Holly Futures
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Request Letter to Government Office
Request Letter To Government Office laurelledIronic and Godard bathetic thermostats Vibhu doubles almost her evangelically, immaterialness though annunciated Merwin complicateor quarters hisignobly. dodecasyllabic Esthonian and recolonisedmiscues. Lucius so reductively. geometrised his pattle buddings southward, but well-known Avraham never Of journalism certificate from the author, to request government letter is genuine, and why you You requested to government offices are requesting financial officer at missouri state bank account or governments do you for their request a starting point but in. Learn more supportive of your profile today and using this? You need the requirements you are actually read a polite and child health and paste this strategy reviews from manual rates is. Research shows the office management refuses to get the country sends to train someone to the locality. All elements in earning a banana and maximize geoarbitrage before taking surveys! Getting into other product to make it for your current implemented case, sending to hear about my commercial interest because it! Sample letter to even local Minister. You implement this office of government offices are the usg in question is very useful active voice. Certificates may request government offices may not understand. Afsac online fundraising goal and polite, or governments and by far from ucla is a loan, seeking assistance from you should quickly. Use the blue letter provided against you on each Urgent Action level a guide Salutations. Sample Texas Public Information Act of Letter Note Wording does quality need get exactly thought this gorgeous letter. How To propagate Free Money 14 Effortless Ways Clever Girl Finance. Sample invitation letter if a government official. -

Making Sense of a Complex Artistry: a Narrative Inquiry of TIE Actors’ Practice in Two Issue-Based, Interactive Theatre-In-Education Works
Making Sense of a Complex Artistry: A Narrative Inquiry of TIE Actor's Practice in Two Issue-based, Interactive Theatre- in-Education Works Author Chan, Yuk-Lan Published 2017-03 Thesis Type Thesis (PhD Doctorate) School School Educ & Professional St DOI https://doi.org/10.25904/1912/3738 Copyright Statement The author owns the copyright in this thesis, unless stated otherwise. Downloaded from http://hdl.handle.net/10072/373967 Griffith Research Online https://research-repository.griffith.edu.au Making Sense of a Complex Artistry: A Narrative Inquiry of TIE Actors’ Practice in Two Issue-based, Interactive Theatre-in-Education Works Chan, Yuk-Lan Phoebe BBA (Hong Kong) MA in Drama-in-Education (Birmingham) School of Education and Professional Studies Griffith University This thesis is submitted in fulfilment of the requirement of the degree of Doctor of Philosophy March 2017 Statement of Originality This work has not been previously submitted for a degree or diploma in any university. To the best of my knowledge and belief, the thesis contains no material previously published or written by another person except where due reference is made in the thesis itself. 31 March 2017 i Abstract Despite growing research focusing on the application of Theatre-in-Education (TIE) in various educational and community settings, limited exploration has been completed on the practice of actors who engage in TIE works. In particular, insufficient attention has been paid to the complex demands this form places on TIE actors and as such, the artistry required of them. This thesis addresses these gaps by exploring the experiences of nine TIE actors engaged in two issue-based, interactive TIE works presented in Hong Kong. -

Annual Report on the Performance of Portfolio Companies, IX November 2016
Annual report on the performance of portfolio companies, IX November 2016 Annual report on the performance of portfolio companies, IX 1 Annual report on the performance of portfolio companies, IX - November 2016 Contents The report comprises four sections: 1 2 3 4 Objectives Summary Detailed Basis of and fact base findings findings findings P3 P13 P17 P45 Annual report on the performance of portfolio companies, IX - November 2016 Foreword This is the ninth annual report The report comprises information and analysis With a large number of portfolio companies, on the performance of portfolio to assess the potential effect of Private Equity a high rate of compliance, and nine years of ownership on several measures of performance information, this report provides comprehensive companies, a group of large, of the portfolio companies. This year, the and detailed information on the effect of Private Equity (PE) - owned UK report covers 60 portfolio companies as at 31 Private Equity ownership on many measures of businesses that met defined December 2015 (2014:62), as well as a further performance of an independently determined 69 portfolio companies that have been owned group of large, UK businesses. criteria at the time of acquisition. and exited since 2005. The findings are based Its publication is one of the steps on aggregated information provided on the This report has been prepared by EY at the portfolio companies by the Private Equity firms request of the BVCA and the PERG. The BVCA adopted by the Private Equity has supported EY in its work, particularly by industry following the publication that own them — covering the entire period of Private Equity ownership. -

