A Rooted Phylogeny Resolves Early Bacterial Evolution (Supplementary Information)
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
Prokaryotes (Domains Bacteria & Archaea)
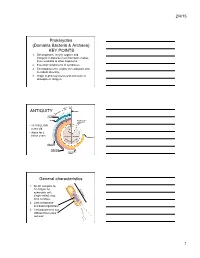
2/4/15 Prokaryotes (Domains Bacteria & Archaea) KEY POINTS 1. Decomposers: recycle organic and inorganic molecules in environment; makes them available to other organisms. 2. Essential components of symbioses. 3. Encompasses the origins of metabolism and metabolic diversity. 4. Origin of photosynthesis and formation of atmospheric Oxygen Ceno- Meso- zoic zoic ANTIQUITY Humans Paleozoic Colonization of land Animals Origin of solar system and Earth • >3.5 BILLION years old. • Alone for 2 1 4 billion years Proterozoic Archaean Prokaryotes Billions of 2 years ago3 Multicellular eukaryotes Single-celled eukaryotes Atmospheric oxygen General characteristics 1. Small: compare to 10-100µm for 0.5-5µm eukaryotic cell; single-celled; may form colonies. 2. Lack membrane- enclosed organelles. 3. Cell wall present, but different from plant cell wall. 1 2/4/15 General characteristics 4. Occur everywhere, most numerous organisms. – More individuals in a handful of soil then there are people that have ever lived. – By far more individuals in our gut than eukaryotic cells that are actually us. General characteristics 5. Metabolic diversity established nutritional modes of eukaryotes. General characteristics 6. Important decomposers and recyclers 2 2/4/15 General characteristics 6. Important decomposers and recyclers • Form the basis of global nutrient cycles. General characteristics 7. Symbionts!!!!!!! • Parasites • Pathogenic organisms. • About 1/2 of all human diseases are caused by Bacteria General characteristics 7. Symbionts!!!!!!! • Parasites • Pathogenic organisms. • Extremely important in agriculture as well. Pierce’s disease is caused by Xylella fastidiosa, a Gamma Proteobacteria. It causes over $56 million in damage annually in California. That’s with $34 million spent to control it! = $90 million in California alone. -

The First Cells Were Most Likely Very Simple Prokaryotic Forms. Ra- Spirochetes
T HE O RIGIN OF E UKARYOTIC C ELLS The first cells were most likely very simple prokaryotic forms. Ra- spirochetes. Ingestion of prokaryotes that resembled present-day diometric dating indicates that the earth is 4 to 5 billion years old cyanobacteria could have led to the endosymbiotic development of and that prokaryotes may have arisen more than 3.5 billion years chloroplasts in plants. ago. Eukaryotes are thought to have first appeared about 1.5 billion Another hypothesis for the evolution of eukaryotic cells proposes years ago. that the prokaryotic cell membrane invaginated (folded inward) to en- The eukaryotic cell might have evolved when a large anaerobic close copies of its genetic material (figure 1b). This invagination re- (living without oxygen) amoeboid prokaryote ingested small aerobic (liv- sulted in the formation of several double-membrane-bound entities ing with oxygen) bacteria and stabilized them instead of digesting them. (organelles) in a single cell. These entities could then have evolved This idea is known as the endosymbiont hypothesis (figure 1a) and into the eukaryotic mitochondrion, nucleus, and chloroplasts. was first proposed by Lynn Margulis, a biologist at Boston Univer- Although the exact mechanism for the evolution of the eu- sity. (Symbiosis is an intimate association between two organisms karyotic cell will never be known with certainty, the emergence of of different species.) According to this hypothesis, the aerobic bac- the eukaryotic cell led to a dramatic increase in the complexity and teria developed into mitochondria, which are the sites of aerobic diversity of life-forms on the earth. At first, these newly formed eu- respiration and most energy conversion in eukaryotic cells. -

