GPU Architecture:Architecture: Implicationsimplications && Trendstrends
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Physx As a Middleware for Dynamic Simulations in the Container Loading Problem
Proceedings of the 2018 Winter Simulation Conference M. Rabe, A.A. Juan, N. Mustafee, A. Skoogh, S. Jain, and B. Johansson, eds. PHYSX AS A MIDDLEWARE FOR DYNAMIC SIMULATIONS IN THE CONTAINER LOADING PROBLEM Juan C. Martínez-Franco David Álvarez-Martínez Department of Mechanical Engineering Department of Industrial Engineering Universidad de Los Andes Universidad de Los Andes Carrera 1 Este No. 19A – 40 Carrera 1 Este No. 19A – 40 Bogotá, 11711, COLOMBIA Bogotá, 11711, COLOMBIA ABSTRACT The Container Loading Problem (CLP) is an optimization challenge where the constraint of dynamic stability plays a significant role. The evaluation of dynamic stability requires the use of dynamic simulations that are carried out either with dedicated simulation software that produces very small errors at the expense of simulation speed, or real-time physics engines that complete simulations in a very short time at the cost of repeatability. One such engine, PhysX, is evaluated to determine the feasibility of its integration with the open source application PackageCargo. A simulation tool based on PhysX is proposed and compared with the dynamic simulation environment of Autodesk Inventor to verify its reliability. The simulation tool presents a dynamically accurate representation of the physical phenomena experienced by cargo during transportation, making it a viable option for the evaluation of dynamic stability in solutions to the CLP. 1 INTRODUCTION The Container Loading Problem (CLP) consists of the geometric arrangement of small rectangular items (cargo) into a larger rectangular space (container), but it is not a simple geometry problem. The arrangements of cargo must maximize volume utilization while complying with certain constraints such as cargo fragility, delivery order, etc. -

Energy-Efficient VLSI Architectures for Next
UNIVERSITY OF CALIFORNIA Los Angeles Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical Engineering by Fang-Li Yuan 2014 c Copyright by Fang-Li Yuan 2014 ABSTRACT OF THE DISSERTATION Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios by Fang-Li Yuan Doctor of Philosophy in Electrical Engineering University of California, Los Angeles, 2014 Professor Dejan Markovic,´ Chair Dedicated radio hardware is no longer promising as it was in the past. Today, the support of diverse standards dictates more flexible solutions. Software-defined radio (SDR) provides the flexibility by replacing dedicated blocks (i.e. ASICs) with more general processors to adapt to various functions, standards and even allow mutable de- sign changes. However, such replacement generally incurs significant efficiency loss in circuits, hindering its feasibility for energy-constrained devices. The capability of dy- namic and blind spectrum analysis, as featured in the cognitive radio (CR) technology, makes chip implementation even more challenging. This work discusses several design techniques to achieve near-ASIC energy effi- ciency while providing the flexibility required by software-defined and cognitive radios. The algorithm-architecture co-design is used to determine domain-specific dataflow ii structures to achieve the right balance between energy efficiency and flexibility. The flexible instruction-set-architecture (ISA), the multi-scale interconnects, and the multi- core dynamic scheduling are also proposed to reduce the energy overhead. We demon- strate these concepts on two real-time blind classification chips for CR spectrum anal- ysis, as well as a 16-core processor for baseband SDR signal processing. -

Real-Time Graphics Architecture P
4/18/2007 Real-Time Graphics Architecture Lecture 4: Parallelism and Communication Kurt Akeley Pat Hanrahan http://graphics.stanford.edu/cs448-07-spring/ CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007 Topics 1. Frame buffers 2. Types of parallelism 3. Communication patterns and requirements 4. Sorting classification for parallel rendering (with examples) CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007 1 4/18/2007 Frame Buffers Raster vs. calligraphic Raster (image order) dominant choice Calligraphic (object order) Earliest choice (Sketchpad) E&S terminals in the 70s and 80s Works with light pens Scene complexity affects frame rate Monitors are expensive Still required for FAA simulation Increases absolute brightness of light points CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007 2 4/18/2007 Frame buffer definitions What is a frame buffer? What can we learn by considering different definitions? CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007 Frame buffer definition #1 Storage for commands that are executed to refresh the display Allows for raster or calligraphiccalligraphic display (e. g. Megatech) “Frame buffer” for calligraphic display is a “display list” OpenGL “render list”? Key point: frame buffer contents are interpreted Color mapping Image scaling, warping Window system (overlay, separate windows, …) Address Recalculation Pipeline CS448 Lecture 4 Kurt Akeley, Pat Hanrahan, Spring 2007 3 4/18/2007 Frame buffer definition #2 Image memory used to decouple the render frame rate from the display -

