Weighted Gene Co-Expression Network Analysis Identifies Modules And
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Disruption of the Neuronal PAS3 Gene in a Family Affected with Schizophrenia D Kamnasaran, W J Muir, M a Ferguson-Smith,Dwcox
325 ORIGINAL ARTICLE J Med Genet: first published as 10.1136/jmg.40.5.325 on 1 May 2003. Downloaded from Disruption of the neuronal PAS3 gene in a family affected with schizophrenia D Kamnasaran, W J Muir, M A Ferguson-Smith,DWCox ............................................................................................................................. J Med Genet 2003;40:325–332 Schizophrenia and its subtypes are part of a complex brain disorder with multiple postulated aetiolo- gies. There is evidence that this common disease is genetically heterogeneous, with many loci involved. See end of article for In this report, we describe a mother and daughter affected with schizophrenia, who are carriers of a authors’ affiliations t(9;14)(q34;q13) chromosome. By mapping on flow sorted aberrant chromosomes isolated from lym- ....................... phoblast cell lines, both subjects were found to have a translocation breakpoint junction between the Correspondence to: markers D14S730 and D14S70, a 683 kb interval on chromosome 14q13. This interval was found to Dr D W Cox, 8-39 Medical contain the neuronal PAS3 gene (NPAS3), by annotating the genomic sequence for ESTs and perform- Sciences Building, ing RACE and cDNA library screenings. The NPAS3 gene was characterised with respect to the University of Alberta, genomic structure, human expression profile, and protein cellular localisation to gain insight into gene Edmonton, Alberta T6G function. The translocation breakpoint junction lies within the third intron of NPAS3, resulting in the dis- 2H7, Canada; [email protected] ruption of the coding potential. The fact that the bHLH and PAS domains are disrupted from the remain- ing parts of the encoded protein suggests that the DNA binding and dimerisation functions of this Revised version received protein are destroyed. -

AP2A2 Antibody Cat
AP2A2 Antibody Cat. No.: 63-513 AP2A2 Antibody Formalin-fixed and paraffin-embedded human Flow cytometric analysis of HepG2 cells using AP2A2 hepatocarcinoma with AP2A2 Antibody , which was Antibody (bottom histogram) compared to a negative peroxidase-conjugated to the secondary antibody, control cell (top histogram). FITC-conjugated goat-anti- followed by DAB staining. rabbit secondary antibodies were used for the analysis. Specifications HOST SPECIES: Rabbit SPECIES REACTIVITY: Human This AP2A2 antibody is generated from rabbits immunized with a KLH conjugated IMMUNOGEN: synthetic peptide between 610-637 amino acids from the Central region of human AP2A2. TESTED APPLICATIONS: Flow, IHC-P, WB For WB starting dilution is: 1:1000 APPLICATIONS: For IHC-P starting dilution is: 1:10~50 For FACS starting dilution is: 1:10~50 September 25, 2021 1 https://www.prosci-inc.com/ap2a2-antibody-63-513.html PREDICTED MOLECULAR 104 kDa WEIGHT: Properties This antibody is purified through a protein A column, followed by peptide affinity PURIFICATION: purification. CLONALITY: Polyclonal ISOTYPE: Rabbit Ig CONJUGATE: Unconjugated PHYSICAL STATE: Liquid BUFFER: Supplied in PBS with 0.09% (W/V) sodium azide. CONCENTRATION: batch dependent Store at 4˚C for three months and -20˚C, stable for up to one year. As with all antibodies STORAGE CONDITIONS: care should be taken to avoid repeated freeze thaw cycles. Antibodies should not be exposed to prolonged high temperatures. Additional Info OFFICIAL SYMBOL: AP2A2 AP-2 complex subunit alpha-2, 100 kDa coated vesicle -

