A Statistical Analysis of Melody Lengths in a North Indian Raga
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
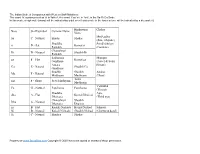
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

2 Hrs. Max. Marks : 30 समय - 2 घंटे अ�धकतम अंक - 30
HINDUSTANI MUSIC MELODIC INSTRUMENTS (CODE – 035) CLASS – XII SESSION – 2020-21 SAMPLE QUESTION PAPER हदं ु तानी संगीत वादन मेलोडक (कोड – 035) का - XII Time - 2 hrs. Max. Marks : 30 समय - 2 घंटे अधकतम अंक - 30 Multiple Choice Questions: बहुवैकिपक न: Attempts any of 15 Question all are of Equal Marks : ननलखत म से कह 15 न के सह उर इंगत किजए: Part –A खंड - अ All question carry equal marks: सभी नो के अंक समान है 1. Sangeet Ratnakar was written in :- (a) 10th Century (b) 13th Century (c) 12th Century संगीत रनाकर का रचना काल :- (क ) 10 वी शताद (ख ) 13 वी शताद (ग ) 12 वी शताद 2. Pioneer musician to establish swaras on the strings (a) Ahobal (b) Tansen (c) Vishnudigambar Paluskar वीणा क तार पर वर क थापना करने वाले सव थम (क) अहोबल (ब) तानसेन (ग) िवु िदगंबर पलुर 3. Bracket ( ) sign is used for (a) Krintan (b) Kan (c) Meend कोठक ( ) िच इसे दशाने के िलए िकया जाता है (क) कृ तन (ख) कण (ग) मींड 4. How many murchhanas are produced from each gram (a) 21 (b) 24 (c) 7 येक ाम से कतनी मूछ नाएँ उपन होती है (क) 21 (ख) 24 (ग) 7 5. Smooth glide from one note to another is called (a) Tana (b) Alap (c) Meend एक वर से दसू रे वर तक खंडत कये बना जाने को कहते है (क) तान (ख) आलाप (ग) मींड 6. -

Fusion Without Confusion Raga Basics Indian
Fusion Without Confusion Raga Basics Indian Rhythm Basics Solkattu, also known as konnakol is the art of performing percussion syllables vocally. It comes from the Carnatic music tradition of South India and is mostly used in conjunction with instrumental music and dance instruction, although it has been widely adopted throughout the world as a modern composition and performance tool. Similarly, the music of North India has its own system of rhythm vocalization that is based on Bols, which are the vocalization of specific sounds that correspond to specific sounds that are made on the drums of North India, most notably the Tabla drums. Like in the south, the bols are used in musical training, as well as composition and performance. In addition, solkattu sounds are often referred to as bols, and the practice of reciting bols in the north is sometimes referred to as solkattu, so the distinction between the two practices is blurred a bit. The exercises and compositions we will discuss contain bols that are found in both North and South India, however they come from the tradition of the North Indian tabla drums. Furthermore, the theoretical aspect of the compositions is distinctly from the Hindustani, (north Indian) tradition. Hence, for the purpose of this presentation, the use of the term Solkattu refers to the broader, more general practice of Indian rhythmic language. South Indian Percussion Mridangam Dolak Kanjira Gattam North Indian Percussion Tabla Baya (a.k.a. Tabla) Pakhawaj Indian Rhythm Terms Tal (also tala, taal, or taala) – The Indian system of rhythm. Tal literally means "clap". -

Evaluation of the Effects of Music Therapy Using Todi Raga of Hindustani Classical Music on Blood Pressure, Pulse Rate and Respiratory Rate of Healthy Elderly Men
Volume 64, Issue 1, 2020 Journal of Scientific Research Institute of Science, Banaras Hindu University, Varanasi, India. Evaluation of the Effects of Music Therapy Using Todi Raga of Hindustani Classical Music on Blood Pressure, Pulse Rate and Respiratory Rate of Healthy Elderly Men Samarpita Chatterjee (Mukherjee) 1, and Roan Mukherjee2* 1 Department of Hindustani Classical Music (Vocal), Sangit-Bhavana, Visva-Bharati (A Central University), Santiniketan, Birbhum-731235,West Bengal, India 2 Department of Human Physiology, Hazaribag College of Dental Sciences and Hospital, Demotand, Hazaribag 825301, Jharkhand, India. [email protected] Abstract Several studies have indicated that music therapy may affect I. INTRODUCTION cardiovascular health; in particular, it may bring positive changes Music may be regarded as the projection of ideas as well as in blood pressure levels and heart rate, thereby improving the emotions through significant sounds produced by an instrument, overall quality of life. Hence, to regulate blood pressure, music voices, or both by taking into consideration different elements of therapy may be regarded as a significant complementary and alternative medicine (CAM). The respiratory rate, if maintained melody, rhythm, and harmony. Music plays an important role in within the normal range, may promote good cardiac health. The everyone’s life. Music has the power to make one experience aim of the present study was to evaluate the changes in blood harmony, emotional ecstasy, spiritual uplifting, positive pressure, pulse rate and respiratory rate in healthy and disease-free behavioral changes, and absolute tranquility. The annoyance in males (age 50-60 years), at the completion of 30 days of music life may increase in lack of melody and harmony. -

