With Pigeon Algorithm
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On-Page SEO Strategy Guide How to Optimise and Improve Your Content’S Ranking Table of Contents
On-Page SEO Strategy Guide How To Optimise And Improve Your Content’s Ranking Table of Contents 01 / Introduction ............................................................................................................ 3 02 / History of SEO ........................................................................................................ 4 03 / How To Get Started With On-Page SEO .............................................................. 7 04 / Topic Clusters Site Architecture ............................................................................ 15 05 / Analyse Results ....................................................................................................... 22 06 / Conclusion .............................................................................................................. 23 ON-PAGE SEO STRATEGY GUIDE 2 01 / Introduction The last few years have been especially exciting in the SEO industry with a series of algorithm updates and search engine optimisation developments escalating in increased pace. Keeping up with all of these changes can be difficult, but proving return on investment can be even harder. The world of SEO is changing. This ebook provides you with a brief history of the SEO landscape, introduces strategies for on- and off-page SEO, and shares reporting tactics that will allow you to track your efforts and identify their return. ON-PAGE SEO STRATEGY GUIDE 3 02 / History of SEO Search engines are constantly improving the search experience and therefore SEO is in a nonstop transformation. -

DESIGN to DISRUPT New Digital Competition
DESIGN TO DISRUPT New digital competition Jaap Bloem, Menno van Doorn, Sander Duivestein, Thomas van Manen, Erik van Ommeren About VINT labs.sogeti.com/vint About SogetiLabs labs.sogeti.com VINT, the Sogeti trend lab and part of SogetiLabs, provides a SogetiLabs is a network of over 90 technology leaders from meaningful interpretation of the connection between busi- Sogeti worldwide. SogetiLabs covers a wide range of digital ness processes and new developments. In every VINT publi- technology expertise: from embedded software, cyber secu- cation, a balance is struck between factual description and rity, simulation, and cloud to business information managem the intended utilization. VINT uses this approach to inspire ent, mobile apps, analytics, testing, and the Internet of organizations to consider and use new technology. Things. The focus is always on leveraging technologies, systems and applications in actual business situations to maximize results. Together with the Sogeti trend lab VINT, SogetiLabs provides insight, research, and inspiration through articles, presentations, and videos that can be downloaded via the extensive SogetiLabs presence on its website, online portals, and social media. Want to participate in our Design to Disrupt About Sogeti www.sogeti.com research project? Please send Sogeti is a leading provider of technology and software testing, specializing an e-mail to in Application, Infrastructure and Engineering Services. Sogeti offers cutting- edge solutions around Testing, Business Intelligence & Analytics, Mobile, [email protected] Cloud and Cyber Security, combining world class methodologies and its global delivery model, Rightshore®. Sogeti brings together more than 20,000 professionals in 15 countries and has a strong local presence in over 100 locations in Europe, USA and India. -