Acetogen Communities in the Gut of Herbivores and Their Potential Role in Syngas Fermentation
fermentation Article Acetogen Communities in the Gut of Herbivores and Their Potential Role in Syngas Fermentation Chunlei Yang Institute of Dairy Science, MoE Key Laboratory of Molecular Animal Nutrition, College of Animal Sciences, Zhejiang University, Hangzhou 310058, China; [email protected] Received: 2 May 2018; Accepted: 4 June 2018; Published: 7 June 2018 Abstract: To better understand the effects of host selection on gut acetogens and their potential role in syngas fermentation, the composition and hydrogenotrophic features of acetogen populations in cow and sheep rumens, rabbit ceca, and horse feces were studied. The acetogens detected in horses and rabbits were more phylogenetically diverse than those in cows and sheep, suggesting that the host species plays an important role in shaping gut acetogen populations. Acetogen enrichments from these animals presented good capacities to use hydrogen, with acetate as the major end product. Minor propionate, butyrate, and isovalerate were also produced. During 48 h of incubation, acetogen enrichments from horse consumed 4.75 moles of H2 to every 1 mole of acetate—significantly lower than rabbits, cows, and sheep (5.17, 5.53, and 5.23 moles, respectively) (p < 0.05)—and produced significantly more butyrate (p < 0.05). Enrichments from cows and sheep produced significantly higher amounts of propionate when compared to rabbits or horses (p < 0.05); enrichments from sheep produced the highest amounts of isovalerate (p < 0.05). These short chain fatty acids are important precursors for the synthesis of biofuel products, suggesting that gut contents of herbivores may be promising sources for harvesting functional acetogens for biofuel production. -

Phylogenetic Rooting Using Minimal Ancestor Deviation
Phylogenetic rooting using minimal ancestor deviation Fernando D. K. Tria1, Giddy Landan1*, Tal Dagan Genomic Microbiology Group, Institute of General Microbiology, Kiel University, Kiel, Germany 1 Equally contributed. * Corresponding author: [email protected] This preprint PDF is the revised manuscript as submitted to Nature Ecology & Evolution on 30-Mar-2017. It includes both the main text and the supplementary information. The final version published in Nature Ecology & Evolution on 19-Jun-2017 (and submitted on 08-May-2017), is here: https://www.nature.com/articles/s41559-017-0193 Readers without subscription to NatE&E can see a read-only (no save or print) version here: http://rdcu.be/tywU The main difference between the versions is that the ‘Detailed Algorithm’ section is part of the main text 'Methods' section in the NatE&E final version, but is part of the supplementary information of this preprint version. Be sure to page beyond the references to see it. 1 Abstract Ancestor-descendent relations play a cardinal role in evolutionary theory. Those relatio ns are determined by rooting phylogenetic trees. Existing rooting methods are hampered by evolutionary rate heterogeneity or the unavailability of auxiliary phylogenetic information. We present a novel rooting approach, the minimal ancestor deviation (MAD) method, which embraces heterotachy by utilizing all pairwise topological and metric information in unrooted trees. We demonstrate the method in comparison to existing rooting methods by the analysis of phylogenies from eukaryotes and prokaryotes. MAD correctly recovers the kno wn root of eukaryotes and uncovers evidence for cyanobacteria origins in the ocean. MAD is more robust and co nsistent than existing methods, provides measures of the root inference quality, and is applicable to any tree with branch lengths. -

Contrasting Environmental Preferences of Photosynthetic and Non-Photosynthetic Soil Cyanobacteria Across the Globe
Received: 31 October 2019 | Revised: 8 July 2020 | Accepted: 20 July 2020 DOI: 10.1111/geb.13173 RESEARCH PAPER Contrasting environmental preferences of photosynthetic and non-photosynthetic soil cyanobacteria across the globe Concha Cano-Díaz1 | Fernando T. Maestre2,3 | David J. Eldridge4 | Brajesh K. Singh5,6 | Richard D. Bardgett7 | Noah Fierer8,9 | Manuel Delgado-Baquerizo10 1Departamento de Biología, Geología, Física y Química Inorgánica, Escuela Superior de Ciencias Experimentales y Tecnología, Universidad Rey Juan Carlos, Móstoles, 28933, Spain 2Instituto Multidisciplinar para el Estudio del Medio “Ramón Margalef”, Universidad de Alicante, Edificio Nuevos Institutos, Carretera de San Vicente del Raspeig s/n, San Vicente del Raspeig, 03690, Spain 3Departamento de Ecología, Universidad de Alicante, Carretera de San Vicente del Raspeig s/n, San Vicente del Raspeig, 03690, Spain 4Centre for Ecosystem Science, School of Biological, Earth and Environmental Sciences, University of New South Wales, Sydney, New South Wales, Australia 5Global Centre for Land-Based Innovation, University of Western Sydney, Penrith, New South Wales, Australia 6Hawkesbury Institute for the Environment, University of Western Sydney, Penrith, New South Wales, Australia 7Department of Earth and Environmental Sciences, The University of Manchester, Manchester, UK 8Department of Ecology and Evolutionary Biology, University of Colorado, Boulder, CO, USA 9Cooperative Institute for Research in Environmental Sciences, University of Colorado, Boulder, Colorado, USA 10Departamento de Sistemas Físicos, Químicos y Naturales, Universidad Pablo de Olavide, Sevilla, 41013, Spain Correspondence Concha Cano-Díaz, Departamento de Abstract Biología, Geología, Física y Química Aim: Cyanobacteria have shaped the history of life on Earth and continue to play Inorgánica, Escuela Superior de Ciencias Experimentales y Tecnología, Universidad important roles as carbon and nitrogen fixers in terrestrial ecosystems. -

