Foundations of Technical Analysis: Computational Algorithms, Statistical Inference, and Empirical Implementation
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Putting Volatility to Work
Wh o ’ s afraid of volatility? Not anyone who wants a true edge in his or her trad i n g , th a t ’ s for sure. Get a handle on the essential concepts and learn how to improve your trading with pr actical volatility analysis and trading techniques. 2 www.activetradermag.com • April 2001 • ACTIVE TRADER TRADING Strategies BY RAVI KANT JAIN olatility is both the boon and bane of all traders — The result corresponds closely to the percentage price you can’t live with it and you can’t really trade change of the stock. without it. Most of us have an idea of what volatility is. We usually 2. Calculate the average day-to-day changes over a certain thinkV of “choppy” markets and wide price swings when the period. Add together all the changes for a given period (n) and topic of volatility arises. These basic concepts are accurate, but calculate an average for them (Rm): they also lack nuance. Volatility is simply a measure of the degree of price move- Rt ment in a stock, futures contract or any other market. What’s n necessary for traders is to be able to bridge the gap between the Rm = simple concepts mentioned above and the sometimes confus- n ing mathematics often used to define and describe volatility. 3. Find out how far prices vary from the average calculated But by understanding certain volatility measures, any trad- in Step 2. The historical volatility (HV) is the “average vari- er — options or otherwise — can learn to make practical use of ance” from the mean (the “standard deviation”), and is esti- volatility analysis and volatility-based strategies. -

Testing the Profitability of Technical Analysis in Singapore And
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by ScholarBank@NUS Testing the Profitability of Technical Analysis in Singapore and Malaysian Stock Markets Department of Electrical and Computer Engineering Zoheb Jamal HT080461R In partial fulfillment of the requirements for the Degree of Master of Engineering National University of Singapore 2010 1 Abstract Technical Analysis is a graphical method of looking at the history of price of a stock to deduce the probable future trend in its return. Being primarily visual, this technique of analysis is difficult to quantify as there are numerous definitions mentioned in the literature. Choosing one over the other might lead to data- snooping bias. This thesis attempts to create a universe of technical rules, which are then tested on historical data of Straits Times Index and Kuala Lumpur Composite Index. The technical indicators tested are Filter Rules, Moving Averages, Channel Breakouts, Support and Resistance and Momentum Strategies in Price. The technical chart patterns tested are Head and Shoulders, Inverse Head and Shoulders, Broadening Tops and Bottoms, Triangle Tops and Bottoms, Rectangle Tops and Bottoms, Double Tops and Bottoms. This thesis also outlines a pattern recognition algorithm based on local polynomial regression to identify technical chart patterns that is an improvement over the kernel regression approach developed by Lo, Mamaysky and Wang [4]. 2 Acknowledgements I would like to thank my supervisor Dr Shuzhi Sam Ge whose invaluable advice and support made this research possible. His mentoring and encouragement motivated me to attempt a project in Financial Engineering, even though I did not have a background in Finance. -

Technical and Fundamental Analysis
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Supervised Undergraduate Student Research Chancellor’s Honors Program Projects and Creative Work 12-2016 Understanding the Retail Investor: Technical and Fundamental Analysis Ben Davis [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_chanhonoproj Part of the Finance and Financial Management Commons Recommended Citation Davis, Ben, "Understanding the Retail Investor: Technical and Fundamental Analysis" (2016). Chancellor’s Honors Program Projects. https://trace.tennessee.edu/utk_chanhonoproj/2024 This Dissertation/Thesis is brought to you for free and open access by the Supervised Undergraduate Student Research and Creative Work at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Chancellor’s Honors Program Projects by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. University of Tennessee Global Leadership Scholars & Chancellors Honors Program Undergraduate Thesis Understanding the Retail Investor: Technical and Fundamental Analysis Benjamin Craig Davis Advisor: Dr. Daniel Flint April 22, 2016 1 Understanding the Retail Investor: Fundamental and Technical Analysis Abstract: If there is one thing that people take more seriously than their health, it is money. Behavior and emotion influence how retail investors make decisions on the methodology of investing/trading their money. The purpose of this study is to better understand what influences retail investors to choose the method by which they invest in capital markets. By better understanding what influences retail investors to choose a certain investment methodology, eventually researchers can provide tailored and normative advice to investors as well as the financial planning industry in effectively and efficiently working with clients. -

