A Cardiogram Exome and Multi-Ancestry UK Biobank Analysi
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

In Vivo Studies Using the Classical Mouse Diversity Panel
The Mouse Diversity Panel Predicts Clinical Drug Toxicity Risk Where Classical Models Fail Alison Harrill, Ph.D The Hamner-UNC Institute for Drug Safety Sciences 0 The Importance of Predicting Clinical Adverse Drug Reactions (ADR) Figure: Cath O’Driscoll Nature Publishing 2004 Risk ID PGx Testing 1 People Respond Differently to Drugs Pharmacogenetic Markers Identified by Genome-Wide Association Drug Adverse Drug Risk Allele Reaction (ADR) Abacavir Hypersensitivity HLA-B*5701 Flucloxacillin Hepatotoxicity Allopurinol Cutaneous ADR HLA-B*5801 Carbamazepine Stevens-Johnson HLA-B*1502 Syndrome Augmentin Hepatotoxicity DRB1*1501 Ximelagatran Hepatotoxicity DRB1*0701 Ticlopidine Hepatotoxicity HLA-A*3303 Average preclinical populations and human hepatocytes lack the diversity to detect incidence of adverse events that occur only in 1/10,000 people. Current Rodent Models of Risk Assessment The Challenge “At a time of extraordinary scientific progress, methods have hardly changed in several decades ([FDA] 2004)… Toxicologists face a major challenge in the twenty-first century. They need to embrace the new “omics” techniques and ensure that they are using the most appropriate animals if their discipline is to become a more effective tool in drug development.” -Dr. Michael Festing Quantitative geneticist Toxicol Pathol. 2010;38(5):681-90 Rodent Models as a Strategy for Hazard Characterization and Pharmacogenetics Genetically defined rodent models may provide ability to: 1. Improve preclinical prediction of drugs that carry a human safety risk 2. -

Human Transcription Factor Protein-Protein Interactions in Health and Disease
HELKA GÖÖS GÖÖS HELKA Recent Publications in this Series 45/2019 Mgbeahuruike Eunice Ego Evaluation of the Medicinal Uses and Antimicrobial Activity of Piper guineense (Schumach & Thonn) 46/2019 Suvi Koskinen AND DISEASE IN HEALTH INTERACTIONS PROTEIN-PROTEIN FACTOR HUMAN TRANSCRIPTION Near-Occlusive Atherosclerotic Carotid Artery Disease: Study with Computed Tomography Angiography 47/2019 Flavia Fontana DISSERTATIONES SCHOLAE DOCTORALIS AD SANITATEM INVESTIGANDAM Biohybrid Cloaked Nanovaccines for Cancer Immunotherapy UNIVERSITATIS HELSINKIENSIS 48/2019 Marie Mennesson Kainate Receptor Auxiliary Subunits Neto1 and Neto2 in Anxiety and Fear-Related Behaviors 49/2019 Zehua Liu Porous Silicon-Based On-Demand Nanohybrids for Biomedical Applications 50/2019 Veer Singh Marwah Strategies to Improve Standardization and Robustness of Toxicogenomics Data Analysis HELKA GÖÖS 51/2019 Iryna Hlushchenko Actin Regulation in Dendritic Spines: From Synaptic Plasticity to Animal Behavior and Human HUMAN TRANSCRIPTION FACTOR PROTEIN-PROTEIN Neurodevelopmental Disorders 52/2019 Heini Liimatta INTERACTIONS IN HEALTH AND DISEASE Efectiveness of Preventive Home Visits among Community-Dwelling Older People 53/2019 Helena Karppinen Older People´s Views Related to Their End of Life: Will-to-Live, Wellbeing and Functioning 54/2019 Jenni Laitila Elucidating Nebulin Expression and Function in Health and Disease 55/2019 Katarzyna Ciuba Regulation of Contractile Actin Structures in Non-Muscle Cells 56/2019 Sami Blom Spatial Characterisation of Prostate Cancer by Multiplex -