Universidad Nacional Del Altiplano Escuela De Posgrado Doctorado En Ciencias De La Computación
UNIVERSIDAD NACIONAL DEL ALTIPLANO ESCUELA DE POSGRADO DOCTORADO EN CIENCIAS DE LA COMPUTACIÓN TESIS MODELO DE ESTRATEGIAS DIGITALES EN EL DISEÑO DE UN MUSEO VIRTUAL PARA LA PRESERVACIÓN DEL PATRIMONIO CULTURAL PRESENTADA POR: HESMERALDA ROJAS ENRIQUEZ PARA OPTAR EL GRADO ACADÉMICO DE: DOCTORIS SCIENTIAE EN CIENCIAS DE LA COMPUTACIÓN PUNO, PERÚ 2020 DEDICATORIA Ahí donde mi corazón está, a mis hijos Diego, Angiolina y Maurizio y a ti, Ronald. A mi familia, que siempre me alienta a proseguir y en especial a mi madre Estela, con cariño. i AGRADECIMIENTOS • A la Escuela de Posgrado de la Universidad Nacional del Altiplano de Puno, por su formación y especialización en el área, y a la parte administrativa que gratamente me sorprendió con un servicio eficiente. • Al Dr. Vladimiro Ibáñez Quispe, por brindar un asesoramiento idóneo, continuo y profesional y su apoyo permanente. • A la Dirección Desconcentrada de Cultura Apurímac, por tener la visión de ampliar su horizonte en el espectro digital, permitiendo que el Museo Arqueológico y Antropológico de Apurímac tenga presencia en medios digitales y por su apoyo en la realización de esta tesis. A su directora Lic. Mérica Inca Paullo, Lic. Fritz Navedo Mosqueira, Arq. Angela Condori Pachecho, Arqueol. Edilberto Saul Contreras Huamán, Arqueol. Darwin Eduardo Villilli Vargas, Arqueol. Edwin Guerreros Ccorahua, Lic. Miriam Ojeda Cuaresma y Lic. Lidia Mendivil Merino. ii ÍNDICE GENERAL Pág. DEDICATORIA i AGRADECIMIENTOS ii ÍNDICE GENERAL iii ÍNDICE DE TABLAS vi ÍNDICE DE FIGURAS vii ÍNDICE DE ANEXOS x RESUMEN xi ABSTRACT xii INTRODUCCIÓN 1 CAPÍTULO I REVISIÓN DE LITERATURA 1.1 Contexto y marco teórico 2 1.1.1 Estrategia 2 1.1.2 Estrategia digital 3 1.1.3 Museo virtual 5 1.1.4 Internet, tecnologías de información y conservación del patrimonio cultural 9 1.1.5 Accesibilidad 10 1.1.6 Accesibilidad web 10 1.1.7 Iniciativa de Accesibilidad Web (WAI) 11 1.1.8 Aplicaciones de internet enriquecidas accesibles (WAI-ARIA) 12 1.1.9 Márketing digital 13 1.1.10 Digital Content Marketing (DCM) 13 1.1.11 Search Engine Optimization (SEO). -

OTT Streaming Wars: Raise Or Fold
OTT Streaming Wars: Raise or Fold How Data is Reshuffling the Cards of the M&E Industry Content 01 02 03 OTT Streaming Media Players Efficient Data Use Shakes-up the Need Data Increases M&E Industry Integration for Competitivity Survival OTT is fast becoming the main The core business of media and In fact, 67% of all interviewees form of content consumption entertainment companies is declared data to be business now challenged critical for survival Multiplication of services drives fragmentation Content is King, but DATA Data as key lever for OTT business emerges as key sucess factor Streaming Wars’ players race for subscribers Advertising-based model accelerates the industry's entry into a new era Consolidation and new opportunities for aggregators 2 OTT Streaming Wars 04 05 06 Two Out of Three Best Practices of Conclusion: Players Reach Leaders Help Raise the Only Basic Levels Overcome Maturity Stakes or Fold of Data Maturity Challenges Fully leveraging the power of data Decide to set data at the core The direction is set towards requires work on multiple streams of the strategy across the full a Data-powered Media & at the same time CxO suite Entertainment Industry Despite data being business Build an environment of trust and Acceleration is required to critical, two out of three media integrate it in the brand promise stay relevant and attractive for and entertainment companies subscribers, content providers reach only a basic level of Address users not audiences or advertisers data-maturity. Work on culture and skill sets to Becoming -

