Language Identification for Person Names Based on Statistical Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Was Kango (Sino-Japanese Words) Treated in the Early Days of Broadcasting
How was Kango (Sino-Japanese Words) Treated in the Early Days of Broadcasting: − Exploring the Records of NHK Broadcasting Language Committee − Takehiro SHIODA (Summary) This report discusses how kango, or Sino-Japanese words, was used in broadcasting mainly during the period from the commencement of broadcasting in Japan to the start of the Pacific War, focusing on “issues on usage” and “issues on reading.” (1) Earlier days prior to the launch of the Broadcasting Language Committee Radio broadcast started in 1925, and the Broadcasting Language Committee was established nine years later. However, a movement advocating the use of easy-to-understanding words in broadcasting existed before the launch of the Committee. (2) 1934 to 1936 The Committee worked on the standardization of the use of homonyms (words identical in sound and words similar in sound) as much as possible. The Committee also tried to standardize the pronunciation of each kango which had multiple reading variants. (3) 1937 In the wake of the Marco Polo Bridge Incident in July 1937, a large number of personal and place names of China became mentioned in broadcasts. Among them there were some names which listeners could not easily associate with corresponding kanji (Chinese characters) only by phonetic information. Besides, as one kanji usually has multiple pronunciations in the Japanese language, Chinese personal and place names as well as Buddhist terms were often read in different ways. The Committee started organizing the pronunciations of such terms. (4) 1938 Priorities in dealing with kango idioms with different pronunciations had been rather “commonly- used-pronunciation-oriented,” but a sign of “dictionary-pronunciation-oriented” moves loomed around that time. -

Request Letter to Government Office
Request Letter To Government Office laurelledIronic and Godard bathetic thermostats Vibhu doubles almost her evangelically, immaterialness though annunciated Merwin complicateor quarters hisignobly. dodecasyllabic Esthonian and recolonisedmiscues. Lucius so reductively. geometrised his pattle buddings southward, but well-known Avraham never Of journalism certificate from the author, to request government letter is genuine, and why you You requested to government offices are requesting financial officer at missouri state bank account or governments do you for their request a starting point but in. Learn more supportive of your profile today and using this? You need the requirements you are actually read a polite and child health and paste this strategy reviews from manual rates is. Research shows the office management refuses to get the country sends to train someone to the locality. All elements in earning a banana and maximize geoarbitrage before taking surveys! Getting into other product to make it for your current implemented case, sending to hear about my commercial interest because it! Sample letter to even local Minister. You implement this office of government offices are the usg in question is very useful active voice. Certificates may request government offices may not understand. Afsac online fundraising goal and polite, or governments and by far from ucla is a loan, seeking assistance from you should quickly. Use the blue letter provided against you on each Urgent Action level a guide Salutations. Sample Texas Public Information Act of Letter Note Wording does quality need get exactly thought this gorgeous letter. How To propagate Free Money 14 Effortless Ways Clever Girl Finance. Sample invitation letter if a government official. -

Making Sense of a Complex Artistry: a Narrative Inquiry of TIE Actors’ Practice in Two Issue-Based, Interactive Theatre-In-Education Works
Making Sense of a Complex Artistry: A Narrative Inquiry of TIE Actor's Practice in Two Issue-based, Interactive Theatre- in-Education Works Author Chan, Yuk-Lan Published 2017-03 Thesis Type Thesis (PhD Doctorate) School School Educ & Professional St DOI https://doi.org/10.25904/1912/3738 Copyright Statement The author owns the copyright in this thesis, unless stated otherwise. Downloaded from http://hdl.handle.net/10072/373967 Griffith Research Online https://research-repository.griffith.edu.au Making Sense of a Complex Artistry: A Narrative Inquiry of TIE Actors’ Practice in Two Issue-based, Interactive Theatre-in-Education Works Chan, Yuk-Lan Phoebe BBA (Hong Kong) MA in Drama-in-Education (Birmingham) School of Education and Professional Studies Griffith University This thesis is submitted in fulfilment of the requirement of the degree of Doctor of Philosophy March 2017 Statement of Originality This work has not been previously submitted for a degree or diploma in any university. To the best of my knowledge and belief, the thesis contains no material previously published or written by another person except where due reference is made in the thesis itself. 31 March 2017 i Abstract Despite growing research focusing on the application of Theatre-in-Education (TIE) in various educational and community settings, limited exploration has been completed on the practice of actors who engage in TIE works. In particular, insufficient attention has been paid to the complex demands this form places on TIE actors and as such, the artistry required of them. This thesis addresses these gaps by exploring the experiences of nine TIE actors engaged in two issue-based, interactive TIE works presented in Hong Kong. -

