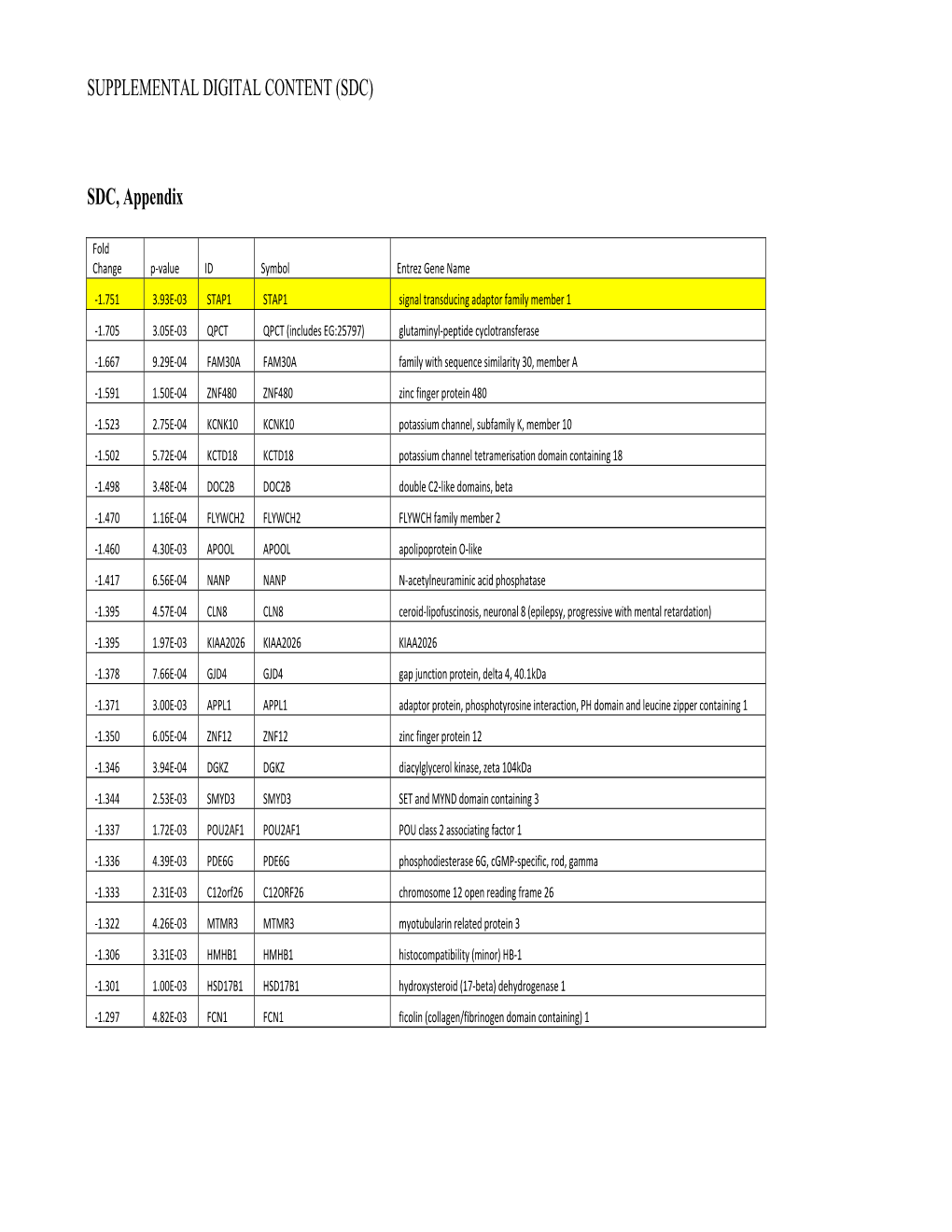
SUPPLEMENTAL DIGITAL CONTENT (SDC) SDC, Appendix
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![FK506-Binding Protein 12.6/1B, a Negative Regulator of [Ca2+], Rescues Memory and Restores Genomic Regulation in the Hippocampus of Aging Rats](https://docslib.b-cdn.net/cover/6136/fk506-binding-protein-12-6-1b-a-negative-regulator-of-ca2-rescues-memory-and-restores-genomic-regulation-in-the-hippocampus-of-aging-rats-16136.webp)
FK506-Binding Protein 12.6/1B, a Negative Regulator of [Ca2+], Rescues Memory and Restores Genomic Regulation in the Hippocampus of Aging Rats
This Accepted Manuscript has not been copyedited and formatted. The final version may differ from this version. A link to any extended data will be provided when the final version is posted online. Research Articles: Neurobiology of Disease FK506-Binding Protein 12.6/1b, a negative regulator of [Ca2+], rescues memory and restores genomic regulation in the hippocampus of aging rats John C. Gant1, Eric M. Blalock1, Kuey-Chu Chen1, Inga Kadish2, Olivier Thibault1, Nada M. Porter1 and Philip W. Landfield1 1Department of Pharmacology & Nutritional Sciences, University of Kentucky, Lexington, KY 40536 2Department of Cell, Developmental and Integrative Biology, University of Alabama at Birmingham, Birmingham, AL 35294 DOI: 10.1523/JNEUROSCI.2234-17.2017 Received: 7 August 2017 Revised: 10 October 2017 Accepted: 24 November 2017 Published: 18 December 2017 Author contributions: J.C.G. and P.W.L. designed research; J.C.G., E.M.B., K.-c.C., and I.K. performed research; J.C.G., E.M.B., K.-c.C., I.K., and P.W.L. analyzed data; J.C.G., E.M.B., O.T., N.M.P., and P.W.L. wrote the paper. Conflict of Interest: The authors declare no competing financial interests. NIH grants AG004542, AG033649, AG052050, AG037868 and McAlpine Foundation for Neuroscience Research Corresponding author: Philip W. Landfield, [email protected], Department of Pharmacology & Nutritional Sciences, University of Kentucky, 800 Rose Street, UKMC MS 307, Lexington, KY 40536 Cite as: J. Neurosci ; 10.1523/JNEUROSCI.2234-17.2017 Alerts: Sign up at www.jneurosci.org/cgi/alerts to receive customized email alerts when the fully formatted version of this article is published. -

A Novel Approach to Identify Driver Genes Involved in Androgen-Independent Prostate Cancer
Schinke et al. Molecular Cancer 2014, 13:120 http://www.molecular-cancer.com/content/13/1/120 RESEARCH Open Access A novel approach to identify driver genes involved in androgen-independent prostate cancer Ellyn N Schinke1, Victor Bii1, Arun Nalla1, Dustin T Rae1, Laura Tedrick1, Gary G Meadows1 and Grant D Trobridge1,2* Abstract Background: Insertional mutagenesis screens have been used with great success to identify oncogenes and tumor suppressor genes. Typically, these screens use gammaretroviruses (γRV) or transposons as insertional mutagens. However, insertional mutations from replication-competent γRVs or transposons that occur later during oncogenesis can produce passenger mutations that do not drive cancer progression. Here, we utilized a replication-incompetent lentiviral vector (LV) to perform an insertional mutagenesis screen to identify genes in the progression to androgen-independent prostate cancer (AIPC). Methods: Prostate cancer cells were mutagenized with a LV to enrich for clones with a selective advantage in an androgen-deficient environment provided by a dysregulated gene(s) near the vector integration site. We performed our screen using an in vitro AIPC model and also an in vivo xenotransplant model for AIPC. Our approach identified proviral integration sites utilizing a shuttle vector that allows for rapid rescue of