Content Selection in Multi-Document Summarization
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Michael Phelps
1 Fact Sheet Table of Contents Open Water Schedule Team History pp. 1-3 Tuesday July 21 Wednesday July 22 Saturday July 25 contains fact sheet, schedule, 5KM 9 a.m. (W) 10KM 9 a.m. (W) 25KM 9 a.m. (M) Team USA notes, warm-down info 11 a.m. (M) 2 p.m. (M) 9:10 a.m. (W) and selection procedures\ TV Schedule p. 4 Roster p. 5 Athlete Bios pp. 6-56 Coach Bios p. 57 Times History pp. 58-110 Record Progressions, All-Time Top Pool Schedule Performances and Performers 2007 Worlds Results pp. 111-114 PRELIMS FINALS PRELIMS FINALS Records pp. 115- 116 Sunday, July 26 Monday, July 27 World, American, U.S. Open and 100m Fly (W) 100m Fly (W)- Semi 100m Back (W) 100m Breast (M) World Champs records 400m Free (M) 400m Free (M) 200m Free (M) 100m Fly (W) USAS Info pp. 117-118 200m IM (W) 200m IM (W)- Semi 100m Breast (W) 100m Back (M)- Semi 50m Fly (M) 50m Fly (M)- Semi 100m Back (M) 100m Breast (W)- Semi 400m Free (W) 400m Free (W) 1500m Free (W) 50m Fly (M) 100m Breast (M) 100m Breast (M)- Semi 100m Back (W)- Semi Quick Facts 400m Free Relay (W) 400m Free Relay (W) 200m Free (M)- Semi 400m Free Relay (M) 400m Free Relay (M) 200m IM (W) WHAT: 13th FINA World Championships WHEN: Tuesday, July 28 Wednesday, July 29 July 17 - August 2, 2009 50m Breast (M) 200m Free (M) 50m Back (W) 100m Free (M)- Semi Open Water Dates: July 19-25 200m Fly (M) 100m Back (W) 100m Free (M) 50m Back (W)- Semi Pool Dates: July 26 - Aug. -

High School Stars Shine Saving the 1996 Olympics Drug Cheaters Exposed
HIGH SCHOOL SWIMMERS OF THE YEAR HIGH SCHOOL STARS SHINE SAVING THE 1996 OLYMPICS DRUG CHEATERS EXPOSED AUGUST 2014 - VOLUME 55 - NO. 8 $3.95 HOW TO ACHIEVE SUCCESS EVERY DAY SPECIAL SW SUBSCRIPTION OFFER: (SEE PAGE 46 FOR DETAILS) NATALIE COUGHLIN 3-time Olympian 12-time Olympic medalist LZR RACER ELITE 2 LIMITED EDITION COLORS This isn’t the place for second best or good enough. This is proven race technology that pushes you to reach the wall first. Our innovative fabrics, targeted muscle compression and true comfort fits give competitive swimmers the performance they demand. New limited edition colors in black/red and black/purple. Speedo and are registered trademarks of and used under license from Speedo International Limited. www.speedousa.com 4C Process:: C0, M96, Y100, K0 4C Process:: C45, M25, Y16, K59 14_AD_SWIMWRLD_JULY_LZR_R4.indd 1 7/3/14 1:16 PM finish strong. ARIANNA VANDERPOOL WALLACE ⋅ 2008, 2012 OLYMPIAN NEW VAPOR TECHNICAL SUIT Constructed from premium Italian fabric, the Vapor utilizes hydro-reflective technology to repel water and increase optimal race efficiency. available in mint, red, and black racing ingenuity. FINISinc.com