Veritas Cluster Server User's Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cluster Server Installation Guide
Veritas™ Cluster Server Installation Guide Solaris 5.0 N18534F Veritas Cluster Server Installation Guide Copyright © 2006 Symantec Corporation. All rights reserved. Veritas Cluster Server 5.0 Symantec, the Symantec logo, Veritas are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THIS DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID, SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be “commercial computer software” and “commercial computer software documentation” as defined in FAR Sections 12.212 and DFARS Section 227.7202. Symantec Corporation 20330 Stevens Creek Blvd. Cupertino, CA 95014 www.symantec.com Third-party legal notices Third-party software may be recommended, distributed, embedded, or bundled with this Symantec product. Such third-party software is licensed separately by its copyright holder. All third-party copyrights associated with this product are listed in the accompanying release notes. -

VERITAS Cluster Server 4.0 Installation Guide for Linux
VERITAS Cluster Server 4.0 Installation Guide Linux N10923H August 2004 Disclaimer The information contained in this publication is subject to change without notice. VERITAS Software Corporation makes no warranty of any kind with regard to this manual, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. VERITAS Software Corporation shall not be liable for errors contained herein or for incidental or consequential damages in connection with the furnishing, performance, or use of this manual. VERITAS Legal Notice Copyright © 1998-2004 VERITAS Software Corporation. All rights reserved. VERITAS, the VERITAS logo, VERITAS Cluster Server, and all other VERITAS product names and slogans are trademarks or registered trademarks of VERITAS Software Corporation. VERITAS and the VERITAS logo, Reg. U.S. Pat. & Tm. Off. Other product names and/or slogans mentioned herein may be trademarks or registered trademarks of their respective companies. VERITAS Software Corporation 350 Ellis Street Mountain View, CA 94043 USA Phone 650–527–8000 Fax 650–527–2908 www.veritas.com Third-Party Copyrights Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. “License” shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. “Licensor” shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. “Legal Entity” shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. -

Symantec™ Cluster Server 6.2.1 Installation Guide - Linux
Symantec™ Cluster Server 6.2.1 Installation Guide - Linux Platform Release OL7 UEK R3 April 2015 Symantec™ Cluster Server Installation Guide The software described in this book is furnished under a license agreement and may be used only in accordance with the terms of the agreement. Product version: 6.2.1 Document version: 6.2.1 Rev 0 Legal Notice Copyright © 2015 Symantec Corporation. All rights reserved. Symantec, the Symantec Logo, the Checkmark Logo, Veritas, Veritas Storage Foundation, CommandCentral, NetBackup, Enterprise Vault, and LiveUpdate are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be commercial computer software as defined in FAR 12.212 and subject to restricted rights as defined in FAR Section 52.227-19 "Commercial Computer Software - Restricted Rights" and DFARS 227.7202, "Rights in Commercial Computer Software or Commercial Computer Software Documentation", as applicable, and any successor regulations, whether delivered by Symantec as on premises or hosted services. -
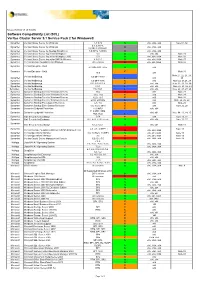
Wxrt VCS for Windows 5.1 SCL Based GA Version
Release Revision 1.6 25 Oct 2012 Software Compatibility List (SCL) Veritas Cluster Server 5.1 Service Pack 2 for Windows® Symantec Veritas Cluster Server for Windows 5.1 SP2 S x86, IA64, x64 Note 01, 02 5.1, 5.1AP1, Symantec Veritas Cluster Server for Windows U x86, IA64, x64 5.1SP1,5.1SP1AP1 Symantec Veritas Cluster Server for NetApp SnapMirror 5.0 RP1a, 5.0RP2 U x86, IA64, x64 Symantec Veritas Cluster Server Agent for Websphere 5.1 S x86, x64 Note 05 Symantec Veritas Cluster Server Agent for Websphere MQ 5.0 S x86, x64, IA64 Note 06 Symantec Veritas Cluster Server Agent for SAP NetWeaver 4.3.01.0 S x86, x64, IA64 Note 07 Symantec Veritas Storage Foundation for Windows All versions X x86, x64, IA64 Note 02 Symantec Veritas Enterprise Vault 8.0 SP1-SP5, 9.0.x S x86 Symantec Veritas Enterprise Vault C Note 31 10.0 x86 Note 21, 22, 23, 28, Veritas NetBackup 6.0 MP1-MP3 Symantec L x86 29 Symantec Veritas NetBackup 6.0 MP4-MP6 C x86 Note 22, 23,28, 29 Symantec Veritas NetBackup 6.5, 6.5.2-6.5.4 C x86, x64 Note 22, 23, 28, 29 Symantec Veritas NetBackup 6.5.1 L x86, x64 Note 22, 23, 28, 29 Symantec Veritas NetBackup 7.0, 7.0.1 L x86, x64 Note 22, 23, 27, 28 Symantec Symantec Backup Exec for Windows Servers 10.x X x86 Note 28 Symantec Symantec Backup Exec for Windows Servers 11.0, 11d C x86 Note 28 Symantec Symantec Backup Exec for Windows Servers 12.0, 12.5 C x86 Note 28 Symantec Symantec Backup Exec for Windows Servers 2010, 2010 R2 L x86 Note 24, 25, 28 Symantec Symantec Backup Exec System Recovery 6.5, 7.0 C x86 Note 28 Symantec Symantec -

