Multiple Reference Motion Compensation: a Tutorial Introduction and Survey Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kulkarni Uta 2502M 11649.Pdf
IMPLEMENTATION OF A FAST INTER-PREDICTION MODE DECISION IN H.264/AVC VIDEO ENCODER by AMRUTA KIRAN KULKARNI Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE IN ELECTRICAL ENGINEERING THE UNIVERSITY OF TEXAS AT ARLINGTON May 2012 ACKNOWLEDGEMENTS First and foremost, I would like to take this opportunity to offer my gratitude to my supervisor, Dr. K.R. Rao, who invested his precious time in me and has been a constant support throughout my thesis with his patience and profound knowledge. His motivation and enthusiasm helped me in all the time of research and writing of this thesis. His advising and mentoring have helped me complete my thesis. Besides my advisor, I would like to thank the rest of my thesis committee. I am also very grateful to Dr. Dongil Han for his continuous technical advice and financial support. I would like to acknowledge my research group partner, Santosh Kumar Muniyappa, for all the valuable discussions that we had together. It helped me in building confidence and motivated towards completing the thesis. Also, I thank all other lab mates and friends who helped me get through two years of graduate school. Finally, my sincere gratitude and love go to my family. They have been my role model and have always showed me right way. Last but not the least; I would like to thank my husband Amey Mahajan for his emotional and moral support. April 20, 2012 ii ABSTRACT IMPLEMENTATION OF A FAST INTER-PREDICTION MODE DECISION IN H.264/AVC VIDEO ENCODER Amruta Kulkarni, M.S The University of Texas at Arlington, 2011 Supervising Professor: K.R. -

1. in the New Document Dialog Box, on the General Tab, for Type, Choose Flash Document, Then Click______
1. In the New Document dialog box, on the General tab, for type, choose Flash Document, then click____________. 1. Tab 2. Ok 3. Delete 4. Save 2. Specify the export ________ for classes in the movie. 1. Frame 2. Class 3. Loading 4. Main 3. To help manage the files in a large application, flash MX professional 2004 supports the concept of _________. 1. Files 2. Projects 3. Flash 4. Player 4. In the AppName directory, create a subdirectory named_______. 1. Source 2. Flash documents 3. Source code 4. Classes 5. In Flash, most applications are _________ and include __________ user interfaces. 1. Visual, Graphical 2. Visual, Flash 3. Graphical, Flash 4. Visual, AppName 6. Test locally by opening ________ in your web browser. 1. AppName.fla 2. AppName.html 3. AppName.swf 4. AppName 7. The AppName directory will contain everything in our project, including _________ and _____________ . 1. Source code, Final input 2. Input, Output 3. Source code, Final output 4. Source code, everything 8. In the AppName directory, create a subdirectory named_______. 1. Compiled application 2. Deploy 3. Final output 4. Source code 9. Every Flash application must include at least one ______________. 1. Flash document 2. AppName 3. Deploy 4. Source 10. In the AppName/Source directory, create a subdirectory named __________. 1. Source 2. Com 3. Some domain 4. AppName 11. In the AppName/Source/Com directory, create a sub directory named ______ 1. Some domain 2. Com 3. AppName 4. Source 12. A project is group of related _________ that can be managed via the project panel in the flash. -

Video Coding Standards
Video coding standards Video signals represent sequences of images or frames which can be transmitted with a rate from 15 to 60 frames per second (fps), that provides the illusion of motion in the displayed signal. Unlike images they contain the so-called temporal redundancy. Temporal redundancy arises from repeated objects in consecutive frames of the video sequence. Such objects can remain, they can move horizontally, vertically, or any combination of directions (translation movement), they can fade in and out, and they can disappear from the image as they move out of view. Temporal redundancy Motion compensation A motion compensation technique is used to compensate the temporal redundancy of video sequence. The main idea of the this method is to predict the displacement of group of pixels (usually block of pixels) from their position in the previous frame. Information about this displacement is represented by motion vectors which are transmitted together with the DCT coded difference between the predicted and the original images. Motion compensation Image VLC DCT Quantizer Buffer - Dequantizer Coded DCT coefficients. IDCT Motion compensated predictor Motion Motion vectors estimation Decoded VL image Buffer Dequantizer IDCT decoder Motion compensated predictor Motion vectors Motion compensation Previous frame Current frame Set of macroblocks of the previous frame used to predict the selected macroblock of the current frame Motion compensation Previous frame Current frame Macroblocks of previous frame used to predict current frame Motion compensation Each 16x16 pixel macroblock in the current frame is compared with a set of macroblocks in the previous frame to determine the one that best predicts the current macroblock. -