Supplementary Table 3 Complete List of RNA-Sequencing Analysis of Gene Expression Changed by ≥ Tenfold Between Xenograft and Cells Cultured in 10%O2
Supplementary Table 3 Complete list of RNA-Sequencing analysis of gene expression changed by ≥ tenfold between xenograft and cells cultured in 10%O2 Expr Log2 Ratio Symbol Entrez Gene Name (culture/xenograft) -7.182 PGM5 phosphoglucomutase 5 -6.883 GPBAR1 G protein-coupled bile acid receptor 1 -6.683 CPVL carboxypeptidase, vitellogenic like -6.398 MTMR9LP myotubularin related protein 9-like, pseudogene -6.131 SCN7A sodium voltage-gated channel alpha subunit 7 -6.115 POPDC2 popeye domain containing 2 -6.014 LGI1 leucine rich glioma inactivated 1 -5.86 SCN1A sodium voltage-gated channel alpha subunit 1 -5.713 C6 complement C6 -5.365 ANGPTL1 angiopoietin like 1 -5.327 TNN tenascin N -5.228 DHRS2 dehydrogenase/reductase 2 leucine rich repeat and fibronectin type III domain -5.115 LRFN2 containing 2 -5.076 FOXO6 forkhead box O6 -5.035 ETNPPL ethanolamine-phosphate phospho-lyase -4.993 MYO15A myosin XVA -4.972 IGF1 insulin like growth factor 1 -4.956 DLG2 discs large MAGUK scaffold protein 2 -4.86 SCML4 sex comb on midleg like 4 (Drosophila) Src homology 2 domain containing transforming -4.816 SHD protein D -4.764 PLP1 proteolipid protein 1 -4.764 TSPAN32 tetraspanin 32 -4.713 N4BP3 NEDD4 binding protein 3 -4.705 MYOC myocilin -4.646 CLEC3B C-type lectin domain family 3 member B -4.646 C7 complement C7 -4.62 TGM2 transglutaminase 2 -4.562 COL9A1 collagen type IX alpha 1 chain -4.55 SOSTDC1 sclerostin domain containing 1 -4.55 OGN osteoglycin -4.505 DAPL1 death associated protein like 1 -4.491 C10orf105 chromosome 10 open reading frame 105 -4.491 -

Sureselect Community Design Glasgow Cancer Panels
SureSelect Community Design Glasgow Cancer Panels Biomarkers with proven or emerging utility Genomics is a key element in precision medicine's potential to transform in predicting outcome and/or drug response/resistance - The clinical space oncology. Hybrid capture-based, targeted next-generation sequencing (NGS) represents a particularly promising technology as it enables the focused profiling of each of the many cancer-relevant loci. This approach allows for Ca rapid and cost-effective detection of most cancer-relevant genomic events, nc Cancer Core with the added advantage of FFPE tissue sample compatibility. er The Glasgow Precision Oncology Laboratory (GPOL) is a team of scientists Haem Cancer Plus with internationally recognized expertise in the technology, biology, and clinical utility of cancer genomics. Among their achievements is their detailed curation of genomic data to define the landscape of clinically and biologically significant genomic events in cancer. This includes not only a published literature review (see references 1-3), but also the International Cancer High confidence cancer genes, including those that are not currently clinically Genome Consortium (ICGC) and the Pan-Cancer Analysis of Whole Genomes actionable - The development space (PCAWG) study. Figure 1. Illustration of the GPOL cancer assay suite of panels that are commercially available as part of The GPOL has leveraged these insights to design the hybrid capture-based Agilent's Community Designs. We currently offer the SureSelect Community Design (CD) Cancer Core, Cancer SureSelect cancer NGS panels. With the SureSelect platform, the GPOL team Plus, and Cancer Haem panels. This figure illustrates the has developed a suite of affordable, fit-for-purpose cancer genomic assays relative size and content overlap of each panel. -

