INVITED & CONTRIBUTED Through Easychair
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

World Higher Education Database Whed Iau Unesco
WORLD HIGHER EDUCATION DATABASE WHED IAU UNESCO Página 1 de 438 WORLD HIGHER EDUCATION DATABASE WHED IAU UNESCO Education Worldwide // Published by UNESCO "UNION NACIONAL DE EDUCACION SUPERIOR CONTINUA ORGANIZADA" "NATIONAL UNION OF CONTINUOUS ORGANIZED HIGHER EDUCATION" IAU International Alliance of Universities // International Handbook of Universities © UNESCO UNION NACIONAL DE EDUCACION SUPERIOR CONTINUA ORGANIZADA 2017 www.unesco.vg No paragraph of this publication may be reproduced, copied or transmitted without written permission. While every care has been taken in compiling the information contained in this publication, neither the publishers nor the editor can accept any responsibility for any errors or omissions therein. Edited by the UNESCO Information Centre on Higher Education, International Alliance of Universities Division [email protected] Director: Prof. Daniel Odin (Ph.D.) Manager, Reference Publications: Jeremié Anotoine 90 Main Street, P.O. Box 3099 Road Town, Tortola // British Virgin Islands Published 2017 by UNESCO CENTRE and Companies and representatives throughout the world. Contains the names of all Universities and University level institutions, as provided to IAU (International Alliance of Universities Division [email protected] ) by National authorities and competent bodies from 196 countries around the world. The list contains over 18.000 University level institutions from 196 countries and territories. Página 2 de 438 WORLD HIGHER EDUCATION DATABASE WHED IAU UNESCO World Higher Education Database Division [email protected] -

ICBM 2019 Conference Proceedings — Printed Version
ISBN 978-984-344-3540 http://icbm.bracu.ac.bd/ ICBM 2019 CONTENTS Message ii Message from the Conference Chairs iii Keynote Speeches iv Industry Talks viii Invited Talks xv Program Overview xxi Index of Abstracts xxiv Abstracts 1 Organizing Committee 52 Technical Committee 54 International Dignitaries 57 ICBM 2019 K M Khalid MP State Minister Ministry of Cultural Affairs Government of the People’s Republic of Bangladesh Message It is a great honor for me to be involved with the 2nd International Conference on Business and Management (ICBM 2019), organized by Brac Business School, Brac University. I am overwhelmed to know that more than 160 research papers will be presented by 200 local and international participants. Definitely, it reflects an outstanding team work and profound activities which were accompanied by the organizing committee of ICBM 2019. I firmly believe that this conference will help the scholars to develop their career and it will be a great experience for them. Moreover, this conference would help the industry people to think more creatively. It is a great initiative taken by Brac University which will contribute towards the development of the business arena. It is creating opportunities and helping the students to explore themselves in order to fit in the workplace based on global phenomena. I am confident that in future Brac University will take such initiatives by which the society will be benefited at large. Finally, I would like to conclude with best wishes. K M Khalid MP State Minister Ministry of Cultural Affairs Government of the People’s Republic of Bangladesh ii ICBM 2019 MESSAGE FROM THE CONFERENCE CHAIRS Professor Vincent Chang, PhD Honorary General Chair, ICBM 2019 Professor Mohammad Mahboob Rahman, PhD Assoc. -

Bangladeshi University Ranking
RESEARCH HUB 2017 BANGLADESHI UNIVERSITY RANKING ResearchHUB www.the-research-hub.org RESEARCH HUB According to Oxford dictionary1, the word more crucial for the development of the ‘ranking’ means “a position in a hierarchy or country. Quality of higher education and scale”. However, the aim of ResearchHUB research activities at universities plays a Bangladeshi University Ranking is not only to crucial role in developing human capital and position universities in a hierarchy but to exploring the potential of a country. reveal students’ perception about their This report portrays the current status of universities, and to develop a transparent Bangladesh’s major universities, both from a mechanism of presenting research output of student perspective and in terms of the Bangladeshi universities. This would help outreach of academic research. The goal is the university authorities to identify key to boost competitiveness and strengthen development areas and work for continuous transparency among universities. This will improvement. The Government authorities help students to make more informed would have an overview of the country’s choices when they apply for their research output and take necessary actions. undergraduate and post-graduate studies Students would have a review of the leading to increased accountability of universities by their peers that would help universities regarding their education quality them choose their desired institution. and research output. Bangladesh is the eighth largest country in This year, ResearchHUB conducted a survey the world in terms of population with over from April 1 until June 1, 2017. In total 3653 163 million people. However, it still lags responses (3570 are analyzed after omitting behind many other countries in terms of duplicates) are received from students and economic progress and quality of life. -