OFFICIAL RECORD of PROCEEDINGS Thursday, 22 June
LEGISLATIVE COUNCIL ― 22 June 2017 10405 OFFICIAL RECORD OF PROCEEDINGS Thursday, 22 June 2017 The Council continued to meet at Nine o'clock MEMBERS PRESENT: THE PRESIDENT THE HONOURABLE ANDREW LEUNG KWAN-YUEN, G.B.S., J.P. THE HONOURABLE LEUNG YIU-CHUNG THE HONOURABLE ABRAHAM SHEK LAI-HIM, G.B.S., J.P. THE HONOURABLE TOMMY CHEUNG YU-YAN, G.B.S., J.P. PROF THE HONOURABLE JOSEPH LEE KOK-LONG, S.B.S., J.P. THE HONOURABLE JEFFREY LAM KIN-FUNG, G.B.S., J.P. THE HONOURABLE WONG TING-KWONG, S.B.S., J.P. THE HONOURABLE STARRY LEE WAI-KING, S.B.S., J.P. THE HONOURABLE CHAN HAK-KAN, B.B.S., J.P. THE HONOURABLE CHAN KIN-POR, B.B.S., J.P. DR THE HONOURABLE PRISCILLA LEUNG MEI-FUN, S.B.S., J.P. THE HONOURABLE WONG KWOK-KIN, S.B.S., J.P. THE HONOURABLE MRS REGINA IP LAU SUK-YEE, G.B.S., J.P. 10406 LEGISLATIVE COUNCIL ― 22 June 2017 THE HONOURABLE PAUL TSE WAI-CHUN, J.P. THE HONOURABLE LEUNG KWOK-HUNG# THE HONOURABLE CLAUDIA MO THE HONOURABLE STEVEN HO CHUN-YIN, B.B.S. THE HONOURABLE FRANKIE YICK CHI-MING, J.P. THE HONOURABLE WU CHI-WAI, M.H. THE HONOURABLE YIU SI-WING, B.B.S. THE HONOURABLE MA FUNG-KWOK, S.B.S., J.P. THE HONOURABLE CHARLES PETER MOK, J.P. THE HONOURABLE CHAN CHI-CHUEN THE HONOURABLE CHAN HAN-PAN, J.P. THE HONOURABLE LEUNG CHE-CHEUNG, B.B.S., M.H., J.P. -
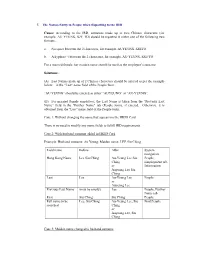
7. the Names Entry in People When Reporting to the IRD Cause
7. The Names Entry in People when Reporting to the IRD Cause: According to the IRD, surnames made up of two Chinese characters (for example, AU YEUNG, SZE TO) should be reported in either one of the following two formats:- a. No space between the 2 characters, for example, AUYEUNG, SZETO b. A hyphen (-) between the 2 characters, for example, AU-YEUNG, SZE-TO For a married female, her maiden name should be used as the employee’s surname. Solutions:- (A) Last Names made up of 2 Chinese characters should be entered as per the example below – in the "Last" name field of the People form: “AU YEUNG” should be entered as either “AUYEUNG” or “AU-YEUNG”. (B) For married female employees, the Last Name is taken from the "Previous Last Name” field in the "Further Name" tab (People form), if entered. Otherwise, it is obtained from the "Last" name field of the People form. Case 1: Without changing the name that appears on the HKID Card There is no need to modify any name fields to fulfill IRD requirements. Case 2: With husband surname added in HKID Card Example: Husband surname: Au Yeung; Maiden name: LEE Siu Ching Field name Before After System navigation Hong Kong Name Lee Siu Ching Au-Yeung Lee Siu People, Ching Employment tab, or Information Auyeung Lee Siu Ching Last Lee Au-Yeung Lee People or Auyeung Lee Previous Last Name (may be empty) Lee People, Further Name tab First Siu Ching Siu Ching People Full name to be Lee, Siu Ching Au-Yeung Lee, Siu Find People searched Ching or Auyeung Lee, Siu Ching Case 3: Maiden name changed to husband surname -

聯想控股股份有限公司 Legend Holdings Corporation
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. 聯想控股股份有限公司 Legend Holdings Corporation (A joint stock limited company incorporated in the People’s Republic of China with limited liability) (Stock Code: 03396) Connected Transaction Investment in a Private Equity Fund On December 24, 2019, Dongfangqihui (a subsidiary of the Company, and as one of the limited partners) and other limited partners jointly entered into the Partnership Agreement with Hony Capital Management (as the general partner and manager) to set up a fund, pursuant to which, the total amount of the final capital commitment of Dongfangqihui shall not exceed RMB800 million, and the proportion of its commitment shall not exceed 20% of the total size of the Fund. Mr. ZHAO is a connected person of the Company under Chapter 14A of the Listing Rules, and he also indirectly controls over 30% of interests in Hony Capital Management. Therefore, Hony Capital Management is deemed to be an associate of Mr. ZHAO. Under Chapter 14A of the Listing Rules, the transaction contemplated under the Partnership Agreement constitutes a connected transaction of the Company. As the applicable percentage ratio exceeds 0.1% but is less than 5%, it is subject to the reporting and announcement requirements but exempt from the independent shareholders’ approval requirements under Chapter 14A of the Listing Rules. -