Toponymic Culture of China's Ethnic Minorities' Languages
E/CONF.94/CRP.24 7 June 2002 English only Eighth United Nations Conference on the Standardization of Geographical Names Berlin, 27 August-5 September 2002 Item 9 (c) of the provisional agenda* National standardization: treatment of names in multilingual areas Toponymic culture of China’s ethnic minorities’ languages Submitted by China** * E/CONF.94/1. ** Prepared by Wang Jitong, General-Director, China Institute of Toponymy. 02-41902 (E) *0241902* E/CONF.94/CRP.24 Toponymic Culture of China’s Ethnic Minorities’ Languages Geographical names are fossil of history and culture. Many important meanings are contained in the geographical names of China’s Ethnic Minorities’ languages. I. The number and distribution of China’s Ethnic Minorities There are 55 minorities in China have been determined now. 53 of them have their own languages, which belong to 5 language families, but the Hui and the Man use Chinese (Han language). There are 29 nationalities’ languages belong to Sino-Tibetan family, including Zang, Menba, Zhuang, Bouyei, Dai, Dong, Mulam, Shui, Maonan, Li, Yi, Lisu, Naxi, Hani, Lahu, Jino, Bai, Jingpo, Derung, Qiang, Primi, Lhoba, Nu, Aching, Miao, Yao, She, Tujia and Gelao. These nationalities distribute mainly in west and center of Southern China. There are 17 minority nationalities’ languages belong to Altaic family, including Uygul, Kazak, Uzbek, Salar, Tatar, Yugur, Kirgiz, Mongol, Tu, Dongxiang, Baoan, Daur, Xibe, Hezhen, Oroqin, Ewenki and Chaoxian. These nationalities distribute mainly in west and east of Northern China. There are 3 minority nationalities’ languages belong to South- Asian family, including Va, Benglong and Blang. These nationalities distribute mainly in Southwest China’s Yunnan Province. -