List of Accepted Papers for the “International Conference On
List of Accepted Papers for the “International Conference on Bioinformatics and Biostatistics for Agriculture, Health and Environment” during 20-23 January, 2017, Venue: Rajshai University Campus, Rajshah Paper Authors/ corresponding Paper Title University/ Presente Paper Present ID authors Institute, Country r Category ation Categor Categor y y (Oral/P oster) 1 Keith A. Crandall Computational Approaches to Computational Keynote Bioinform Oral Biodiversity informatics Biology Institute, atics George Washington University, USA 2 Shinto Eguchi Two Paradigms in Statistical Keynote Bioinform Oral Prediction Institute of Statistical atics Mathematics, Japan. 3 Hirohisa Kishino Statistical modeling of molecular University of Tokyo, Plenary Bioinform Oral evolution and its potential Japan atics 4 Hiroyuki Kurata Virtual cell metabolism for systems Kyushu Institute of Plenary Bioinform Oral and synthetic biology Technology, Japan atics 5 Kenji Mizuguchi Computational systems approaches National Institutes of Plenary Bioinform Oral to drug discovery and development Biomedical atics Innovation, Health and Nutrition, Japan 6 Jun Zhu Mixed Linear Model Approaches of Zhejiang University, Plenary Bioinform Oral Association Mapping for Complex China atics Traits Based on Omics Variants 7 Ming Chen Integrative bioinformatics Zhejiang University, Plenary Bioinform Oral approaches towards whole plant cell China atics modeling 8 Bikas K Sinha Improving the Efficiency of Indian Statistical Plenary Biostatisti Oral Experiments : Role of Covariates in Institute, India cs Design Selection relating to Health Issues 9 Partha P. Majumder Identifying Drivers in Cancer Indian Statistical Plenary Bioinform Oral Genomes: Computational and Institute, Kolkata, atics Statistical Challenges India 10 M. Ataharul Islam Generalized Linear Models for East West Plenary Biostatisti Oral Bivariate Count Data University, cs Bangladesh 11 Md. -

Cflsf,Trffirrfqrrst'f {(Qrrq=Tr{Rnmtqfttfufi Qt"Tlfrdte, E-[St-Seol (Ffinsrr @ Frsrtrrqr Wr Tbrrtrffitr 4Rde Ttgtwitxftgiiwl.Q
s lrill IH' **ffi**' cffinnrR qqr @ Flq'rtrffir Wfrr {RGe r{Gr ry-+ q(Ffs rrErr{ (Manual for [Jnique Student Identification Number) cflsf,tRffirrfqrRst'f {(qrrq=tR{RnmTqftTfufi qt"tlfrdte, E-[st-seol (ffinsrR @ Frsrtrrqr wr tBRrtrffitr 4RDe TTGTwiTxFtgIIWl.q 5. tBfrsP6tr qRG&qrs, sr',Ts ,{<( q$-{{<e errcj-s trrfift-{ RqfrN frrxres-k< ?Efrs fistft "iRffi aq< IslT FflCO Et'<a faffiryffi 6E.fs vTsT<q-< gEK mts frtrfirc-+.rs qE Cfl_S (dt$lT mlv ;FsTft-{ ofr-o q< ooo oo o oo aoooo ooo 5.5. ftqfrqrEs mls'e ffirtqx.s1s B{ effi( qmr <l(E&zt ffirtET rqfr ofu.lr*n q-fle qlc,ffi <-srlt-{ Fist TFfu{ E-fll=l <rr6q.* RqfrRrrqmTcq< aefiskE< Gfrre ffi,,- Rrn-{ QCr rr {( T-{lc{ ERRfs cs'fs ryRXB ffir< ffir61 crts R{6a ,tqI EFI sfr-s" Rffinirqrqr m RqRq-ifET mts I North South University 001 2. University of Science & Technology Chittagong 002 J. Independent University, Bangladesh 003 4. Central Women's University 004 5. Intemational University of Business Agriculture & 005 Iechnology 6. lnternational Islamic University Chittagong 006 7. Ahsanullah University of Science and Technology 007 8. American International University Bangladesh 008 9. East West University 009 10. University of Asia Pacific 010 11 Gono Bishwabidyalay 0ll 12. The People's University of Bangladesh 012 13. Asian University of Bangladesh 013 14. Dhaka International University 0t4 c* ,dftffiffi fralOlner Frruque Dircctor 6 lrivra Udvcrsity Divicion Ulvcnfty Oruu Cmrirdre.f &Eldcri Alrrtrn, Dhrke-I207. sfro R{RqnEr-q{ ilr R,tfrqrl-Ex crrs 15. Manarat International University 015 16. BRAC University 016 t7. -

