Title Bus Bunching Prediction and Transit Route Demand Estimation
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Analysis and Simulation of Intervention Strategies Against Bus Bunching by Means of an Empirical Agent‑Based Model
This document is downloaded from DR‑NTU (https://dr.ntu.edu.sg) Nanyang Technological University, Singapore. Analysis and simulation of intervention strategies against bus bunching by means of an empirical agent‑based model Quek, Wei Liang; Chung, Ning Ning; Saw, Vee‑Liem; Chew, Lock Yue 2021 Quek, W. L., Chung, N. N., Saw, V. & Chew, L. Y. (2021). Analysis and simulation of intervention strategies against bus bunching by means of an empirical agent‑based model. Complexity, 2021. https://dx.doi.org/10.1155/2021/2606191 https://hdl.handle.net/10356/146829 https://doi.org/10.1155/2021/2606191 © 2021 Wei Liang Quek et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Downloaded on 30 Sep 2021 12:08:52 SGT Hindawi Complexity Volume 2021, Article ID 2606191, 24 pages https://doi.org/10.1155/2021/2606191 Research Article Analysis and Simulation of Intervention Strategies against Bus Bunching by means of an Empirical Agent-Based Model Wei Liang Quek,1 Ning Ning Chung,2 Vee-Liem Saw ,3,4 and Lock Yue Chew 3,4,5 1School of Humanities, Nanyang Technological University, 639818, Singapore 2Centre for University Core, Singapore University of Social Sciences, 599494, Singapore 3Division of Physics and Applied Physics, School of Physical and Mathematical Sciences, Nanyang Technological University, 637371, Singapore 4Data Science & Artificial Intelligence Research Centre, Nanyang Technological University, 639798, Singapore 5Complexity Institute, Nanyang Technological University, 637723, Singapore Correspondence should be addressed to Lock Yue Chew; [email protected] Received 27 April 2020; Revised 8 August 2020; Accepted 3 September 2020; Published 8 January 2021 Academic Editor: Tingqiang Chen Copyright © 2021 Wei Liang Quek et al. -

Bus Bunching Modelling and Control: a Passenger-Oriented Approach
CASPT 2018 Extended Abstract Bus Bunching Modelling and Control: A Passenger-oriented Approach Dong Zhao Abstract Introduction Bus reliability is one of the crucial element that describe the performance of the bus system operation. Due to the unreliable transit environment as well as the flexible internal operation, bus irregularity increasingly becomes an issue, especially in big cities with a massive demand. The uncertain bus operation lead to an imbalance of demand and supplement which influences the efficiency and effectivity of this transit. This kind of unreliability enables our bus becomes less attractive comparing with other public transportation such as metro and train. Those well-timetable-based mode have the operational advantage of being separable from the other traffic and have a less likelihood of being interrupted by external influence factors such as traffic lights or road constructions, which seems to be more reliable for the passenger. Also, due to the reliable operation, the real-time information provided for passenger is more trustable and the passenger arriving pattern are more similar to the uniform pattern, which is proved can increase the level of service reliability. On the other hand, the part of the travel demand that should be satisfied by bus obliged to be reallocated to other transit mode. The decreases of the efficiency and comfortability because of this extra demand would even compel those affordable people to travel by private vehicles which may increase the road pressure. Therefore, it is essential to improve the reliability of the bus service. One of the measurement of the bus unreliability is the level and extent of bus bunching. -

