Augmented Reality on Mobile Phones Daniel Wagner Lukas Gruber Dieter Schmalstieg Graz University of Technology
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

THINC: a Virtual and Remote Display Architecture for Desktop Computing and Mobile Devices
THINC: A Virtual and Remote Display Architecture for Desktop Computing and Mobile Devices Ricardo A. Baratto Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2011 c 2011 Ricardo A. Baratto This work may be used in accordance with Creative Commons, Attribution-NonCommercial-NoDerivs License. For more information about that license, see http://creativecommons.org/licenses/by-nc-nd/3.0/. For other uses, please contact the author. ABSTRACT THINC: A Virtual and Remote Display Architecture for Desktop Computing and Mobile Devices Ricardo A. Baratto THINC is a new virtual and remote display architecture for desktop computing. It has been designed to address the limitations and performance shortcomings of existing remote display technology, and to provide a building block around which novel desktop architectures can be built. THINC is architected around the notion of a virtual display device driver, a software-only component that behaves like a traditional device driver, but instead of managing specific hardware, enables desktop input and output to be intercepted, manipulated, and redirected at will. On top of this architecture, THINC introduces a simple, low-level, device-independent representation of display changes, and a number of novel optimizations and techniques to perform efficient interception and redirection of display output. This dissertation presents the design and implementation of THINC. It also intro- duces a number of novel systems which build upon THINC's architecture to provide new and improved desktop computing services. The contributions of this dissertation are as follows: • A high performance remote display system for LAN and WAN environments. -

Wearable Mixed Reality System in Less Than 1 Pound
Eurographics Symposium on Virtual Environments (2006) Roger Hubbold and Ming Lin (Editors) Wearable Mixed Reality System In Less Than 1 Pound Achille Peternier,1 Frédéric Vexo1 and Daniel Thalmann1 1Virtual Reality Laboratory (VRLab), École Polytechnique Fédérale de Lausanne (EPFL), 1015 Lausanne, Switzerland Abstract We have designed a wearable Mixed Reality (MR) framework which allows to real-time render game-like 3D scenes on see-through head-mounted displays (see through HMDs) and to localize the user position within a known internet wireless area. Our equipment weights less than 1 Pound (0.45 Kilos). The information visualized on the mobile device could be sent on-demand from a remote server and realtime rendered onboard. We present our PDA-based platform as a valid alternative to use in wearable MR contexts under less mobility and encumbering constraints: our approach eliminates the typical backpack with a laptop, a GPS antenna and a heavy HMD usually required in this cases. A discussion about our results and user experiences with our approach using a handheld for 3D rendering is presented as well. 1. Introduction also few minutes to put on or remove the whole system. Ad- ditionally, a second person is required to help him/her in- The goal of wearable Mixed Reality is to give more infor- stalling the framework for the first time. Gleue and Daehne mation to users by mixing it with the real world in the less pointed the encumbering, even if limited, of their platform invasive way. Users need to move freely and comfortably and the need of a skilled technician for the maintenance of when wear such systems, in order to improve their expe- their system [GD01]. -

A Hybrid Client-Server Based Technique for Navigation in Large Terrains Using Mobile Devices
A Hybrid Client-Server Based Technique for Navigation in Large Terrains Using Mobile Devices Jos´eM. Noguera, Rafael J. Segura, Carlos J. Og´ayar Grupo de Gr´aficos y Geom´atica Universidad de Ja´en Robert Joan-Arinyo Grup d’Inform`atica a l’Enginyeria Universitat Polit`ecnica de Catalunya January 29, 2010 Abstract We describe a hybrid client-server technique for remote adaptive streaming and render- ing of large terrains in resource-limited mobile devices. The technique has been designed to achieve an interactive rendering performance on a mobile device connected to a low- bandwidth wireless network. The rendering workload is split between the client and the server. The terrain area close to the viewer is rendered in real-time by the client using a hierarchical multiresolution scheme. The terrain located far from the viewer is portrayed as view-dependent impostors, rendered by the server on demand and, then sent to the client. The hybrid technique provides tools to dynamically balance the rendering work- load according to the resources available at the client side and to the saturation of the network and server. A prototype has been built and an exhaustive set of experiments covering several platforms, wireless networks and a wide range of viewer velocities has been conducted. Results show that the approach is feasible, effective and robust. Keywords: Terrain navigation, Terrain rendering, Mobile computing, 3D graphics, Soft- ware Portability, Adaptive streaming. 1 Introduction Nowadays, mobile devices with computational capabilities like mobile phones and Personal Digital Assistants (PDA) are ubiquitous. Following the general framework depicted in Fig- ure 1, they are used as interactive guides to real environments, offer features such as Global Positioning Systems (GPS), access to location-based data and, visualization of maps and, terrain rendering. -