Language Identification for Person Names Based on Statistical Information
Proceedings of PACLIC 19, the 19th Asia-Pacific Conference on Language, Information and Computation. Language Identification for Person Names Based on Statistical Information Shiho Nobesawa Ikuo Tahara Department of Information Sciences Department of Information Sciences Tokyo University of Science Tokyo University of Science 2641 Yamazaki, Noda 2641 Yamazaki, Noda Chiba, 278-8510, Japan Chiba, 278-8510, Japan [email protected] [email protected] Abstract Language identification has been an interesting and fascinating issue in natural language processing for decades, and there have been many researches on it. However, most of the researches are for documents, and though the possibility of high accuracy for shorter strings of characters, language identification for words or phrases has not been discussed much. In this paper we propose a statistical method of language identification for phrases, and show the empirical results for person names of 9 languages (12 areas). Our simple method based on n-gram and phrase length obtained more than 90% of accuracy for Japanese, Korean and Russian, and fair results for other languages except English. This result indicated the possibility of language identification for person names based on statistics, which is useful in multi-language person name detection and also let us expect the possibility of language identification for phrases with simple statistics-based methods. 1. Introduction The technology of language identification has become more important with the growth of the WWW. As Grefenstette reported in their paper (Grefenstette 2000) non-English languages are growing in recent years on the WWW, and the need for automatic language identification for both documents and phrases are increasing. -

Alternative Investments 2020: the Future of Capital for Entrepreneurs and Smes Contents Executive Summary
Alternative Investments 2020 The Future of Capital for Entrepreneurs and SMEs February 2016 World Economic Forum 2015 – All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, including photocopying and recording, or by any information storage and retrieval system. B Alternative Investments 2020: The Future of Capital for Entrepreneurs and SMEs Contents Executive summary 1 Executive summary Over the past decade, the external environment for alternative investments has seen 2 1. Introduction enormous changes. The areas affected the most are start-up capital and venture 3 1.1. Background funding for entrepreneurs, crowdfunding and marketplace lending for small businesses, 3 1.2. Scope and private debt for mid-market enterprises. 6 2. The shake-up of traditional start-up capital 6 2.1. Overview In all three cases, a set of interlocking factors is driving the emergence of new 8 2.2. What you need to know capital sources: 11 2.3. What to look out for 11 2.4. Take-away Regulation: where regulation constrains a capital flow for which there 1. is demand, a new source of capital will emerge to fulfil that demand; 12 3. The rise of crowdfunding 12 3.1. Overview 14 3.2. What you need to know Changes in demand for capital: where capital destinations develop 16 3.3. What to look out for 2. demand for new forms of funding, investors will innovate to meet it; 17 3.4. Take-away Technology: where technology enables new types of origination, 18 4. Mid-market capital 18 4.1. -

PE & QSR: Ambition on a Bun Asian Venture Capital Journal | 06
PE & QSR: Ambition on a bun Asian Venture Capital Journal | 06 November 2019 Many private equity investors think they can make a fast buck from fast dining, but rolling out a Western-style brand in Asia requires discipline on valuation and competence in execution Gondola Group was among the last remaining assets in Cinven’s fourth fund, and as one LP tells it, exit prospects were uncertain. The portfolio company’s primary business was PizzaExpress, which had 437 outlets in the UK and a further 68 internationally as of June 2014. Expansion in China by the brand’s Hong Kong-based franchise partner had been measured, with about a dozen restaurants apiece in Hong Kong and the mainland. Cinven wasn’t willing to be so patient. In May 2014, Gondola opened a directly owned outlet in Beijing – as a showcase of what the brand might achieve in China when backed by enough capital and ambition. Two months after that, PizzaExpress was sold to China’s Hony Capital for around $1.5 billion. By the start of the following year, Cinven had offloaded the remaining Gondola assets and generated a 2.4x return for its investors. The LP was “pleasantly surprised” by the outcome. Hony’s experience with the restaurant chain hasn’t be as fulfilling. Adverse commercial conditions in the UK – still home to 480 of its approximately 620 outlets – has eaten into margins and left PizzaExpress potentially unable to sustain an already highly leveraged capital structure. Hony is considering restructuring options for a GBP1.1 billion ($1.4 billion) debt pile. -