Headway Adherence. Detection and Reduction of the Bus Bunching Effect
HEADWAY ADHERENCE. DETECTION AND REDUCTION OF THE BUS BUNCHING EFFECT Josep Mension Camps Director Central Services and Deputy Chief Officer of Bus Network. Transports Metropolitans de Barcelona (TMB). Miquel Estrada Romeu Associate Professor. Universitat Politècnica de Catalunya- BarcelonaTECH. 1. INTRODUCTION Transit systems should provide a good performance to compete against the wide usage of cars in metropolitan areas. The level of service of these systems relies on a proper temporal and spatial coverage provision (high frequencies, low stop spacings) as well as significant regularity and comfort. In this way, bus systems in densely populated cities usually operate at short headways (10 minutes or less). However, in these busy routes, any delay suffered by a single bus is propagated to the whole bus fleet. This fact causes vehicle bunching and unstable time-headways. In real bus lines, we usually see that two or more vehicles arrive together or in close succession, followed by a long gap between them. There are many sources of potential external disruptions in the service of one bus: illegal parking in the bus lane, failure in the doors opening system, traffic jams, etc. However, some intrinsic characteristics of transit systems and traffic management may also induce delays at specific vehicles such as traffic signal coordination and irregular passenger arrivals at stops. These facts make the bus motion unstable. Therefore, bus bunching is a common problem in the real operation of buses all over the world that must be addressed. The crucial issue is that bus bunching has a great impact on both users and agency cost. From a passenger perspective, the bus bunching phenomena increases the travel time of passengers (riding and waiting time) and worsens the vehicle occupancy. -

Multiline Bus Bunching Control Via Vehicle Substitution
Transportation Research Part B 126 (2019) 68–86 Contents lists available at ScienceDirect Transportation Research Part B journal homepage: www.elsevier.com/locate/trb Multiline Bus Bunching Control via Vehicle Substitution ∗ Antoine Petit, Chao Lei, Yanfeng Ouyang Department of Civil and Environmental Engineering, University of Illinois at Urbana-Champaign, Urbana, IL 61801, USA a r t i c l e i n f o a b s t r a c t Article history: Traditional bus bunching control methods (e.g., adding slack to schedules, adapting cruis- Received 2 August 2018 ing speed), in one way or another, trade commercial speed for better system stability and, Revised 13 April 2019 as a result, may impose the burden of additional travel time on passengers. Recently, a dy- Accepted 20 May 2019 namic bus substitution strategy, where standby buses are dispatched to take over service Available online 6 June 2019 from late/early buses, was proposed as an attempt to enhance system reliability without Keywords: sacrificing too much passenger experience. This paper further studies this substitution Bus bunching strategy in the context of multiple bus lines under either time-independent or time- Transit reliability varying settings. In the latter scenario, the fleet of standby buses can be dynamically Approximate dynamic programming utilized to save on opportunity costs. We model the agency’s substitution decisions and Multiline control retired bus repositioning decisions as a stochastic dynamic program so as to obtain the optimal policy that minimizes the system-wide costs. Numerical results show that the dynamic substitution strategy can benefit from the “economies of scale” by pooling the standby fleet across lines, and there are also benefits from dynamic fleet management when transit demand varies over time. -

An Approach to Reducing Bus Bunching
UC Berkeley Dissertations Title An Approach to Reducing Bus Bunching Permalink https://escholarship.org/uc/item/6zc5j8xg Author Pilachowski, Joshua Michael Publication Date 2009-12-01 eScholarship.org Powered by the California Digital Library University of California University of California Transportation Center UCTC Dissertation No. 165 An Approach to Reducing Bus Bunching Joshua Michael Pilachowski University of California, Berkeley 2009 An Approach to Reducing Bus Bunching by Joshua Michael Pilachowski A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Engineering—Civil and Environmental Engineering in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Carlos F. Daganzo Professor Samer M. Madanat Professor Laurent El Ghaoui Fall 2009 An Approach to Reducing Bus Bunching Copyright 2009 by Joshua Michael Pilachowski i Abstract An Approach to Reducing Bus Bunching by Joshua Michael Pilachowski Doctor of Philosophy in Engineering University of California, Berkeley Professor Carlos F. Daganzo, Chair The tendency of buses to bunch is a problem that was defined almost 50 years ago. Since then, there has been a significant amount of work done on the problem; however, the tendency of the current literature is either to only focus on the surface causes or to rely on simulation to create results instead of model formulation. With GPS installed on many buses throughout the world, the data is only being used for monitoring and informing the user. This research proposes a new approach to solving the problem that uses the GPS data to directly counteract the cause of the bunching by allowing the buses to cooperate with each other and determine their speed based on relative position. -