Hot off the blocks adidas performance now available in the pool ALL YOUR GEAR WHERE YOU NEED IT. NI KESWIM.COM 022|Life in the Fast LAne 040| Q&A with Coach Sue Chen by Shoshanna Rutemiller by Michael J. Stott Caeleb Dressel is the quickest high schooler AUGUST ever in the 50 yard free as well as the public 041| How They Train MORGAN HILL school record holder in the 100 fly—reasons 2014 that Swimming World Magazine named him by Michael J. -
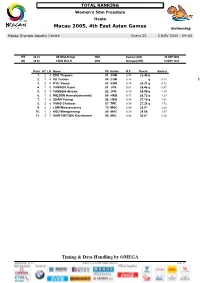
Macau 2005, 4Th East Asian Games Timing & Data-Handling by OMEGA
TOTAL RANKING Women’s 50m Freestyle Heats Macau 2005, 4th East Asian Games Swimming Macao Olympic Aquatic Centre Event 25 5 NOV 2005 - 09:00 WR 24.13 DE BRUIJN IngeNED Sydney (AUS) 22 SEP 2000 GR 25.25 YANG Wen YiCHN Shangai (CHN) 15 MAY 1993 RankHT LN Name YB NationR.T. Result Behind 1. 24ZHU Yingwen81 CHN 0.77 25.49 q 2. 14XU Yanwei84 CHN 0.75 q 0.33 25.82 3. 25RYU Yoonji85 KOR 0.78 26.31 q 0.82 4. 15YAMADA Kaori81 JPN 0.81 26.46 q 0.97 5. 23YAMADA Atsumi82 JPN 0.79 26.59 q 1.10 6. 13WILSON Hannahjanearnett89 HKG 0.77 26.72 q 1.23 7. 16CHAN Yuning88 HKG 0.88 27.10 q 1.61 8. 26YANG Chinkuei87 TPE 0.79 27.21 q 1.72 9. 22LAM Waimansarina79 MAC 0.84 28.07 2.58 10. 12KOU Wengcheong89 MAC 0.79 29.06 3.57 11. 27SAINTSETSEG Dashtseren90 MGL 0.84 30.67 5.18 Timing & Data-Handling by OMEGA SWW010900_74 1.0 Report Created SAT 5 NOV 2005 9:00 Page 1/1 FINAL RESULTS Women’s 50m Freestyle Finals Macau 2005, 4th East Asian Games Swimming Macao Olympic Aquatic Centre Event 125 5 NOV 2005 - 19:00 WR 24.13 DE BRUIJN IngeNED Sydney (AUS) 22 SEP 2000 GR 25.25 YANG Wen YiCHN Shangai (CHN) 15 MAY 1993 RankLN Name YB NationR.T. Result Behind FINAL 1.4 ZHU Yingwen 81 CHN 0.74 24.87 GR 2.5 XU Yanwei 84CHN 0.74 25.25 0.38 3.3 RYU Yoonji 85 KOR 0.75 26.12 1.25 4.6 YAMADA Kaori 81 JPN 0.76 26.13 1.26 5.7 WILSON Hannahjanearnett 89 HKG 0.76 26.60 1.73 6.8 YANG Chinkuei 87 TPE 0.80 26.65 1.78 7.2 YAMADA Atsumi 82 JPN 0.79 26.69 1.82 8.1 CHAN Yuning 88 HKG 0.86 27.23 2.36 Timing & Data-Handling by OMEGA SWW010100_73 1.0 Report Created SAT 5 NOV 2005 19:01 Page 1/1 TOTAL RANKING Women’s 100m Freestyle Heats Macau 2005, 4th East Asian Games Swimming Macao Olympic Aquatic Centre Event 3 2 NOV 2005 - 09:09 WR 53.52 HENRY JodieAUS Athens (GRE) 18 AUG 2004 GR 55.02 XU YanweiCHN Osaka (JPN) 21 MAY 2001 RankHT LN Name YB NationR.T. -

2003 World Championships Results