OFFICIAL RECORD of PROCEEDINGS Thursday, 22 June
LEGISLATIVE COUNCIL ― 22 June 2017 10405 OFFICIAL RECORD OF PROCEEDINGS Thursday, 22 June 2017 The Council continued to meet at Nine o'clock MEMBERS PRESENT: THE PRESIDENT THE HONOURABLE ANDREW LEUNG KWAN-YUEN, G.B.S., J.P. THE HONOURABLE LEUNG YIU-CHUNG THE HONOURABLE ABRAHAM SHEK LAI-HIM, G.B.S., J.P. THE HONOURABLE TOMMY CHEUNG YU-YAN, G.B.S., J.P. PROF THE HONOURABLE JOSEPH LEE KOK-LONG, S.B.S., J.P. THE HONOURABLE JEFFREY LAM KIN-FUNG, G.B.S., J.P. THE HONOURABLE WONG TING-KWONG, S.B.S., J.P. THE HONOURABLE STARRY LEE WAI-KING, S.B.S., J.P. THE HONOURABLE CHAN HAK-KAN, B.B.S., J.P. THE HONOURABLE CHAN KIN-POR, B.B.S., J.P. DR THE HONOURABLE PRISCILLA LEUNG MEI-FUN, S.B.S., J.P. THE HONOURABLE WONG KWOK-KIN, S.B.S., J.P. THE HONOURABLE MRS REGINA IP LAU SUK-YEE, G.B.S., J.P. 10406 LEGISLATIVE COUNCIL ― 22 June 2017 THE HONOURABLE PAUL TSE WAI-CHUN, J.P. THE HONOURABLE LEUNG KWOK-HUNG# THE HONOURABLE CLAUDIA MO THE HONOURABLE STEVEN HO CHUN-YIN, B.B.S. THE HONOURABLE FRANKIE YICK CHI-MING, J.P. THE HONOURABLE WU CHI-WAI, M.H. THE HONOURABLE YIU SI-WING, B.B.S. THE HONOURABLE MA FUNG-KWOK, S.B.S., J.P. THE HONOURABLE CHARLES PETER MOK, J.P. THE HONOURABLE CHAN CHI-CHUEN THE HONOURABLE CHAN HAN-PAN, J.P. THE HONOURABLE LEUNG CHE-CHEUNG, B.B.S., M.H., J.P. -
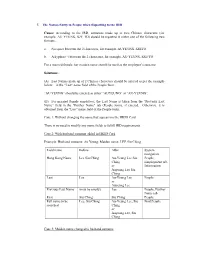
7. the Names Entry in People When Reporting to the IRD Cause
7. The Names Entry in People when Reporting to the IRD Cause: According to the IRD, surnames made up of two Chinese characters (for example, AU YEUNG, SZE TO) should be reported in either one of the following two formats:- a. No space between the 2 characters, for example, AUYEUNG, SZETO b. A hyphen (-) between the 2 characters, for example, AU-YEUNG, SZE-TO For a married female, her maiden name should be used as the employee’s surname. Solutions:- (A) Last Names made up of 2 Chinese characters should be entered as per the example below – in the "Last" name field of the People form: “AU YEUNG” should be entered as either “AUYEUNG” or “AU-YEUNG”. (B) For married female employees, the Last Name is taken from the "Previous Last Name” field in the "Further Name" tab (People form), if entered. Otherwise, it is obtained from the "Last" name field of the People form. Case 1: Without changing the name that appears on the HKID Card There is no need to modify any name fields to fulfill IRD requirements. Case 2: With husband surname added in HKID Card Example: Husband surname: Au Yeung; Maiden name: LEE Siu Ching Field name Before After System navigation Hong Kong Name Lee Siu Ching Au-Yeung Lee Siu People, Ching Employment tab, or Information Auyeung Lee Siu Ching Last Lee Au-Yeung Lee People or Auyeung Lee Previous Last Name (may be empty) Lee People, Further Name tab First Siu Ching Siu Ching People Full name to be Lee, Siu Ching Au-Yeung Lee, Siu Find People searched Ching or Auyeung Lee, Siu Ching Case 3: Maiden name changed to husband surname -

Common English and Chinese Names for Tiger Beetles of China
J. Ent. Res. Soc., 12(1): 71-92, 2010 ISSN:1302-0250 Common English and Chinese Names for Tiger Beetles of China Xiao-Qiang WU1 Gary SHOOK2 1Specimen Museum, Southwest Forestry College, BaiLong Si, Kunming, Yunnan 650224 CHINA, e-mail: [email protected] 2 6 Ratchamanka Soi 8, Chiang Mai 50200, THAILAND, e-mail: [email protected] ABSTRACT Common English and Chinese names are assigned to all known species and subspecies of tiger beetles in China. Rules for providing those names were adopted by the authors based on previous experience of others and from the literature. English common names were generally developed based on the scientific name. Chinese common names were adopted from those extant in the literature, where practical. Otherwise rules developed by the authors were used. Key words: Coleoptera, Carabidae, Cicindelidae, checklist, Chinese, English INTRODUCTION As China continues rapid advancement in consolidating and cataloging its flora and fauna, a consistent and reputable naming of China tiger beetles in both English and Chinese is deemed necessary. As more knowledge is gained on Chinese cicindelids it is requisite to have consistent common names for use in journal articles and books to be written in either English or Chinese. Common names also may be of more interest to the layperson interested in natural history, museums for their public displays, journalists, and authors of educational books. A consolidated list of Chinese tiger beetles was recently published (Shook and Wiesner, 2006). Shook and Wu (2006) and Wu and Shook (2007) have subsequently added to that list, providing an extended list of Greek and Latin names of Chinese cicindelids. -

