A Resource for Exploring the Understudied Human Kinome for Research and Therapeutic
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Characterization of Protein Kinase C Alpha Deficiency in a Mouse Model
Aus der Medizinischen Klinik mit Schwerpunkt Infektiologie und Pneumologie der Charité – Universitätsmedizin Berlin Eingereicht über das Institut für Veterinär-Physiologie des Fachbereichs Veterinärmedizin der Freien Universität Berlin Characterization of Protein Kinase C Alpha Deficiency in a Mouse Model Inaugural-Dissertation zur Erlangung des Doctor of Philosophy (Ph.D.) an der Freien Universität Berlin vorgelegt von Elena Ariane Noe Tierärztin aus Düsseldorf Berlin 2016 Journal-Nr.: 3878 Gedruckt mit Genehmigung des Fachbereichs Veterinärmedizin der Freien Universität Berlin Dekan: Univ.-Prof. Dr. Jürgen Zentek Erster Gutachter: Prof. Dr. Dr. Petra Reinhold Zweiter Gutachter: Univ.-Prof. Dr. Martin Witzenrath Dritter Gutachter: Univ.-Prof. Dr. Christa Thöne-Reineke Deskriptoren (nach CAB-Thesaurus): Mice; animal models; protein kinase C (MeSH); pulmonary artery; hypertension; blood pressure, vasoconstriction; esophageal sphincter, lower (MeSH); respiratory system; smooth muscle; esophageal achalasia (MeSH) Tag der Promotion: 14.07.2016 Contents Contents ................................................................................................................................... V List of Abbreviations ............................................................................................................... VII 1 Introduction ................................................................................................................. 1 1.1 Protein Kinase C (PKC) and its Role in Smooth Muscle Contraction ........................ -

Supplemental Information to Mammadova-Bach Et Al., “Laminin Α1 Orchestrates VEGFA Functions in the Ecosystem of Colorectal Carcinogenesis”
Supplemental information to Mammadova-Bach et al., “Laminin α1 orchestrates VEGFA functions in the ecosystem of colorectal carcinogenesis” Supplemental material and methods Cloning of the villin-LMα1 vector The plasmid pBS-villin-promoter containing the 3.5 Kb of the murine villin promoter, the first non coding exon, 5.5 kb of the first intron and 15 nucleotides of the second villin exon, was generated by S. Robine (Institut Curie, Paris, France). The EcoRI site in the multi cloning site was destroyed by fill in ligation with T4 polymerase according to the manufacturer`s instructions (New England Biolabs, Ozyme, Saint Quentin en Yvelines, France). Site directed mutagenesis (GeneEditor in vitro Site-Directed Mutagenesis system, Promega, Charbonnières-les-Bains, France) was then used to introduce a BsiWI site before the start codon of the villin coding sequence using the 5’ phosphorylated primer: 5’CCTTCTCCTCTAGGCTCGCGTACGATGACGTCGGACTTGCGG3’. A double strand annealed oligonucleotide, 5’GGCCGGACGCGTGAATTCGTCGACGC3’ and 5’GGCCGCGTCGACGAATTCACGC GTCC3’ containing restriction site for MluI, EcoRI and SalI were inserted in the NotI site (present in the multi cloning site), generating the plasmid pBS-villin-promoter-MES. The SV40 polyA region of the pEGFP plasmid (Clontech, Ozyme, Saint Quentin Yvelines, France) was amplified by PCR using primers 5’GGCGCCTCTAGATCATAATCAGCCATA3’ and 5’GGCGCCCTTAAGATACATTGATGAGTT3’ before subcloning into the pGEMTeasy vector (Promega, Charbonnières-les-Bains, France). After EcoRI digestion, the SV40 polyA fragment was purified with the NucleoSpin Extract II kit (Machery-Nagel, Hoerdt, France) and then subcloned into the EcoRI site of the plasmid pBS-villin-promoter-MES. Site directed mutagenesis was used to introduce a BsiWI site (5’ phosphorylated AGCGCAGGGAGCGGCGGCCGTACGATGCGCGGCAGCGGCACG3’) before the initiation codon and a MluI site (5’ phosphorylated 1 CCCGGGCCTGAGCCCTAAACGCGTGCCAGCCTCTGCCCTTGG3’) after the stop codon in the full length cDNA coding for the mouse LMα1 in the pCIS vector (kindly provided by P. -