Relative Strength Index for Developing Effective Trading Strategies in Constructing Optimal Portfolio
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 19 (2017) pp. 8926-8936 © Research India Publications. http://www.ripublication.com Relative Strength Index for Developing Effective Trading Strategies in Constructing Optimal Portfolio Dr. Bhargavi. R Associate Professor, School of Computer Science and Software Engineering, VIT University, Chennai, Vandaloor Kelambakkam Road, Chennai, Tamilnadu, India. Orcid Id: 0000-0001-8319-6851 Dr. Srinivas Gumparthi Professor, SSN School of Management, Old Mahabalipuram Road, Kalavakkam, Chennai, Tamilnadu, India. Orcid Id: 0000-0003-0428-2765 Anith.R Student, SSN School of Management, Old Mahabalipuram Road, Kalavakkam, Chennai, Tamilnadu, India. Abstract Keywords: RSI, Trading, Strategies innovation policy, innovative capacity, innovation strategy, competitive Today’s investors’ dilemma is choosing the right stock for advantage, road transport enterprise, benchmarking. investment at right time. There are many technical analysis tools which help choose investors pick the right stock, of which RSI is one of the tools in understand whether stocks are INTRODUCTION overpriced or under priced. Despite its popularity and powerfulness, RSI has been very rarely used by Indian Relative Strength Index investors. One of the important reasons for it is lack of Investment in stock market is common scenario for making knowledge regarding how to use it. So, it is essential to show, capital gains. One of the major concerns of today’s investors how RSI can be used effectively to select shares and hence is regarding choosing the right securities for investment, construct portfolio. Also, it is essential to check the because selection of inappropriate securities may lead to effectiveness and validity of RSI in the context of Indian stock losses being suffered by the investor. -

Stairstops Using Magee’S Basing Points to Ratchet Stops in Trends
StairStops Using Magee’s Basing Points to Ratchet Stops in Trends This may be the most important book on stops of this decade for the general investor. Professor Henry Pruden, PhD. Golden Gate University W.H.C. Bassetti Coauthor/Editor Edwards & Magee’s Technical Analysis of Stock Trends, 9th Edition This book contains information obtained from authentic and highly regarded sources. Reprinted material is quoted with permission, and sources are indicated. A wide variety of references are listed. Reasonable efforts have been made to publish reliable date and information, but the author and the publisher cannot assume responsibility for the validity of all materials or for the consequences of their use. Neither this book nor any part may be reproduced or transmitted in any form by any means, electronic or mechanical, including photocopying, microfilming, and recording, or by any information storage or retrieval system, without prior permission in writing from the publisher. The consent of MaoMao Press LLC does not extend to copying for general distribution, for promotion, for creating new works, or for resale. Specific permission must be obtained in writing from MaoMao Press LLC for such copying. Direct all inquiries to MaoMao Press LLC, POB 88, San Geronimo, CA 94963-0088 Trademark Notice: Product or corporate names may be trademarks or registered trademarks, and are used only for identification and explanation, without intent to infringe. Dow–JonesSM, The DowSM, Dow–Jones Industrial AverageSM, and DJIASM are service marks of Dow– Jones & Company, Inc., and have been licensed for use for certain purposes by the Board of Trade of the City of Chicago (CBOT®). -

Pattern Recognition User Guide.Book
Chart Pattern Recognition Module User Guide CPRM User Guide April 2011 Edition PF-09-01-05 Support Worldwide Technical Support and Product Information www.nirvanasystems.com Nirvana Systems Corporate Headquarters 7000 N. MoPac, Suite 425, Austin, Texas 78731 USA Tel: 512 345 2545 Fax: 512 345 4225 Sales Information For product information or to place an order, please contact 800 880 0338 or 512 345 2566. You may also fax 512 345 4225 or send email to [email protected]. Technical Support Information For assistance in installing or using Nirvana products, please contact 512 345 2592. You may also fax 512 345 4225 or send email to [email protected]. To comment on the documentation, send email to [email protected]. © 2011 Nirvana Systems Inc. All rights reserved. Important Information Copyright Under the copyright laws, this publication may not be reproduced or transmitted in any form, electronic or mechanical, including photocopying, recording, storing in an information retrieval system, or translating, in whole or in part, without the prior written consent of Nirvana Systems, Inc. Trademarks OmniTrader™, VisualTrader™, Adaptive Reasoning Model™, ARM™, ARM Knowledge Base™, Easy Data™, The Trading Game™, Focus List™, The Power to Trade with Confidence™, The Path to Trading Success™, The Trader’s Advantage™, Pattern Tutor ™, and Chart Pattern Recognition Module™ are trademarks of Nirvana Systems, Inc. Product and company names mentioned herein are trademarks or trade names of their respective companies. DISCLAIMER REGARDING USE OF NIRVANA SYSTEMS PRODUCTS Trading stocks, mutual funds, futures, and options involves high risk including possible loss of principal and other losses. Neither the software nor any demonstration of its operation should be construed as a recommendation or an offer to buy or sell securities or security derivative products of any kind. -

