The IBM Presentation Template
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Energy-Efficient VLSI Architectures for Next
UNIVERSITY OF CALIFORNIA Los Angeles Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical Engineering by Fang-Li Yuan 2014 c Copyright by Fang-Li Yuan 2014 ABSTRACT OF THE DISSERTATION Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios by Fang-Li Yuan Doctor of Philosophy in Electrical Engineering University of California, Los Angeles, 2014 Professor Dejan Markovic,´ Chair Dedicated radio hardware is no longer promising as it was in the past. Today, the support of diverse standards dictates more flexible solutions. Software-defined radio (SDR) provides the flexibility by replacing dedicated blocks (i.e. ASICs) with more general processors to adapt to various functions, standards and even allow mutable de- sign changes. However, such replacement generally incurs significant efficiency loss in circuits, hindering its feasibility for energy-constrained devices. The capability of dy- namic and blind spectrum analysis, as featured in the cognitive radio (CR) technology, makes chip implementation even more challenging. This work discusses several design techniques to achieve near-ASIC energy effi- ciency while providing the flexibility required by software-defined and cognitive radios. The algorithm-architecture co-design is used to determine domain-specific dataflow ii structures to achieve the right balance between energy efficiency and flexibility. The flexible instruction-set-architecture (ISA), the multi-scale interconnects, and the multi- core dynamic scheduling are also proposed to reduce the energy overhead. We demon- strate these concepts on two real-time blind classification chips for CR spectrum anal- ysis, as well as a 16-core processor for baseband SDR signal processing. -

20201130 Gcdv V1.0.Pdf
DE LA RECHERCHE À L’INDUSTRIE Architecture evolutions for HPC 30 Novembre 2020 Guillaume Colin de Verdière Commissariat à l’énergie atomique et aux énergies alternatives - www.cea.fr Commissariat à l’énergie atomique et aux énergies alternatives EUROfusion G. Colin de Verdière 30/11/2020 EVOLUTION DRIVER: TECHNOLOGICAL CONSTRAINTS . Power wall . Scaling wall . Memory wall . Towards accelerated architectures . SC20 main points Commissariat à l’énergie atomique et aux énergies alternatives EUROfusion G. Colin de Verdière 30/11/2020 2 POWER WALL P: power 푷 = 풄푽ퟐ푭 V: voltage F: frequency . Reduce V o Reuse of embedded technologies . Limit frequencies . More cores . More compute, less logic o SIMD larger o GPU like structure © Karl Rupp https://software.intel.com/en-us/blogs/2009/08/25/why-p-scales-as-cv2f-is-so-obvious-pt-2-2 Commissariat à l’énergie atomique et aux énergies alternatives EUROfusion G. Colin de Verdière 30/11/2020 3 SCALING WALL FinFET . Moore’s law comes to an end o Probable limit around 3 - 5 nm o Need to design new structure for transistors Carbon nanotube . Limit of circuit size o Yield decrease with the increase of surface • Chiplets will dominate © AMD o Data movement will be the most expensive operation • 1 DFMA = 20 pJ, SRAM access= 50 pJ, DRAM access= 1 nJ (source NVIDIA) 1 nJ = 1000 pJ, Φ Si =110 pm Commissariat à l’énergie atomique et aux énergies alternatives EUROfusion G. Colin de Verdière 30/11/2020 4 MEMORY WALL . Better bandwidth with HBM o DDR5 @ 5200 MT/s 8ch = 0.33 TB/s Thread 1 Thread Thread 2 Thread Thread 3 Thread o HBM2 @ 4 stacks = 1.64 TB/s 4 Thread Skylake: SMT2 . -