Cluster Server 5.0 MP2 Release Notes
Veritas™ Cluster Server Release Notes HP-UX 5.0 Maintenance Pack 2 Veritas Cluster Server Release Notes The software described in this book is furnished under a license agreement and may be used only in accordance with the terms of the agreement. Product version: 5.0 MP2 Document version: 5.0MP2.0 Legal Notice Copyright © 2009 Symantec Corporation. All rights reserved. Symantec, the Symantec Logo, Storage Foundation and Veritas are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. This Symantec product may contain third party software for which Symantec is required to provide attribution to the third party (“Third Party Programs”). Some of the Third Party Programs are available under open source or free software licenses. The License Agreement accompanying the Software does not alter any rights or obligations you may have under those open source or free software licenses. Please see the Third Party Legal Notice Appendix to this Documentation or TPIP ReadMe File accompanying this Symantec product for more information on the Third Party Programs. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. -
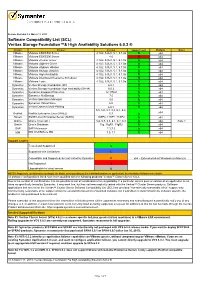
Wxrt VCS for Windows 5.1 SCL Based GA Version
Release Revision 1.6 March 11, 2013 Software Compatibility List (SCL) Veritas Storage Foundation™& High Availability Solutions 6.0.2 ® Vendor Product Version Support Level Platform Notes VMware VMware ESX/ESXi Server 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware ESX/ESXi Server 4.0 X x64 VMware VMware vCenter server 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware vSphere Client 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware vSphere vMotion 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware Storage vMotion 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware High Availability 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware Distributed Resource Scheduler 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 VMware VMware Tools 4.1U2, 5.0U1, 5.1, 5.1.0a S x64 Symantec Veritas Storage Foundation (SF) 6.0.1 S x64 Symantec Veritas Storage Foundation High Availability (SFHA) 6.0.2 S x64 Symantec Symantec Endpoint Protection 12.1 RU2 S x64 Symantec Symantec NetBackup 7.5 S x64 Symantec Veritas Operations Manager 5.0 S x64 Symantec Symantec Virtual Store 6.0 S x64 Symantec Veritas Dynamic Multi-Pathing 6.0.1 S x64 5.5, 5.6, 5.7, 5,8, 6,1, 6.2, x64 RedHat RedHat Enterprise Linux (RHEL) 6.3 S Novell SUSE Linux Enterprise Server (SLES) 10SP4, 11SP1, 11SP2 S x64 Oracle Oracle Linux (OL) 5.6, 5.7, 5.8, 6.1, 6.2, 6.3 S x64 Note 1 Oracle Oracle Database 11g, 11gR1, 11gR2 S x64 SAP SAP Netweaver 7.1,7.3 S x64 IBM IBM WebSphere MQ 7.0, 7.1 S x64 Support Legend Tested and Supported S Supported with Limitations L Compatible and Supported, but not tested by Symantec C x64 = Extended 64-bit Windows architecture Not Supported X Upgradeable to latest version U NOTES: Support is conditional according to the Notes corresponding to the individual platform or application. -