Lecture 20: Technical Analysis Steven Skiena
Lecture 20: Technical Analysis Steven Skiena Department of Computer Science State University of New York Stony Brook, NY 11794–4400 http://www.cs.sunysb.edu/∼skiena The Efficient Market Hypothesis The Efficient Market Hypothesis states that the price of a financial asset reflects all available public information available, and responds only to unexpected news. If so, prices are optimal estimates of investment value at all times. If so, it is impossible for investors to predict whether the price will move up or down. There are a variety of slightly different formulations of the Efficient Market Hypothesis (EMH). For example, suppose that prices are predictable but the function is too hard to compute efficiently. Implications of the Efficient Market Hypothesis EMH implies it is pointless to try to identify the best stock, but instead focus our efforts in constructing the highest return portfolio for our desired level of risk. EMH implies that technical analysis is meaningless, because past price movements are all public information. EMH’s distinction between public and non-public informa- tion explains why insider trading should be both profitable and illegal. Like any simple model of a complex phenomena, the EMH does not completely explain the behavior of stock prices. However, that it remains debated (although not completely believed) means it is worth our respect. Technical Analysis The term “technical analysis” covers a class of investment strategies analyzing patterns of past behavior for future predictions. Technical analysis of stock prices is based on the following assumptions (Edwards and Magee): • Market value is determined purely by supply and demand • Stock prices tend to move in trends that persist for long periods of time. -

Technical Analysis, Liquidity, and Price Discovery∗
Technical Analysis, Liquidity, and Price Discovery∗ Felix Fritzy Christof Weinhardtz Karlsruhe Institute of Technology Karlsruhe Institute of Technology This version: 27.08.2016 Abstract Academic literature suggests that Technical Analysis (TA) plays a role in the decision making process of some investors. If TA traders act as uninformed noise traders and generate a relevant amount of trading volume, market quality could be affected. We analyze moving average (MA) trading signals as well as support and resistance levels with respect to market quality and price efficiency. For German large-cap stocks we find excess liquidity demand around MA signals and high limit order supply on support and resistance levels. Depending on signal type, spreads increase or remain unaffected which contra- dicts the mitigating effect of uninformed TA trading on adverse selection risks. The analysis of transitory and permanent price components demonstrates increasing pricing errors around TA signals, while for MA permanent price changes tend to increase of a larger magnitude. This suggests that liquidity demand in direction of the signal leads to persistent price deviations. JEL Classification: G12, G14 Keywords: Technical Analysis, Market Microstructure, Noise Trading, Liquidity ∗Financial support from Boerse Stuttgart is gratefully acknowledged. The Stuttgart Stock Exchange (Boerse Stuttgart) kindly provided us with databases. The views expressed here are those of the authors and do not necessarily represent the views of the Boerse Stuttgart Group. yE-mail: [email protected]; Karlsruhe Institute of Technology, Research Group Financial Market Innovation, Englerstrasse 14, 76131 Karlsruhe, Germany. zE-mail: [email protected]; Karlsruhe Institute of Technology, Institute of Information System & Marketing, Englerstrasse 14, 76131 Karlsruhe, Germany. -

Technical-Analysis-Bloomberg.Pdf
TECHNICAL ANALYSIS Handbook 2003 Bloomberg L.P. All rights reserved. 1 There are two principles of analysis used to forecast price movements in the financial markets -- fundamental analysis and technical analysis. Fundamental analysis, depending on the market being analyzed, can deal with economic factors that focus mainly on supply and demand (commodities) or valuing a company based upon its financial strength (equities). Fundamental analysis helps to determine what to buy or sell. Technical analysis is solely the study of market, or price action through the use of graphs and charts. Technical analysis helps to determine when to buy and sell. Technical analysis has been used for thousands of years and can be applied to any market, an advantage over fundamental analysis. Most advocates of technical analysis, also called technicians, believe it is very likely for an investor to overlook some piece of fundamental information that could substantially affect the market. This fact, the technician believes, discourages the sole use of fundamental analysis. Technicians believe that the study of market action will tell all; that each and every fundamental aspect will be revealed through market action. Market action includes three principal sources of information available to the technician -- price, volume, and open interest. Technical analysis is based upon three main premises; 1) Market action discounts everything; 2) Prices move in trends; and 3) History repeats itself. This manual was designed to help introduce the technical indicators that are available on The Bloomberg Professional Service. Each technical indicator is presented using the suggested settings developed by the creator, but can be altered to reflect the users’ preference. -