Gene Symbol Gene Description ACVR1B Activin a Receptor, Type IB
Table S1. Kinase clones included in human kinase cDNA library for yeast two-hybrid screening Gene Symbol Gene Description ACVR1B activin A receptor, type IB ADCK2 aarF domain containing kinase 2 ADCK4 aarF domain containing kinase 4 AGK multiple substrate lipid kinase;MULK AK1 adenylate kinase 1 AK3 adenylate kinase 3 like 1 AK3L1 adenylate kinase 3 ALDH18A1 aldehyde dehydrogenase 18 family, member A1;ALDH18A1 ALK anaplastic lymphoma kinase (Ki-1) ALPK1 alpha-kinase 1 ALPK2 alpha-kinase 2 AMHR2 anti-Mullerian hormone receptor, type II ARAF v-raf murine sarcoma 3611 viral oncogene homolog 1 ARSG arylsulfatase G;ARSG AURKB aurora kinase B AURKC aurora kinase C BCKDK branched chain alpha-ketoacid dehydrogenase kinase BMPR1A bone morphogenetic protein receptor, type IA BMPR2 bone morphogenetic protein receptor, type II (serine/threonine kinase) BRAF v-raf murine sarcoma viral oncogene homolog B1 BRD3 bromodomain containing 3 BRD4 bromodomain containing 4 BTK Bruton agammaglobulinemia tyrosine kinase BUB1 BUB1 budding uninhibited by benzimidazoles 1 homolog (yeast) BUB1B BUB1 budding uninhibited by benzimidazoles 1 homolog beta (yeast) C9orf98 chromosome 9 open reading frame 98;C9orf98 CABC1 chaperone, ABC1 activity of bc1 complex like (S. pombe) CALM1 calmodulin 1 (phosphorylase kinase, delta) CALM2 calmodulin 2 (phosphorylase kinase, delta) CALM3 calmodulin 3 (phosphorylase kinase, delta) CAMK1 calcium/calmodulin-dependent protein kinase I CAMK2A calcium/calmodulin-dependent protein kinase (CaM kinase) II alpha CAMK2B calcium/calmodulin-dependent -

Small Cell Ovarian Carcinoma: Genomic Stability and Responsiveness to Therapeutics
Gamwell et al. Orphanet Journal of Rare Diseases 2013, 8:33 http://www.ojrd.com/content/8/1/33 RESEARCH Open Access Small cell ovarian carcinoma: genomic stability and responsiveness to therapeutics Lisa F Gamwell1,2, Karen Gambaro3, Maria Merziotis2, Colleen Crane2, Suzanna L Arcand4, Valerie Bourada1,2, Christopher Davis2, Jeremy A Squire6, David G Huntsman7,8, Patricia N Tonin3,4,5 and Barbara C Vanderhyden1,2* Abstract Background: The biology of small cell ovarian carcinoma of the hypercalcemic type (SCCOHT), which is a rare and aggressive form of ovarian cancer, is poorly understood. Tumourigenicity, in vitro growth characteristics, genetic and genomic anomalies, and sensitivity to standard and novel chemotherapeutic treatments were investigated in the unique SCCOHT cell line, BIN-67, to provide further insight in the biology of this rare type of ovarian cancer. Method: The tumourigenic potential of BIN-67 cells was determined and the tumours formed in a xenograft model was compared to human SCCOHT. DNA sequencing, spectral karyotyping and high density SNP array analysis was performed. The sensitivity of the BIN-67 cells to standard chemotherapeutic agents and to vesicular stomatitis virus (VSV) and the JX-594 vaccinia virus was tested. Results: BIN-67 cells were capable of forming spheroids in hanging drop cultures. When xenografted into immunodeficient mice, BIN-67 cells developed into tumours that reflected the hypercalcemia and histology of human SCCOHT, notably intense expression of WT-1 and vimentin, and lack of expression of inhibin. Somatic mutations in TP53 and the most common activating mutations in KRAS and BRAF were not found in BIN-67 cells by DNA sequencing. -