Neural Network FAQ, Part 1 of 7
Neural Network FAQ, part 1 of 7: Introduction Archive-name: ai-faq/neural-nets/part1 Last-modified: 2002-05-17 URL: ftp://ftp.sas.com/pub/neural/FAQ.html Maintainer: [email protected] (Warren S. Sarle) Copyright 1997, 1998, 1999, 2000, 2001, 2002 by Warren S. Sarle, Cary, NC, USA. --------------------------------------------------------------- Additions, corrections, or improvements are always welcome. Anybody who is willing to contribute any information, please email me; if it is relevant, I will incorporate it. The monthly posting departs around the 28th of every month. --------------------------------------------------------------- This is the first of seven parts of a monthly posting to the Usenet newsgroup comp.ai.neural-nets (as well as comp.answers and news.answers, where it should be findable at any time). Its purpose is to provide basic information for individuals who are new to the field of neural networks or who are just beginning to read this group. It will help to avoid lengthy discussion of questions that often arise for beginners. SO, PLEASE, SEARCH THIS POSTING FIRST IF YOU HAVE A QUESTION and DON'T POST ANSWERS TO FAQs: POINT THE ASKER TO THIS POSTING The latest version of the FAQ is available as a hypertext document, readable by any WWW (World Wide Web) browser such as Netscape, under the URL: ftp://ftp.sas.com/pub/neural/FAQ.html. If you are reading the version of the FAQ posted in comp.ai.neural-nets, be sure to view it with a monospace font such as Courier. If you view it with a proportional font, tables and formulas will be mangled. -

Computer Hardware and Servicing
GOVERNMENT OF TAMILNADU DIRECTORATE OF TECHNICAL EDUCATION CHENNAI – 600 025 STATE PROJECT COORDINATION UNIT Diploma in Computer Engineering Course Code: 1052 M – Scheme e-TEXTBOOK on Computer Hardware and Servicing for VI Semester Diploma in Computer Engineering Convener for Computer Engineering Discipline: Tmt.A.Ghousia Jabeen Principal TPEVR Government Polytechnic College Vellore- 632202 Team Members for Computer Hardware and Servicing: Mr. M. Suresh Babu HOD / Computer Engineering, N.P.A. Centenary Polytechnic College, Kotagiri – 643217 Mr. H.Ganesh Lecturer (SG) / Computer Engineering, N.P.A. Centenary Polytechnic College, Kotagiri – 643217 Dr. S.Sharmila HOD / IT P.S.G. Polytechnic College, Coimbatore – 641001. Validated by Dr. S. Brindha HOD/Computer Networks, PSG Polytechnic College, Coimbatore – 641001. CONTENTS Unit No. Name of the Unit Page No. 1 MOTHERBOARD COMPONENTS 1 2 MEMORY AND I/O DEVICES 33 3 DISPLAY, POWER SUPPLY AND BIOS 91 4 MAINTENANCE AND TROUBLE SHOOTING OF 114 DESKTOP & LAPTOP COMPUTERS 5 MOBILE PHONE SERVICING 178 Unit-1 Motherboard Components UNIT -1 MOTHERBOARD COMPONENTS Learning Objectives: Learner should be able to ➢ Acquire the skills of motherboard and its components ➢ Explain the basic concepts of processor. ➢ Differentiate the types of processor technology ➢ Describe the concepts of chipsets ➢ Differentiate the features of PCI,AGP, USB and processor bus Introduction: To troubleshoot the PC effectively, a student must be familiar about the components and its features. This chapter focuses the motherboard and its components. Motherboard is an important component of the PC. The architecture and the construction of the motherboard are described. This chapter deals the various types of processors and its features. -