The Lavender Plumage Colour in Japanese Quail Is
Bed’hom et al. BMC Genomics 2012, 13:442 http://www.biomedcentral.com/1471-2164/13/442 RESEARCH ARTICLE Open Access The lavender plumage colour in Japanese quail is associated with a complex mutation in the region of MLPH that is related to differences in growth, feed consumption and body temperature Bertrand Bed’hom1, Mohsen Vaez2,5, Jean-Luc Coville1, David Gourichon3, Olivier Chastel4, Sarah Follett2, Terry Burke2 and Francis Minvielle1,6* Abstract Background: The lavender phenotype in quail is a dilution of both eumelanin and phaeomelanin in feathers that produces a blue-grey colour on a wild-type feather pattern background. It has been previously demonstrated by intergeneric hybridization that the lavender mutation in quail is homologous to the same phenotype in chicken, which is caused by a single base-pair change in exon 1 of MLPH. Results: In this study, we have shown that a mutation of MLPH is also associated with feather colour dilution in quail, but that the mutational event is extremely different. In this species, the lavender phenotype is associated with a non-lethal complex mutation involving three consecutive overlapping chromosomal changes (two inversions and one deletion) that have consequences on the genomic organization of four genes (MLPH and the neighbouring PRLH, RAB17 and LRRFIP1). The deletion of PRLH has no effect on the level of circulating prolactin. Lavender birds have lighter body weight, lower body temperature and increased feed consumption and residual feed intake than wild-type plumage quail, indicating that this complex mutation is affecting the metabolism and the regulation of homeothermy. Conclusions: An extensive overlapping chromosome rearrangement was associated with a non-pathological Mendelian trait and minor, non deleterious effects in the lavender Japanese quail which is a natural knockout for PRLH. -

A Rare Variant in MCF2L Identified Using Exclusion Linkage in A
European Journal of Human Genetics (2016) 24, 86–91 & 2016 Macmillan Publishers Limited All rights reserved 1018-4813/16 www.nature.com/ejhg ARTICLE A rare variant in MCF2L identified using exclusion linkage in a pedigree with premature atherosclerosis Stephanie Maiwald1,7, Mahdi M Motazacker1,7,8, Julian C van Capelleveen1, Suthesh Sivapalaratnam1, Allard C van der Wal2, Chris van der Loos2, John JP Kastelein1, Willem H Ouwehand3,4, G Kees Hovingh1, Mieke D Trip1,5, Jaap D van Buul6 and Geesje M Dallinga-Thie*,1 Cardiovascular disease (CVD) is a major cause of death in Western societies. CVD risk is largely genetically determined. The molecular pathology is, however, not elucidated in a large number of families suffering from CVD. We applied exclusion linkage analysis and next-generation sequencing to elucidate the molecular defect underlying premature CVD in a small pedigree, comprising two generations of which six members suffered from premature CVD. A total of three variants showed co-segregation with the disease status in the family. Two of these variants were excluded from further analysis based on the prevalence in replication cohorts, whereas a non-synonymous variant in MCF.2 Cell Line Derived Transforming Sequence-like protein (MCF2L, c.2066A4G; p.(Asp689Gly); NM_001112732.1), located in the DH domain, was only present in the studied family. MCF2L is a guanine exchange factor that potentially links pathways that signal through Rac1 and RhoA. Indeed, in HeLa cells, MCF2L689Gly failed to activate Rac1 as well as RhoA, resulting in impaired stress fiber formation. Moreover, MCF2L protein was found in human atherosclerotic lesions but not in healthy tissue segments. -

Investigation of the Underlying Hub Genes and Molexular Pathogensis in Gastric Cancer by Integrated Bioinformatic Analyses
bioRxiv preprint doi: https://doi.org/10.1101/2020.12.20.423656; this version posted December 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Investigation of the underlying hub genes and molexular pathogensis in gastric cancer by integrated bioinformatic analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2020.12.20.423656; this version posted December 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract The high mortality rate of gastric cancer (GC) is in part due to the absence of initial disclosure of its biomarkers. The recognition of important genes associated in GC is therefore recommended to advance clinical prognosis, diagnosis and and treatment outcomes. The current investigation used the microarray dataset GSE113255 RNA seq data from the Gene Expression Omnibus database to diagnose differentially expressed genes (DEGs). Pathway and gene ontology enrichment analyses were performed, and a proteinprotein interaction network, modules, target genes - miRNA regulatory network and target genes - TF regulatory network were constructed and analyzed. Finally, validation of hub genes was performed. The 1008 DEGs identified consisted of 505 up regulated genes and 503 down regulated genes. -