plasmids in E. coli that contain LV long terminal repeat (LTR)-chromosome junctions. This shuttle vector approach does not require PCR amplification and has several advantages over PCR-based techniques. Results: Proviral integrations were enriched near prostate cancer susceptibility loci in cells grown in androgen- deficient medium (p < 0.001), and five candidate genes that influence AIPC were identified; ATPAF1, GCOM1, MEX3D, PTRF, and TRPM4. -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Genome-Wide Analysis Reveals Selection Signatures Involved in Meat Traits and Local Adaptation in Semi-Feral Maremmana Cattle
Genome-Wide Analysis Reveals Selection Signatures Involved in Meat Traits and Local Adaptation in Semi-Feral Maremmana Cattle Slim Ben-Jemaa, Gabriele Senczuk, Elena Ciani, Roberta Ciampolini, Gennaro Catillo, Mekki Boussaha, Fabio Pilla, Baldassare Portolano, Salvatore Mastrangelo To cite this version: Slim Ben-Jemaa, Gabriele Senczuk, Elena Ciani, Roberta Ciampolini, Gennaro Catillo, et al.. Genome-Wide Analysis Reveals Selection Signatures Involved in Meat Traits and Local Adaptation in Semi-Feral Maremmana Cattle. Frontiers in Genetics, Frontiers, 2021, 10.3389/fgene.2021.675569. hal-03210766 HAL Id: hal-03210766 https://hal.inrae.fr/hal-03210766 Submitted on 28 Apr 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License ORIGINAL RESEARCH published: 28 April 2021 doi: 10.3389/fgene.2021.675569 Genome-Wide Analysis Reveals Selection Signatures Involved in Meat Traits and Local Adaptation in Semi-Feral Maremmana Cattle Slim Ben-Jemaa 1, Gabriele Senczuk 2, Elena Ciani 3, Roberta -
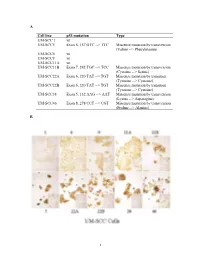
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Replace This with the Actual Title Using All Caps
UNDERSTANDING THE GENETICS UNDERLYING MASTITIS USING A MULTI-PRONGED APPROACH A Dissertation Presented to the Faculty of the Graduate School of Cornell University In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Asha Marie Miles December 2019 © 2019 Asha Marie Miles UNDERSTANDING THE GENETICS UNDERLYING MASTITIS USING A MULTI-PRONGED APPROACH Asha Marie Miles, Ph. D. Cornell University 2019 This dissertation addresses deficiencies in the existing genetic characterization of mastitis due to granddaughter study designs and selection strategies based primarily on lactation average somatic cell score (SCS). Composite milk samples were collected across 6 sampling periods representing key lactation stages: 0-1 day in milk (DIM), 3- 5 DIM, 10-14 DIM, 50-60 DIM, 90-110 DIM, and 210-230 DIM. Cows were scored for front and rear teat length, width, end shape, and placement, fore udder attachment, udder cleft, udder depth, rear udder height, and rear udder width. Independent multivariable logistic regression models were used to generate odds ratios for elevated SCC (≥ 200,000 cells/ml) and farm-diagnosed clinical mastitis. Within our study cohort, loose fore udder attachment, flat teat ends, low rear udder height, and wide rear teats were associated with increased odds of mastitis. Principal component analysis was performed on these traits to create a single new phenotype describing mastitis susceptibility based on these high-risk phenotypes. Cows (N = 471) were genotyped on the Illumina BovineHD 777K SNP chip and considering all 14 traits of interest, a total of 56 genome-wide associations (GWA) were performed and 28 significantly associated quantitative trait loci (QTL) were identified. -

Identification of Genes Concordantly Expressed with Atoh1 During Inner Ear Development