Product Selection Guide 2008 - 2009
Product Selection Guide 2008 - 2009 Mission Visionary Computing Empowers eWorld Innovations Trusted ePlatform Services ePlatform Trusted Growth Model Segmented Business Units Powered by a Global Trusted Brand Focus & Goal The Global Leader of ePlatform Services for eWorld Solution Integrators Product Selection Guide Regional Service & Customization Centers Product Selection Guide 2008 - 2009 China Kunshan China Dongguan Taiwan Taipei Netherlands Eindhoven USA Milpitas, CA 86-512-5777-5666 86-769-8730-8088 886-2-2792-7818 31-040-267-7000 1-408-519-3800 Embedded & Industrial Computing Worldwide Offices Communications & Networking Greater China Asia Pacific Europe Americas Applied Computing China Japan Europe North America ePlatform 800-820-2280 ePlatform 0800-500-1055 Customer Care Center ePlatform 1-888-576-9668 eAutomation 800-810-0345 eAutomation 0800-500-1077 ePlatform 00800-2426-8080 eAutomation 1-800-205-7940 Medical Computing eAutomation 00800-2426-8081 Beijing 86-10-6298-4346 Tokyo 81-3-5212-5789 Cincinnati, OH 1-800-800-6889 eServices Solutions Shanghai 86-21-3360-8989 Osaka 81-6-6267-1887 Germany (Industrial Automation) 1-513-742-8895 Shenzhen 86-755-8212-4222 (European Head office) 49-89-12599-0 Irvine, CA 1-800-866-6008 eAutomation Solutions Chengdu 86-28-8545-0198 Korea 080-363-9494 49-211-97477-0 (Embedded & Industrial 1-800-557-6813 Hong Kong 852-2720-5118 Seoul 82-2-3663-9494 49-9621-9732-100 Computing) 1-949-789-7178 Milpitas, CA 1-408-519-1788 Singapore 001-800-9898-8998 France (eServices & Applied Computing) Taiwan 65-6442-1000 -

User Manual Ubiq-470 Copyright the Documentation and the Software Included with This Product Are Copyrighted 2006 by Advantech Co., Ltd
User Manual UbiQ-470 Copyright The documentation and the software included with this product are copyrighted 2006 by Advantech Co., Ltd. All rights are reserved. Advantech Co., Ltd. reserves the right to make improvements in the products described in this manual at any time without notice. No part of this manual may be reproduced, copied, translated or transmitted in any form or by any means without the prior written permission of Advantech Co., Ltd. Information provided in this manual is intended to be accurate and reliable. How- ever, Advantech Co., Ltd. assumes no responsibility for its use, nor for any infringe- ments of the rights of third parties, which may result from its use. Acknowledgements Intel and Pentium are trademarks of Intel Corporation. Microsoft Windows and MS-DOS are registered trademarks of Microsoft Corp. All other product names or trademarks are properties of their respective owners. Product Warranty (2 years) Advantech warrants to you, the original purchaser, that each of its products will be free from defects in materials and workmanship for two years from the date of pur- chase. This warranty does not apply to any products which have been repaired or altered by persons other than repair personnel authorized by Advantech, or which have been subject to misuse, abuse, accident or improper installation. Advantech assumes no liability under the terms of this warranty as a consequence of such events. Because of Advantech’s high quality-control standards and rigorous testing, most of our customers never need to use our repair service. If an Advantech product is defec- tive, it will be repaired or replaced at no charge during the warranty period. -
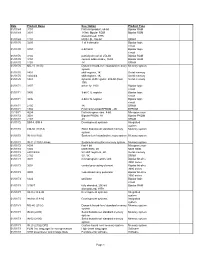
Date Product Name Description Product Type 01/01/69 3101 First
Date Product Name Description Product Type 01/01/69 3101 first Intel product, 64-bit Bipolar RAM 01/01/69 3301 1K-bit, Bipolar ROM Bipolar ROM discontinued, 1976 01/01/69 1101 MOS LSI, 256-bit SRAM 01/01/70 3205 1-of-8 decoder Bipolar logic circuit 01/01/70 3404 6-bit latch Bipolar logic circuit 01/01/70 3102 partially decoded, 256-bit Bipolar RAM 01/01/70 3104 content addressable, 16-bit Bipolar RAM 01/01/70 1103 1K DRAM 01/01/70 MU-10 (1103) Dynamic board-level standard memory Memory system system 01/01/70 1401 shift register, 1K Serial memory 01/01/70 1402/3/4 shift register, 1K Serial memory 01/01/70 1407 dynamic shift register, 200-bit (Dual Serial memory 100) 01/01/71 3207 driver for 1103 Bipolar logic circuit 01/01/71 3405 3-bit CTL register Bipolar logic circuit 01/01/71 3496 4-bit CTL register Bipolar logic circuit 01/01/71 2105 1K DRAM 01/01/71 1702 First commercial EPROM - 2K EPROM 11/15/71 4004 first microprocessor, 4-bit Microprocessor 01/01/72 3601 Bipolar PROM, 1K Bipolar PROM 01/01/72 2107 4K DRAM 01/01/72 SIM 4, SIM 8 Development systems Integrated system 01/01/72 CM-50 (1101A) Static board-level standard memory Memory system system 01/01/72 IN-10 (1103) System-level standard memory system Memory system 01/01/72 IN-11 (1103) Univac System-level custom memory system Memory system 01/01/72 8008 first 8-bit Microprocessor 01/01/72 1302 MOS ROM, 2K MOS ROM 01/01/72 2401/2/3/4 5V shift registers, 2K Serial memory 01/01/72 2102 5V, 1K SRAM 01/01/73 3001 microprogram control unit Bipolar bit-slice 3000 series 01/01/73 3002 central -