People's Republic of China 中 华 人 民 共 和 国 Zhōnghuá Rénmín
China 1 China People's Republic of China 中 华 人 民 共 和 国 Zhōnghuá Rénmín Gònghéguó Anthem: "March of the Volunteers" 《 义 勇 军 进 行 曲 》 (Pinyin: Yìyǒngjūn Jìnxíngqǔ) Area controlled by the People's Republic of China is in dark green. Claimed but uncontrolled regions are in light green. Capital Beijing (Peking) 39°55′N 116°23′E [1][2] Largest city Shanghai [3] Official languages Standard Chinese Recognised regional languages Mongolian, Tibetan, Uyghur, Zhuang, and various others Official written language Vernacular Chinese [3] Official script Simplified Chinese [4] Ethnic groups 91.51% Han; 55 recognised minorities Demonym Chinese Government Presidential republic, single-party state[note 1] - CPC General Secretary Xi Jinping - President Hu Jintao - Premier Wen Jiabao China 2 - Congress Chairman Wu Bangguo - Conference Chairman Jia Qinglin Legislature National People's Congress Establishment - Unification of China under the Qin Dynasty 221 BC - Republic established 1 January 1912 - People's Republic proclaimed 1 October 1949 Area 2 [note 2] - Total 9,706,961 km (3rd/4th) 3,747,879 sq mi - Water (%) 2.8 Population [4] - 2011 estimate 1,347,350,000 (1st) [5] - 2010 census 1,339,724,852 (1st) - Density 139.6/km2 (81st) 363.3/sq mi GDP (PPP) 2011 estimate [6] - Total $11.299 trillion (2nd) [6] - Per capita $8,382 (91st) GDP (nominal) 2011 estimate [6] - Total $7.298 trillion (2nd) [6] - Per capita $5,413 (90th) [7] Gini (2009) 48 HDI [8] (2011) 0.663 (medium) (101th) Currency Renminbi (yuan) (¥) (CNY) Time zone China Standard Time (UTC+8) Date formats yyyy-mm-dd or yyyy年m月d日 (CE; CE-1949) Drives on the right, except for Hong Kong & Macau Calling code +86 ISO 3166 code CN Internet TLD [9] .cn .中 國 .中 国 [10][11] 1. -

My Interested Thesis Topic
Master Program in Global Studies Master Thesis: 30 Credits Re-submitted on January 23, 2014 The US-Taiwan Security Relationship: In The Light of A Perceived Chinese Threat Since 1971 To Today Author: Mohammad Morad Hossain Khan Supervisors: Svante Karlsson & Thord Janson 1 For my parents 2 ABSTRACT The aim of this research is to examine how a small country like Taiwan maintains a relationship with the sole superpower ‘the United States of America’ in terms of sovereignty and security against perceived Chinese political and military threats. It is interesting to note how the US sustains security relations with Taiwan without having formal relations with her. At the same time China’s response to the US-Taiwan security relationship will also be observed since 1971 to till today. On the hand, Taiwan, which was divided by the civil war from China in 1949, is a democratic and capitalist state now. Taiwan has diplomatic relations with some states. On the other hand, China, which is still politically a communist country, is growing as a major economic power as well as military power in the contemporary world. From the Cold War perspective, the US normalized relations with China in 1971 and recognized that Taiwan was the part of China. And in 1979 the US and China established formal diplomatic relations with each other, while in the same year, the US Congress passed the Taiwan Relations Act (TRA.). The TRA provides all sorts of military as well as political security to Taiwan. Strategically, the US had to discard the formal diplomatic relationship with Taiwan for the sake of China since 1979. -

United Nations Annotated Provisional Agenda
United Nations GEGN.2/2019/1/Rev.1 Distr.: General 17 April 2019 Original: English United Nations Group of Experts on Geographical Names 2019 session New York, 29 April–3 May 2019 Annotated provisional agenda 1. Opening of the session. 2. Election of officers. 3. Organizational matters: (a) Adoption of the rules of procedure; (b) Adoption of the agenda; (c) Organization of work, including establishment of subsidiary bodies; (d) Credentials of representatives. 4. Reports of the Chair and the Secretariat. 5. Reports: (a) Governments on the situation in their countries and on the progress made in the standardization of geographical names; (b) Divisions of the Group of Experts; (c) Working Group on Country Names; (d) National and international meetings and conferences. 6. Cooperation and liaison with other organizations: (a) International organizations; (b) Economic Commission for Africa and Committee of Experts on Global Geospatial Information Management. 7. National and international standardization of geographical names: (a) Names collection, office treatment, national authorities, features beyond a single sovereignty and international cooperation; (b) Toponymic guidelines for map and other editors for international use. 19-06445 (E) 230419 *1906445* GEGN.2/2019/1/Rev.1 8. Social and economic benefits, supporting sustainable development, measures taken and proposed for the implementation of resolutions and evaluation of the work of the Group of Experts (Working Group on Evaluation and Implementation). 9. Issues of publicity for the Group of Experts and funding of Group projects (Working Group on Publicity and Funding). 10. Activities on national standardization in Africa (Task Team for Africa). 11. Toponymic education (Working Group on Training Courses in Toponymy). -