Original Article doi: 10.5115/acb.2011.44.1.69 pISSN 2093-3665 eISSN 2093-3673 Identification of genes concordantly expressed with Atoh1 during inner ear development Heejei Yoon, Dong Jin Lee, Myoung Hee Kim, Jinwoong Bok Department of Anatomy, Brain Korea 21 Project for Medical Science, College of Medicine, Yonsei University, Seoul, Korea Abstract: The inner ear is composed of a cochlear duct and five vestibular organs in which mechanosensory hair cells play critical roles in receiving and relaying sound and balance signals to the brain. To identify novel genes associated with hair cell differentiation or function, we analyzed an archived gene expression dataset from embryonic mouse inner ear tissues. Since atonal homolog 1a (Atoh1) is a well known factor required for hair cell differentiation, we searched for genes expressed in a similar pattern with Atoh1 during inner ear development. The list from our analysis includes many genes previously reported to be involved in hair cell differentiation such as Myo6, Tecta, Myo7a, Cdh23, Atp6v1b1, and Gfi1. In addition, we identified many other genes that have not been associated with hair cell differentiation, including Tekt2, Spag6, Smpx, Lmod1, Myh7b, Kif9, Ttyh1, Scn11a and Cnga2. We examined expression patterns of some of the newly identified genes using real-time polymerase chain reaction and in situ hybridization. For example, Smpx and Tekt2, which are regulators for cytoskeletal dynamics, were shown specifically expressed in the hair cells, suggesting a possible role in hair cell differentiation or function. Here, by re- analyzing archived genetic profiling data, we identified a list of novel genes possibly involved in hair cell differentiation. -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

Transcriptional Events Co-Regulated by Hypoxia and Cold Stresses In
Long et al. BMC Genomics (2015) 16:385 DOI 10.1186/s12864-015-1560-y RESEARCH ARTICLE Open Access Transcriptional events co-regulated by hypoxia and cold stresses in Zebrafish larvae Yong Long1, Junjun Yan1,2, Guili Song1, Xiaohui Li1,2, Xixi Li1,2, Qing Li1* and Zongbin Cui1* Abstract Background: Hypoxia and temperature stress are two major adverse environmental conditions often encountered by fishes. The interaction between hypoxia and temperature stresses has been well documented and oxygen is considered to be the limiting factor for the thermal tolerance of fish. Although both high and low temperature stresses can impair the cardiovascular function and the cross-resistance between hypoxia and heat stress has been found, it is not clear whether hypoxia acclimation can protect fish from cold injury. Results: Pre-acclimation of 96-hpf zebrafish larvae to mild hypoxia (5% O2) significantly improved their resistance to lethal hypoxia (2.5% O2) and increased the survival rate of zebrafish larvae after lethal cold (10°C) exposure. However, pre-acclimation of 96-hpf larvae to cold (18°C) decreased their tolerance to lethal hypoxia although their ability to endure lethal cold increased. RNA-seq analysis identified 132 up-regulated and 41 down-regulated genes upon mild hypoxia exposure. Gene ontology enrichment analyses revealed that genes up-regulated by hypoxia are primarily involved in oxygen transport, oxidation-reduction process, hemoglobin biosynthetic process, erythrocyte development and cellular iron ion homeostasis. Hypoxia-inhibited genes are enriched in inorganic anion transport, sodium ion transport, very long-chain fatty acid biosynthetic process and cytidine deamination. A comparison with the dataset of cold-regulated gene expression identified 23 genes co-induced by hypoxia and cold and these genes are mainly associated with oxidation-reduction process, oxygen transport, hemopoiesis, hemoglobin biosynthetic process and cellular iron ion homeostasis. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