Empirical Analysis of Bus Bunching Characteristics Based on Bus AVL/APC Data
Portland State University PDXScholar Civil and Environmental Engineering Faculty Publications and Presentations Civil and Environmental Engineering 1-2015 Empirical Analysis of Bus Bunching Characteristics Based on Bus AVL/APC Data Wei Feng Portland State University Miguel A. Figliozzi Portland State University, [email protected] Follow this and additional works at: https://pdxscholar.library.pdx.edu/cengin_fac Part of the Civil Engineering Commons, Environmental Engineering Commons, and the Transportation Engineering Commons Let us know how access to this document benefits ou.y Citation Details Feng, Wei and Figliozzi, Miguel A., "Empirical Analysis of Bus Bunching Characteristics Based on Bus AVL/ APC Data" (2015). Civil and Environmental Engineering Faculty Publications and Presentations. 315. https://pdxscholar.library.pdx.edu/cengin_fac/315 This Post-Print is brought to you for free and open access. It has been accepted for inclusion in Civil and Environmental Engineering Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. 1 Empirical Analysis of Bus Bunching Characteristics Based on Bus AVL/APC Data 2 3 4 5 6 Wei Feng* 7 PhD. Researcher 8 Portland State University 9 [email protected] 10 11 12 13 14 Miguel Figliozzi 15 Associate Professor 16 Portland State University 17 [email protected] 18 19 20 21 22 Mailing Address: 23 Portland State University 24 Civil and Environmental Engineering 25 PO Box 751 26 Portland, OR 97207 27 28 29 30 31 *corresponding author 32 33 34 35 36 Word count: 4,292 words + (11 Figures + 1 Table) * 250 = 7,292 words 37 38 39 40 Submitted to the 94th Annual Meeting of Transportation Research Board, 41 January 11-15, 2015 42 43 Feng and Figliozzi 1 1 Abstract 2 3 Bus bunching takes place when headways between buses are irregular. -

Definition and Properties of Alternative Bus Service Reliability Measures at the Stop Level
Definition and Properties of Alternative Bus Service Reliability Measures at the Stop Level Definition and Properties of Alternative Bus Service Reliability Measures at the Stop Level Meead Saberi and Ali Zockaie K., Northwestern University Wei Feng, Portland State University Ahmed El-Geneidy, McGill University Abstract TheTransit Capacity and Quality of Service Manual (TCQSM) provides transit agen- cies with tools for measuring system performance at different levels of operation. Bus service reliability, one of the key performance measures, has become a major con- cern of both transit operators and users because it significantly affects user experi- ence and service quality perceptions. The objective of this paper is to assess the exist- ing reliability measures proposed by TCQSM and develop new ones at the bus stop level. The latter are not suggested as replacements for the existing measures; rather, they are complementary. Using empirical data from archived Bus Dispatch System (BDS) data in Portland, Oregon, a number of key characteristics of distributions of delay (schedule deviation) and headway deviation are identified. In addition, the proposed reliability measures at the stop level are capable of differentiating between the costs of being early versus late. The results of this study can be implemented in transit operations for use in improving schedules and operations strategies. Also, transit agencies can use the proposed reliability measures to evaluate and prioritize stops for operational improvement purposes. 97 Journal of Public Transportation, Vol. 16, No. 1, 2013 Introduction Monitoring of the performance measures of public transportation systems has improved since advanced surveillance, monitoring, and management systems have been deployed by transit agencies worldwide. -