List of New Applications Added in ARL #2586
List of new applications added in ARL #2586 Application Name Publisher NetCmdlets 2016 /n software 1099 Pro 2009 Corporate 1099 Pro 1099 Pro 2020 Enterprise 1099 Pro 1099 Pro 2008 Corporate 1099 Pro 1E Client 5.1 1E SyncBackPro 9.1 2BrightSparks FindOnClick 2.5 2BrightSparks TaxAct 2002 Standard 2nd Story Software Phone System 15.5 3CX Phone System 16.0 3CX 3CXPhone 16.3 3CX Grouper Plus System 2021 3M CoDeSys OPC Server 3.1 3S-Smart Software Solutions 4D 15.0 4D Duplicate Killer 3.4 4Team Disk Drill 4.1 508 Software NotesHolder 2.3 Pro A!K Research Labs LibraryView 1.0 AB Sciex MetabolitePilot 2.0 AB Sciex Advanced Find and Replace 5.2 Abacre Color Picker 2.0 ACA Systems Password Recovery Toolkit 8.2 AccessData Forensic Toolkit 6.0 AccessData Forensic Toolkit 7.0 AccessData Forensic Toolkit 6.3 AccessData Barcode Xpress 7.0 AccuSoft ImageGear 17.2 AccuSoft ImagXpress 13.6 AccuSoft PrizmDoc Server 13.1 AccuSoft PrizmDoc Server 12.3 AccuSoft ACDSee 2.2 ACD Systems ACDSync 1.1 ACD Systems Ace Utilities 6.3 Acelogix Software True Image for Crucial 23. Acronis Acrosync 1.6 Acrosync Zen Client 5.10 Actian Windows Forms Controls 16.1 Actipro Software Opus Composition Server 7.0 ActiveDocs Network Component 4.6 ActiveXperts Multiple Monitors 8.3 Actual Tools Multiple Monitors 8.8 Actual Tools ACUCOBOL-GT 5.2 Acucorp ACUCOBOL-GT 8.0 Acucorp TransMac 12.1 Acute Systems Ultimate Suite for Microsoft Excel 13.2 Add-in Express Ultimate Suite for Microsoft Excel 21.1 Business Add-in Express Ultimate Suite for Microsoft Excel 21.1 Personal Add-in Express -

Veritas™ Cluster Server Release Notes
Veritas™ Cluster Server Release Notes Windows Server 2008 (x64), Windows Server 2008 R2 (x64) 6.0 March 2013 Veritas Cluster Server Release Notes The software described in this book is furnished under a license agreement and may be used only in accordance with the terms of the agreement. Product version: 6.0 Document version: 6.0.0 Legal Notice Copyright © 2013 Symantec Corporation. All rights reserved. Symantec, the Symantec Logo, the Checkmark Logo, Veritas, Veritas Storage Foundation, CommandCentral, NetBackup, Enterprise Vault, and LiveUpdate are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. This Symantec product may contain third party software for which Symantec is required to provide attribution to the third party (“Third Party Programs”). Some of the Third Party Programs are available under open source or free software licenses. The License Agreement accompanying the Software does not alter any rights or obligations you may have under those open source or free software licenses. See the Third-party Legal Notices document for this product, which is available online or included in the base release media. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. -