Journalism Education in Bangladesh: from Aspiring Journalists to Career Professionals
EDITION DW AKADEMIE | 2019 Journalism education in Bangladesh From aspiring journalists to career professionals Imprint PUBLISHER AUTHORS RESPONSIBLE EDITORS Deutsche Welle Prof. Jude William Genilo, PhD Carsten von Nahmen Dr. Esther Dorn-Fellermann 53110 Bonn Prof. Fahmidul Haq, PhD Michael Karhausen Dr. Dennis Reineck Germany Shameem Mahmud, PhD PUBLISHED © DW Akademie October 2019 Journalism education in Bangladesh From aspiring journalists to career professionals Jude William Genilo, Fahmidul Haq, Shameem Mahmud ACKNOWLEDGEMENTS Acknowledgements First of all, we would like to express our sincere thanks to DW Akademie for this initiative. The importance of this study lies in its main research questions: What factors facilitate or inhibit aspiring Bangladeshi journalists to prepare for and join the pro- fession and what factors enable or restrict them from acquiring the necessary skill sets (particularly in educational institutions and media outlets) to succeed in journalism. The insights gath- ered from this will aid both the industry and academia to help the profession of journalism progress to a new level. A research study of this magnitude requires a lot of sup- port from so many people. We would like to express our sin- cere thanks to the advisors from DW Akademie: Dr. Esther Dorn- Fellermann and Dr. Dennis Reineck (Project Managers, DW Akademie) as well as Priya Esselborn (Country Manager Bangladesh, DW Akademie) who gave us multitudes of good advice on the study’s methodology. Before this study was finalized, it was presented to the heads and faculty members of journalism departments in Bangladesh. We would like to thank them for the feedback they gave during the Networking Conference held on November 28, 2018 at the University of Chittagong. -

A Webometric Analysis of Private University Websites in Bangladesh
A Webometric Analysis of Private University Websites in Bangladesh A Webometric Analysis of Private University Websites in Bangladesh By Sajia Sultana A Dissertation Submitted in Partial Fulfilment of the Requirements for the Degree of Master of Philosophy Department of Information Science and Library Management University of Dhaka, Bangladesh July 2014 S.M. Zabed Ahmed, PhD Professor and Chair Department of Information Science and Library Management, University of Dhaka, Dhaka-1000 CERTIFICATE This is to certify that the thesis entitled “A Webometric Analysis of Private university Websites in Bangladesh” submitted by Sajia Sultana, for the degree of Master of Philosophy (MPhil) in the Department of Information Science and Library Management, University of Dhaka, is her original work carried out under my supervision and guidance, and is worthy of examination. Dr. S.M. Zabed Ahmed Supervisor Abstract There have been many research studies conducted on webometrics, especially on the impact of websites and the web impact factor. This current research analyzes the private university websites in Bangladesh according to some common webometrics indicators. It examines and explores 54 private university websites in Bangladesh and identifies the number of web pages and link pages, and calculates their Simple Web Impact Factor, Self-link Web Impact Factor and External link Web Impact Factor. The results indicate that some private universities have relatively high number of web pages, but correspondingly their link pages are low in number and the websites fall behind in their simple, self-link and external link web impact factors. It is also found that the external link web pages provide more than other link pages. -