CHAPTER 10 Basic Video Compression Techniques Contents
Multimedia Network Lab. CHAPTER 10 Basic Video Compression Techniques Multimedia Network Lab. Prof. Sang-Jo Yoo http://multinet.inha.ac.kr The Graduate School of Information Technology and Telecommunications, INHA University http://multinet.inha.ac.kr Multimedia Network Lab. Contents 10.1 Introduction to Video Compression 10.2 Video Compression with Motion Compensation 10.3 Search for Motion Vectors 10.4 H.261 10.5 H.263 The Graduate School of Information Technology and Telecommunications, INHA University 2 http://multinet.inha.ac.kr Multimedia Network Lab. 10.1 Introduction to Video Compression A video consists of a time-ordered sequence of frames, i.e.,images. Why we need a video compression CIF (352x288) : 35 Mbps HDTV: 1Gbps An obvious solution to video compression would be predictive coding based on previous frames. Compression proceeds by subtracting images: subtract in time order and code the residual error. It can be done even better by searching for just the right parts of the image to subtract from the previous frame. Motion estimation: looking for the right part of motion Motion compensation: shifting pieces of the frame The Graduate School of Information Technology and Telecommunications, INHA University 3 http://multinet.inha.ac.kr Multimedia Network Lab. 10.2 Video Compression with Motion Compensation Consecutive frames in a video are similar – temporal redundancy Frame rate of the video is relatively high (30 frames/sec) Camera parameters (position, angle) usually do not change rapidly. Temporal redundancy is exploited so that not every frame of the video needs to be coded independently as a new image. The difference between the current frame and other frame(s) in the sequence will be coded – small values and low entropy, good for compression. -

Overview: Motion-Compensated Coding
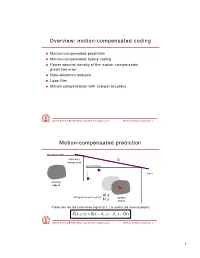
Overview: motion-compensated coding Motion-compensated prediction Motion-compensated hybrid coding Motion estimation by block-matching Motion estimation with sub-pixel accuracy Power spectral density of the motion-compensated prediction error Rate-distortion analysis Loop filter Motion compensated coding with sub-pixel accuracy Rate-constrained motion estimation Bernd Girod: EE398B Image Communication II Motion Compensated Coding no. 1 Motion-compensated prediction previous frame stationary Δt background current frame x time t y moving object ⎛ d x ⎞ „Displacement vector“ ⎜ d ⎟ shifted ⎝ y ⎠ object Prediction for the luminance signal S(x,y,t) within the moving object: ˆ S (x, y,t) = S(x − dx , y − dy ,t − Δt) Bernd Girod: EE398B Image Communication II Motion Compensated Coding no. 2 Combining transform coding and prediction Transform domain prediction Space domain prediction Q Q T - T - T T −1 T −1 T −1 PT T PTS T T −1 T−1 PT PS Bernd Girod: EE398B Image Communication II Motion Compensated Coding no. 3 Motion-compensated hybrid coder Coder Control Control Data Intra-frame DCT DCT Coder - Coefficients Decoder Intra-frame Decoder 0 Motion- Compensated Intra/Inter Predictor Motion Data Motion Estimator Bernd Girod: EE398B Image Communication II Motion Compensated Coding no. 4 Motion-compensated hybrid decoder Control Data DCT Coefficients Decoder Intra-frame Decoder 0 Motion- Compensated Intra/Inter Predictor Motion Data Bernd Girod: EE398B Image Communication II Motion Compensated Coding no. 5 Block-matching algorithm search range in Subdivide current reference frame frame into blocks. Sk −1 Find one displacement vector for each block. Within a search range, find a best „match“ that minimizes an error measure. -