Transcription Factor P73 Regulates Th1 Differentiation
ARTICLE https://doi.org/10.1038/s41467-020-15172-5 OPEN Transcription factor p73 regulates Th1 differentiation Min Ren1, Majid Kazemian 1,4, Ming Zheng2, JianPing He3, Peng Li1, Jangsuk Oh1, Wei Liao1, Jessica Li1, ✉ Jonathan Rajaseelan1, Brian L. Kelsall 3, Gary Peltz 2 & Warren J. Leonard1 Inter-individual differences in T helper (Th) cell responses affect susceptibility to infectious, allergic and autoimmune diseases. To identify factors contributing to these response differ- 1234567890():,; ences, here we analyze in vitro differentiated Th1 cells from 16 inbred mouse strains. Haplotype-based computational genetic analysis indicates that the p53 family protein, p73, affects Th1 differentiation. In cells differentiated under Th1 conditions in vitro, p73 negatively regulates IFNγ production. p73 binds within, or upstream of, and modulates the expression of Th1 differentiation-related genes such as Ifng and Il12rb2. Furthermore, in mouse experimental autoimmune encephalitis, p73-deficient mice have increased IFNγ production and less dis- ease severity, whereas in an adoptive transfer model of inflammatory bowel disease, transfer of p73-deficient naïve CD4+ T cells increases Th1 responses and augments disease severity. Our results thus identify p73 as a negative regulator of the Th1 immune response, suggesting that p73 dysregulation may contribute to susceptibility to autoimmune disease. 1 Laboratory of Molecular Immunology and the Immunology Center, National Heart, Lung, and Blood Institute, Bethesda, MD 20892-1674, USA. 2 Department of Anesthesia, Stanford University School of Medicine, Stanford, CA 94305, USA. 3 Laboratory of Molecular Immunology, National Institute of Allergy and Infectious Diseases, Bethesda, MD 20892, USA. 4Present address: Department of Biochemistry and Computer Science, Purdue University, West ✉ Lafayette, IN 37906, USA. -

Regulation of Expression and Activity of the Bhlh-PAS Transcription
Regulation of Expression and Activity of the bHLH-PAS Transcription Factor NPAS4 David Christopher Bersten B.Sc. (Biomedical Science), Honours (Biochemistry) A thesis submitted in fulfilment of the requirements for the degree of Doctor of Philosophy Discipline of Biochemistry School of Molecular and Biomedical Science University of Adelaide, Australia June 2014 1 Contents Abstract ................................................................................................................................................... 3 PhD Thesis Declaration ........................................................................................................................... 5 Acknowledgements ................................................................................................................................. 6 Publications ............................................................................................................................................. 8 Conference oral presentations ........................................................................................................... 9 Additional publications ....................................................................................................................... 9 Chapter 1: .............................................................................................................................................. 10 Introduction ..................................................................................................................................... -

Steroid-Dependent Regulation of the Oviduct: a Cross-Species Transcriptomal Analysis
University of Kentucky UKnowledge Theses and Dissertations--Animal and Food Sciences Animal and Food Sciences 2015 Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis Katheryn L. Cerny University of Kentucky, [email protected] Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Cerny, Katheryn L., "Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis" (2015). Theses and Dissertations--Animal and Food Sciences. 49. https://uknowledge.uky.edu/animalsci_etds/49 This Doctoral Dissertation is brought to you for free and open access by the Animal and Food Sciences at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Animal and Food Sciences by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. -

Evolution, Politics and Law
Valparaiso University Law Review Volume 38 Number 4 Summer 2004 pp.1129-1248 Summer 2004 Evolution, Politics and Law Bailey Kuklin Follow this and additional works at: https://scholar.valpo.edu/vulr Part of the Law Commons Recommended Citation Bailey Kuklin, Evolution, Politics and Law, 38 Val. U. L. Rev. 1129 (2004). Available at: https://scholar.valpo.edu/vulr/vol38/iss4/1 This Article is brought to you for free and open access by the Valparaiso University Law School at ValpoScholar. It has been accepted for inclusion in Valparaiso University Law Review by an authorized administrator of ValpoScholar. For more information, please contact a ValpoScholar staff member at [email protected]. Kuklin: Evolution, Politics and Law VALPARAISO UNIVERSITY LAW REVIEW VOLUME 38 SUMMER 2004 NUMBER 4 Article EVOLUTION, POLITICS AND LAW Bailey Kuklin* I. Introduction ............................................... 1129 II. Evolutionary Theory ................................. 1134 III. The Normative Implications of Biological Dispositions ......................... 1140 A . Fact and Value .................................... 1141 B. Biological Determinism ..................... 1163 C. Future Fitness ..................................... 1183 D. Cultural N orm s .................................. 1188 IV. The Politics of Sociobiology ..................... 1196 A. Political Orientations ......................... 1205 B. Political Tactics ................................... 1232 V . C onclusion ................................................. 1248 I. INTRODUCTION -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig. -