Role of RUNX1 in Aberrant Retinal Angiogenesis Jonathan D
Page 1 of 25 Diabetes Identification of RUNX1 as a mediator of aberrant retinal angiogenesis Short Title: Role of RUNX1 in aberrant retinal angiogenesis Jonathan D. Lam,†1 Daniel J. Oh,†1 Lindsay L. Wong,1 Dhanesh Amarnani,1 Cindy Park- Windhol,1 Angie V. Sanchez,1 Jonathan Cardona-Velez,1,2 Declan McGuone,3 Anat O. Stemmer- Rachamimov,3 Dean Eliott,4 Diane R. Bielenberg,5 Tave van Zyl,4 Lishuang Shen,1 Xiaowu Gai,6 Patricia A. D’Amore*,1,7 Leo A. Kim*,1,4 Joseph F. Arboleda-Velasquez*1 Author affiliations: 1Schepens Eye Research Institute/Massachusetts Eye and Ear, Department of Ophthalmology, Harvard Medical School, 20 Staniford St., Boston, MA 02114 2Universidad Pontificia Bolivariana, Medellin, Colombia, #68- a, Cq. 1 #68305, Medellín, Antioquia, Colombia 3C.S. Kubik Laboratory for Neuropathology, Massachusetts General Hospital, 55 Fruit St., Boston, MA 02114 4Retina Service, Massachusetts Eye and Ear Infirmary, Department of Ophthalmology, Harvard Medical School, 243 Charles St., Boston, MA 02114 5Vascular Biology Program, Boston Children’s Hospital, Department of Surgery, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115 6Center for Personalized Medicine, Children’s Hospital Los Angeles, Los Angeles, 4650 Sunset Blvd, Los Angeles, CA 90027, USA 7Department of Pathology, Harvard Medical School, 25 Shattuck St., Boston, MA 02115 Corresponding authors: Joseph F. Arboleda-Velasquez: [email protected] Ph: (617) 912-2517 Leo Kim: [email protected] Ph: (617) 912-2562 Patricia D’Amore: [email protected] Ph: (617) 912-2559 Fax: (617) 912-0128 20 Staniford St. Boston MA, 02114 † These authors contributed equally to this manuscript Word Count: 1905 Tables and Figures: 4 Diabetes Publish Ahead of Print, published online April 11, 2017 Diabetes Page 2 of 25 Abstract Proliferative diabetic retinopathy (PDR) is a common cause of blindness in the developed world’s working adult population, and affects those with type 1 and type 2 diabetes mellitus. -

Functional Receptor Molecules Cd300lf and Cd300ld Within the CD300 Family Enable Murine Noroviruses to Infect Cells
Functional receptor molecules CD300lf and CD300ld within the CD300 family enable murine noroviruses to infect cells Kei Hagaa,1, Akira Fujimotoa,1, Reiko Takai-Todakaa, Motohiro Mikia,b, Yen Hai Doana, Kosuke Murakamia, Masaru Yokoyamac, Kazuyoshi Muratad, Akira Nakanishie,2, and Kazuhiko Katayamaa,2 aDepartment of Virology II, National Institute of Infectious Diseases, Tokyo 208-0011, Japan; bNew Business Planning Division, Innovative Diagnostics Research Center, Denka Innovation Center, Denka Company Limited, Tokyo 194-8560, Japan; cPathogen Genomics Center, National Institute of Infectious Diseases, Tokyo 208-0011, Japan; dNational Institute for Physiological Sciences, Aichi 444-8585, Japan; and eSection of Gene Therapy, Department of Aging Intervention, National Center for Geriatrics and Gerontology, Aichi 474-8511, Japan Edited by Mary K. Estes, Baylor College of Medicine, Houston, Texas, and approved August 11, 2016 (received for review April 9, 2016) Norovirus is the leading cause of acute gastroenteritis worldwide. mice that were deficient in STAT1 and RAG2 (11). MNV repli- Since the discovery of human norovirus (HuNoV), an efficient and cates within the murine macrophage cell line RAW264.7 cells. reproducible norovirus replication system has not been established in MNV strains MNV-1, WU11, and S99 bind macrophages ex vivo cultured cells. Although limited amounts of virus particles can be through a terminal sialic acid on the ganglioside GD1a, which produced when the HuNoV genome is directly transfected into cells, has been suggested as a binding receptor (12). Another MNV the HuNoV cycle of infection has not been successfully reproduced in strain, CR3, binds a different glycan, and the difference in glycan any currently available cell-culture system. -