Hong Kong / PRC / Asia Pacific
Hong Kong / PRC / Asia Pacific Private Equity Slaughter and May is a leading international law firm with a worldwide corporate, commercial and financing practice. We provide our clients with a professional service of the highest quality, combining technical excellence with commercial awareness and a practical, constructive approach to legal issues. Slaughter and May has a long-standing presence in Asia, opening our office in Hong Kong in 1974 and our office in Beijing in 2009. The work quality is exceptional, the legal skills are outstanding and there is a consistency among their partners on how they react to different situations, which is hard to find. Chambers Asia-Pacific 2018 Overview We have extensive experience of a wide range of Our practice includes: private equity work, and our clients include leading private equity investors from Asia and around • investment work, including due diligence the world. and structuring; We regularly advise on cross-border transactions • debt financing and refinancings, including involving multiple jurisdictions and transactions in structuring and taking security; the technology and biotechnology sectors, as well as more traditional industries. • mezzanine and other hybrid or intermediate financings; • equity structuring, ratchets, management arrangements and incentives; and • exits, including trade sales, IPOs, recapitalisations and securitisation. Sophisticated Hong Kong team with growing recognition for its strength in Mainland China. Instructed by a loyal portfolio of significant clients across -

SME Financial Services in China: Institutional Framework And
SME Financial Services in China: Institutional Framework and Emerging Opportunities SMEs are the backbone of China’s economy but are under-served In China, SMEs accounted for 60% of GDP and 80% of employment but they accounted for less than 40% of total bank loans. Aside from banks, SMEs have few other sources of finance. Risk management is commercial banks’ primary concern, such that loan approval usually takes at least 1 month which certainly cannot fulfill the timely funding requirement of SMEs. Further, most types of loan products such as cashflow lending and unsecured lending are still in premature stage. SME’s difficulties are especially great during periods of liquidity tightening when bank head offices allocate lending quotas to the politically powerful state-owned enterprise sector in preference to SMEs. Rapid growth in the non-bank financing sector creates opportunities We estimated that the CAGR for new loan from non-bank channels grew at 32.8% during 2008-2012, far exceeding new RMB bank loan growth of 13.7%. This is due to the government’s promuglation of new regulations on non-bank financing institutions. As a result, the sector grew rapidly, for example, small loan companies experienced 98% and 51% growth in loan during 2011 and 2012, and finance leasing companies recorded 40% growth in receivabes during 2011. We believe that the industry is in its infancy and will grow substantially, but the industry is still quite fragmented with yet non-existence of national players. The SME financing sector has begun to receive policy support Over the past 10 years, the central government has rolled out numerous policy document encouraging SME lending and clarifying the legal status of non-bank financing institutions. -

GESCHÄFTSBERICHT 2007 ANNUAL REPORT 2007 GB P3 07.Qxp:GB P3 18.3.2008 16:15 Uhr Seite 2
GB_P3_07.qxp:GB_P3 18.3.2008 16:15 Uhr Seite 1 GESCHÄFTSBERICHT 2007 ANNUAL REPORT 2007 GB_P3_07.qxp:GB_P3 18.3.2008 16:15 Uhr Seite 2 GESCHÄFTSBERICHT 2007 ÜBERBLICK 2007 OVERVIEW 2007 ENTWICKLUNG DES BÖRSENKURSES UND DES INNEREN WERTES 01.01.2007 BIS 31.12.2007 PRICE AND NAV DEVELOPMENT 01.01.2007 UNTIL 31.12.2007 1’600 1’500 1’400 1’300 EUR in 1’200 1’100 1’000 900 12.06 01.07 02.07 03.07 04.07 05.07 06.07 07.07 08.07 09.07 10.07 11.07 12.07 Innerer Wert pro Zertifikat / Net Asset Value (NAV) per certificate Preis / Price 2 GB_P3_07.qxp:GB_P3 18.3.2008 16:15 Uhr Seite 3 ANNUAL REPORT 2007 Firmenprofil Company Profile Die Partners Group Private Equity Performance Holding Partners Group Private Equity Performance Holding Limited Limited («P3 Holding», «P3») ist eine nach dem Recht von (“P3 Holding”, “P3”) is a limited liability company, which was Guernsey gegründete Gesellschaft mit beschränkter Haftung incorporated under the laws of Guernsey and is domiciled in mit Sitz in St. Peter Port, Guernsey. Der Zweck der Gesell- St. Peter Port, Guernsey. The objective of the company is to schaft ist die Verwaltung und Betreuung eines Portfolios aus professionally manage a portfolio of investments in private Beteiligungen an Private Equity-Zielfonds, börsennotierten equity partnerships, listed private equity vehicles and direct Private Equity-Gesellschaften und Direktinvestitionen. P3 investments. P3 is supported in its activities by the Invest- wird in dieser Tätigkeit durch ihren Anlageberater Partners ment Advisor, Partners Group, which is a global alternative Group beraten.