NVIDIA DGX Station the First Personal AI Supercomputer 1.0 Introduction
White Paper NVIDIA DGX Station The First Personal AI Supercomputer 1.0 Introduction.........................................................................................................2 2.0 NVIDIA DGX Station Architecture ........................................................................3 2.1 NVIDIA Tesla V100 ..........................................................................................5 2.2 Second-Generation NVIDIA NVLink™ .............................................................7 2.3 Water-Cooling System for the GPUs ...............................................................7 2.4 GPU and System Memory...............................................................................8 2.5 Other Workstation Components.....................................................................9 3.0 Multi-GPU with NVLink......................................................................................10 3.1 DGX NVLink Network Topology for Efficient Application Scaling..................10 3.2 Scaling Deep Learning Training on NVLink...................................................12 4.0 DGX Station Software Stack for Deep Learning.................................................14 4.1 NVIDIA CUDA Toolkit.....................................................................................16 4.2 NVIDIA Deep Learning SDK ...........................................................................16 4.3 Docker Engine Utility for NVIDIA GPUs.........................................................17 4.4 NVIDIA Container -
Shippensburg University Investment Management Program
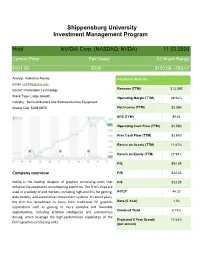
Shippensburg University Investment Management Program Hold NVIDIA Corp. (NASDAQ: NVDA) 11.03.2020 Current Price Fair Value 52 Week Range $501.36 $300 $180.68 - 589.07 Analyst: Valentina Alonso Key Stock Statistics Email: [email protected] Sector: Information Technology Revenue (TTM) $13.06B Stock Type: Large Growth Operating Margin (TTM) 28.56% Industry: Semiconductors and Semiconductors Equipment Market Cap: $309.697B Net Income (TTM) $3.39B EPS (TTM) $5.44 Operating Cash Flow (TTM) $5.58B Free Cash Flow (TTM) $3.67B Return on Assets (TTM) 11.67% Return on Equity (TTM) 27.94% P/E $92.59 Company overview P/B $22.32 Nvidia is the leading designer of graphics processing units that P/S $23.29 enhance the experience on computing platforms. The firm's chips are used in a variety of end markets, including high-end PCs for gaming, P/FCF 44.22 data centers, and automotive infotainment systems. In recent years, the firm has broadened its focus from traditional PC graphics Beta (5-Year) 1.54 applications such as gaming to more complex and favorable Dividend Yield 0.13% opportunities, including artificial intelligence and autonomous driving, which leverage the high-performance capabilities of the Projected 5 Year Growth 17.44% firm's graphics processing units. (per annum) Contents Executive Summary ....................................................................................................................................................3 Company Overview ....................................................................................................................................................4 -

The NVIDIA DGX-1 Deep Learning System
NVIDIA DGX-1 ARTIFIcIAL INTELLIGENcE SYSTEM The World’s First AI Supercomputer in a Box Get faster training, larger models, and more accurate results from deep learning with the NVIDIA® DGX-1™. This is the world’s first purpose-built system for deep learning and AI-accelerated analytics, with performance equal to 250 conventional servers. It comes fully integrated with hardware, deep learning software, development tools, and accelerated analytics applications. Immediately shorten SYSTEM SPECIFICATIONS data processing time, visualize more data, accelerate deep learning frameworks, GPUs 8x Tesla P100 and design more sophisticated neural networks. TFLOPS (GPU FP16 / 170/3 CPU FP32) Iterate and Innovate Faster GPU Memory 16 GB per GPU CPU Dual 20-core Intel® Xeon® High-performance training accelerates your productivity giving you faster insight E5-2698 v4 2.2 GHz NVIDIA CUDA® Cores 28672 and time to market. System Memory 512 GB 2133 MHz DDR4 Storage 4x 1.92 TB SSD RAID 0 NVIDIA DGX-1 Delivers 58X Faster Training Network Dual 10 GbE, 4 IB EDR Software Ubuntu Server Linux OS DGX-1 Recommended GPU NVIDIA DX-1 23 Hours, less than 1 day Driver PU-Only Server 1310 Hours (5458 Days) System Weight 134 lbs 0 10X 20X 30X 40X 50X 60X System Dimensions 866 D x 444 W x 131 H (mm) Relatve Performance (Based on Tme to Tran) Packing Dimensions 1180 D x 730 W x 284 H (mm) affe benchmark wth V-D network, tranng 128M mages wth 70 epochs | PU servers uses 2x Xeon E5-2699v4 PUs Maximum Power 3200W Requirements Operating Temperature 10 - 30°C NVIDIA DGX-1 Delivers 34X More Performance Range NVIDIA DX-1 170 TFLOPS PU-Only Server 5 TFLOPS 0 10 50 100 150 170 Performance n teraFLOPS PU s dual socket Intel Xeon E5-2699v4 170TF s half precson or FP16 DGX-1 | DATA SHEET | DEc16 computing for Infinite Opportunities NVIDIA DGX-1 Software Stack The NVIDIA DGX-1 is the first system built with DEEP LEARNING FRAMEWORKS NVIDIA Pascal™-powered Tesla® P100 accelerators. -