10th FINA World Championships BARCELONA 2003 Event 31 Men’s 50m Freestyle Heats 25 JUL 2003 50m Nage Libre Hommes Séries TOTAL RANKING CLASSEMENT TOTAL WR 21.64 POPOV AlexanderRUS Moscow (RUS) 16 JUN 2000 CR 22.05 ERVIN AnthonyUSA Fukuoka (JPN) 22 JUL 2001 RankHT LN Name YB NationR.T. Result Points 1. 22 4 POPOV Alexander71 RUS 0.85 21.98 qCR 992 2. 22 5 LEZAK Jason75 USA 0.74 22.29 q 972 3. 21 4 KENKHUIS Johan80 NED 0.68 22.32 q 970 4. 20 1 SICOT Julien78 FRA 0.78 22.36 q 967 5. 22 2 VAN DEN HOOGENBAND Pieter78 NED 0.78 22.51 q 958 6. 18 5 MANKOC Peter78 SLO 0.77 22.54 q 956 6. 21 3 HAWKE Brett75 AUS 0.77 22.54 q 956 8. 20 2 NEETHLING Ryk77 RSA 0.70 22.56 q 954 9. 20 3 VOLYNETS Olersandr74 UKR 0.83 22.57 q 954 10. 21 2 FOSTER Mark70 GBR 0.76 22.59 q 952 11. 20 7 LORENTE Eduard77 ESP 0.75 22.60 q 952 12. 18 4 NOVY Karel80 SUI 0.83 22.63 q 950 12. 20 8 SCARICA Michele82 ITA 0.78 22.63 q 950 12. 22 6 SHYRSHOV Vyacheslav79 UKR 0.79 22.63 q 950 15. 22 8 BOUSQUET Frederick81 FRA 0.72 22.64 q 949 16. 17 5 PIMANKOV Denis75 RUS 0.80 22.69 q 946 17. 20 6 SCHOEMAN Roland80 RSA 0.68 22.74 943 17. 21 6 ILES Salim75 ALG 0.69 22.74 943 17. -

Fswc History Titles.Xlsx
27 years of FINA Swimming World Cup 1989 - 2015 THE COMPLETE SWIMMING WORLD CUP GOLDEN BOOK Title Sponsor 2015: SITES of the FINA SWIMMING WORLD CUP SERIES all pools short course unless otherwise stated (LC = long course) page 1 / 2 1989 1990 1991 1992 1993 1994 1995 SWC.1 Toronto (CAN) Montreal (CAN) Milano (ITA) Montreal (CAN) Shanghai (CHN) Hong Kong (HKG) Hong Kong (HKG) 15-17 Dec 1988 29 Nov - 1 Dec 1989 13-14 Mar1991 29 Nov - 1 Dec 1991 5-6 Jan 1993 1-2 Jan 1994 1-2 Jan 1995 SWC.2 Indianapolis (USA) Orlando (USA) Bonn (GER) St-Petersburg (URS) Beijing (CHN) Beijing (CHN) Espoo (FIN) LC • 18-20 Dec 1988 LC • 3-5 Dec 1989 16-17 Mar 1991 13-14 Jan 1992 9-10 Jan 1993 5-6 Jan 1994 31 Jan - 1 Feb 1995 SWC.3 Paris (FRA) Paris FRA) Malmö (SWE) Leicester (GBR) Paris (FRA) Desenzano (ITA) Paris (FRA) 3-5 Feb 1989 2-4 Feb 1990 19-20 Mar 1991 16-18 Jan 1992 6-7 Feb 1993 12-13 Mar 1994 4-5 Feb 1995 SWC.4 Berlin (GDR) Berlin (GDR) Rostock (GER) Malmö (SWE) Malmö (SWE) Malmö (SWE) St Vincent (ITA) LC • 7-8 Feb 1989 LC • 5-7 Feb 1990 22-23 Mar 1991 21-22 Jan 1992 9-10 Feb 1993 15-16 Mar 1994 7-8 Feb 1995 SWC.5 Bonn (FRG) Bonn (FRG) Leningrad (URS) Bonn (GER) Gelsenkirchen (GER) Gelsenkirchen (GER) Sheffield (GBR) 10-12 Feb 1989 9-11 Feb 1990 26-27 Mar 1991 25-26 Jan 1992 13-14 Feb 1993 19-20 Mar 1994 11-12 Feb 1995 SWC.6 Gothenburg (SWE) Gothenburg (SWE) Sheffield (GBR) Milano (ITA) Sheffield (GBR) Sheffield (GBR) Malmö (SWE) LC • 14-15 Feb 1989 LC • 13-14 Feb 1990 29-30 Mar 1991 28-29 Jan 1992 16-17 Feb 1993 22-23 Mar 1994 14-15 Feb 1995 SWC.7 -

2000 Olympic Games Results