Integration of an Animated Talking Face Model in a Portable Device for Multimodal Speech Synthesis
Integration of an animated talking face model in a portable device for multimodal speech synthesis Master of Science in Speech Technology Teodor Gjermani [email protected] Supervisor: Jonas Beskow Examinator: Björn Granström Abstract Abstract Talking heads applications is not a new thing for the scientific society. In the contrary; they are used in a wide range of applications reaching web applications and the game industry as well as applications designed for special groups like hearing impaired people. The purpose of the current study, carried out at the Department of Speech, Music and Hearing, CSC, KTH, is to investigate how the MPEG based virtual talking head platform developed in the department could be integrated into a portable device to facilitate the human computer interaction for target groups, such as hearing impaired or elder people. A research evaluation on the quality of the multimodal speech synthesis produced by the model is also conducted. Abstract Sammanfattning Applikationer med virtuella talande huvuden är inte något nytt påfund. Tvärtom, de förekommer i allt från webbapplikationer och datorspel till applikationer för speciella grupper såsom hörselskadade. Avsikten med detta arbete, utfört på Tal, musik och hörsel vid skolan för datavetenskap och kommunikation, KTH, är att undersöka hur den plattform för MPEG-baserad animering av virtuella talande huvuden, som är utvecklad vid avdelningen, kan integreras i en portabel enhet för att underlätta människa- datorinteraktion exempelvis för hörselskadade eller äldre människor. En utvärdering av kvaliteten i den multimodala talsyntes som produceras av modellen har också genomförts. Acknowledgments Acknowledgments I would like to give special thanks to a number of people, without their help and support this work could never be successfully completed. -

Linux Hwmon Documentation
Linux Hwmon Documentation The kernel development community Jul 14, 2020 CONTENTS i ii CHAPTER ONE THE LINUX HARDWARE MONITORING KERNEL API Guenter Roeck 1.1 Introduction This document describes the API that can be used by hardware monitoring drivers that want to use the hardware monitoring framework. This document does not describe what a hardware monitoring (hwmon) Driver or Device is. It also does not describe the API which can be used by user space to communicate with a hardware monitoring device. If you want to know this then please read the following file: Documentation/hwmon/sysfs-interface.rst. For additional guidelines on how to write and improve hwmon drivers, please also read Documentation/hwmon/submitting-patches.rst. 1.2 The API Each hardware monitoring driver must #include <linux/hwmon.h> and, in most cases, <linux/hwmon-sysfs.h>. linux/hwmon.h declares the following regis- ter/unregister functions: struct device * hwmon_device_register_with_groups(struct device *dev, const char *name, void *drvdata, const struct attribute_group **groups); struct device * devm_hwmon_device_register_with_groups(struct device *dev, const char *name, void *drvdata, const struct attribute_group␣ ,!**groups); struct device * hwmon_device_register_with_info(struct device *dev, const char *name, void *drvdata, const struct hwmon_chip_info *info, const struct attribute_group **extra_ ,!groups); (continues on next page) 1 Linux Hwmon Documentation (continued from previous page) struct device * devm_hwmon_device_register_with_info(struct device *dev, const char *name, void *drvdata, const struct hwmon_chip_info *info, const struct attribute_group **extra_ ,!groups); void hwmon_device_unregister(struct device *dev); void devm_hwmon_device_unregister(struct device *dev); hwmon_device_register_with_groups registers a hardware monitoring device. The first parameter of this function is a pointer to the parent device. -