Overall Messaging/Description (We'll Want to Highlight
Storage and Availability Management Group Data Protection Group At-a-Glance PROFILE Symantec provides enterprise customers with storage management, high availability and data protection solutions across heterogeneous storage and server platforms in both physical and virtual environments. These solutions enable companies to standardize on a single layer of infrastructure software that works on every major distributed operating system and supports every major storage device, database and application. Storage and Availability Management – Symantec’s storage management and high availability family of products provide storage management, storage resource management, storage utilization management, storage area network, or SAN management, storage virtualization and replication, allowing enterprises to ensure the availability of critical applications and data. Products include Veritas CommandCentral Storage, Veritas Storage Foundation and Veritas Cluster Server. Data Protection – Symantec’s data protection family of products is designed to ensure successful backup and recovery of information and systems for organizations across all market segments, from small and medium-sized businesses to large enterprises, using the latest disk, tape, deduplication, indexing and virtual technologies. Products include Veritas NetBackup Platform, Symantec Backup Exec and Symantec Backup Exec System Recovery. LEADERSHIP • Rob Soderbery, senior vice president, Storage and Availability Management Group • Deepak Mohan, senior vice president, Data Protection Group Symantec Corp., 2008 1 STORAGE AND AVAILABILITY MANAGEMENT PRODUCTS Veritas Storage Foundation Veritas Storage Foundation from Symantec provides a complete solution for heterogeneous online storage management. Based on the industry-leading Veritas Volume Manager and Veritas File System, it provides a standard set of integrated tools to centrally manage explosive data growth, maximize storage hardware investments, provide data protection and adapt to changing business requirements. -

Veritas Cluster Server User's Guide
Veritas™ Cluster Server User’s Guide HP-UX 5.0 N18472G Veritas Cluster Server User’s Guide Copyright © 2006 Symantec Corporation. All rights reserved. Veritas Cluster Server 5.0 Symantec, the Symantec logo,Veritas, are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THIS DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID, SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be “commercial computer software” and “commercial computer software documentation” as defined in FAR Sections 12.212 and DFARS Section 227.7202. Symantec Corporation 20330 Stevens Creek Blvd. Cupertino, CA 95014 www.symantec.com Third-party legal notices Third-party software may be recommended, distributed, embedded, or bundled with this Symantec Corporation product. Such third-party software is licensed separately by its copyright holder. All third-party copyrights associated with this product are listed in the accompanying release notes. -