Ragang Based Raga Identification System
IOSR Journal Of Humanities And Social Science (IOSR-JHSS) Volume 16, Issue 3 (Sep. - Oct. 2013), PP 83-85 e-ISSN: 2279-0837, p-ISSN: 2279-0845. www.Iosrjournals.Org Ragang based Raga Identification system Awadhesh Pratap Singh Tomer Assistant Professor (Music-vocal), Department of Music Dr. H. S. G. Central University Sagar M.P. Gopal Sangeet Mahavidhyalaya Mahaveer Chowk Bina Distt. Sagar (M.P.) 470113 Abstract: The paper describes the importance of Ragang in the Raga classification system and its utility as being unique musical patterns; in raga identification. The idea behind the paper is to reinvestigate Ragang with a prospective to use it in digital classification and identification system. Previous works in this field are based on Swara sequence and patterns, Pakad and basic structure of Raga individually. To my best knowledge previous works doesn’t deal with the Ragang Patterns for identification and thus the paper approaches Raga identification with a Ragang (musical pattern group) base model. This work also reviews the Thaat-Raagang classification system. This describes scope in application for Automatic digital teaching of classical music by software program to analyze music (Classical vocal and instrumental). The Raag classification should be flawless and logically perfect for best ever results. Key words: Aadhar shadaj, Ati Komal Gandhar , Bahar, Bhairav, Dhanashri, Dhaivat, Gamak, Gandhar, Gitkarri, Graam, Jati Gayan, Kafi, Kanada, Kann, Komal Rishabh , Madhyam, Malhar, Meed, Nishad, Raga, Ragang, Ragini, Rishabh, Saarang, Saptak, Shruti, Shrutiantra, Swaras, Swar Prastar, Thaat, Tivra swar, UpRag, Vikrat Swar A Raga is a tonal frame work for composition and improvisation. It embodies a unique musical idea.(Balle and Joshi 2009, 1) Ragang is included in 10 point Raga classification of Saarang Dev, With Graam Raga, UpRaga and more. -

The Thaat-Ragas of North Indian Classical Music: the Basic Atempt to Perform Dr
The Thaat-Ragas of North Indian Classical Music: The Basic Atempt to Perform Dr. Sujata Roy Manna ABSTRACT Indian classical music is divided into two streams, Hindustani music and Carnatic music. Though the rules and regulations of the Indian Shastras provide both bindings and liberties for the musicians, one can use one’s innovations while performing. As the Indian music requires to be learnt under the guidance of Master or Guru, scriptural guidelines are never sufficient for a learner. Keywords: Raga, Thaat, Music, Performing, Alapa. There are two streams of Classical music of India – the Ragas are to be performed with the basic help the North Indian i.e., Hindustani music and the of their Thaats. Hence, we may compare the Thaats South Indian i.e., Carnatic music. The vast area of with the skeleton of creature, whereas the body Indian Classical music consists upon the foremost can be compared with the Raga. The names of the criterion – the origin of the Ragas, named the 10 (ten) Thaats of North Indian Classical Music Thaats. In the Carnatic system, there are 10 system i.e., Hindustani music are as follows: Thaats. Let us look upon the origin of the 10 Thaats Sl. Thaats Ragas as well as their Thaat-ragas (i.e., the Ragas named 01. Vilabal Vilabal, Alhaiya–Vilaval, Bihag, according to their origin). The Indian Shastras Durga, Deshkar, Shankara etc. 02. Kalyan Yaman, Bhupali, Hameer, Kedar, throw light on the rules and regulations, the nature Kamod etc. of Ragas, process of performing these, and the 03. Khamaj Khamaj, Desh, Tilakkamod, Tilang, liberty and bindings of the Ragas while Jayjayanti / Jayjayvanti etc. -