Bus Bunching As a Synchronisation Phenomenon Vee-Liem Saw 1,2, Ning Ning Chung3, Wei Liang Quek1, Yi En Ian Pang1 & Lock Yue Chew1,2,3
www.nature.com/scientificreports OPEN Bus bunching as a synchronisation phenomenon Vee-Liem Saw 1,2, Ning Ning Chung3, Wei Liang Quek1, Yi En Ian Pang1 & Lock Yue Chew1,2,3 Bus bunching is a perennial phenomenon that not only diminishes the efciency of a bus system, but Received: 5 March 2019 also prevents transit authorities from keeping buses on schedule. We present a physical theory of buses Accepted: 18 April 2019 serving a loop of bus stops as a ring of coupled self-oscillators, analogous to the Kuramoto model. Published: xx xx xxxx Sustained bunching is a repercussion of the process of phase synchronisation whereby the phases of the oscillators are locked to each other. This emerges when demand exceeds a critical threshold. Buses also bunch at low demand, albeit temporarily, due to frequency detuning arising from diferent human drivers’ distinct natural speeds. We calculate the critical transition when complete phase locking (full synchronisation) occurs for the bus system, and posit the critical transition to completely no phase locking (zero synchronisation). The intermediate regime is the phase where clusters of partially phase locked buses exist. Intriguingly, these theoretical results are in close correspondence to real buses in a university’s shuttle bus system. A self-oscillator is a unit with an internal source of energy (to overcome dissipation) that continuously and auton- omously performs rhythmic motion. It is stable against perturbations on its amplitude but neutrally stable over perturbations on its phase. Te latter allows an array of coupled self-oscillators to undergo phase synchronisa- tion, as individual members afect others’ phases through their nonlinear interactions1. -

Characteristics of Bus Rapid Transit for Decision-Making
Project No: FTA-VA-26-7222-2004.1 Federal United States Transit Department of August 2004 Administration Transportation CharacteristicsCharacteristics ofof BusBus RapidRapid TransitTransit forfor Decision-MakingDecision-Making Office of Research, Demonstration and Innovation NOTICE This document is disseminated under the sponsorship of the United States Department of Transportation in the interest of information exchange. The United States Government assumes no liability for its contents or use thereof. The United States Government does not endorse products or manufacturers. Trade or manufacturers’ names appear herein solely because they are considered essential to the objective of this report. Form Approved REPORT DOCUMENTATION PAGE OMB No. 0704-0188 Public reporting burden for this collection of information is estimated to average 1 hour per response, including the time for reviewing instructions, searching existing data sources, gathering and maintaining the data needed, and completing and reviewing the collection of information. Send comments regarding this burden estimate or any other aspect of this collection of information, including suggestions for reducing this burden, to Washington Headquarters Services, Directorate for Information Operations and Reports, 1215 Jefferson Davis Highway, Suite 1204, Arlington, VA 22202-4302, and to the Office of Management and Budget, Paperwork Reduction Project (0704-0188), Washington, DC 20503. 1. AGENCY USE ONLY (Leave blank) 2. REPORT DATE 3. REPORT TYPE AND DATES August 2004 COVERED BRT Demonstration Initiative Reference Document 4. TITLE AND SUBTITLE 5. FUNDING NUMBERS Characteristics of Bus Rapid Transit for Decision-Making 6. AUTHOR(S) Roderick B. Diaz (editor), Mark Chang, Georges Darido, Mark Chang, Eugene Kim, Donald Schneck, Booz Allen Hamilton Matthew Hardy, James Bunch, Mitretek Systems Michael Baltes, Dennis Hinebaugh, National Bus Rapid Transit Institute Lawrence Wnuk, Fred Silver, Weststart - CALSTART Sam Zimmerman, DMJM + Harris 8. -
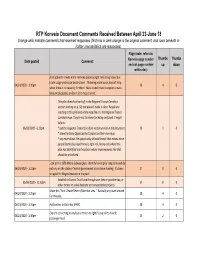
RTP Konveio Document Comments Received Between April 23-June 18
RTP Konveio Document Comments Received Between April 23-June 18 Orange cells indicate comments that received responses (first row in dark orange is the original comment, and rows beneath in lighter orange/italics are responses) Page (note: refers to Thumbs Thumbs Date posted Comment Konveio page number and not page number up down within doc) Add option to create more rail lines (subway/light rail) along heavy bus route usage and major destinations. Throwing more buses doesn't help 04/24/2020 - 1:20pm 26 4 0 when there is no capacity for them. Mass transit must transport a mass amount of people, or else it isn't mass transit. This plan does that (sort of) in the Regional Transit Corridors section starting on p. 58, but doesn't make it clear. People are reacting to this pink and white map like it is the Regional Transit Corridors map. They're not to blame for being confused. It might help to: 06/03/2020 - 6:12pm * put the Regional Transit Corridors section earlier in the document 26 1 0 * show the Early Opportunity Corridors on their own map * say more about the opportunity to build transit that moves more people faster (bus rapid transit, light rail, heavy rail) where this plan has identified are the places where improvements like that should be prioritized Look at the 1978 Metro Subway plan. Identify funding for long term and do 04/24/2020 - 1:22pm not rely on the state or federal government to continue funding. It's been 27 8 0 stripped for illogical reasons in the past! Establish a Transit Trust Fund through user fees or gasoline tax, or 05/06/2020 - 11:50pm 27 8 0 other means to solely dedicate to transportation projects. -