Functional Receptor Molecules Cd300lf and Cd300ld Within the CD300 Family Enable Murine Noroviruses to Infect Cells
Functional receptor molecules CD300lf and CD300ld within the CD300 family enable murine noroviruses to infect cells Kei Hagaa,1, Akira Fujimotoa,1, Reiko Takai-Todakaa, Motohiro Mikia,b, Yen Hai Doana, Kosuke Murakamia, Masaru Yokoyamac, Kazuyoshi Muratad, Akira Nakanishie,2, and Kazuhiko Katayamaa,2 aDepartment of Virology II, National Institute of Infectious Diseases, Tokyo 208-0011, Japan; bNew Business Planning Division, Innovative Diagnostics Research Center, Denka Innovation Center, Denka Company Limited, Tokyo 194-8560, Japan; cPathogen Genomics Center, National Institute of Infectious Diseases, Tokyo 208-0011, Japan; dNational Institute for Physiological Sciences, Aichi 444-8585, Japan; and eSection of Gene Therapy, Department of Aging Intervention, National Center for Geriatrics and Gerontology, Aichi 474-8511, Japan Edited by Mary K. Estes, Baylor College of Medicine, Houston, Texas, and approved August 11, 2016 (received for review April 9, 2016) Norovirus is the leading cause of acute gastroenteritis worldwide. mice that were deficient in STAT1 and RAG2 (11). MNV repli- Since the discovery of human norovirus (HuNoV), an efficient and cates within the murine macrophage cell line RAW264.7 cells. reproducible norovirus replication system has not been established in MNV strains MNV-1, WU11, and S99 bind macrophages ex vivo cultured cells. Although limited amounts of virus particles can be through a terminal sialic acid on the ganglioside GD1a, which produced when the HuNoV genome is directly transfected into cells, has been suggested as a binding receptor (12). Another MNV the HuNoV cycle of infection has not been successfully reproduced in strain, CR3, binds a different glycan, and the difference in glycan any currently available cell-culture system. -
Supplementary Figures and Tables
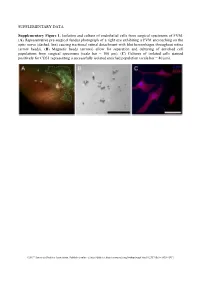
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Brain Region-Dependent Gene Networks Associated with Selective Breeding for Increased Voluntary Wheel-Running Behavior
UC Riverside UC Riverside Previously Published Works Title Brain region-dependent gene networks associated with selective breeding for increased voluntary wheel-running behavior. Permalink https://escholarship.org/uc/item/8c49g8fd Journal PloS one, 13(8) ISSN 1932-6203 Authors Zhang, Pan Rhodes, Justin S Garland, Theodore et al. Publication Date 2018 DOI 10.1371/journal.pone.0201773 Peer reviewed eScholarship.org Powered by the California Digital Library University of California RESEARCH ARTICLE Brain region-dependent gene networks associated with selective breeding for increased voluntary wheel-running behavior Pan Zhang1,2, Justin S. Rhodes3,4, Theodore Garland, Jr.5, Sam D. Perez3, Bruce R. Southey2, Sandra L. Rodriguez-Zas2,6,7* 1 Illinois Informatics Institute, University of Illinois at Urbana-Champaign, Urbana, IL, United States of America, 2 Department of Animal Sciences, University of Illinois at Urbana-Champaign, Urbana, IL, United a1111111111 States of America, 3 Beckman Institute for Advanced Science and Technology, Urbana, IL, United States of a1111111111 America, 4 Center for Nutrition, Learning and Memory, University of Illinois at Urbana-Champaign, Urbana, a1111111111 IL, United States of America, 5 Department of Evolution, Ecology, and Organismal Biology, University of a1111111111 California, Riverside, CA, United States of America, 6 Department of Statistics, University of Illinois at Urbana-Champaign, Urbana, IL, United States of America, 7 Carle Woese Institute for Genomic Biology, a1111111111 University of Illinois at Urbana-Champaign, Urbana, IL, United States of America * [email protected] OPEN ACCESS Abstract Citation: Zhang P, Rhodes JS, Garland T, Jr., Perez SD, Southey BR, Rodriguez-Zas SL (2018) Brain Mouse lines selectively bred for high voluntary wheel-running behavior are helpful models region-dependent gene networks associated with for uncovering gene networks associated with increased motivation for physical activity and selective breeding for increased voluntary wheel- other reward-dependent behaviors.