Ykt6 Membrane-To-Cytosol Cycling Regulates Exosomal Wnt Secretion
bioRxiv preprint doi: https://doi.org/10.1101/485565; this version posted December 3, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Ykt6 membrane-to-cytosol cycling regulates exosomal Wnt secretion Karen Linnemannstöns1,2, Pradhipa Karuna1,2, Leonie Witte1,2, Jeanette Kittel1,2, Adi Danieli1,2, Denise Müller1,2, Lena Nitsch1,2, Mona Honemann-Capito1,2, Ferdinand Grawe3,4, Andreas Wodarz3,4 and Julia Christina Gross1,2* Affiliations: 1Hematology and Oncology, University Medical Center Goettingen, Goettingen, Germany. 2Developmental Biochemistry, University Medical Center Goettingen, Goettingen, Germany. 3Molecular Cell Biology, Institute I for Anatomy, University of Cologne Medical School, Cologne, Germany 4Cluster of Excellence-Cellular Stress Response in Aging-Associated Diseases (CECAD), Cologne, Germany *Correspondence: Dr. Julia Christina Gross, Hematology and Oncology/Developmental Biochemistry, University Medical Center Goettingen, Justus-von-Liebig Weg 11, 37077 Goettingen Germany Abstract Protein trafficking in the secretory pathway, for example the secretion of Wnt proteins, requires tight regulation. These ligands activate Wnt signaling pathways and are crucially involved in development and disease. Wnt is transported to the plasma membrane by its cargo receptor Evi, where Wnt/Evi complexes are endocytosed and sorted onto exosomes for long-range secretion. However, the trafficking steps within the endosomal compartment are not fully understood. The promiscuous SNARE Ykt6 folds into an auto-inhibiting conformation in the cytosol, but a portion associates with membranes by its farnesylated and palmitoylated C-terminus. Here, we demonstrate that membrane detachment of Ykt6 is essential for exosomal Wnt secretion. -

Integrating Protein Copy Numbers with Interaction Networks to Quantify Stoichiometry in Mammalian Endocytosis
bioRxiv preprint doi: https://doi.org/10.1101/2020.10.29.361196; this version posted October 29, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Integrating protein copy numbers with interaction networks to quantify stoichiometry in mammalian endocytosis Daisy Duan1, Meretta Hanson1, David O. Holland2, Margaret E Johnson1* 1TC Jenkins Department of Biophysics, Johns Hopkins University, 3400 N Charles St, Baltimore, MD 21218. 2NIH, Bethesda, MD, 20892. *Corresponding Author: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2020.10.29.361196; this version posted October 29, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Abstract Proteins that drive processes like clathrin-mediated endocytosis (CME) are expressed at various copy numbers within a cell, from hundreds (e.g. auxilin) to millions (e.g. clathrin). Between cell types with identical genomes, copy numbers further vary significantly both in absolute and relative abundance. These variations contain essential information about each protein’s function, but how significant are these variations and how can they be quantified to infer useful functional behavior? Here, we address this by quantifying the stoichiometry of proteins involved in the CME network. We find robust trends across three cell types in proteins that are sub- vs super-stoichiometric in terms of protein function, network topology (e.g. -
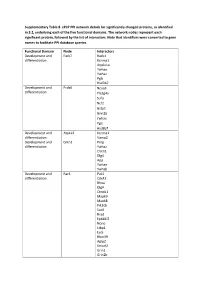
Supplementary Table 8. Cpcp PPI Network Details for Significantly Changed Proteins, As Identified in 3.2, Underlying Each of the Five Functional Domains
Supplementary Table 8. cPCP PPI network details for significantly changed proteins, as identified in 3.2, underlying each of the five functional domains. The network nodes represent each significant protein, followed by the list of interactors. Note that identifiers were converted to gene names to facilitate PPI database queries. Functional Domain Node Interactors Development and Park7 Rack1 differentiation Kcnma1 Atp6v1a Ywhae Ywhaz Pgls Hsd3b7 Development and Prdx6 Ncoa3 differentiation Pla2g4a Sufu Ncf2 Gstp1 Grin2b Ywhae Pgls Hsd3b7 Development and Atp1a2 Kcnma1 differentiation Vamp2 Development and Cntn1 Prnp differentiation Ywhaz Clstn1 Dlg4 App Ywhae Ywhab Development and Rac1 Pak1 differentiation Cdc42 Rhoa Dlg4 Ctnnb1 Mapk9 Mapk8 Pik3cb Sod1 Rrad Epb41l2 Nono Ltbp1 Evi5 Rbm39 Aplp2 Smurf2 Grin1 Grin2b Xiap Chn2 Cav1 Cybb Pgls Ywhae Development and Hbb-b1 Atp5b differentiation Hba Kcnma1 Got1 Aldoa Ywhaz Pgls Hsd3b4 Hsd3b7 Ywhae Development and Myh6 Mybpc3 differentiation Prkce Ywhae Development and Amph Capn2 differentiation Ap2a2 Dnm1 Dnm3 Dnm2 Atp6v1a Ywhab Development and Dnm3 Bin1 differentiation Amph Pacsin1 Grb2 Ywhae Bsn Development and Eef2 Ywhaz differentiation Rpgrip1l Atp6v1a Nphp1 Iqcb1 Ezh2 Ywhae Ywhab Pgls Hsd3b7 Hsd3b4 Development and Gnai1 Dlg4 differentiation Development and Gnao1 Dlg4 differentiation Vamp2 App Ywhae Ywhab Development and Psmd3 Rpgrip1l differentiation Psmd4 Hmga2 Development and Thy1 Syp differentiation Atp6v1a App Ywhae Ywhaz Ywhab Hsd3b7 Hsd3b4 Development and Tubb2a Ywhaz differentiation Nphp4 -