Microbiology Unit- 1 1. According to Bergey's Manual of Systematic
Microbiology Unit- 1 1. According to Bergey’s Manual of Systematic Bacteriology, prokaryotes that lack a cell wall belong to the group? a) Gracilicutes b) Firmicutes c) Tenericutes d) Mendosicutes 2.Which among the following kingdoms were proposed by Whittaker? a) Monera b) Protista,Fungi c) Plantae,Animalia d) Monera,Protista,Fungi,Plantae,Animalia 3. Lipopolysaccharide in cell walls is characteristic of? a) Gram-positive bacteria b) Gram-negative bacteria c) Fungi d) Algae 4. Which of the following symmetry is exhibited by rod-shaped viruses? a) icosahedral b) helical c) complex d) circular 5. Fungi are ______________ a) prokaryotic b) eukaryotic c) prokaryotic and lack chlorophyll d) eukaryotic and lack chlorophyll 6. Which microorganism(s) among the following perform photosynthesis by utilizing light? a) Cyanobacteria b) Fungi c) Viruses d) Cyanobacteria, Fungi and Viruses 7. Adenoviruses exhibit which of the following symmetry? a) helical symmetry b) circular symmetry c) icosahedral symmetry d) complex structure symmetry 8. The transfer of genes from one cell to another by a bacteriophage is known as __________________ a) Recombination b) Conjugation c) Transduction d) Transformation 9. The cell in which the F factor carries along with it some chromosomal genes are known as ____________ a) F+ cell b) F— cell c) F’ cell d) F’’’ cell 10. The xanthophyte walls are typically of _____________________ a) chitin b) cellulose c) cellulose and pectin d) starch 11. Vaucheria is a single-celled organism. a) True b) False 12. In Chlamydomonas the most common method of sexual reproduction is ________________ a) isogamy b) heterogamy c) oogamy d) spore formation 13. -

Table S4. Phylogenetic Distribution of Bacterial and Archaea Genomes in Groups A, B, C, D, and X
Table S4. Phylogenetic distribution of bacterial and archaea genomes in groups A, B, C, D, and X. Group A a: Total number of genomes in the taxon b: Number of group A genomes in the taxon c: Percentage of group A genomes in the taxon a b c cellular organisms 5007 2974 59.4 |__ Bacteria 4769 2935 61.5 | |__ Proteobacteria 1854 1570 84.7 | | |__ Gammaproteobacteria 711 631 88.7 | | | |__ Enterobacterales 112 97 86.6 | | | | |__ Enterobacteriaceae 41 32 78.0 | | | | | |__ unclassified Enterobacteriaceae 13 7 53.8 | | | | |__ Erwiniaceae 30 28 93.3 | | | | | |__ Erwinia 10 10 100.0 | | | | | |__ Buchnera 8 8 100.0 | | | | | | |__ Buchnera aphidicola 8 8 100.0 | | | | | |__ Pantoea 8 8 100.0 | | | | |__ Yersiniaceae 14 14 100.0 | | | | | |__ Serratia 8 8 100.0 | | | | |__ Morganellaceae 13 10 76.9 | | | | |__ Pectobacteriaceae 8 8 100.0 | | | |__ Alteromonadales 94 94 100.0 | | | | |__ Alteromonadaceae 34 34 100.0 | | | | | |__ Marinobacter 12 12 100.0 | | | | |__ Shewanellaceae 17 17 100.0 | | | | | |__ Shewanella 17 17 100.0 | | | | |__ Pseudoalteromonadaceae 16 16 100.0 | | | | | |__ Pseudoalteromonas 15 15 100.0 | | | | |__ Idiomarinaceae 9 9 100.0 | | | | | |__ Idiomarina 9 9 100.0 | | | | |__ Colwelliaceae 6 6 100.0 | | | |__ Pseudomonadales 81 81 100.0 | | | | |__ Moraxellaceae 41 41 100.0 | | | | | |__ Acinetobacter 25 25 100.0 | | | | | |__ Psychrobacter 8 8 100.0 | | | | | |__ Moraxella 6 6 100.0 | | | | |__ Pseudomonadaceae 40 40 100.0 | | | | | |__ Pseudomonas 38 38 100.0 | | | |__ Oceanospirillales 73 72 98.6 | | | | |__ Oceanospirillaceae -