Manycore GPU Architectures and Programming, Part 1
Lecture 19: Manycore GPU Architectures and Programming, Part 1 Concurrent and Mul=core Programming CSE 436/536, [email protected] www.secs.oakland.edu/~yan 1 Topics (Part 2) • Parallel architectures and hardware – Parallel computer architectures – Memory hierarchy and cache coherency • Manycore GPU architectures and programming – GPUs architectures – CUDA programming – Introduc?on to offloading model in OpenMP and OpenACC • Programming on large scale systems (Chapter 6) – MPI (point to point and collec=ves) – Introduc?on to PGAS languages, UPC and Chapel • Parallel algorithms (Chapter 8,9 &10) – Dense matrix, and sorng 2 Manycore GPU Architectures and Programming: Outline • Introduc?on – GPU architectures, GPGPUs, and CUDA • GPU Execuon model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruc?on intrinsic and library • Performance, profiling, debugging, and error handling • Direc?ve-based high-level programming model – OpenACC and OpenMP 3 Computer Graphics GPU: Graphics Processing Unit 4 Graphics Processing Unit (GPU) Image: h[p://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html 5 Graphics Processing Unit (GPU) • Enriching user visual experience • Delivering energy-efficient compung • Unlocking poten?als of complex apps • Enabling Deeper scien?fic discovery 6 What is GPU Today? • It is a processor op?mized for 2D/3D graphics, video, visual compu?ng, and display. • It is highly parallel, highly multhreaded mulprocessor op?mized for visual -

Computing for the Most Demanding Users
COMPUTING FOR THE MOST DEMANDING USERS NVIDIA Artificial intelligence, the dream of computer scientists for over half a century, is no longer science fiction. And in the next few years, it will transform every industry. Soon, self-driving cars will reduce congestion and improve road safety. AI travel agents will know your preferences and arrange every detail of your family vacation. And medical instruments will read and understand patient DNA to detect and treat early signs of cancer. Where engines made us stronger and powered the first industrial revolution, AI will make us smarter and power the next. What will make this intelligent industrial revolution possible? A new computing model — GPU deep learning — that enables computers to learn from data and write software that is too complex for people to code. NVIDIA — INVENTOR OF THE GPU The GPU has proven to be unbelievably effective at solving some of the most complex problems in computer science. It started out as an engine for simulating human imagination, conjuring up the amazing virtual worlds of video games and Hollywood films. Today, NVIDIA’s GPU simulates human intelligence, running deep learning algorithms and acting as the brain of computers, robots, and self-driving cars that can perceive and understand the world. This is our life’s work — to amplify human imagination and intelligence. THE NVIDIA GPU DEFINES MODERN COMPUTER GRAPHICS Our invention of the GPU in 1999 made possible real-time programmable shading, which gives artists an infinite palette for expression. We’ve led the field of visual computing since. SIMULATING HUMAN IMAGINATION Digital artists, industrial designers, filmmakers, and broadcasters rely on NVIDIA Quadro® pro graphics to bring their imaginations to life. -