Transcriptomic Profiling of Equine and Viral Genes in Peripheral Blood
pathogens Article Transcriptomic Profiling of Equine and Viral Genes in Peripheral Blood Mononuclear Cells in Horses during Equine Herpesvirus 1 Infection Lila M. Zarski 1, Patty Sue D. Weber 2, Yao Lee 1 and Gisela Soboll Hussey 1,* 1 Department of Pathobiology and Diagnostic Investigation, Michigan State University, East Lansing, MI 48824, USA; [email protected] (L.M.Z.); [email protected] (Y.L.) 2 Department of Large Animal Clinical Sciences, Michigan State University, East Lansing, MI 48824, USA; [email protected] * Correspondence: [email protected] Abstract: Equine herpesvirus 1 (EHV-1) affects horses worldwide and causes respiratory dis- ease, abortions, and equine herpesvirus myeloencephalopathy (EHM). Following infection, a cell- associated viremia is established in the peripheral blood mononuclear cells (PBMCs). This viremia is essential for transport of EHV-1 to secondary infection sites where subsequent immunopathol- ogy results in diseases such as abortion or EHM. Because of the central role of PBMCs in EHV-1 pathogenesis, our goal was to establish a gene expression analysis of host and equine herpesvirus genes during EHV-1 viremia using RNA sequencing. When comparing transcriptomes of PBMCs during peak viremia to those prior to EHV-1 infection, we found 51 differentially expressed equine genes (48 upregulated and 3 downregulated). After gene ontology analysis, processes such as the interferon defense response, response to chemokines, the complement protein activation cascade, cell adhesion, and coagulation were overrepresented during viremia. Additionally, transcripts for EHV-1, EHV-2, and EHV-5 were identified in pre- and post-EHV-1-infection samples. Looking at Citation: Zarski, L.M.; Weber, P.S.D.; micro RNAs (miRNAs), 278 known equine miRNAs and 855 potentially novel equine miRNAs were Lee, Y.; Soboll Hussey, G. -

Mtor Coordinates Transcriptional Programs and Mitochondrial Metabolism of Activated Treg Subsets to Protect Tissue Homeostasis
ARTICLE DOI: 10.1038/s41467-018-04392-5 OPEN mTOR coordinates transcriptional programs and mitochondrial metabolism of activated Treg subsets to protect tissue homeostasis Nicole M. Chapman1, Hu Zeng 1, Thanh-Long M. Nguyen1, Yanyan Wang1, Peter Vogel 2, Yogesh Dhungana1, Xiaojing Liu3, Geoffrey Neale 4, Jason W. Locasale 3 & Hongbo Chi1 1234567890():,; Regulatory T (Treg) cells derived from the thymus (tTreg) and periphery (pTreg) have central and distinct functions in immunosuppression, but mechanisms for the generation and acti- vation of Treg subsets in vivo are unclear. Here, we show that mechanistic target of rapamycin (mTOR) unexpectedly supports the homeostasis and functional activation of tTreg and pTreg cells. mTOR signaling is crucial for programming activated Treg-cell function to protect immune tolerance and tissue homeostasis. Treg-specific deletion of mTOR drives sponta- neous effector T-cell activation and inflammation in barrier tissues and is associated with reduction in both thymic-derived effector Treg (eTreg) and pTreg cells. Mechanistically, mTOR functions downstream of antigenic signals to drive IRF4 expression and mitochondrial metabolism, and accordingly, deletion of mitochondrial transcription factor A (Tfam) severely impairs Treg-cell suppressive function and eTreg-cell generation. Collectively, our results show that mTOR coordinates transcriptional and metabolic programs in activated Treg subsets to mediate tissue homeostasis. 