The Growing Importance of Ray Tracing Due to Gpus
NVIDIA Application Acceleration Engines advancing interactive realism & development speed July 2010 NVIDIA Application Acceleration Engines A family of highly optimized software modules, enabling software developers to supercharge applications with high performance capabilities that exploit NVIDIA GPUs. Easy to acquire, license and deploy (most being free) Valuable features and superior performance can be quickly added App’s stay pace with GPU advancements (via API abstraction) NVIDIA Application Acceleration Engines PhysX physics & dynamics engine breathing life into real-time 3D; Apex enabling 3D animators CgFX programmable shading engine enhancing realism across platforms and hardware SceniX scene management engine the basis of a real-time 3D system CompleX scene scaling engine giving a broader/faster view on massive data OptiX ray tracing engine making ray tracing ultra fast to execute and develop iray physically correct, photorealistic renderer, from mental images making photorealism easy to add and produce © 2010 Application Acceleration Engines PhysX • Streamlines the adoption of latest GPU capabilities, physics & dynamics getting cutting-edge features into applications ASAP, CgFX exploiting the full power of larger and multiple GPUs programmable shading • Gaining adoption by key ISVs in major markets: SceniX scene • Oil & Gas Statoil, Open Inventor management • Design Autodesk, Dassault Systems CompleX • Styling Autodesk, Bunkspeed, RTT, ICIDO scene scaling • Digital Content Creation Autodesk OptiX ray tracing • Medical Imaging N.I.H iray photoreal rendering © 2010 Accelerating Application Development App Example: Auto Styling App Example: Seismic Interpretation 1. Establish the Scene 1. Establish the Scene = SceniX = SceniX 2. Maximize interactive 2. Maximize data visualization quality + quad buffered stereo + CgFX + OptiX + volume rendering + ambient occlusion 3. -

NVIDIA Physx SDK EULA
NVIDIA CORPORATION NVIDIA® PHYSX® SDK END USER LICENSE AGREEMENT Welcome to the new world of reality gaming brought to you by PhysX® acceleration from NVIDIA®. NVIDIA Corporation (“NVIDIA”) is willing to license the PHYSX SDK and the accompanying documentation to you only on the condition that you accept all the terms in this License Agreement (“Agreement”). IMPORTANT: READ THE FOLLOWING TERMS AND CONDITIONS BEFORE USING THE ACCOMPANYING NVIDIA PHYSX SDK. IF YOU DO NOT AGREE TO THE TERMS OF THIS AGREEMENT, NVIDIA IS NOT WILLING TO LICENSE THE PHYSX SDK TO YOU. IF YOU DO NOT AGREE TO THESE TERMS, YOU SHALL DESTROY THIS ENTIRE PRODUCT AND PROVIDE EMAIL VERIFICATION TO [email protected] OF DELETION OF ALL COPIES OF THE ENTIRE PRODUCT. NVIDIA MAY MODIFY THE TERMS OF THIS AGREEMENT FROM TIME TO TIME. ANY USE OF THE PHYSX SDK WILL BE SUBJECT TO SUCH UPDATED TERMS. A CURRENT VERSION OF THIS AGREEMENT IS POSTED ON NVIDIA’S DEVELOPER WEBSITE: www.developer.nvidia.com/object/physx_eula.html 1. Definitions. “Licensed Platforms” means the following: - Any PC or Apple Mac computer with a NVIDIA CUDA-enabled processor executing NVIDIA PhysX; - Any PC or Apple Mac computer running NVIDIA PhysX software executing on the primary central processing unit of the PC only; - Any PC utilizing an AGEIA PhysX processor executing NVIDIA PhysX code; - Microsoft XBOX 360; - Nintendo Wii; and/or - Sony Playstation 3 “Physics Application” means a software application designed for use and fully compatible with the PhysX SDK and/or NVIDIA Graphics processor products, including but not limited to, a video game, visual simulation, movie, or other product. -