Local-Search-Marketi
“Local SEO Uncovered: The Secrets Every Law Firm Must Know To LEGALLY STEAL Floods of FREE Google Traffic From Your Competition!” Sponsored by Presented by We make law firms grow. Ask us how. Agenda . About BusinessCreator, Inc. and me . About the Power Practice Builder Webinar Series . Topics . Goals . Definitions . The New Local Landscape . How To Get Your Phone To Ring About BusinessCreator, Inc. BusinessCreator is a full-service local search, lead generation and mobile marketing agency specializing in innovative and engaging local and mobile programs, promotions and campaigns. Our goal is to increase your online presence and convert your website traffic into new clients. Holistic approach to local search marketing About BusinessCreator, Inc. Holistic approach to local search marketing: . Local Search Marketing and LSEO . Citation and Directory Building . Lead Generation Platform-All In One Marketing Solution . Live Attorney Leads GUARANTEED Quality Calls . Reputation Marketing-5 Star Reputation Program About BusinessCreator, Inc. Holistic approach to local search marketing: . WebCreatorPlus Custom Rent-To-Own Websites . Lead Generation Websites . Website and Online Marketing Audits . Social Media Marketing (SMM) . Video Marketing-production, SEO, syndication . PPC . Retargeting About BusinessCreator, Inc. Holistic approach to local search marketing: . Mobile Websites . iseekLaw Mobile App Directory . iseekLaw Mobile Website Directory . Mobile Apps . Mobile Marketing . Mobile Display Advertising-NearYou Mobile Marketing . Consumer Financing For Legal Services . Me Power Practice Builder Webinar Series Webinar Topics-found on www.forlawfirmsonly.com 1. Local Search Marketing for Law Firms 2. Why Are So Many Businesses Struggling With Mobile Marketing? 3. Mobile App Marketing For Law Firms-Daniel Rosemark, Esq. 4. Lead Generation-Live Attorney Leads Program, PPC, Retargeting 5. -

Serverless Machine Learning with Tensorflow
Proprietary + Confidential Serverless Machine Learning with Tensorflow Vijay Reddy ©Google Inc. or its affiliates. All rights reserved. Do not distribute. May only be taught by Google Cloud Platform Authorized Trainers. Beginning of Day Logistics ● Qwiklabs Setup ○ Sign up for account ○ Provide us e-mail you signed up with ● Datalab Setup © 2017 Google Inc. All rights reserved. Google and the Google logo are trademarks of Google Inc. All other company and product names may be trademarks of the respective companies with which they are associated. Agenda ● 9-10:30 (90 min) ○ Qwiklabs Setup ○ Lab 1: Explore dataset, create ML datasets, create benchmark ○ Lab 2: Getting Started with TensorFlow ● 10:30-11:00 (30 min) ○ Break (use the break to catch up if you’re behind) ● 11:00-12:30 (90 min) ○ Lab 3: Machine Learning using tf.estimator ○ Lab 4: Refactoring to add batching and feature-creation ● 12:30-1:30 (60 min) ○ Lunch ● 1:30-3:00 (90 min) ○ Lab 5: Distributed training and monitoring ○ Lab 6: Scaling up ML using Cloud ML Engine ● 3:00-3:30 (30 min) ○ Break ● 3:30-5:00 (90 min) ○ Lab 7: Feature Engineering ○ Wrap Up + Questions © 2017 Google Inc. All rights reserved. Google and the Google logo are trademarks of Google Inc. All other company and product names may be trademarks of the respective companies with which they are associated. Beginning ML Pipeline Train Inputs model Model © 2017 Google Inc. All rights reserved. Google and the Google logo are trademarks of Google Inc. All other company and product names may be trademarks of the respective companies with which they are associated. -
Book Title Author Reading Level Approx. Grade Level
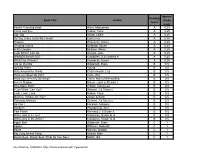
Approx. Reading Book Title Author Grade Level Level Anno's Counting Book Anno, Mitsumasa A 0.25 Count and See Hoban, Tana A 0.25 Dig, Dig Wood, Leslie A 0.25 Do You Want To Be My Friend? Carle, Eric A 0.25 Flowers Hoenecke, Karen A 0.25 Growing Colors McMillan, Bruce A 0.25 In My Garden McLean, Moria A 0.25 Look What I Can Do Aruego, Jose A 0.25 What Do Insects Do? Canizares, S.& Chanko,P A 0.25 What Has Wheels? Hoenecke, Karen A 0.25 Cat on the Mat Wildsmith, Brain B 0.5 Getting There Young B 0.5 Hats Around the World Charlesworth, Liza B 0.5 Have you Seen My Cat? Carle, Eric B 0.5 Have you seen my Duckling? Tafuri, Nancy/Greenwillow B 0.5 Here's Skipper Salem, Llynn & Stewart,J B 0.5 How Many Fish? Cohen, Caron Lee B 0.5 I Can Write, Can You? Stewart, J & Salem,L B 0.5 Look, Look, Look Hoban, Tana B 0.5 Mommy, Where are You? Ziefert & Boon B 0.5 Runaway Monkey Stewart, J & Salem,L B 0.5 So Can I Facklam, Margery B 0.5 Sunburn Prokopchak, Ann B 0.5 Two Points Kennedy,J. & Eaton,A B 0.5 Who Lives in a Tree? Canizares, Susan et al B 0.5 Who Lives in the Arctic? Canizares, Susan et al B 0.5 Apple Bird Wildsmith, Brain C 1 Apples Williams, Deborah C 1 Bears Kalman, Bobbie C 1 Big Long Animal Song Artwell, Mike C 1 Brown Bear, Brown Bear What Do You See? Martin, Bill C 1 Found online, 7/20/2012, http://home.comcast.net/~ngiansante/ Approx. -

