohio State University, Columbus, OH, USA; 5Divisions of Experimental Hematology and Cancer Biology, Cincinnati Children's Hospital Medical Center, Cincinnati, OH, USA; 6Department of Medical Oncology, Dana-Farber Cancer Institute, Harvard Medical School, Boston, MA, USA. -

Identification of Genetic Factors Underpinning Phenotypic Heterogeneity in Huntington’S Disease and Other Neurodegenerative Disorders
Identification of genetic factors underpinning phenotypic heterogeneity in Huntington’s disease and other neurodegenerative disorders. By Dr Davina J Hensman Moss A thesis submitted to University College London for the degree of Doctor of Philosophy Department of Neurodegenerative Disease Institute of Neurology University College London (UCL) 2020 1 I, Davina Hensman Moss confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indicated in the thesis. Collaborative work is also indicated in this thesis. Signature: Date: 2 Abstract Neurodegenerative diseases including Huntington’s disease (HD), the spinocerebellar ataxias and C9orf72 associated Amyotrophic Lateral Sclerosis / Frontotemporal dementia (ALS/FTD) do not present and progress in the same way in all patients. Instead there is phenotypic variability in age at onset, progression and symptoms. Understanding this variability is not only clinically valuable, but identification of the genetic factors underpinning this variability has the potential to highlight genes and pathways which may be amenable to therapeutic manipulation, hence help find drugs for these devastating and currently incurable diseases. Identification of genetic modifiers of neurodegenerative diseases is the overarching aim of this thesis. To identify genetic variants which modify disease progression it is first necessary to have a detailed characterization of the disease and its trajectory over time. In this thesis clinical data from the TRACK-HD studies, for which I collected data as a clinical fellow, was used to study disease progression over time in HD, and give subjects a progression score for subsequent analysis. In this thesis I show blood transcriptomic signatures of HD status and stage which parallel HD brain and overlap with Alzheimer’s disease brain. -

Noncoding Rnas As Novel Pancreatic Cancer Targets
NONCODING RNAS AS NOVEL PANCREATIC CANCER TARGETS by Amy Makler A Thesis Submitted to the Faculty of The Charles E. Schmidt College of Science In Partial Fulfillment of the Requirements for the Degree of Master of Science Florida Atlantic University Boca Raton, FL August 2018 Copyright 2018 by Amy Makler ii ACKNOWLEDGEMENTS I would first like to thank Dr. Narayanan for his continuous support, constant encouragement, and his gentle, but sometimes critical, guidance throughout the past two years of my master’s education. His faith in my abilities and his belief in my future success ensured I continue down this path of research. Working in Dr. Narayanan’s lab has truly been an unforgettable experience as well as a critical step in my future endeavors. I would also like to extend my gratitude to my committee members, Dr. Binninger and Dr. Jia, for their support and suggestions regarding my thesis. Their recommendations added a fresh perspective that enriched our initial hypothesis. They have been indispensable as members of my committee, and I thank them for their contributions. My parents have been integral to my successes in life and their support throughout my education has been crucial. They taught me to push through difficulties and encouraged me to pursue my interests. Thank you, mom and dad! I would like to thank my boyfriend, Joshua Disatham, for his assistance in ensuring my writing maintained a logical progression and flow as well as his unwavering support. He was my rock when the stress grew unbearable and his encouraging words kept me pushing along. -