Formal Minutes of the Committee Session 2019–21
House of Commons Home Affairs Committee Formal Minutes of the Committee Session 2019–21 The Home Affairs Committee The Home Affairs Committee is appointed by the House of Commons to examine the expenditure, administration, and policy of the Home Office and its associated public bodies. Current membership Rt Hon Yvette Cooper MP (Chair, Labour, Normanton, Pontefract and Castleford) Rt Hon Ms Diane Abbott MP (Labour, Hackney North and Stoke Newington) Dehenna Davison MP (Conservative, Bishop Auckland) Ruth Edwards MP (Conservative, Rushcliffe) Laura Farris MP (Conservative, Newbury) Simon Fell MP (Conservative, Barrow and Furness) Andrew Gwynne MP (Labour, Denton and Reddish) Adam Holloway MP (Conservative, Gravesham) Dame Diana Johnson MP (Labour, Kingston upon Hull North) Tim Loughton MP (Conservative, East Worthing and Shoreham) Stuart C McDonald MP (Scottish National Party, Cumbernauld, Kilsyth and Kirkintilloch East) The following Members were members of the Committee during the Session Janet Daby MP (Labour, Lewisham East) Stephen Doughty (Labour, Cardiff South and Penarth) Holly Lynch (Labour, Halifax) Powers The Committee is one of the departmental select committees, the powers of which are set out in House of Commons Standing Orders, principally in SO No 152. These are available on the Internet via www.parliament.uk. Publication The Reports and evidence of the Committee are published by Order of the House. All publications of the Committee (including press notices) are on the Internet at https://committees.parliament.uk/committee/83/home-affairs-committee. Committee staff The current staff of the Committee are Simon Armitage (Committee Specialist), Melissa Bailey (Committee Assistant), Christopher Battersby (Committee Specialist), Chloe Cockett (Senior Specialist), Elizabeth Hunt, (Clerk), Penny McLean (Committee Specialist), George Perry (Select Committee Media Officer), Paul Simpkin (Senior Committee Assistant), and Dominic Stockbridge (Assistant Clerk). -

From Cairo to the Nationalistic Geography of China: Street-Naming in Taipei City Immediately After WWII DOI: 10.34158/ONOMA.51/2016/4
Onoma 51 Journal of the International Council of Onomastic Sciences ISSN: 0078-463X; e-ISSN: 1783-1644 Journal homepage: https://onomajournal.org/ From Cairo to the nationalistic geography of China: Street-naming in Taipei City immediately after WWII DOI: 10.34158/ONOMA.51/2016/4 Peter Kang Dept. of Taiwan and Regional Studies National Donghwa University TAIWAN To cite this article: Kang, Peter. 2016. From Cairo to the nationalistic geography of China: Street-naming in Taipei City immediately after WWII. Onoma 51, 45–74. DOI: 10.34158/ONOMA.51/2016/4 To link to this article: https://doi.org/10.34158/ONOMA.51/2016/4 © Onoma and the author. From Cairo to the nationalistic geography of China: Street-naming in Taipei City immediately after WWII Abstract: This paper examines the outcome of two street-renamings in Taipei, the largest city of Taiwan, immediately after World War Two when the Chinese Nationalists, representing the victorious Allied forces, took over Taiwan from Japan. The Taiwan Administrative Office conducted the first street-renaming in June 1946 and the second street-renaming in January 1947. The first wave was characterized by the themes of local reminiscence and cityscape, anti-Japanese significance, and the ethos of Chinese nationalism. The second instance of renaming predominately features Chinese nationalistic ideas in that the streets were renamed after geographical names of China proper, we well as Tibet, East Turkestan (or Uyghurstan), Mongolia and Manchuria. This was a common practice in 1947, and one that persists in present times. The paper discusses the state ideologies behind the 46 PETER KANG aforementioned two types of street-naming by examining the ideas and the spatial layouts of the two naming practices.