1 Department of Immunology, St. Jude Children’s Research Hospital, 262 Danny Thomas Place, MS 351, Memphis, TN 38105, USA. 2 Department of Pathology, St. Jude Children’s Research Hospital, 262 Danny Thomas Place, MS 250, Memphis, TN 38105, USA. 3 Department of Pharmacology & Cancer Biology, Duke University School of Medicine, Levine Science Research Center C266, Box 3813, Durham, NC 27710, USA. -

Transcriptomic Analysis of Native Versus Cultured Human and Mouse Dorsal Root Ganglia Focused on Pharmacological Targets Short
bioRxiv preprint doi: https://doi.org/10.1101/766865; this version posted September 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Transcriptomic analysis of native versus cultured human and mouse dorsal root ganglia focused on pharmacological targets Short title: Comparative transcriptomics of acutely dissected versus cultured DRGs Andi Wangzhou1, Lisa A. McIlvried2, Candler Paige1, Paulino Barragan-Iglesias1, Carolyn A. Guzman1, Gregory Dussor1, Pradipta R. Ray1,#, Robert W. Gereau IV2, # and Theodore J. Price1, # 1The University of Texas at Dallas, School of Behavioral and Brain Sciences and Center for Advanced Pain Studies, 800 W Campbell Rd. Richardson, TX, 75080, USA 2Washington University Pain Center and Department of Anesthesiology, Washington University School of Medicine # corresponding authors [email protected], [email protected] and [email protected] Funding: NIH grants T32DA007261 (LM); NS065926 and NS102161 (TJP); NS106953 and NS042595 (RWG). The authors declare no conflicts of interest Author Contributions Conceived of the Project: PRR, RWG IV and TJP Performed Experiments: AW, LAM, CP, PB-I Supervised Experiments: GD, RWG IV, TJP Analyzed Data: AW, LAM, CP, CAG, PRR Supervised Bioinformatics Analysis: PRR Drew Figures: AW, PRR Wrote and Edited Manuscript: AW, LAM, CP, GD, PRR, RWG IV, TJP All authors approved the final version of the manuscript. 1 bioRxiv preprint doi: https://doi.org/10.1101/766865; this version posted September 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Advancing a Clinically Relevant Perspective of the Clonal Nature of Cancer
Advancing a clinically relevant perspective of the clonal nature of cancer Christian Ruiza,b, Elizabeth Lenkiewicza, Lisa Eversa, Tara Holleya, Alex Robesona, Jeffrey Kieferc, Michael J. Demeurea,d, Michael A. Hollingsworthe, Michael Shenf, Donna Prunkardf, Peter S. Rabinovitchf, Tobias Zellwegerg, Spyro Moussesc, Jeffrey M. Trenta,h, John D. Carpteni, Lukas Bubendorfb, Daniel Von Hoffa,d, and Michael T. Barretta,1 aClinical Translational Research Division, Translational Genomics Research Institute, Scottsdale, AZ 85259; bInstitute for Pathology, University Hospital Basel, University of Basel, 4031 Basel, Switzerland; cGenetic Basis of Human Disease, Translational Genomics Research Institute, Phoenix, AZ 85004; dVirginia G. Piper Cancer Center, Scottsdale Healthcare, Scottsdale, AZ 85258; eEppley Institute for Research in Cancer and Allied Diseases, Nebraska Medical Center, Omaha, NE 68198; fDepartment of Pathology, University of Washington, Seattle, WA 98105; gDivision of Urology, St. Claraspital and University of Basel, 4058 Basel, Switzerland; hVan Andel Research Institute, Grand Rapids, MI 49503; and iIntegrated Cancer Genomics Division, Translational Genomics Research Institute, Phoenix, AZ 85004 Edited* by George F. Vande Woude, Van Andel Research Institute, Grand Rapids, MI, and approved