Nvidia Autonomous Driving Platform
NVIDIA AUTONOMOUS DRIVING PLATFORM Apr, 2017 Sr. Solution Architect , Marcus Oh Who is NVIDIA Deep Learning in Autonomous Driving Training Infra & Machine / DIGIT Contents DRIVE PX2 DRIVEWORKS USECASE Example Next Generation AD Platform 2 NVIDIA CONFIDENTIAL — DRIVE PX2 DEVELOPMENT PLATFORM NVIDIA Founded in 1993 | CEO & Co-founder: Jen-Hsun Huang | FY16 revenue: $5.01B | 9,500 employees | 7,300 patents | HQ in Santa Clara, CA | 3 NVIDIA — “THE AI COMPUTING COMPANY” GPU Computing Computer Graphics Artificial Intelligence 4 DEEP LEARNING IN AUTONOMOUS DRIVING 5 WHAT IS DEEP LEARNING? Input Result 6 Deep Learning Framework Forward Propagation Repeat “turtle” Tree Training Backward Propagation Cat Compute weight update to nudge Dog from “turtle” towards “dog” Trained Neural Net Model Inference “cat” 7 REINFORCEMENT LEARNING How’s it work? F A reinforcement learning agent includes: state (environment) actions (controls) reward (feedback) A value function predicts the future reward of performing actions in the current state Given the recent state, action with the maximum estimated future reward is chosen for execution For agents with complex state spaces, deep networks are used as Q-value approximator Numerical solver (gradient descent) optimizes github.com/dusty-nv/jetson-reinforcement the network on-the-fly based on reward inputs SELF-DRIVING CARS ARE AN AI CHALLENGE PERCEPTION AI PERCEPTION AI LOCALIZATION DRIVING AI DEEP LEARNING 9 NVIDIA AI SYSTEM FOR AUTONOMOUS DRIVING MAPPING KALDI LOCALIZATION DRIVENET Training on Driving with NVIDIA DGX-1 NVIDIA DRIVE PX 2 DGX-1 DriveWorks 10 TRAINING INFRA & MACHINE / DIGIT 11 170X SPEED-UP OVER COTS SERVER MICROSOFT COGNITIVE TOOLKIT SUPERCHARGED ON NVIDIA DGX-1 170x Faster (AlexNet images/sec) 13,000 78 8x Tesla P100 | 170TF FP16 | NVLink hybrid cube mesh CPU Server DGX-1 AlexNet training batch size 128, Dual Socket E5-2699v4, 44 cores CNTK 2.0b2 for CPU. -

Investigations of Various HPC Benchmarks to Determine Supercomputer Performance Efficiency and Balance
Investigations of Various HPC Benchmarks to Determine Supercomputer Performance Efficiency and Balance Wilson Lisan August 24, 2018 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2018 Abstract This dissertation project is based on participation in the Student Cluster Competition (SCC) at the International Supercomputing Conference (ISC) 2018 in Frankfurt, Germany as part of a four-member Team EPCC from The University of Edinburgh. There are two main projects which are the team-based project and a personal project. The team-based project focuses on the optimisations and tweaks of the HPL, HPCG, and HPCC benchmarks to meet the competition requirements. At the competition, Team EPCC suffered with hardware issues that shaped the cluster into an asymmetrical system with mixed hardware. Unthinkable and extreme methods were carried out to tune the performance and successfully drove the cluster back to its ideal performance. The personal project focuses on testing the SCC benchmarks to evaluate the performance efficiency and system balance at several HPC systems. HPCG fraction of peak over HPL ratio was used to determine the system performance efficiency from its peak and actual performance. It was analysed through HPCC benchmark that the fraction of peak ratio could determine the memory and network balance over the processor or GPU raw performance as well as the possibility of the memory or network bottleneck part. Contents Chapter 1 Introduction .............................................................................................. -