Efficient Video Coding with Motion-Compensated Orthogonal
Efficient Video Coding with Motion-Compensated Orthogonal Transforms DU LIU Master’s Degree Project Stockholm, Sweden 2011 XR-EE-SIP 2011:011 Efficient Video Coding with Motion-Compensated Orthogonal Transforms Du Liu July, 2011 Abstract Well-known standard hybrid coding techniques utilize the concept of motion- compensated predictive coding in a closed-loop. The resulting coding de- pendencies are a major challenge for packet-based networks like the Internet. On the other hand, subband coding techniques avoid the dependencies of predictive coding and are able to generate video streams that better match packet-based networks. An interesting class for subband coding is the so- called motion-compensated orthogonal transform. It generates orthogonal subband coefficients for arbitrary underlying motion fields. In this project, a theoretical lossless signal model based on Gaussian distribution is proposed. It is possible to obtain the optimal rate allocation from this model. Addition- ally, a rate-distortion efficient video coding scheme is developed that takes advantage of motion-compensated orthogonal transforms. The scheme com- bines multiple types of motion-compensated orthogonal transforms, variable block size, and half-pel accurate motion compensation. The experimental results show that this scheme outperforms individual motion-compensated orthogonal transforms. i Acknowledgements This thesis was carried out at Sound and Image Processing Lab, School of Electrical Engineering, KTH. I would like to express my appreciation to my supervisor Markus Flierl for the opportunity of doing this thesis. I am grateful for his patience and valuable suggestions and discussions. Many thanks to Haopeng Li, Mingyue Li, and Zhanyu Ma, who helped me a lot during my research. -

Respiratory Motion Compensation Using Diaphragm Tracking for Cone-Beam C-Arm CT: a Simulation and a Phantom Study
Hindawi Publishing Corporation International Journal of Biomedical Imaging Volume 2013, Article ID 520540, 10 pages http://dx.doi.org/10.1155/2013/520540 Research Article Respiratory Motion Compensation Using Diaphragm Tracking for Cone-Beam C-Arm CT: A Simulation and a Phantom Study Marco Bögel,1 Hannes G. Hofmann,1 Joachim Hornegger,1 Rebecca Fahrig,2 Stefan Britzen,3 and Andreas Maier3 1 Pattern Recognition Lab, Friedrich-Alexander-University Erlangen-Nuremberg, 91058 Erlangen, Germany 2 Department of Radiology, Lucas MRS Center, Stanford University, Palo Alto, CA 94304, USA 3 Siemens AG, Healthcare Sector, 91301 Forchheim, Germany Correspondence should be addressed to Andreas Maier; [email protected] Received 21 February 2013; Revised 13 May 2013; Accepted 15 May 2013 Academic Editor: Michael W. Vannier Copyright © 2013 Marco Bogel¨ et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Long acquisition times lead to image artifacts in thoracic C-arm CT. Motion blur caused by respiratory motion leads to decreased image quality in many clinical applications. We introduce an image-based method to estimate and compensate respiratory motion in C-arm CT based on diaphragm motion. In order to estimate respiratory motion, we track the contour of the diaphragm in the projection image sequence. Using a motion corrected triangulation approach on the diaphragm vertex, we are able to estimate a motion signal. The estimated motion signal is used to compensate for respiratory motion in the target region, for example, heart or lungs. -

CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Optimized AV1 Inter
CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Optimized AV1 Inter Prediction using Binary classification techniques A graduate project submitted in partial fulfillment of the requirements for the degree of Master of Science in Software Engineering by Alex Kit Romero May 2020 The graduate project of Alex Kit Romero is approved: ____________________________________ ____________ Dr. Katya Mkrtchyan Date ____________________________________ ____________ Dr. Kyle Dewey Date ____________________________________ ____________ Dr. John J. Noga, Chair Date California State University, Northridge ii Dedication This project is dedicated to all of the Computer Science professors that I have come in contact with other the years who have inspired and encouraged me to pursue a career in computer science. The words and wisdom of these professors are what pushed me to try harder and accomplish more than I ever thought possible. I would like to give a big thanks to the open source community and my fellow cohort of computer science co-workers for always being there with answers to my numerous questions and inquiries. Without their guidance and expertise, I could not have been successful. Lastly, I would like to thank my friends and family who have supported and uplifted me throughout the years. Thank you for believing in me and always telling me to never give up. iii Table of Contents Signature Page ................................................................................................................................ ii Dedication ..................................................................................................................................... -

Video Coding Standards
Module 8 Video Coding Standards Version 2 ECE IIT, Kharagpur Lesson 23 MPEG-1 standards Version 2 ECE IIT, Kharagpur Lesson objectives At the end of this lesson, the students should be able to : 1. Enlist the major video coding standards 2. State the basic objectives of MPEG-1 standard. 3. Enlist the set of constrained parameters in MPEG-1 4. Define the I- P- and B-pictures 5. Present the hierarchical data structure of MPEG-1 6. Define the macroblock modes supported by MPEG-1 23.0 Introduction In lesson 21 and lesson 22, we studied how to perform motion estimation and thereby temporally predict the video frames to exploit significant temporal redundancies present in the video sequence. The error in temporal prediction is encoded by standard transform domain techniques like the DCT, followed by quantization and entropy coding to exploit the spatial and statistical redundancies and achieve significant video compression. The video codecs therefore follow a hybrid coding structure in which DPCM is adopted in temporal domain and DCT or other transform domain techniques in spatial domain. Efforts to standardize video data exchange via storage media or via communication networks are actively in progress since early 1980s. A number of international video and audio standardization activities started within the International Telephone Consultative Committee (CCITT), followed by the International Radio Consultative Committee (CCIR), and the International Standards Organization / International Electrotechnical Commission (ISO/IEC). An experts group, known as the Motion Pictures Expects Group (MPEG) was established in 1988 in the framework of the Joint ISO/IEC Technical Committee with an objective to develop standards for coded representation of moving pictures, associated audio, and their combination for storage and retrieval of digital media. -