Programming Graphics Hardware Overview of the Tutorial: Afternoon
Tutorial 5 ProgrammingProgramming GraphicsGraphics HardwareHardware Randy Fernando, Mark Harris, Matthias Wloka, Cyril Zeller Overview of the Tutorial: Morning 8:30 Introduction to the Hardware Graphics Pipeline Cyril Zeller 9:30 Controlling the GPU from the CPU: the 3D API Cyril Zeller 10:15 Break 10:45 Programming the GPU: High-level Shading Languages Randy Fernando 12:00 Lunch Tutorial 5: Programming Graphics Hardware Overview of the Tutorial: Afternoon 12:00 Lunch 14:00 Optimizing the Graphics Pipeline Matthias Wloka 14:45 Advanced Rendering Techniques Matthias Wloka 15:45 Break 16:15 General-Purpose Computation Using Graphics Hardware Mark Harris 17:30 End Tutorial 5: Programming Graphics Hardware Tutorial 5: Programming Graphics Hardware IntroductionIntroduction toto thethe HardwareHardware GraphicsGraphics PipelinePipeline Cyril Zeller Overview Concepts: Real-time rendering Hardware graphics pipeline Evolution of the PC hardware graphics pipeline: 1995-1998: Texture mapping and z-buffer 1998: Multitexturing 1999-2000: Transform and lighting 2001: Programmable vertex shader 2002-2003: Programmable pixel shader 2004: Shader model 3.0 and 64-bit color support PC graphics software architecture Performance numbers Tutorial 5: Programming Graphics Hardware Real-Time Rendering Graphics hardware enables real-time rendering Real-time means display rate at more than 10 images per second 3D Scene = Image = Collection of Array of pixels 3D primitives (triangles, lines, points) Tutorial 5: Programming Graphics Hardware Hardware Graphics Pipeline -
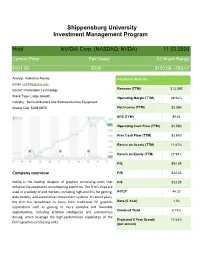
Shippensburg University Investment Management Program
Shippensburg University Investment Management Program Hold NVIDIA Corp. (NASDAQ: NVDA) 11.03.2020 Current Price Fair Value 52 Week Range $501.36 $300 $180.68 - 589.07 Analyst: Valentina Alonso Key Stock Statistics Email: [email protected] Sector: Information Technology Revenue (TTM) $13.06B Stock Type: Large Growth Operating Margin (TTM) 28.56% Industry: Semiconductors and Semiconductors Equipment Market Cap: $309.697B Net Income (TTM) $3.39B EPS (TTM) $5.44 Operating Cash Flow (TTM) $5.58B Free Cash Flow (TTM) $3.67B Return on Assets (TTM) 11.67% Return on Equity (TTM) 27.94% P/E $92.59 Company overview P/B $22.32 Nvidia is the leading designer of graphics processing units that P/S $23.29 enhance the experience on computing platforms. The firm's chips are used in a variety of end markets, including high-end PCs for gaming, P/FCF 44.22 data centers, and automotive infotainment systems. In recent years, the firm has broadened its focus from traditional PC graphics Beta (5-Year) 1.54 applications such as gaming to more complex and favorable Dividend Yield 0.13% opportunities, including artificial intelligence and autonomous driving, which leverage the high-performance capabilities of the Projected 5 Year Growth 17.44% firm's graphics processing units. (per annum) Contents Executive Summary ....................................................................................................................................................3 Company Overview ....................................................................................................................................................4 -