Chapter 11: Bacteria Bacterial Groups
Bacterial Groups u Most widely accepted taxonomic classification for bacteria is Bergey’s Manual of Systematic Bacteriology. u 5000 bacterial species identified, 3100 classified. Chapter 11: Bacteria u Bacteria are divided into four divisions (phyla) according to the characteristics of their cell walls. u Each division is divided into sections according to: u Gram stain reaction u Cell shape u Cell arrangements u Oxygen requirements u Motility u Nutritional and metabolic properties u Each section contains several genera. Four Divisions of Bacteria Classification of Bacteria Procaryotes Gram-Negative Division II Wall-Less Archaea Bacteria Bacteria Bacteria Bacteria (Gracilicutes) (Firmicutes) (Tenericutes) (Mendosicutes) Thin Cell Walls Thick cell Walls Lack cell walls Unusual cell walls Division I. Gram-Negative Bacteria Gram Negative Bacteria Spirochetes 1. Spirochetes u Helical shape. Flexible. u Contain two or more axial filaments (endoflagella). u Move in corkscrew pattern. u Medically important members: F Treponema pallidum: Syphilis F Borrelia spp.: Lyme disease, relapsing fever F Leptospira: Leptospirosis 1 Syphilis is Caused by a Spirochete Lyme Disease is Caused by a Spirochete Primary syphilitic chancre and secondary rash. Source: Tropical Medicine and Parasitology, 1997 Lyme Disease early lesion at tick bite site. Source: Medical Microbiology, 1998 2. Aerobic, Motile, Helical/Vibroid Gram- Negative Bacteria Gram Negative Bacteria u Rigid helical shape or curved rods. Aerobic, Motile, Helical/Vibroid u Lack axial filaments (endoflagella); have polar Gram-Negative Bacteria flagella instead. u Most are harmless aquatic organisms. u Genus Azospirillum fixes nitrogen in soil. u Genus Bdellovibrio attacks other bacteria. u Important pathogens include: F Campylobacter jejuni: Most common bacterial food- borne intestinal disease in the United States (2 million cases/year). -

Within-Arctic Horizontal Gene Transfer As a Driver of Convergent Evolution in Distantly Related 1 Microalgae 2 Richard G. Do
bioRxiv preprint doi: https://doi.org/10.1101/2021.07.31.454568; this version posted August 2, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Within-Arctic horizontal gene transfer as a driver of convergent evolution in distantly related 2 microalgae 3 Richard G. Dorrell*+1,2, Alan Kuo3*, Zoltan Füssy4, Elisabeth Richardson5,6, Asaf Salamov3, Nikola 4 Zarevski,1,2,7 Nastasia J. Freyria8, Federico M. Ibarbalz1,2,9, Jerry Jenkins3,10, Juan Jose Pierella 5 Karlusich1,2, Andrei Stecca Steindorff3, Robyn E. Edgar8, Lori Handley10, Kathleen Lail3, Anna Lipzen3, 6 Vincent Lombard11, John McFarlane5, Charlotte Nef1,2, Anna M.G. Novák Vanclová1,2, Yi Peng3, Chris 7 Plott10, Marianne Potvin8, Fabio Rocha Jimenez Vieira1,2, Kerrie Barry3, Joel B. Dacks5, Colomban de 8 Vargas2,12, Bernard Henrissat11,13, Eric Pelletier2,14, Jeremy Schmutz3,10, Patrick Wincker2,14, Chris 9 Bowler1,2, Igor V. Grigoriev3,15, and Connie Lovejoy+8 10 11 1 Institut de Biologie de l'ENS (IBENS), Département de Biologie, École Normale Supérieure, CNRS, 12 INSERM, Université PSL, 75005 Paris, France 13 2CNRS Research Federation for the study of Global Ocean Systems Ecology and Evolution, 14 FR2022/Tara Oceans GOSEE, 3 rue Michel-Ange, 75016 Paris, France 15 3 US Department of Energy Joint Genome Institute, Lawrence Berkeley National Laboratory, 1 16 Cyclotron Road, Berkeley, -