June 10, 2011 (received for review March 11, 2011) Cancers frequently arise as a result of an acquired genomic insta- on the basis of morphology alone (8). Thus, the application of bility and the subsequent clonal evolution of neoplastic cells with purification methods such as laser capture microdissection does variable patterns of genetic aberrations. Thus, the presence and not resolve the complexities of many samples. A second approach behaviors of distinct clonal populations in each patient’s tumor is to passage tumor biopsies in tissue culture or in xenografts (4, 9– may underlie multiple clinical phenotypes in cancers. -
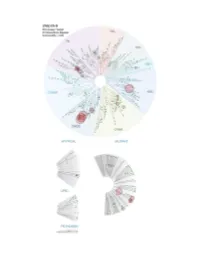
Profiling Data
Compound Name DiscoveRx Gene Symbol Entrez Gene Percent Compound Symbol Control Concentration (nM) JNK-IN-8 AAK1 AAK1 69 1000 JNK-IN-8 ABL1(E255K)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317I)-nonphosphorylated ABL1 87 1000 JNK-IN-8 ABL1(F317I)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317L)-nonphosphorylated ABL1 65 1000 JNK-IN-8 ABL1(F317L)-phosphorylated ABL1 61 1000 JNK-IN-8 ABL1(H396P)-nonphosphorylated ABL1 42 1000 JNK-IN-8 ABL1(H396P)-phosphorylated ABL1 60 1000 JNK-IN-8 ABL1(M351T)-phosphorylated ABL1 81 1000 JNK-IN-8 ABL1(Q252H)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(Q252H)-phosphorylated ABL1 56 1000 JNK-IN-8 ABL1(T315I)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(T315I)-phosphorylated ABL1 92 1000 JNK-IN-8 ABL1(Y253F)-phosphorylated ABL1 71 1000 JNK-IN-8 ABL1-nonphosphorylated ABL1 97 1000 JNK-IN-8 ABL1-phosphorylated ABL1 100 1000 JNK-IN-8 ABL2 ABL2 97 1000 JNK-IN-8 ACVR1 ACVR1 100 1000 JNK-IN-8 ACVR1B ACVR1B 88 1000 JNK-IN-8 ACVR2A ACVR2A 100 1000 JNK-IN-8 ACVR2B ACVR2B 100 1000 JNK-IN-8 ACVRL1 ACVRL1 96 1000 JNK-IN-8 ADCK3 CABC1 100 1000 JNK-IN-8 ADCK4 ADCK4 93 1000 JNK-IN-8 AKT1 AKT1 100 1000 JNK-IN-8 AKT2 AKT2 100 1000 JNK-IN-8 AKT3 AKT3 100 1000 JNK-IN-8 ALK ALK 85 1000 JNK-IN-8 AMPK-alpha1 PRKAA1 100 1000 JNK-IN-8 AMPK-alpha2 PRKAA2 84 1000 JNK-IN-8 ANKK1 ANKK1 75 1000 JNK-IN-8 ARK5 NUAK1 100 1000 JNK-IN-8 ASK1 MAP3K5 100 1000 JNK-IN-8 ASK2 MAP3K6 93 1000 JNK-IN-8 AURKA AURKA 100 1000 JNK-IN-8 AURKA AURKA 84 1000 JNK-IN-8 AURKB AURKB 83 1000 JNK-IN-8 AURKB AURKB 96 1000 JNK-IN-8 AURKC AURKC 95 1000 JNK-IN-8 -

BMPR2 Mutations in Pulmonary Arterial Hypertension with Congenital Heart Disease
Copyright #ERS Journals Ltd 2004 Eur Respir J 2004; 24: 371–374 European Respiratory Journal DOI: 10.1183/09031936.04.00018604 ISSN 0903-1936 Printed in UK – all rights reserved BMPR2 mutations in pulmonary arterial hypertension with congenital heart disease K.E. Roberts*, J.J. McElroy#, W.P.K. Wong*, E. Yen*, A. Widlitz}, R.J. Barst}, J.A. Knowles#,z,§, J.H. Morse* # } BMPR2 mutations in pulmonary arterial hypertension with congenital heart disease. Depts ofz *Medicine, Psychiatry, Pediatrics, K.E. Roberts, J.J. McElroy, W.P.K. Wong, E. Yen, A. Widlitz, R.J. Barst, J.A. Knowles, and the Columbia Genome Center, Columbia University College of Physicians and Surgeons, J.H. Morse. #ERS Journals Ltd 2004. § ABSTRACT: The aim of the present study was to determine if patients with both and the New York State Psychiatric Institute, New York, NY, USA. pulmonary arterial hypertension (PAH), due to pulmonary vascular obstructive disease, and congenital heart defects (CHD), have mutations in the gene encoding bone Correspondence: J.H. Morse, Dept of Medi- morphogenetic protein receptor (BMPR)-2. cine, Columbia University College of Physi- The BMPR2 gene was screened in two cohorts: 40 adults and 66 children with PAH/ cians and Surgeons, New York, NY, USA. CHD. CHDs were patent ductus arteriosus, atrial and ventricular septal defects, partial Fax: 1 2123054943 anomalous pulmonary venous return, transposition of the great arteries, atrioventicular E-mail: [email protected] canal, and rare lesions with systemic-to-pulmonary shunts. Six novel missense BMPR2 mutations were found in three out of four adults with Keywords: Bone morphogenetic protein receptor 2 mutations complete type C atrioventricular canals and in three children. -