50m LIBRE HOMMES SERIES Event 25 50m FREE MEN Day 6 HEATS LISTE DE DEPART Printed18-09-00 at 09:04 Page 500 START LIST WR 21.64 POPOV Alexander RUS 16-06-00 MOSCOW OR 21.91 POPOV Alexander RUS 30-07-92 BARCELONA CouloirNom Prénom Nat AN LaneName Firstname Nat YB Entry time HEAT 1/ 10 1 SAEED Wael GQAT 84 35.00 2 SEREME BakaryMLI 81 33.10 3 WALLACE S.VIN 82 29.58 4 SAMUEL AnlloydPLW 80 27.23 5 GURUNG C.NEP 70 27.28 6 MUBAH HassanMDV 84 29.59 7 ABDEL HAMID MohamedSUD 80 35.00 8 NDAYISHIMIYE SamsonRWA 80 35.00 HEAT 2/ 10 1 MARONIE KennethDMA 80 26.96 2 OUNKHAMPHANYAVONG S.LAO 82 26.00 3 MATUSSE IlidioMOZ 75 25.51 4 BISSLIK DavyARU 82 25.15 5 AHMED MuhammadIRQ 76 25.50 6 PETERKIN JamieLCA 82 25.91 7 AL KULAIBI KhalidOMA 86 26.26 8 HEM KiryCAM 80 27.15 HEAT 3/ 10 1 ALMAS AyoubUAE 78 24.11 2 MARGARYAN DmitriARM 78 24.00 3 HUGHES OmarGRN 82 24.00 4 BLANCO EstebanCRC 81 23.87 5 HINDS HowardAHO 77 23.88 6 AGUIAR JoaoANG 83 24.00 7 GULIYEV EmilAZE 75 24.00 8 BERIDZE ZurabGEO 79 24.13 HEAT 4/ 10 1 BORISSENKO SergeyKAZ 71 23.84 2 HUANG Chih−YungTPE 78 23.75 3 KUTSCHER P.URU 77 23.72 4 ASHIHMIN SergeyKGZ 77 23.55 5 FU Wing HarbethHKG 80 23.71 6 KWOK LeslieSIN 73 23.72 7 LOPEZ HARTINGER LuisPER 75 23.76 8 STOLEARENCO SergheiMDA 78 23.86 50m LIBRE HOMMES SERIES Event 25 50m FREE MEN Day 6 HEATS LISTE DE DEPART Printed18-09-00 at 09:04 Page 501 START LIST WR 21.64 POPOV Alexander RUS 16-06-00 MOSCOW OR 21.91 POPOV Alexander RUS 30-07-92 BARCELONA CouloirNom Prénom Nat AN LaneName Firstname Nat YB Entry time HEAT 5/ 10 1 NACHAEV RavilUZB 74 23.51 2 BECERRA -

Finacoverx:Layout 1.Qxd
FINAcoverx:Layout 1 2011.05.10. 17:46 Page 1 CROP: 28-28-243-32 100% 24-24-177-159 71% Official FINA Magazine Sponsor ISSN 1664-0365 ISSN 1664-0365 2011/3 2011/3 AQUATICS WORLD AQUATICS A UATICS world magazine World Championships July 16-31, 2011 Photo: REUTERS Shanghai ready to shine www.fina.org FINAcover:Layout 1 2011.05.16. 18:41 Page 2 Cesar Cielo 16 Federica Pellegrini 48 Damir Buric 101 CONTENT 2011/3. “I think I’m handling my life and “The Chinese will win many med - “I think this event and the Olym - my problems in a better way.“ als but Michael Phelps will still be pics in 2012 will be the most diffi- the Championships’ best swim- cult water polo tournaments in Ian Thorpe 19 mer.” the history of the sport.“ “...after a few months I’m confi- dent that I can be better and faster Zhao Jing 54 than I used to be able to swim.“ “Since I lack systematic training due to health problem, I need to Sun Yang 22 make up rapidly.“ “Age is my advantage. Since the SYNCHRO Shanghai Worlds is not my last Kirsty Coventry 55 Worlds, I don’t really care about “I love swimming. I needed the Hold your breath, the show- the title things.“ break from it but I am happy to be down’s on 82 back.“ Usually, it’s Russia all the way. Can it Liam Tancock 24 be different this time? Answers from “...we’re doing a lot of cross train - Rebecca Soni 59 Sarah Chiarello. -

ROME 1994 Results at the Swimming World Championships