Keyword Research Tools & Services 3 7
ClickMinded.com Search Engine Optimization Course Environment Setup CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use Google Chrome ● Faster ● Great plugins ● Developer tools ● Generally better for digital marketers CLICKMINDED DIGITAL MARKETING CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use Keyword Everywhere ● Adds keyword volume below search bar ● Great way to accidentally find monster opportunities CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use SEOQuake ● Chrome extension that overlays SEO data on results ● Size up competitive opportunities quickly CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use LinkClump ● Chrome extension that opens multiple links at once ● Good for lots of different uses CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use User-Agent Switcher ● Chrome extension that will let you change your user agent ● Easily view pages as different browsers and devices CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use Link Grabber ● Chrome extension that will let you grab all the links on a page ● Easily copy/paste all the links on a page in a new tab CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use Google Tag Assistant ● Chrome extension that shows if Google tags are working ● Absolutely vital! CLICKMINDED DIGITAL MARKETING Environment Setup Getting Started Use Redirect Path ● Chrome extension that shows you the redirect path and response codes on a page ● Identify bad response codes quickly like -

Efficient Dictionary Compression for Processing RDF Big Data Using
Efficient Dictionary Compression for Processing RDF Big Data Using Google BigQuery Omer Dawelbeit Rachel McCrindle School of Systems Engineering, School of Systems Engineering, University of Reading, University of Reading, United Kingdom. United Kingdom. Email: [email protected] Email: [email protected] Abstract—The Resource Description Framework (RDF) data RDF triples can be exchanged in a number of formats, model, is used on the Web to express billions of structured primarily RDF/XML which is based on XML documents. statements in a wide range of topics, including government, Other formats include line based, plain text encoding of RDF publications, life sciences, etc. Consequently, processing and storing this data requires the provision of high specification statements such as N-Triples [2]. An example of an RDF systems, both in terms of storage and computational capabilities. statement in N-Triple format is shown in Fig 1. On the other hand, cloud-based big data services such as When dealing with large datasets, URIs occupy many bytes Google BigQuery can be used to store and query this data and take a large amount of storage space, which is particularly without any upfront investment. Google BigQuery pricing is true with datasets in N-Triple format that have long URIs. Ad- based on the size of the data being stored or queried, but given that RDF statements contain long Uniform Resource Identifiers ditionally, there is increased network latencies when transfer- (URIs), the cost of query and storage of RDF big data can ring such data over the network. -