A Multi-Method Simulation of a High-Frequency Bus Line Using Anylogic
A multi-method simulation of a high-frequency bus line using AnyLogic Thierry van der Spek Name Two LIACS, Leiden University LIACS, Leiden University [email protected] [email protected] ABSTRACT able approach to visualize this bus line and create a better In this work a mixed agent-based and discrete event simula- comprehension of frequently occurring problems. One of the tion model is developed for a high frequency bus route in the external factors, the number of passengers, is modelled and Netherlands. With this model, different passenger growth can be configured to analyse several passenger growth sce- scenarios can be easily evaluated. This simulation model narios. The effect of these scenarios is illustrated by several helps policy makers to predict changes that have to be made key performance indicators (KPIs), determined by Arriva. to bus routes and planned travel times before problems oc- This paper is structured as follows: In Section 2, common cur. The model is validated using several performance indi- domain terminology is introduced to gain a better under- cators, showing that under some model assumptions, it can standing of the problems occurring. In Section 3, the prob- realistically simulate real-life situations. The simulation's lems occurring are described by formulating our KPIs. In workings are illustrated by two use cases. Section 4, we look into related work in this domain, and also at other agent-based and discrete-event simulation models. 1. INTRODUCTION Section 5 discusses the data that is considered and the data sets that are used. Also, the preprocessing of data that In all metropolitan areas, people rely on buses as a means is needed to generate our model is discussed. -

Speeding up Chicago's Buses
BACK ON THE BUS: SPEEDING UP CHICAGO’S BUSES Funded by TABLE OF CONTENTS EXECUTIVE SUMMARY 1 WHAT RIDERS ARE SAYING ABOUT CHICAGO’S BUS SERVICE 5 SERVICE UPGRADES 6 Priority improvements to make Chicago’s buses faster and more reliable Dedicated bus lanes 6 Traffic signal improvements 8 Faster boarding 9 Route profiles & recommendations 11 POLICY CHANGES 16 What’s next? 19 ACKNOWLEDGMENTS 20 EXECUTIVE SUMMARY As Chicago strives to become a more connected, spoke rail system continues to be a good option prosperous, and equitable city, elected officials for people who live and work along the CTA train and transit agency leaders must take action to lines and in the Loop, but many neighborhoods improve bus service. More than half of CTA trips lack access to it. Without more investment in bus in Chicago are made by bus and it’s one of the service, Chicago risks more people abandoning most affordable transportation options in many transit for transportation options that are more neighborhoods where people can’t easily access expensive and less efficient, healthy, and green. the El train. Every day, buses are connecting In an era of limited funding at all levels of people to jobs, schools, and other critical services government, bus upgrades are cheaper and can while taking up far less space on the road than be implemented faster than rail modernization private vehicles. While buses continue to play a and expansion. The next several years present central role in the city’s transportation system, an opportunity to make timely, cost-effective there are signs that quality bus service is under improvements to bus service while continuing threat in a changing transportation environment.