1 Silencing Branched-Chain Ketoacid Dehydrogenase Or
bioRxiv preprint doi: https://doi.org/10.1101/2020.02.21.960153; this version posted February 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Silencing branched-chain ketoacid dehydrogenase or treatment with branched-chain ketoacids ex vivo inhibits muscle insulin signaling Running title: BCKAs impair insulin signaling Dipsikha Biswas1, PhD, Khoi T. Dao1, BSc, Angella Mercer1, BSc, Andrew Cowie1 , BSc, Luke Duffley1, BSc, Yassine El Hiani2, PhD, Petra C. Kienesberger1, PhD, Thomas Pulinilkunnil1†, PhD 1Department of Biochemistry and Molecular Biology, Dalhousie Medicine New Brunswick, Saint John, New Brunswick, Canada, 2Department of Physiology and Biophysics, Dalhousie University, Halifax, Nova Scotia, Canada. †Correspondence to Thomas Pulinilkunnil, PhD Department of Biochemistry and Molecular Biology, Faculty of Medicine, Dalhousie University Dalhousie Medicine New Brunswick, 100 Tucker Park Road, Saint John E2L4L5, New Brunswick, Canada. Telephone: (506) 636-6973; Fax: (506) 636-6001; email: [email protected]. 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.02.21.960153; this version posted February 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International -

1 UST College of Science Department of Biological Sciences
UST College of Science Department of Biological Sciences 1 Pharmacogenomics of Myofascial Pain Syndrome An Undergraduate Thesis Submitted to the Department of Biological Sciences College of Science University of Santo Tomas In Partial Fulfillment of the Requirements for the Degree of Bachelor of Science in Biology Jose Marie V. Lazaga Marc Llandro C. Fernandez May 2021 UST College of Science Department of Biological Sciences 2 PANEL APPROVAL SHEET This undergraduate research manuscript entitled: Pharmacogenomics of Myofascial Pain Syndrome prepared and submitted by Jose Marie V. Lazaga and Marc Llandro C. Fernandez, was checked and has complied with the revisions and suggestions requested by panel members after thorough evaluation. This final version of the manuscript is hereby approved and accepted for submission in partial fulfillment of the requirements for the degree of Bachelor of Science in Biology. Noted by: Asst. Prof. Marilyn G. Rimando, PhD Research adviser, Bio/MicroSem 602-603 Approved by: Bio/MicroSem 603 panel member Bio/MicroSem 603 panel member Date: Date: UST College of Science Department of Biological Sciences 3 DECLARATION OF ORIGINALITY We hereby affirm that this submission is our own work and that, to the best of our knowledge and belief, it contains no material previously published or written by another person nor material to which a substantial extent has been accepted for award of any other degree or diploma of a university or other institute of higher learning, except where due acknowledgement is made in the text. We also declare that the intellectual content of this undergraduate research is the product of our work, even though we may have received assistance from others on style, presentation, and language expression.