11.2 Motion Estimation and Motion Compensation 421
11.2 Motion Estimation and Motion Compensation 421 vertical component to the enhancement filter, making the overall filter separable with 3 3 support. × 11.2 MOTION ESTIMATION AND MOTION COMPENSATION Motion compensation (MC) is very useful in video filtering to remove noise and enhance signal. It is useful since it allows the filter or coder to process through the video on a path of near-maximum correlation based on following motion trajectories across the frames making up the image sequence or video. Motion compensation is also employed in all distribution-quality video coding formats, since it is able to achieve the smallest prediction error, which is then easier to code. Motion can be characterized in terms of either a velocity vector v or displacement vector d and is used to warp a reference frame onto a target frame. Motion estimation is used to obtain these displacements, one for each pixel in the target frame. Several methods of motion estimation are commonly used: • Block matching • Hierarchical block matching • Pel-recursive motion estimation • Direct optical flow methods • Mesh-matching methods Optical flow is the apparent displacement vector field d .d1,d2/ we get from setting (i.e., forcing) equality in the so-called constraint equationD x.n1,n2,n/ x.n1 d1,n2 d2,n 1/. (11.2–1) D − − − All five approaches start from this basic equation, which is really just an ide- alization. Departures from the ideal are caused by the covering and uncovering of objects in the viewed scene, lighting variation both in time and across the objects in the scene, movement toward or away from the camera, as well as rotation about an axis (i.e., 3-D motion). -
Motion Compensation with Sub-Pel Accuracy
Overview: motion-compensated coding n Motion-compensated prediction n Motion-compensated hybrid coding n Power spectral density of the motion-compensated prediction error n Rate-distortion analysis n Loop filter n Motion compensation with sub-pel accuracy Bernd Girod: EE368b Image and Video Compression Motion Compensation no. 1 Motion-compensated prediction previous frame stationary Dt background current frame x time t y moving object æ dx ö „Displacement vector“ ç d ÷ shifted è y ø object Prediction for the luminance signal S(x,y,t) within the moving object: ˆ S (x, y,t) = S(x - dx , y - dy ,t - Dt) Bernd Girod: EE368b Image and Video Compression Motion Compensation no. 2 1 Motion-compensated prediction: example Previous frame Current frame Current frame with Motion-compensated displacement vectors Prediction error Bernd Girod: EE368b Image and Video Compression Motion Compensation no. 3 Motion-compensated hybrid coder Control „side information“ Video Channel signal Intraframe S e DCT coder - Intraframe Decoder Motion compensated predictor Decoder Bernd Girod: EE368b Image and Video Compression Motion Compensation no. 4 2 Motion-compensated hybrid decoder Channel reconstructed Intraframe video signal Decoder Motion compensated predictor side information Bernd Girod: EE368b Image and Video Compression Motion Compensation no. 5 Model for performance analysis of an MCP hybrid coder luminance signal S e R-D optimal intraframe - encoder intraframe decoder e‘ motion s‘ compensated predictor displacement estimate æ dx ö æ D xö true displacement ç ÷ + ç ÷ displacement error è dyø è D yø Bernd Girod: EE368b Image and Video Compression Motion Compensation no. 6 3 Analysis of the motion-compensated prediction error Motion-compensated signal c(x) = s(x - Dx )- n(x) Prediction error Previous e(x) = s(x)- c(x) frame = s(x)- s(x - Dx )+ n(x) x c(x) s(x) Current frame Displacement dx Displacement error Dx x Bernd Girod: EE368b Image and Video Compression Motion Compensation no. -

Entropy Coding: 6
Multimedia-Systems: Compression Prof. Dr.-Ing. Ralf Steinmetz Prof. Dr. Max Mühlhäuser R. Steinmetz, M. Mühlhäuser MM: TU Darmstadt - Darmstadt University of Technology, © Dept. of of Computer Science TK - Telecooperation, Tel.+49 6151 16-3709, Alexanderstr. 6, D-64283 Darmstadt, Germany, [email protected] Fax. +49 6151 16-3052 http://www.tk.informatik.tu-darmstadt.de http://www.kom.e-technik.tu-darmstadt.de RS: TU Darmstadt - Darmstadt University of Technology, Dept. of Electrical Engineering and Information Technology, Dept. of Computer Science KOM - Industrial Process and System Communications, Tel.+49 6151 166151, Merckstr. 25, D-64283 Darmstadt, Germany, [email protected] Fax. +49 6151 166152 GMD -German National Research Center for Information Technology httc - Hessian Telemedia Technology Competence-Center e.V Scope Contents 05A-compression.fm 1 15.March.01 Scope Applications Learning & Teaching Design User Interfaces Usage Content Group Docu- Synchro- Process- Security ... Communi- ments nization R. Steinmetz, M. Mühlhäuser ing cations Services © Databases Programming http://www.tk.informatik.tu-darmstadt.de http://www.kom.e-technik.tu-darmstadt.de Media-Server Operating Systems Communications Systems Opt. Memories Quality of Service Networks Compression Computer Archi- Image & Basics Animation Video Audio Scope tectures Graphics Contents 05A-compression.fm 2 15.March.01 Contents 1. Motivation 2. Requirements - General 3. Fundamentals - Categories 4. Source Coding 5. Entropy Coding: 6. Hybrid Coding: Basic Encoding Steps R. Steinmetz, M. Mühlhäuser © 7. JPEG http://www.tk.informatik.tu-darmstadt.de 8. H.261 and related ITU Standards http://www.kom.e-technik.tu-darmstadt.de 9. MPEG-1 10.