Fabric Manager for NVIDIA Nvswitch Systems
Fabric Manager for NVIDIA NVSwitch Systems User Guide / Virtualization / High Availability Modes DU-09883-001_v0.7 | January 2021 Document History DU-09883-001_v0.7 Version Date Authors Description of Change 0.1 Oct 25, 2019 SB Initial Beta Release 0.2 Mar 23, 2020 SB Updated error handling and bare metal mode 0.3 May 11, 2020 YL Updated Shared NVSwitch APIs section with new API information 0.4 July 7, 2020 SB Updated MIG interoperability and high availability details. 0.5 July 17, 2020 SB Updated running as non-root instructions 0.6 Aug 03, 2020 SB Updated installation instructions based on CUDA repo and updated SXid error details 0.7 Jan 26, 2021 GT, CC Updated with vGPU multitenancy virtualization mode Fabric Ma nager fo r NVI DIA NVSwitch Sy stems DU-09883-001_v0.7 | ii Table of Contents Chapter 1. Overview ...................................................................................................... 1 1.1 Introduction .............................................................................................................1 1.2 Terminology ............................................................................................................1 1.3 NVSwitch Core Software Stack .................................................................................2 1.4 What is Fabric Manager?..........................................................................................3 Chapter 2. Getting Started With Fabric Manager ...................................................... 5 2.1 Basic Components...................................................................................................5 -

Lecture: Manycore GPU Architectures and Programming, Part 1
Lecture: Manycore GPU Architectures and Programming, Part 1 CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan [email protected] https://passlab.github.io/CSCE569/ 1 Manycore GPU Architectures and Programming: Outline • Introduction – GPU architectures, GPGPUs, and CUDA • GPU Execution model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruction intrinsic and library • Performance, profiling, debugging, and error handling • Directive-based high-level programming model – OpenACC and OpenMP 2 Computer Graphics GPU: Graphics Processing Unit 3 Graphics Processing Unit (GPU) Image: http://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html 4 Graphics Processing Unit (GPU) • Enriching user visual experience • Delivering energy-efficient computing • Unlocking potentials of complex apps • Enabling Deeper scientific discovery 5 What is GPU Today? • It is a processor optimized for 2D/3D graphics, video, visual computing, and display. • It is highly parallel, highly multithreaded multiprocessor optimized for visual computing. • It provide real-time visual interaction with computed objects via graphics images, and video. • It serves as both a programmable graphics processor and a scalable parallel computing platform. – Heterogeneous systems: combine a GPU with a CPU • It is called as Many-core 6 Graphics Processing Units (GPUs): Brief History GPU Computing General-purpose computing on graphics processing units (GPGPUs) GPUs with programmable shading Nvidia GeForce GE 3 (2001) with programmable shading DirectX graphics API OpenGL graphics API Hardware-accelerated 3D graphics S3 graphics cards- single chip 2D accelerator Atari 8-bit computer IBM PC Professional Playstation text/graphics chip Graphics Controller card 1970 1980 1990 2000 2010 Source of information http://en.wikipedia.org/wiki/Graphics_Processing_Unit 7 NVIDIA Products • NVIDIA Corp. -

Cuda-Gdb Cuda Debugger
CUDA-GDB CUDA DEBUGGER DU-05227-042 _v5.0 | October 2012 User Manual TABLE OF CONTENTS Chapter 1. Introduction.........................................................................................1 1.1 What is CUDA-GDB?...................................................................................... 1 1.2 Supported Features...................................................................................... 1 1.3 About This Document.................................................................................... 2 Chapter 2. Release Notes...................................................................................... 3 Chapter 3. Getting Started.....................................................................................6 3.1 Installation Instructions..................................................................................6 3.2 Setting Up the Debugger Environment................................................................6 3.2.1 Linux...................................................................................................6 3.2.2 Mac OS X............................................................................................. 6 3.2.3 Temporary Directory................................................................................ 7 3.3 Compiling the Application...............................................................................8 3.3.1 Debug Compilation.................................................................................. 8 3.3.2 Compiling for Fermi GPUs........................................................................