NIC - Il Nuoto in Cifre ROME 1994 results at the Swimming World Championships FREESTYLE 50 M MEN 100 M MEN 200 M MEN POPOV ALEXANDER RUS 1° 22,17 POPOV ALEXANDER RUS 1° 49,12 KASVIO ANTTI FIN 1° 1,47,32 HALL GARY JR USA 2° 22,44 HALL GARY JR USA 2° 49,41 HOLMERTZ ANDERS SWE 2° 1,48,24 MAŽUOLIS RAIMUNDAS LTU 3° 22,52 BORGES GUSTAVO BRA 3° 49,52 LOADER DANYON NZL 3° 1,48,49 BORGES GUSTAVO BRA 4° 22,64 OLSEN JON USA 4° 49,90 ŠEGOLEV ROMAN RUS 4° 1,48,79 KALFAYAN CRISTOPHE FRA 5° 22,65 TRÖGER CHRISTIAN GER 5° 50,03 BRAY TRENT NZL 5° 1,49,13 FOSTER MARK GBR 6° 22,76 WERNER TOMMY SWE 6° 50,06 CZENE ATTILA HUN 6° 1,49,21 CWALINA KRZYSZTOF POL 7° 22,89 MAŽUOLIS RAIMUNDAS LTU 7° 50,20 ZESNER STEFFEN GER 7° 1,49,28 BRUCK YOAV ISR 8° 22,94 CLARKE STEPHEN CAN 8° 50,27 CARVIN CHAD USA 8° 1,49,86 400 M MEN 1500 M MEN PERKINS KIEREN AUS 1° 3,43,80 PERKINS KIEREN AUS 1° 14,50,52 KASVIO ANTTI FIN 2° 3,48,55 KOWALSKI DANIEL AUS 2° 14,53,42 LOADER DANYON NZL 3° 3,48,62 ZESNER STEFFEN GER 3° 15,09,20 KOWALSKI DANIEL AUS 4° 3,50,03 HOFFMANN JÖRG GER 4° 15,13,95 SICILIANO PIER MARIA ITA 5° 3,50,94 BRUNER CARLTON USA 5° 15,15,64 HOFFMANN JÖRG GER 6° 3,51,28 HIRANO MASATO JPN 6° 15,16,59 ZESNER STEFFEN GER 7° 3,52,24 WILSON IAN GBR 7° 15,20,58 DOLAN TOM USA 8° 3,54,26 SMITH GRAEME GBR 8° 15,29,24 BACKSTROKE 100 M MEN 200 M MEN LÓPEZ-ZUBERO MARTÍN ESP 1° 55,17 SELKOV VLADIMIR RUS 1° 1,57,42 ROUSE JEFF USA 2° 55,51 LÓPEZ-ZUBERO MARTÍN ESP 2° 1,58,75 DEUTSCH TAMÁS HUN 3° 55,69 SHARP ROYCE USA 3° 1,58,86 SELKOV VLADIMIR RUS 4° 55,72 DEUTSCH TAMÁS HUN 4° 1,59,31 -
Palma De Maillorca-1993.Xlsx
NIC - Il Nuoto in Cifre PALMA DE MAILLORCA 1993 World Swimming Short Course Championships FREESTYLE 50 M MEN 100 M MEN 200 M MEN FOSTER MARK GBR 1° 21,84 SCHERER FERNANDO BRA 1° 48,38 KASVIO ANTTI FIN 1° 1,45,21 HU BIN CHN 2° 21,93 BORGES GUSTAVO BRA 2° 48,42 BRAY TRENT NZL 2° 1,45,53 ABERNETHY ROBERT AUS 3° 21,97 OLSEN JON USA 3° 48,49 WOJDAT ARTUR POL 3° 1,45,63 FOX DAVID USA 4° 22,03 TRÖGER CHRISTIAN GER 4° 48,76 HOLMERTZ ANDERS SWE 3° 1,45,63 OLSEN JON USA 5° 22,11 WERNER TOMMY SWE 5° 48,79 BORGES GUSTAVO BRA 5° 1,46,71 CWALINA KRZYSZTOF POL 6° 22,17 HOLMERTZ ANDERS SWE 6° 48,82 SICILIANO PIER MARIA ITA 6° 1,47,06 SEI INDREK EST 7° 22,32 PEPPER SETH USA 7° 49,14 OLSEN JON USA 7° 1,47,40 SCHERER FERNANDO BRA 8° 22,43 ABERNETHY ROBERT AUS 8° 49,41 TRÖGER CHRISTIAN GER 8° 1,47,70 400 M MEN 1500 M MEN KOWALSKI DANIEL AUS 1° 3,42,95 KOWALSKI DANIEL AUS 1° 14,42,04 KASVIO ANTTI FIN 2° 3,42,98 HOFFMANN JÖRG GER 2° 14,53,09 PALMER PAUL GBR 3° 3,45,07 ALBIŃSKI PIOTR POL 3° 14,53,97 BRAY TRENT NZL 4° 3,45,09 SMITH GRAEME GBR 4° 14,54,46 WOJDAT ARTUR POL 5° 3,45,36 MAJCEN IGOR SLO 5° 14,56,70 SICILIANO PIER MARIA ITA 6° 3,45,92 FUJIMOTO MASAYUKI JPN 6° 15,02,37 HOFFMANN JÖRG GER 7° 3,47,29 ANDREEV VIKTOR RUS 7° 15,12,13 ALLEN MALCOLM AUS 8° 3,48,06 SICILIANO PIER MARIA ITA 8° 15,14,33 BACKSTROKE 100 M MEN 200 M MEN SCHWENK TRIPP USA 1° 52,98 SCHWENK TRIPP USA 1° 1,54,19 HARRIS MARTIN GBR 2° 53,93 BIANCHIN LUCA ITA 2° 1,55,09 FALCON RODOLFO CUB 3° 54,00 MAENE STEFAAN BEL 3° 1,55,68 FORD CRAIG AUS 4° 54,02 ROMERO ROGERIO BRA 4° 1,55,90 WEBER TINO -