46 Annual Report 2019
46th Annual Report 2019 (Executive Summary) University Grants Commission of Bangladesh 46th Annual Report 2019 (Executive Summary) University Grants Commission of Bangladesh 46th Annual Report 2019 --------------------------------------------------(Executive Summary) ------------------------------------------------ Year of Publication: December 2020 Published by The University Grants Commission of Bangladesh UGC Building, Plot # E-18/A, Agargaon Administrative Area, Sher-e-Bangla Nagar, Dhaka-1207 Phone: + 88-02-58160100, 58160208 Fax: 88-02-58160202, 58160206 E-mail: [email protected] Website: www.ugc.gov.bd UGC Publication Number- 215 Editorial Board 1. Professor Dr. Kazi Shahidullah, Chairman, UGC - Chief Patron 2. Professor Dr. Md. Sazzad Hossain, Member, UGC - Chief Editor 3. Professor Dr. Dil Afroza Begum, Member, UGC - Member 4. Professor Dr. Muhammed Alamgir, Member, UGC - Member 5. Professor Dr. Biswajit Chanda, Member, UGC - Member 6. Professor Dr. Md. Abu Taher, Member, UGC - Member 7. Dr. Ferdous Zaman, Secretary (Additional Charge), UGC - Member 8. Mr. Md. Omar Faruque, Director (Current Charge), RSP Division, UGC - Member 9. Ms. Nahid Sultana, Additional Director, RSP Division, UGC - Member 10. Mr. Md. Shahin Siraj, Deputy Director (Publication), RSP Division, UGC - Member-Secretary Data collection, refinement, development, analysis and research Jalal Ahmed, Bishwanath Biswas and Srijan Chakraborti Translation Editing Committee Dr. Md. Fakhrul Islam, Director, SPQA Division, UGC - Convener Mr. Md. Shahin Siraj, Deputy -

IJCCI 2018 Program Schedule
IJCCI 2018 Program Schedule Day 1: Friday 14 December, 2018 @ 71 Milonayoton, Daffodil Tower, Sobhanbug, Dhaka Time Session Venue 03:00 – 03:30 Registration Lobby, 71 milonayoton, Daffodil Tower 04:00-04:30 Inauguration 71 milonayoton, 04:02 Daffodil Theme Song Daffodil Tower 04:05 Welcome address by Vice Chancellor, Daffodil International University 04:10 Address of IJCCI 2018 TPC Chair 04:15 Address by the Guest of Honor 04:20 Address by the Special Guest 04:30 Address by the Chief Guest 04:45 – 05:15 Topic: The importance of indigenous development of 71 milonayoton, Keynote Talk-1 computer based technology in healthcare- seen through a Daffodil Tower chronicle of our own efforts Chair: Prof Syed Akhter Hossain, General Chair, IJCCI 2018 Speaker: K Siddique-e Rabbani,Honorary Professor, Dept of Biomedical Physics & Technology,University of Dhaka, Dhaka, Bangladesh 05:30 Tea Break Banquet, Level 8, Daffodil Tower 06:00-07:30 Networking and Conference Dinner Banquet, Level 8, Daffodil Tower IJCCI 2018 Program Schedule Day 2: Saturday 15 December, 2018 @ 71 Milonayoton, Daffodil Tower, Sobhanbug, Dhaka Time Session Venue 09:00 – 09:40 Registration Lobby, 71 milonayoton, Daffodil Tower 10:00 – 10:45 Topic: Prediction based on biological sequences, where 71 milonayoton, Keynote Talk-2 Machine Learning meets Life Sciences Daffodil Tower Chair: Prof Mohammed Shorif Uddin, General and TPC Chair, IJCCI 2018 Speaker: Professor Sohel Rahman Department of Computer Science and Engineering Bangladesh University of Engineering and Technology (BUET) 10:45 Tea Break Banquet, Level 8, Daffodil Tower IJCCI 2018 Program Schedule Technical Session A: Soft Computing and Optimization Room# 803 Day 2: Saturday 15 December, 2018 @ 71 Milonayoton, Daffodil Tower, Sobhanbug, Dhaka Time Session Venue 11:15-12:25 Chair: Prof Dr. -
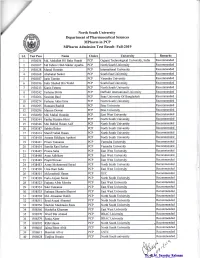
Mpharm Admission Test Result, Fall19
North South University Department of Pharmaceutical Sciences MPharm in PCP MPharm Admission Test Result- F'all-2019 s.r- Test Pass Name Choice University Remarks i 938036 Md. Abdullah Hil Baky Rupak PCP Gujarat Technological University, India Recommended 2 938 0v Md Fahim Ullah Sikder Apurba PCP North South University Recommended 3 938 28 Murad Hossain PCP Intemational UniversiE Recommended 4 938 68 Abubakar Sarker PCP South East University Recommended 5 938 87 Iarin Tasnim PCF Varendra Universi8 Recommended 6 938 96 Fakir Shahed Bin Walid PCP South East University Recommended 7 938213 Kaniz Fatems PCP North South [.lniversity Recommended I 938242 Farhana Shirin PCP Daffodil International University Recommended 9 938266 Susmita Baui PCP State University Of Bangiadesh Recommended 0 938274 Farhana Akter Emu PCP North South University Recommended 1 938295 Humaira Rashid PCP Brac {.Jniversity Recommended 2 938296 Marzan Dewan PCP Brac University Recommended J 93 8050 Md. Mukul Hossain PCP East West University Recommended 4 938344 Fariha Mariam Himi PCP North South University Recommended 5 938346 Md. Rabiul Hasan Asif PCP North South University Recommended 6 938387 Sabiha Baker PCP North South UniversiE Recommended 7 938414 Sharif Nahid Hasan PCP North South University R.ecommended I 93 841 8 Amena Siddique Apshori PCP North South Universif Recomrnended 9 93843 I Prium Tamanna PCP Varendra University Recommended 2A 938434 Sumita Rani Serker PCP Varendra University Recommended 21 938445 Proma Saha PCP East West University Recommended 22 938448 -