An Integrated Approach to Comprehensively Map the Molecular Context of Proteins
bioRxiv preprint doi: https://doi.org/10.1101/264788; this version posted February 13, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Liu et al. An integrated approach to comprehensively map the molecular context of proteins Xiaonan Liu1,2, Kari Salokas1,2, Fitsum Tamene1,2,3 and Markku Varjosalo1,2,3* 1Institute of Biotechnology, University of Helsinki, Helsinki 00014, Finland 2Helsinki Institute of Life Science, University of Helsinki, Helsinki 00014, Finland 3Proteomics Unit, University of Helsinki, Helsinki 00014, Finland *Corresponding author Abstract: Protein-protein interactions underlie almost all cellular functions. The comprehensive mapping of these complex cellular networks of stable and transient associations has been made available by affi nity purifi cation mass spectrometry (AP-MS) and more recently by proximity based labelling methods such as BioID. Due the advancements in both methods and MS instrumentation, an in-depth analysis of the whole human proteome is at grasps. In order to facilitate this, we designed and optimized an integrated approach utilizing MAC-tag combining both AP-MS and BioID in a single construct. We systematically applied this approach to 18 subcellular localization markers and generated a molecular context database, which can be used to defi ne molecular locations for any protein of interest. In addition, we show that by combining the AP-MS and BioID results we can also obtain interaction distances within a complex. Taken together, our combined strategy off ers comprehensive approach for mapping physical and functional protein interactions. Introduction: Majority of proteins do not function in isolation geting the endogenous bait protein, allowing and their interactions with other proteins defi ne purifi cation of the bait protein together with the their cellular functions. -

Biological Waste Water Treatment
Wastewater Management 18. SECONDARY TREATMENT Secondary treatment of the wastewater could be achieved by chemical unit processes such as chemical oxidation, coagulation-flocculation and sedimentation, chemical precipitation, etc. or by employing biological processes (aerobic or anaerobic) where bacteria are used as a catalyst for removal of pollutant. For removal of organic matter from the wastewater, biological treatment processes are commonly used all over the world. Hence, for the treatment of wastewater like sewage and many of the agro-based industries and food processing industrial wastewaters the secondary treatment will invariably consist of a biological reactor either in single stage or in multi stage as per the requirements to meet the discharge norms. 18.1 Biological Treatment The objective of the biological treatment of wastewater is to remove organic matter from the wastewater which is present in soluble and colloidal form or to remove nutrients such as nitrogen and phosphorous from the wastewater. The microorganisms (principally bacteria) are used to convert the colloidal and dissolved carbonaceous organic matter into various gases and into cell tissue. Cell tissue having high specific gravity than water can be removed in settling tank. Hence, complete treatment of the wastewater will not be achieved unless the cell tissues are removed. Biological removal of degradable organics involves a sequence of steps including mass transfer, adsorption, absorption and biochemical enzymatic reactions. Stabilization of organic substances by microorganisms in a natural aquatic environment or in a controlled environment of biological treatment systems is accomplished by two distinct metabolic processes: respiration and synthesis, also called as catabolism and anabolism, respectively.