A Molecular and Genetic Analysis of Otosclerosis
A molecular and genetic analysis of otosclerosis Joanna Lauren Ziff Submitted for the degree of PhD University College London January 2014 1 Declaration I, Joanna Ziff, confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indicated in the thesis. Where work has been conducted by other members of our laboratory, this has been indicated by an appropriate reference. 2 Abstract Otosclerosis is a common form of conductive hearing loss. It is characterised by abnormal bone remodelling within the otic capsule, leading to formation of sclerotic lesions of the temporal bone. Encroachment of these lesions on to the footplate of the stapes in the middle ear leads to stapes fixation and subsequent conductive hearing loss. The hereditary nature of otosclerosis has long been recognised due to its recurrence within families, but its genetic aetiology is yet to be characterised. Although many familial linkage studies and candidate gene association studies to investigate the genetic nature of otosclerosis have been performed in recent years, progress in identifying disease causing genes has been slow. This is largely due to the highly heterogeneous nature of this condition. The research presented in this thesis examines the molecular and genetic basis of otosclerosis using two next generation sequencing technologies; RNA-sequencing and Whole Exome Sequencing. RNA–sequencing has provided human stapes transcriptomes for healthy and diseased stapes, and in combination with pathway analysis has helped identify genes and molecular processes dysregulated in otosclerotic tissue. Whole Exome Sequencing has been employed to investigate rare variants that segregate with otosclerosis in affected families, and has been followed by a variant filtering strategy, which has prioritised genes found to be dysregulated during RNA-sequencing. -

Primate Specific Retrotransposons, Svas, in the Evolution of Networks That Alter Brain Function
Title: Primate specific retrotransposons, SVAs, in the evolution of networks that alter brain function. Olga Vasieva1*, Sultan Cetiner1, Abigail Savage2, Gerald G. Schumann3, Vivien J Bubb2, John P Quinn2*, 1 Institute of Integrative Biology, University of Liverpool, Liverpool, L69 7ZB, U.K 2 Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK 3 Division of Medical Biotechnology, Paul-Ehrlich-Institut, Langen, D-63225 Germany *. Corresponding author Olga Vasieva: Institute of Integrative Biology, Department of Comparative genomics, University of Liverpool, Liverpool, L69 7ZB, [email protected] ; Tel: (+44) 151 795 4456; FAX:(+44) 151 795 4406 John Quinn: Department of Molecular and Clinical Pharmacology, Institute of Translational Medicine, The University of Liverpool, Liverpool L69 3BX, UK, [email protected]; Tel: (+44) 151 794 5498. Key words: SVA, trans-mobilisation, behaviour, brain, evolution, psychiatric disorders 1 Abstract The hominid-specific non-LTR retrotransposon termed SINE–VNTR–Alu (SVA) is the youngest of the transposable elements in the human genome. The propagation of the most ancient SVA type A took place about 13.5 Myrs ago, and the youngest SVA types appeared in the human genome after the chimpanzee divergence. Functional enrichment analysis of genes associated with SVA insertions demonstrated their strong link to multiple ontological categories attributed to brain function and the disorders. SVA types that expanded their presence in the human genome at different stages of hominoid life history were also associated with progressively evolving behavioural features that indicated a potential impact of SVA propagation on a cognitive ability of a modern human.