Metabolites OH
H OH metabolites OH Article Metabolite Genome-Wide Association Study (mGWAS) and Gene-Metabolite Interaction Network Analysis Reveal Potential Biomarkers for Feed Efficiency in Pigs Xiao Wang and Haja N. Kadarmideen * Quantitative Genomics, Bioinformatics and Computational Biology Group, Department of Applied Mathematics and Computer Science, Technical University of Denmark, Richard Petersens Plads, Building 324, 2800 Kongens Lyngby, Denmark; [email protected] * Correspondence: [email protected] Received: 1 April 2020; Accepted: 11 May 2020; Published: 15 May 2020 Abstract: Metabolites represent the ultimate response of biological systems, so metabolomics is considered the link between genotypes and phenotypes. Feed efficiency is one of the most important phenotypes in sustainable pig production and is the main breeding goal trait. We utilized metabolic and genomic datasets from a total of 108 pigs from our own previously published studies that involved 59 Duroc and 49 Landrace pigs with data on feed efficiency (residual feed intake (RFI)), genotype (PorcineSNP80 BeadChip) data, and metabolomic data (45 final metabolite datasets derived from LC-MS system). Utilizing these datasets, our main aim was to identify genetic variants (single-nucleotide polymorphisms (SNPs)) that affect 45 different metabolite concentrations in plasma collected at the start and end of the performance testing of pigs categorized as high or low in their feed efficiency (based on RFI values). Genome-wide significant genetic variants could be then used as potential genetic or biomarkers in breeding programs for feed efficiency. The other objective was to reveal the biochemical mechanisms underlying genetic variation for pigs’ feed efficiency. In order to achieve these objectives, we firstly conducted a metabolite genome-wide association study (mGWAS) based on mixed linear models and found 152 genome-wide significant SNPs (p-value < 1.06 10 6) in association with 17 metabolites that included 90 significant SNPs annotated × − to 52 genes. -

Downloaded from Here
bioRxiv preprint doi: https://doi.org/10.1101/017566; this version posted November 19, 2015. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 1 Testing for ancient selection using cross-population allele 2 frequency differentiation 1;∗ 3 Fernando Racimo 4 1 Department of Integrative Biology, University of California, Berkeley, CA, USA 5 ∗ E-mail: [email protected] 6 1 Abstract 7 A powerful way to detect selection in a population is by modeling local allele frequency changes in a 8 particular region of the genome under scenarios of selection and neutrality, and finding which model is 9 most compatible with the data. Chen et al. [2010] developed a composite likelihood method called XP- 10 CLR that uses an outgroup population to detect departures from neutrality which could be compatible 11 with hard or soft sweeps, at linked sites near a beneficial allele. However, this method is most sensitive 12 to recent selection and may miss selective events that happened a long time ago. To overcome this, 13 we developed an extension of XP-CLR that jointly models the behavior of a selected allele in a three- 14 population tree. Our method - called 3P-CLR - outperforms XP-CLR when testing for selection that 15 occurred before two populations split from each other, and can distinguish between those events and 16 events that occurred specifically in each of the populations after the split. -
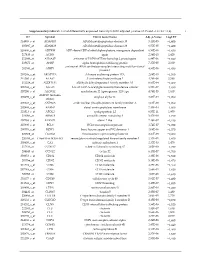
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at -

Towards Personalized Medicine in Psychiatry: Focus on Suicide
TOWARDS PERSONALIZED MEDICINE IN PSYCHIATRY: FOCUS ON SUICIDE Daniel F. Levey Submitted to the faculty of the University Graduate School in partial fulfillment of the requirements for the degree Doctor of Philosophy in the Program of Medical Neuroscience, Indiana University April 2017 ii Accepted by the Graduate Faculty, Indiana University, in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Andrew J. Saykin, Psy. D. - Chair ___________________________ Alan F. Breier, M.D. Doctoral Committee Gerry S. Oxford, Ph.D. December 13, 2016 Anantha Shekhar, M.D., Ph.D. Alexander B. Niculescu III, M.D., Ph.D. iii Dedication This work is dedicated to all those who suffer, whether their pain is physical or psychological. iv Acknowledgements The work I have done over the last several years would not have been possible without the contributions of many people. I first need to thank my terrific mentor and PI, Dr. Alexander Niculescu. He has continuously given me advice and opportunities over the years even as he has suffered through my many mistakes, and I greatly appreciate his patience. The incredible passion he brings to his work every single day has been inspirational. It has been an at times painful but often exhilarating 5 years. I need to thank Helen Le-Niculescu for being a wonderful colleague and mentor. I learned a lot about organization and presentation working alongside her, and her tireless work ethic was an excellent example for a new graduate student. I had the pleasure of working with a number of great people over the years. Mikias Ayalew showed me the ropes of the lab and began my understanding of the power of algorithms.