Google's 9 Major Algorithm Updates & Penalties
Google’s 9 Major Algorithm Updates & Penalties Your ultimate guide to understanding Google updates and their impact on rankings Google’s 9 Major Algorithm Updates & Penalties Introduction Google rolls out algorithm updates once or twice every month (and that’s just the ones we know about!), but not all of them have an equally strong impact on the SERPs. To help you make sense of Google’s major algo changes in the past years, I’ve put up a cheat sheet with the most important updates and penalties rolled out in the recent years, along with a list of hazards and prevention tips for each. But before we start, let’s have a quick look to check whether any given update has impacted your own site’s traffic.SEO PowerSuite’s Rank Tracker is a massive help in this; the tool will automatically match up dates of all major Google updates to your traffic and ranking graphs. Launch Rank Tracker (if you don’t have it installed, get SEO PowerSuite’s free version here) and create a project for your site by entering its URL and specifying your target keywords. Click the Update visits button in Rank Tracker’s top menu, and enter your Google Analytics credentials to sync your account with the tool. In the lower part of your Rank Tracker dashboard, switch to the Organic Traffic tab. The dotted lines over your graph mark the dates of major Google algo updates. Examine the graph to see if any drops (or spikes!) in visits correlate with the updates. Hover your mouse over any of the lines to see what the update was. -

Ef Cient Dictionary Compression for Fi Processing RDF Big Data Using
Effi cient dictionary compression for processing RDF big data using Google BigQuery Conference or Workshop Item Accepted Version Dawelbeit, O. and McCrindle, R. (2017) Effi cient dictionary compression for processing RDF big data using Google BigQuery. In: IEEE GLOBECOM 2016, December 4-8th 2016, Washington DC. Available at http://centaur.reading.ac.uk/69737/ It is advisable to refer to the publisher’s version if you intend to cite from the work. See Guidance on citing . Published version at: http://doi.org/10.1109/GLOCOM.2016.7841775 All outputs in CentAUR are protected by Intellectual Property Rights law, including copyright law. Copyright and IPR is retained by the creators or other copyright holders. Terms and conditions for use of this material are defined in the End User Agreement . www.reading.ac.uk/centaur CentAUR Central Archive at the University of Reading Reading’s research outputs online Efficient Dictionary Compression for Processing RDF Big Data Using Google BigQuery Omer Dawelbeit Rachel McCrindle School of Systems Engineering, School of Systems Engineering, University of Reading, University of Reading, United Kingdom. United Kingdom. Email: [email protected] Email: [email protected] Abstract—The Resource Description Framework (RDF) data RDF triples can be exchanged in a number of formats, model, is used on the Web to express billions of structured primarily RDF/XML which is based on XML documents. statements in a wide range of topics, including government, Other formats include line based, plain text encoding of RDF publications, life sciences, etc. Consequently, processing and storing this data requires the provision of high specification statements such as N-Triples [2]. -

6 the Technology Behind Google's Great Results
6 The Technology Behind Google’s Great Results Google Inc. Among modern lawyers, Google has joined Westlaw and Lexis as an essential research tool. Why? The essay reproduced here, which originally appeared on the Internet on April , 2002, offers one set of answers. We have made no chang- es, except to add the byline and author note, replace hotlinks with footnotes, and alter font and format to fit the Green Bag’s style. – The Editors S A GOOGLE USER, you’re familiar faster than human editors or machine-based with the speed and accuracy of a algorithms. And while Google has dozens of Google search. How exactly does engineers working to improve every aspect Google manage to find the right results for of our service on a daily basis, PigeonRank Aevery query as quickly as it does? The heart continues to provide the basis for all of our of Google’s search technology is Pigeon- web search tools. Rank™, a system for ranking web pages de- veloped by Google founders Larry Page¹ and Why Google’s patented Sergey Brin² at Stanford University. PigeonRank™ works so well Building upon the breakthrough work of B.F. Skinner,³ Page and Brin reasoned that PigeonRank’s success relies primarily on the low cost pigeon clusters (PCs) could be used superior trainability of the domestic pigeon to compute the relative value of web pages (Columba livia) and its unique capacity to Google is a public and profitable company focused on search services. Named for the mathematical term “googol,” Google operates web sites at many international domains, with the most trafficked being www.google.