Technical Analysis: Technical Indicators
Chapter 2.3 Technical Analysis: Technical Indicators 0 TECHNICAL ANALYSIS: TECHNICAL INDICATORS Charts always have a story to tell. However, from time to time those charts may be speaking a language you do not understand and you may need some help from an interpreter. Technical indicators are the interpreters of the Forex market. They look at price information and translate it into simple, easy-to-read signals that can help you determine when to buy and when to sell a currency pair. Technical indicators are based on mathematical equations that produce a value that is then plotted on your chart. For example, a moving average calculates the average price of a currency pair in the past and plots a point on your chart. As your currency chart moves forward, the moving average plots new points based on the updated price information it has. Ultimately, the moving average gives you a smooth indication of which direction the currency pair is moving. 1 2 Each technical indicator provides unique information. You will find you will naturally gravitate toward specific technical indicators based on your TRENDING INDICATORS trading personality, but it is important to become familiar with all of the Trending indicators, as their name suggests, identify and follow the trend technical indicators at your disposal. of a currency pair. Forex traders make most of their money when currency pairs are trending. It is therefore crucial for you to be able to determine You should also be aware of the one weakness associated with technical when a currency pair is trending and when it is consolidating. -
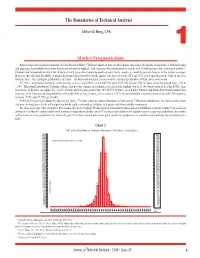
The Boundaries of Technical Analysis Milton W
The Boundaries of Technical Analysis Milton W. Berg, CFA 1 Market Prognostication In his treatise on stock market patterns, the late Professor Harry V. Roberts1 observed that “of all economic time series, the history of stock prices, both individual and aggregate, has probably been most widely and intensively studied,” and “patterns of technical analysis may be little if nothing more than a statistical artifact.”2 Ibbotson and Sinquefield maintain that historical stock price data cannot be used to predict daily, weekly or monthly percent changes in the market averages. However, they do claim the ability to predict in advance the probability that the market will move between +X% and -Y% over a specific period.3 Only to this very limited extent – forecasting the probabilities of return – can historical stock price movements be considered indicative of future price movements. In Chart 1, we present a histogram of the five-day rate of change (ROC) in the S&P 500 since 1928. The five-day ROC of stock prices has ranged from -27% to + 24%. This normal distribution4 is strong evidence that five-day changes in stock prices are effectively random. Out of 21,165 observations of five-day ROCs, there have been 138 declines exceeding -8%, (0.65% of total) and 150 gains greater than +8% (0.71% of total). Accordingly, Ibbotson and Sinquefield would maintain that over any given 5-day period, the probability of the S&P 500 gaining or losing 8% or more is 1.36%. Stated differently, the probabilities of the S&P 500 returning between -7.99% and +7.99% are 98.64%. -

The Titans of Technical Analysis by David Penn REAL WORLD
Stocks & Commodities V. 20:10 (32-38): The Titans Of Technical Analysis by David Penn REAL WORLD A Celebration Of Technical Analysts From Dow To Zweig The Titans Of Technical Analysis A not-so-random walk through the history of charting the observations, and commentary on the subjects of trading markets. and technical analysis. From our earliest issues featuring reviews titled “An Easy Course In Using The HP-12C And by David Penn Other Financial Calculators” to the present issue, which includes pages of Traders’ Tips in sophisticated computer any years ago, a poet friend who was editing language, no other publication has had its finger on the pulse a collection of contemporary verse noted to of both applied and theoretical technical analysis for as long me that “about half the working poets in as STOCKS & COMMODITIES. And this has been no mere M America are going to be really upset about minding the store. this anthology. Of course, the other half of them are in the S&C publisher Jack Hutson introduced the TRIX, or triple book. …” exponential smoothing oscillator, in 1983. The Richard Such sentiments came to mind when I embarked upon the Wyckoff method was reintroduced to the world via these task of highlighting the few among the many whose contri- pages in 1986. John Bollinger, Jack Schwager, and Vic butions to the field of technical analysis have made them Sperandeo were all among S&C’s interviews in 1993. In the what STOCKS & COMMODITIES has designated the “Titans nine-odd years since then, as a bull market in equities resumed, Of Technical Analysis.” S&C was on hand to provide technical tools for minimizing How subjective is such a list? In some ways, all too risk and maximizing gain — whether through new indicators subjective — particularly with those whose contributions (such as John Ehlers’ MESA adaptive moving averages), new are more recent or are less widely enjoyed.