1994 World Championships Results
for the Record 8141 85 Nikki Dryd€n, CAN Eugenia Emakova, KAZ 2:04,45 S Rìchardson, CAN RIJS 54 15 Lu Bin, CHN 59 ô8 25!ø N Meshsryakova, Johnc*e, SWE 8:43.16 Phil¡ppa Langrell, NZL 59 Eileen coparropa, PAN 2:04.70 Louise Dyken, USA 54.n F. Van Almsick, GEF 83 2549 AmY Van Elwani, EGY 8r44,89 Carla Geurls, NED 59 Joscelin Yeo, SIN 2105,39 Rania Postma, NED 55,16 JennyThmpson,USA 89 0rcn0 2567 Angêla Caterina Borgato, ITA 8:45.38 llziar EspaEa, ESP TRI 2:05 53 55,57 l\¡etle Jacobsen, DEN 1:00 39 Siobhan CroPPer, 25.77 Lu Bin, CHN liladine, IRL 8ì49 15 Malin Nilssm, SWE 1:00 46 Teresa Moodie, Zll\¡ 2105 88 Mailm Angel Malìno, USA 5577 Angel Mart¡no, USA 25,85 2:06 Olga Kirichenko, RUS 8:52 36 loana Nagh¡, ROM Suzu Chiba, JPN 1:00 77 Shu.Nl¡n Tsa¡, TPE 27 25.85 Sumika Minamolo, JPN 55 79 815252 Hana cerna, CzÉ '1r01.16 Rom¡naCannmi,CHl 2ì0632 SandraCam,EEL GER 55 79 Karen Pickering, GBR 25 94 F Van Almsick, 8152 M Kirslen Vlìeghuis, NED Naìalia Scapinello, AFG 2107 il Fu-Jen Kuo, TPE ESP Consolation Finals 1r01,59 2ûM Claudia Fran@, DEN 8:53 23 SandraCam, BEL 1:01 Jovanka Dimovska, MKD 2:07 99 Beril Puggaard, CAN 55 64 N, l\¡esheryakova, RIJS 57 2620 S Shakespeare, Alegr¡a, POR 8i53 86 S Richardson, CAN 1r01 Duska Hadan, IPS 2:08 55 Ana Volker, GEB 56 52 Sumìka Minamolo, JPN 83 2626 Sandra 2:08.58 Chanlal Strasser, SUI 8:56 47 Ztìou Guanbin, CHN Claudia Franco, ESP 1:02 00 Maritza Chiaway, Per Sarah BYan, AUS 56 78 BritWomdal, NoR 2640 NAM 2108.91 Alicia Barancos, AFG 8:57,89 56 Luminila Dobrescu, RoM 1:02 60 Anila Kruger, 26 44 Judilh Draxler, -

The 16Th FINA World Championships (Kazan) Media Guide
16th FINA World Championships KAZAN MEdia Guide diving synchro swimming 16th FINA World Masters Championships KAZAN contents introduction Diving Synchro Swimming Media Contacts Diving Team Synchro Team Swimming Team Media Protocol Diving Schedule Synchro Schedule Marathon Swimming Team Athletes and Events: Swimming Diver Profiles: Men Synchro Profiles Swimming Schedule Athletes and Events: Open Water Diver Profiles: Women Synchro Former Medallists Marathon Swimming Schedule Athletes and Events: Diving Diving Former Medallists Swimmer Profiles: Men Athletes and Events: Synchro Swimmer Profiles: Women Marathon Swimming Profiles: Men Marathon Swimming Profiles: Women Swimmer PBs Swimming Selection Policy Marathon Swimming Selection Policy Swimming Former Medallists Marathon Swimming Former Medallists Rankings Records MEdia Guide diving synchro swimming 16th FINA