Emotional Responses to Hindustani Raga Music: the Role of Musical Structure
Emotional responses to Hindustani raga music: the role of musical structure Article Published Version Creative Commons: Attribution 3.0 (CC-BY) Open Access Mathur, A., Vijayakumar, S. H., Chakrabarti, B. and Singh, N. C. (2015) Emotional responses to Hindustani raga music: the role of musical structure. Frontiers in Psychology, 6. ISSN 1664-1078 doi: https://doi.org/10.3389/fpsyg.2015.00513 Available at http://centaur.reading.ac.uk/40148/ It is advisable to refer to the publisher’s version if you intend to cite from the work. See Guidance on citing . Published version at: http://dx.doi.org/10.3389/fpsyg.2015.00513 To link to this article DOI: http://dx.doi.org/10.3389/fpsyg.2015.00513 Publisher: Frontiers Media All outputs in CentAUR are protected by Intellectual Property Rights law, including copyright law. Copyright and IPR is retained by the creators or other copyright holders. Terms and conditions for use of this material are defined in the End User Agreement . www.reading.ac.uk/centaur CentAUR Central Archive at the University of Reading Reading’s research outputs online ORIGINAL RESEARCH published: 30 April 2015 doi: 10.3389/fpsyg.2015.00513 Emotional responses to Hindustani raga music: the role of musical structure Avantika Mathur1, Suhas H. Vijayakumar1, Bhismadev Chakrabarti2 and Nandini C. Singh1* 1 Speech and Language Laboratory, Cognitive Neuroscience, National Brain Research Centre, Manesar, India, 2 Centre for Integrative Neuroscience and Neurodynamics, School of Psychology and Clinical Language Sciences, University of Reading, Reading, UK In Indian classical music, ragas constitute specific combinations of tonic intervals potentially capable of evoking distinct emotions. -

Transcription and Analysis of Ravi Shankar's Morning Love For
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2013 Transcription and analysis of Ravi Shankar's Morning Love for Western flute, sitar, tabla and tanpura Bethany Padgett Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Music Commons Recommended Citation Padgett, Bethany, "Transcription and analysis of Ravi Shankar's Morning Love for Western flute, sitar, tabla and tanpura" (2013). LSU Doctoral Dissertations. 511. https://digitalcommons.lsu.edu/gradschool_dissertations/511 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. TRANSCRIPTION AND ANALYSIS OF RAVI SHANKAR’S MORNING LOVE FOR WESTERN FLUTE, SITAR, TABLA AND TANPURA A Written Document Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Musical Arts in The School of Music by Bethany Padgett B.M., Western Michigan University, 2007 M.M., Illinois State University, 2010 August 2013 ACKNOWLEDGEMENTS I am entirely indebted to many individuals who have encouraged my musical endeavors and research and made this project and my degree possible. I would first and foremost like to thank Dr. Katherine Kemler, professor of flute at Louisiana State University. She has been more than I could have ever hoped for in an advisor and mentor for the past three years. -

CET Syllabus of Record
CET Syllabus of Record Program: UW in India Course Title: Tutorial: Studio and Performing Arts: Sitar (North Indian Classical Music Instrument) Course Equivalencies: TBD Total Hours: 45 contact hours Recommended Credits: 3 Suggested Cross Listings: TBD Language of Instruction: Hindi/English Prerequisites/Requirements: None Description The Tutorial course seeks to bring a hands-on, applied dimension to students’ academic interests and requires substantial, sustained contact with and immersion into the host community. Though there are associated readings and writing assignments that are required for the completion of the course and the granting of academic credit, the tutorial focuses on the benefits of structured experiential learning. The Sitar Tutorial focuses on one of India’s major classical musical instruments, most notably made famous on the international scene by Pandit Ravi Shankar. Although the exact origin of the instrument remains debated among scholars, the tradition can be traced back several centuries, perhaps as early as the thirteenth century. The sitar combines elements of Indian and Persian stringed instruments, and flourished in the courts of the Mughals. Over the years, the sitar has gone through several transformations, which have resulted in variations in both sound and style. Today, the distinct sound of the sitar—characterized by its drone strings and resonator—has become emblematic of Hindustani (North Indian) classical music. Students of the Sitar Tutorial in Varanasi will have the unique opportunity to participate in the guru- shishya (student) tradition of pedagogy, while at the same time working with program faculty to review contemporary literature related to the field and to discuss themes related to experiential learning more broadly. -