University Grants Commission of Bangladesh Agargaon Administrative Area, Sher-E-Bangla Nagar, Dhaka-1207
Government of the People’s Republic of Bangladesh University Grants Commission of Bangladesh Agargaon Administrative Area, Sher-e-Bangla Nagar, Dhaka-1207 www.ugc.gov.bd No. 37.01.0000.002.45.02.21.1817 Date: 04/04/2021 Subject: Fulbright Foreign Student Program for 2022-2023 Academic Years. Ref: E-mail from US Embassy, Dhaka; Date: 23 March, 2021 With the above-mentioned subject and reference, the undersigned is conveying with pleasure that the Fulbright Foreign Student Program for 2022-2023 Academic Years has been announced. The program will provide the graduate students and the young professionals with an opportunity to pursue a fully funded Master’s degree in the United States. The deadline for submission of application is 15 May 2021. Details of this announcement are available at https://bd.usembassy.gov/25254/ and please visit https://bd.usembassy.gov/education-culture/student-exchange-programs/. to find more information. The application form is available at https://apply.iie.org/ffsp2022. 02. Hence, you are kindly requested to take a proper arrangement for an extensive publicity on the Central, each of Institutional and Departmental notice boards and also to upload at the websites of your university. 04.04.2021 Mohammad Maksudur Rahman Bhuiyan Additional Director (ICC) Distribution (Not on the basis of seniority): Registrar/s: Dhaka/ Rajshahi/ Bangladesh Agricultural/ Bangladesh University of Engineering & Technology/ Chittagong/ Jahngirnagar/ Islamic University/ Shahjalal University of Science & Technology/ Khulna/ National/ Bangladesh -

A Comparative Study of the Quality of Higher Education Provision in Public and Private Universities in Bangladesh
Global Journal of Educational Studies ISSN 2377-3936 2021, Vol. 7, No. 1 A Comparative Study of the Quality of Higher Education Provision in Public and Private Universities in Bangladesh Dr. Md. Ruhul Amin Associate Professor Department of Public Administration Comilla University, Cumilla-3505, Bangladesh E-mail: [email protected] Md. Rashidul Islam Sheikh Associate Professor Department of Public Administration Comilla University, Cumilla-3506, Bangladesh E-mail: [email protected] Received: April 24, 2021 Accepted: May 6, 2021 Published: June 5, 2021 doi:10.5296/gjes.v7i1.18725 URL: https://doi.org/10.5296/gjes.v7i1.18725 Abstract The evolution of a modern society largely depends on the essence of quality higher education. In a developing country, higher education has enormous potential to foster its development. Universities all over the world are changing actors of culture and remain the center of transformation and growth. Different Education Commissions have been formed in Bangladesh to explore the potentialities and create highly skilled human resources to contribute the national development (Topader, 2021). Due to the economic and globalization change emphasis on the quality education in education policy across the world. As a result, policymakers, academicians, and professionals in Bangladesh have expressed various issues regarding the quality of higher education. Over the last two decades, the standard of higher education in Bangladesh has steadily deteriorated (Rabbani & Chowdhury, 2014). In this regard, the government, ministry, and UGC have taken various initiatives to ensure quality 1 Global Journal of Educational Studies ISSN 2377-3936 2021, Vol. 7, No. 1 higher education, especially at the tertiary level, to meet global demand.