Prokaryotes, Protists, Reconstructing the Photosynthesis, Evolution of Living Things
Prokaryotes, Protists, Reconstructing the Photosynthesis, evolution of living things Endosymbiosis • Systematists study evolutionary relationships Ch 28 & 29 •Look for shared derived (=different from ancestor) traits to group organisms • Evidence used: morphology, 26 February 2009 development, and molecular data (especially DNA sequences) ECOL 182R UofA K. E. Bonine 1 2 Why can’t we figure it out perfectly? • More distant history is obscured by more changes trypanosomes • Among oldest lineages of Bacteria and Archaea in particular, lots of “lateral gene transfer.” Makes it difficult to infer relationships from phylogeny of red blood cells single genes. 3 4 Early prokaryote fossil Diversity of Prokaryotes Bacteria & Archaea 5 6 1 What are microbes? Life can be divided into 3 domains • Only a minority make us sick •Robert Koch, Germ Theory of Disease • In ordinary English, might be anything small 3.8bya –bacteria 1.5bya –yeast –protists – viruses •Prokaryotes = bacteria + archaea • In science, classify by evolutionary • Prokaryote was ancestral and only form for relationships… 7 billions of years 8 Eukarya Scheme has been revised before: Haeckel (1894) Whittaker (1959) Woese (1977) Woese (1990) Three kingdoms Five kingdoms Six kingdoms Three domains Eubacteria Bacteria Monera (prokaryotes) Protista Archaebacteria Archaea Protista Protista Fungi Fungi Plantae Eukarya are Prokaryotes monophyletic, Plantae Plantae Animalia Animalia Animalia paraphyleticparaphyletic, polyphyletic? 9 modified from Wikipedia 10 Shared by all 3 domains Unique to -

Prokaryote Vs. Eukaryote Campaign Biology Name: ______Period: ______
Prokaryote vs. Eukaryote Campaign Biology Name: ___________________________________________ Period: ____________ Prokaryotes vs. Eukaryotes: A Campaign for Election as Coolest Cell Type! Purpose: While prokaryotes and eukaryotes share some similar structures and characteristics of life, the two lead some pretty different lives! Your job in this assignment is to create a campaign poster and a campaign platform commercial for a prokaryote or a eukaryote as they campaign to be elected coolest cell type! Directions: Each group will be assigned a campaign platform from those listed below. Use the resources listed (as well as any others you might find) to understand why your platform makes your cell type the coolest. Create a campaign poster (using one slide on a Google Presentation, shared between partners, and submitted by due date via a form) and a short campaign platform commercial (given as a speech in class) using the attached rubric. Prokaryotic campaign platforms: 1. Ability to form endospores http://goo.gl/Y1tUK http://goo.gl/DhVNe 2. Ability to form biofilms with other cells http://goo.gl/umy7Z http://goo.gl/m9d5W 3. Quorum sensing neighboring cells http://goo.gl/DSiJU http://goo.gl/IFFtA 4. Production of bacteriocins http://goo.gl/lW75y http://goo.gl/WzFv1 5. Endosymbiotic theory http://goo.gl/6VIba http://goo.gl/uSYh4 Eukaryotic campaign platforms: 6. Contain organelles that have their own genetic material in addition to that found in the nucleus http://goo.gl/6VIba http://goo.gl/Nqesq 7. Vesicles http://goo.gl/bwF3x http://goo.gl/j3qY3 8. Membrane bound organelles that facilitate transport (endomembrane system) http://goo.gl/j3qY3 http://goo.gl/i4brZ 9. -

Cell Structure and Function in the Bacteria and Archaea
4 Chapter Preview and Key Concepts 4.1 1.1 DiversityThe Beginnings among theof Microbiology Bacteria and Archaea 1.1. •The BacteriaThe are discovery classified of microorganismsinto several Cell Structure wasmajor dependent phyla. on observations made with 2. theThe microscope Archaea are currently classified into two 2. •major phyla.The emergence of experimental 4.2 Cellscience Shapes provided and Arrangements a means to test long held and Function beliefs and resolve controversies 3. Many bacterial cells have a rod, spherical, or 3. MicroInquiryspiral shape and1: Experimentation are organized into and a specific Scientificellular c arrangement. Inquiry in the Bacteria 4.31.2 AnMicroorganisms Overview to Bacterialand Disease and Transmission Archaeal 4.Cell • StructureEarly epidemiology studies suggested how diseases could be spread and 4. Bacterial and archaeal cells are organized at be controlled the cellular and molecular levels. 5. • Resistance to a disease can come and Archaea 4.4 External Cell Structures from exposure to and recovery from a mild 5.form Pili allowof (or cells a very to attach similar) to surfacesdisease or other cells. 1.3 The Classical Golden Age of Microbiology 6. Flagella provide motility. Our planet has always been in the “Age of Bacteria,” ever since the first 6. (1854-1914) 7. A glycocalyx protects against desiccation, fossils—bacteria of course—were entombed in rocks more than 3 billion 7. • The germ theory was based on the attaches cells to surfaces, and helps observations that different microorganisms years ago. On any possible, reasonable criterion, bacteria are—and always pathogens evade the immune system. have been—the dominant forms of life on Earth.