Covering the Spectrum of Intel Communications Products
NOTE: PLEASE ADJUST SPINE TO PROPER WIDTH The Communications and Embedded Products Source Book Source The Communications and Embedded Products The Communications Intel Corporation United States and Canada Intel Corporation Robert Noyce Building and Embedded Products 2200 Mission College Boulevard P.O. Box 58119 Santa Clara, CA 95052-8119 Source Book 2004 USA Phone: (408) 765-8080 Europe Intel Corporation (UK) Ltd. Pipers Way Swindon Wiltshire SN3 1RJ UK Phone: England (44) 1793 403 000 France (33) 1 4694 7171 Germany (49) 89 99143 0 Italy (39) 02 575 441 Israel (972) 2 589 7111 Netherlands (31) 20 659 1800 Asia Pacific Intel Semiconductor Ltd. 32/F Two Pacific Place 88 Queensway, Central Hong Kong SAR Phone: (852) 2844-4555 Japan Intel Kabushiki Kaisha P.O. Box 300-8603 Tsukuba-gakuen May 2004 5-6 Tokodai, Tsukuba-shi Ibaraki-ken 300-2635 Japan Phone: (81) 298-47-8511 South America Intel Semicondutores do Brasil Av. Dr Chucri Zaidan, 940- 10th floor Market Place Tower II 04583-906 Sao Paulo-SP-Brasil Phone: (55) 11 3365 5500 Copyright © 2004 Intel Corporation Intel, and the Intel logo are registered trademarks of Intel Corporation. * Other names and brands may be claimed as the property of others. Printed in USA/2004/10K/MD/HP Covering the spectrum Order No. 272676-012 of Intel communications products Communications and Embedded Products Source Book elcome to The Intel Communications and Embedded Products Sourcebook—2004, your Wcomplete reference guide for Intel’s Communications and Embedded products. As you look through this sourcebook, you will note that all of the sections have been updated to include the latest released products. -

SPC-101 10.4” TFT LCD Smart Panel ® ® Computer with Intel Xscale CPU ® & Windows CE.5.0 Users Manual Copyright This Document Is Copyrighted, © 2006
SPC-101 10.4” TFT LCD Smart Panel ® ® Computer with Intel Xscale CPU ® & Windows CE.5.0 Users Manual Copyright This document is copyrighted, © 2006. All rights are reserved. The original manufacturer reserves the right to make improvements to the products described in this manual at any time without notice. No part of this manual may be reproduced, copied, translated or transmitted in any form or by any means without the prior written permission of the original manufacturer. Information provided in this manual is intended to be accurate and reliable. However, the original manufacturer assumes no responsibility for its use, nor for any infringements upon the rights of third parties that may result from such use. Acknowledgements IBM, PC/AT, PS/2 and VGA are trademarks of International Business Machines Corporation. Intel® is trademark of Intel Corporation. Microsoft® Windows® CE 5.0 is a registered trademark of Microsoft Corp. All other product names or trademarks are properties of their respective owners. For more information on this and other Advantech products, please visit our websites at: http://www.advantech.com For technical support and service, please visit our support website at: http://eservice.advantech.com.tw/eservice/ This manual is for the SPC-101 series products. 1st. Edition: September 2006 FCC Class A This equipment has been tested and found to comply with the limits for a Class A digital device, pursuant to Part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference when the equipment is operated in a residential environment. This equipment generates, uses, and can radiate radio frequency energy.