20 Years of Opengl
20 Years of OpenGL Kurt Akeley © Copyright Khronos Group, 2010 - Page 1 So many deprecations! • Application-generated object names • Depth texture mode • Color index mode • Texture wrap mode • SL versions 1.10 and 1.20 • Texture borders • Begin / End primitive specification • Automatic mipmap generation • Edge flags • Fixed-function fragment processing • Client vertex arrays • Alpha test • Rectangles • Accumulation buffers • Current raster position • Pixel copying • Two-sided color selection • Auxiliary color buffers • Non-sprite points • Context framebuffer size queries • Wide lines and line stipple • Evaluators • Quad and polygon primitives • Selection and feedback modes • Separate polygon draw mode • Display lists • Polygon stipple • Hints • Pixel transfer modes and operation • Attribute stacks • Pixel drawing • Unified text string • Bitmaps • Token names and queries • Legacy pixel formats © Copyright Khronos Group, 2010 - Page 2 Technology and culture © Copyright Khronos Group, 2010 - Page 3 Technology © Copyright Khronos Group, 2010 - Page 4 OpenGL is an architecture Blaauw/Brooks OpenGL SGI Indy/Indigo/InfiniteReality Different IBM 360 30/40/50/65/75 NVIDIA GeForce, ATI implementations Amdahl Radeon, … Code runs equivalently on Top-level goal Compatibility all implementations Conformance tests, … It’s an architecture, whether Carefully planned, though Intentional design it was planned or not . mistakes were made Can vary amount of No feature subsetting Configuration resource (e.g., memory) Config attributes (e.g., FB) Not a formal -

Manycore GPU Architectures and Programming, Part 1
Lecture 19: Manycore GPU Architectures and Programming, Part 1 Concurrent and Mul=core Programming CSE 436/536, [email protected] www.secs.oakland.edu/~yan 1 Topics (Part 2) • Parallel architectures and hardware – Parallel computer architectures – Memory hierarchy and cache coherency • Manycore GPU architectures and programming – GPUs architectures – CUDA programming – Introduc?on to offloading model in OpenMP and OpenACC • Programming on large scale systems (Chapter 6) – MPI (point to point and collec=ves) – Introduc?on to PGAS languages, UPC and Chapel • Parallel algorithms (Chapter 8,9 &10) – Dense matrix, and sorng 2 Manycore GPU Architectures and Programming: Outline • Introduc?on – GPU architectures, GPGPUs, and CUDA • GPU Execuon model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruc?on intrinsic and library • Performance, profiling, debugging, and error handling • Direc?ve-based high-level programming model – OpenACC and OpenMP 3 Computer Graphics GPU: Graphics Processing Unit 4 Graphics Processing Unit (GPU) Image: h[p://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html 5 Graphics Processing Unit (GPU) • Enriching user visual experience • Delivering energy-efficient compung • Unlocking poten?als of complex apps • Enabling Deeper scien?fic discovery 6 What is GPU Today? • It is a processor op?mized for 2D/3D graphics, video, visual compu?ng, and display. • It is highly parallel, highly multhreaded mulprocessor op?mized for visual -

PACKET 22 BOOKSTORE, TEXTBOOK CHAPTER Reading Graphics
A.11 GRAPHICS CARDS, Historical Perspective (edited by J Wunderlich PhD in 2020) Graphics Pipeline Evolution 3D graphics pipeline hardware evolved from the large expensive systems of the early 1980s to small workstations and then to PC accelerators in the 1990s, to $X,000 graphics cards of the 2020’s During this period, three major transitions occurred: 1. Performance-leading graphics subsystems PRICE changed from $50,000 in 1980’s down to $200 in 1990’s, then up to $X,0000 in 2020’s. 2. PERFORMANCE increased from 50 million PIXELS PER SECOND in 1980’s to 1 billion pixels per second in 1990’’s and from 100,000 VERTICES PER SECOND to 10 million vertices per second in the 1990’s. In the 2020’s performance is measured more in FRAMES PER SECOND (FPS) 3. Hardware RENDERING evolved from WIREFRAME to FILLED POLYGONS, to FULL- SCENE TEXTURE MAPPING Fixed-Function Graphics Pipelines Throughout the early evolution, graphics hardware was configurable, but not programmable by the application developer. With each generation, incremental improvements were offered. But developers were growing more sophisticated and asking for more new features than could be reasonably offered as built-in fixed functions. The NVIDIA GeForce 3, described by Lindholm, et al. [2001], took the first step toward true general shader programmability. It exposed to the application developer what had been the private internal instruction set of the floating-point vertex engine. This coincided with the release of Microsoft’s DirectX 8 and OpenGL’s vertex shader extensions. Later GPUs, at the time of DirectX 9, extended general programmability and floating point capability to the pixel fragment stage, and made texture available at the vertex stage. -