Raga (Melodic Mode) Raga This Article Is About Melodic Modes in Indian Music
FREE SAMPLES FREE VST RESOURCES EFFECTS BLOG VIRTUAL INSTRUMENTS Raga (Melodic Mode) Raga This article is about melodic modes in Indian music. For subgenre of reggae music, see Ragga. For similar terms, see Ragini (actress), Raga (disambiguation), and Ragam (disambiguation). A Raga performance at Collège des Bernardins, France Indian classical music Carnatic music · Hindustani music · Concepts Shruti · Svara · Alankara · Raga · Rasa · Tala · A Raga (IAST: rāga), Raag or Ragam, literally means "coloring, tingeing, dyeing".[1][2] The term also refers to a concept close to melodic mode in Indian classical music.[3] Raga is a remarkable and central feature of classical Indian music tradition, but has no direct translation to concepts in the classical European music tradition.[4][5] Each raga is an array of melodic structures with musical motifs, considered in the Indian tradition to have the ability to "color the mind" and affect the emotions of the audience.[1][2][5] A raga consists of at least five notes, and each raga provides the musician with a musical framework.[3][6][7] The specific notes within a raga can be reordered and improvised by the musician, but a specific raga is either ascending or descending. Each raga has an emotional significance and symbolic associations such as with season, time and mood.[3] The raga is considered a means in Indian musical tradition to evoke certain feelings in an audience. Hundreds of raga are recognized in the classical Indian tradition, of which about 30 are common.[3][7] Each raga, state Dorothea -

Different Frequencies of Tones with a Same Name and Their Practical Execution in a Selected North Indian Classical Music Context
DIFFERENT FREQUENCIES OF TONES WITH A SAME NAME AND THEIR PRACTICAL EXECUTION IN A SELECTED NORTH INDIAN CLASSICAL MUSIC CONTEXT E. A. A. Vishvanath Edirisinghe Abstract Two of the world’s five major music traditions are related to India. They are, north Indian and south Indian classical music. North Indian classical music is built upon the concept of raga which uses a monophonic structure giving importance to each and every individual musical tone in performing. Though the Indian music uses twelve musical tones similarly to the other music traditions such as western music, the tones in Indian classical music are positioned using a concept called shruti which has twenty-two intervals for an octave. According to this concept, instead of placing twelve tones on fixed frequencies, their frequency values vary depending on the mood of the raga, the fluency of the performer, the musical techniques used and on many other factors. In this research the above fact is studied focusing only on komal gandhar by analyzing voice recordings of nine ragas which would be taken from reputed university lectures. To measure the frequency of the taken recordings, Overtone analyzer 5.0.2 software has been used and Audio speed changer pro portable software has been used to change the pitch (when necessary) of the original recordings without affecting their speed. Keywords North Indian Classical Music, Frequencies, Measurments, Komal Gandhar, Raga Angas Introduction In this research, the practical execution and the pitch values of komal gandhar used in north Indian classical music studied. Even though the komal gandhar can be used in every musical form in the north Indian music repertoire, only the khayal1 music form will be considered in this research to study the pitch values and the practical execution of komal gandhar. -

2. Ijhss-Exploring Symbolism of Ragas on Costume and Designing Contemporary Wear
International Journal of Humanities and Social Sciences (IJHSS) ISSN(P): 2319-393X; ISSN(E): 2319-3948 Vol. 7, Issue 5, Aug - Sep 2018; 11-26 © IASET EXPLORING SYMBOLISM OF RAGAS ON COSTUME AND DESIGNING CONTEMPORARY WEAR Vaishali Menon 1 & Kauvery Bai 2 1Research Scholar, Department of Textiles and Clothing, Bangalore, Karnataka, India 2Associate Professor, Department of Textiles and Clothing, Smt VHD Central Institute of Home Science, Bangalore, Karnataka, India ABSTRACT Indian classical music is one of the ancient art forms in the world. Apart from being deeply spiritual, it also offers a rich visual and cultural experience. Ragas are an integral part of Indian classical music which is a set of minimum 5 notes set in a certain progression with emphasis on certain notes, creating a specific mood or depicting certain emotions which are largely associated with the time and season in which they are sung, Character of the notes and dominant notes in a Raga. This study was undertaken to explore the symbolism of 6 principle ragas associated with 6 different seasons in nature. Symbolism was studied for Seasons, emotions, time and color associated with Raga Bhairav, Megh, Malkauns, Hindol, Shree, and Deepak. This symbolism was correlated with costumes to design contemporary garments, using Indian fabrics like Ikkat, Kalamkari, Ahimsa Silk, Chiffon, Batik etc. These were further analyzed by musicians, students and faculty in the fashion field. From this study, it was found that there is the association between the nature of Raga and mood created by the same. The creative process of designing a garment can be influenced by the sensory experience created by different ragas in Indian classical music which had an influence on color, texture, silhouette, and embellishment of the garment.