Redmondmag.Com Group Policy Grows with Windows
0506red_cover.v6 4/18/06 1:31 PM Page 1 AttackAttack ofof thethe Ball-PointBall-Point PensPens 6161 MAY 2006 WWW.REDMONDMAG.COM New Admin Features Are Tough to Beat page 29 > $5.95 05 • MAY Readers’ Choice Awards Apps To Go: 20 Programs Nobody Does It Better 38 That Fit on Your Keychain 53 25274 867 27 71 Project1 4/11/06 3:14 PM Page 1 8)&/ %*4"45&3 i)FMMP IFMQEFTL w 453*,&4 3&"$) '03 "%.*/*453"5034 1", 3FQBJS BO VOCPPUBCMF TZTUFN $IBOHF B MPTU "ENJOJTUSBUPS QBTTXPSE 3FDPWFS EFMFUFE PS MPTU EBUB %JBHOPTF TZTUFN BOE OFUXPSL JTTVFT 3FNPWF NBMXBSF XIJMF B TZTUFN JT PGnJOF #VZ POF "ENJOJTUSBUPST 1BL BOE HFU B TFDPOE GPS 4FFCBDLGPS EFUBJMT '3&& &WBM 8JOUFSOBMTDPN#VZ(FU Project1 4/11/06 3:15 PM Page 2 #VZ POF "ENJOJTUSBUPST 1BL BU MJTU QSJDF BOE HFU B TFDPOE DPQZ GPS POMZ 5XJDF UIF QSPUFDUJPO " GSBDUJPO PG UIF DPTU 5IF5PQ5FO5PPMT"CTPMVUFMZ&WFSZ"ENJOJTUSBUPS/FFET SBUPST 1BL MJTU QSJDF JT $FSUBJO &3%$PNNBOEFS 'JMFNPO #PPUBEFBETZTUFNGSPN$%JOUPBGBNJMJBS8JO 7JFX SFBMUJNF SFQPSUT PG BMM mMF TZTUFN EPXTMJLF SFQBJS FOWJSPONFOU BDUJWJUZ PO B TZTUFN FDUJWF PXOFST JO UIF 64 BOEPS PUIFS DPVOUSJFT 8JOUFSOBMT $SBTI"OBMZ[FS8J[BSE 3FHNPO 1JOQPJOU UIF DBVTF PG TZTUFN DSBTIFT TP UIBU ZPV DBO 7JFX SFBMUJNF SFQPSUT PG BMM SFHJTUSZ BDUJWJUZ PO B NBLF SBQJE SFQBJST TZTUFN 3FNPUF3FDPWFS *OTJHIUGPS"DUJWF%JSFDUPSZ 3FNPUFMZ BDDFTT BO VOCPPUBCMF TZTUFN UP NBLF 7JFX SFBMUJNF SFQPSUT PG BMM -%"1 USBGmD PO B TZTUFN SFQBJST /5'4%041SPGFTTJPOBM "%&YQMPSFS "DDFTT /5'4 WPMVNFT GSPN %04 &YQMPSF UIF "% TUSVDUVSF UP mOE BOE NPEJGZ PCKFDUT BOE UIFJS BUUSJCVUFT 'JMF3FTUPSF -

Symantec Corporation 2007 Annual Report TWO YEAR SUMMARY of FINANCIAL RESULTS RECONCILIATION of GAAP to NON-GAAP FINANCIALS
Symantec Corporation 2007 Annual Report TWO YEAR SUMMARY OF FINANCIAL RESULTS RECONCILIATION OF GAAP TO NON-GAAP FINANCIALS Fiscal Year The non-GAAP information reflects the com- ($ in millions, except per share amounts) 2007 2006 bined results of Symantec and Veritas Soft- ware, including adjustments based on the fair Revenue values of assets acquired and liabilities GAAP Revenue $5,199 $4,143 assumed by Symantec as of the actual acqui- Veritas revenue — 559 sition date of July 2, 2005. For comparative Fair value adjustment to Veritas deferred revenue 53 302 purposes, the information presented assumes Non-GAAP Revenue $5,253 $5,004 that the acquisition took place on April 1, 2004. Symantec’s fiscal years ended March 31st Gross Profit whereas Veritas’ fiscal years ended Decem- GAAP Gross Profit $3,984 $3,162 ber 31st. The 2006 fiscal amounts combine Veritas gross profit — 398 Symantec’s 2006 fiscal results with Veritas’ Fair value adjustment to Veritas deferred revenue 53 302 Integration planning — 1 historical results for the three months ended Amortization of acquired product rights 342 386 March 31, 2005. Additional non-GAAP adjust- Amortization of deferred stock-based compensation 16 1 ments consist of: non-cash charges related to Non-GAAP Gross Profit $4,396 $4,250 acquisitions, such as the amortization of intan- gibles and stock-based compensation Operating Expenses expense, and the write-off of in-process GAAP Operating Expenses $3,464 $2,888 research and development; restructuring Veritas operating expenses — 400 charges; integration planning costs; and the Amortization of other intangible assets (202) (196) impact of other special items, such as other Amortization of deferred stock-based compensation (137) (43) stock-based compensation expense, litigation Acquired in-process research and development — (285) matters, gain/loss on investments and related Restructuring (70) (25) Integration planning (1) (27) adjustments to the provision for income taxes, Patent settlement — (2) on our operating results.