Tegra: Mobile & GPU Supercomputing Convergence | GTC 2013
Tegra – at the Convergence of Mobile and GPU Supercomputing Neil Trevett, VP Mobile Content, NVIDIA © 2012 NVIDIA - Page 1 Welcome to the Inaugural GTC Mobile Summit! Tuesday Afternoon - Room 210C Ecosystem Broad View – including Ouya Development Tools – including Tegra 4 and Shield Wednesday Morning - Marriott Ballroom 3 Visualization – including using H.264 for still imagery Augmented device interaction – including depth camera on Tegra Wednesday Afternoon - Room 210C Vision and Computational Photography – including Chimera Web – the fastest mobile browser Mobile Panel – your chance to ask gnarly questions! Select Mobile Summit Tag in your GTC Mobile App! © 2012 NVIDIA - Page 2 Why Mobile GPU Compute? State-of-the-art Augmented Reality without GPU Compute Courtesy Metaio http://www.youtube.com/watch?v=xw3M-TNOo44&feature=related © 2012 NVIDIA - Page 3 Augmented Reality with GPU Compute Research today on CUDA equipped laptop PCs How will this GPU Compute Capability migrate from high- end PCs to mobile? High-Quality Reflections, Refractions, and Caustics in Augmented Reality and their Contribution to Visual Coherence P. Kán, H. Kaufmann, Institute of Software Technology and Interactive Systems, Vienna University of Technology, Vienna, Austria © 2012 NVIDIA - Page 4 Denver CPU Mobile SOC Performance Increases Maxwell GPU FinFET Full Kepler GPU CUDA 5.0 OpenGL 4.3 100 Parker Google Nexus 7 Logan HTC One X+ 100x perf increase in Tegra 4 four years 1st Quad A15 10 Chimera Computational Photography Core i5 Tegra 3 1st Quad A9 1st Power saver 5th core Core 2 Duo Tegra 2 st CPU/GPU AGGREGATE PERFORMANCE AGGREGATE CPU/GPU 1 Dual A9 1 2012 2013 2014 2015 2011 Device Shipping Dates © 2012 NVIDIA - Page 5 Power is the New Design Limit The Process Fairy keeps bringing more transistors. -

Interactive Visualization of Large-Scale Architectural Models Over the Grid Strolling in Tang Chang’An City
Interactive Visualization of Large-Scale Architectural Models over the Grid Strolling in Tang Chang’an City XU Shuhong1, HENG Chye Kiang2, SUBRAMANIAM Ganesan1, HO Quoc Thuan1, KHOO Boon Tat1 and HUANG Yan2 1 Institute of High Performance Computing, Singapore 2 Department of Architecture, National University of Singapore Keywords: remote visualization, grid-enabled visualization, large-scale architectural models, virtual heritage Abstract: Virtual reconstruction of the ancient Chinese Chang’an city has been continued for ten years at the National University of Singapore. Motivated by sharing this grand city with people who are geographically distant and equipped with normal personal computers, this paper presents a practical Grid-enabled visualization infrastructure that is suitable for interactive visualization of large-scale architectural models. The underlying Grid services, such as information service, visualization planner and execution container etc, are developed according to the OGSA standard. To tackle the critical problem of Grid visualization, i.e. data size and network bandwidth, a multi-stage data compression approach is deployed and the corresponding data pre-processing, rendering and remote display issues are systematically addressed. 1 INTRODUCTION Chang’an, meaning long-lasting peace, was the capital of China’s Tang dynasty from 618 to 907 AD. At its peak, it had a population of about one million. Measuring 9.7 by 8.6 kilometres, the city’s architecture inspired the planning of many capital cities in East Asia such as Heijo-kyo and Heian-kyo in Japan in the 8th century, and imperial Chinese cities like Beijing of the Ming and Qing dynasties. To bring this architectural miracle back to life, a team led by Professor Heng Chye Kiang at the National University of Singapore (NUS) has conducted extensive research since the middle of 90s.