World Championships KAZAN media contacts Contact for Swimming Dave Richards – Head of Communications M: +447789 926 136 E: [email protected] Contact for Diving Gemma Field – Communications Manager M: +447917 726 431 E: [email protected] USEFUL WEBSITES British Swimming: www.swimming.org/britishswimming/ Official Event Website: http://kazan2015.com/en LEN: http://www.fina.org MEdia Guide diving synchro swimming 16th FINA World Championships KAZAN media PROTOCOL The media protocol has been designed to help ACCESS TO BRITISH COACHES The swim down pool is off limits to all media as indicated by achieve an understanding between all media and accreditation. No member of the British Swimming squad will be DURING COMPETITION available at swim down. those representing British Swimming. It aims After the final event of the day a coach or coaches with relevance to The Press Officer will try to obtain quotes from athletes if, for to create opportunities for the media as well as that evening’s finals will be available to the media at a location within whatever reason, access has been limited further. -

Campionati Mondiali Vasca Lunga Dal 1973 Al 2019 World Long Course Swimming Championships from 1973 to 2019
NIC - Il Nuoto in Cifre Campionati Mondiali Vasca Lunga dal 1973 al 2019 World Long Course Swimming Championships from 1973 to 2019 50 M FREESTYLE WOMEN 5th MADRID (ESP) 17-23 AUG 1986 6th PERTH (AUS) 07-13 JAN 1991 COSTACHE TAMARA ROU 1° 25,28 ZHUANG YONG CHN 1° 25,47 OTTO KRISTIN GDR 2° 25,50 PLEWINSKI CATHERINE FRA 2° 25,50 ARMENTERO MARIE-THÉRÈSE SUI 3° 25,93 FETTER LEIGH ANN USA 2° 25,50 JOHNSON JENNA USA 4° 26,07 YANG WENYI CHN 4° 25,87 VERSTAPPEN ANNEMARIE NED 5° 26,08 THOMPSON JENNIFER USA 4° 25,87 VAN BENTUM CONNY NED 6° 26,14 OSYGUS SIMONE GER 6° 25,95 DORMAN LISA USA 7° 26,15 ERMAKOVA EVGENIJA URS 7° 26,00 KAMOUN SOPHIE FRA 8° 26,60 HUNGER DANIELA GER 8° 26,01 7th ROME (ITA) 05-11 SEP 1994 8th PERTH (AUS) 12-18 JAN 1998 LE JINGYI CHN 1° 24,51 VAN DYKEN AMY USA 1° 25,15 MEŠČERJAKOVA NATALYA RUS 2° 25,10 VÖLKER SANDRA GER 2° 25,32 VAN DYKEN AMY USA 3° 25,18 SHAN YING CHN 3° 25,36 VAN ALMSICK FRANZISKA GER 4° 25,40 THOMPSON JENNIFER USA 4° 25,59 MARTINO ANGEL USA 5° 25,46 POSTMA ANGELA NED 5° 25,67 LU BIN CHN 6° 25,52 ALSHAMMAR THERESE SWE 6° 25,83 POSTMA ANGELA NED 7° 25,55 OSYGUS SIMONE GER 7° 25,90 MINAMOTO SUMIKA JPN 8° 25,85 MORAVCOVÁ MARTINA SVK 8° 26,04 9th FUKUOKA (JPN) 22-29 JUL 2001 10th BARCELONA (ESP) 20-27 JUL 2003 DE BRUIJN INGE NED 1° 24,47 DE BRUIJN INGE NED 1° 24,47 ALSHAMMAR THERESE SWE 2° 24,88 MILLS ALICE AUS 2° 25,07 VÖLKER SANDRA GER 3° 24,96 TRICKETT LISBETH AUS 3° 25,08 SHEPPARD ALISON GBR 4° 25,00 THOMPSON JENNIFER USA 4° 25,10 STONE TAMMIE USA 5° 25,10 VÖLKER SANDRA GER 5° 25,14 COPE HALEY USA 6° 25,25