Journal of Linguistic Geography (JLG)
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Lithofacies Palaeogeography of the Late Permian Wujiaping Age in the Middle and Upper Yangtze Region, China
Journal of Palaeogeography 2014, 3(4): 384-409 DOI: 10.3724/SP.J.1261.2014.00063 Lithofacies palaeogeography and sedimentology Lithofacies palaeogeography of the Late Permian Wujiaping Age in the Middle and Upper Yangtze Region, China Jin-Xiong Luo*, You-Bin He, Rui Wang School of Geosciences, Yangtze University, Wuhan 430100, China Abstract The lithofacies palaeogeography of the Late Permian Wujiaping Age in Middle and Upper Yangtze Region was studied based on petrography and the “single factor analysis and multifactor comprehensive mapping” method. The Upper Permian Wujiaping Stage in the Middle and Upper Yangtze Region is mainly composed of carbonate rocks and clastic rocks, with lesser amounts of siliceous rocks, pyroclastic rocks, volcanic rocks and coal. The rocks can be divided into three types, including clastic rock, clastic rock-limestone and lime- stone-siliceous rock, and four fundamental ecological types and four fossil assemblages are recognized in the Wujiaping Stage. Based on a petrological and palaeoecological study, six single factors were selected, namely, thickness (m), content (%) of marine rocks, content (%) of shallow water carbonate rocks, content (%) of biograins with limemud, content (%) of thin- bedded siliceous rocks and content (%) of deep water sedimentary rocks. Six single factors maps of the Wujiaping Stage and one lithofacies palaeogeography map of the Wujiaping Age were composed. Palaeogeographic units from west to east include an eroded area, an alluvial plain, a clastic rock platform, a carbonate rock platform where biocrowds developed, a slope and a basin. In addition, a clastic rock platform exists in the southeast of the study area. Hydro- carbon source rock and reservoir conditions were preliminarily analyzed based on lithofacies palaeogeography. -

Modelling Diasystemic Inflexion: Verb Morphology in the Croissant
Modelling diasystemic inflexion: Verb morphology in the Croissant linguistique Maximilien Guérin Louise Esher Jean Léo Léonard Sylvain Loiseau CNRS – LLACAN CNRS - CLLE-ERSS Université Montpellier 3 Université Paris 13 (UMR 8135) (UMR 5263) & Dipralang (EA 739) & LACITO (UMR 7107) 1 Introduction Our paper explores how tools developed for the formal modelling of individual inflexional systems may be fruitfully applied to the description of inflexion in a dialect continuum or DIASYSTEM. We take as our case study the area of central France termed the CROISSANT LINGUISTIQUE (literally, ‘Linguistic Crescent’; Tourtoulon & Bringuier 1876, Brun-Trigaud 1990), usually characterized as a transitional zone between northern Gallo-Romance (Oïl) varieties and southern Gallo-Romance (Occitan) varieties. For each of six survey points within the Croissant area, and a seventh, Occitan, survey point as a comparator, we analyse the inflexional morphology of the verb, using two principal formalizations: PARADIGM FUNCTION MORPHOLOGY (Stump 2001, 2016, Stump & Finkel 2013, Bonami & Stump 2016) and STEM SPACES (Bonami & Boyé 2002, 2003, 2014, Boyé 2011). By these means, we obtain schemas highlighting the key principles of paradigm organization in each individual variety. Comparison of the schemas reveals structural continuities and discontinuities within the Croissant dialect continuum itself, and between the Croissant dialect continuum and neighbouring varieties. 2 Data Seven localities, shown in Figure 1, were chosen to represent the study area: Dompierre-les- -

"Atlas Lingüístico-Etnográfico De Andalucía"
A C0;IIPARISCN OF FNE ANWSIAN VARIETIES BASED ON THE; IIATw LINGC is TIC o-ETNCGR~FICo DE AI~ALUc kt by Jutta Peucker A T'rES IS SUBMITTE;D XI1 PARTIAL FULFILUfiNT OF THE RE;QUIRE;tfl3E;MTS FOR THE DEGREE OF MASTER OF ASTS in the Department of Modem Languages @ Jutta Peucker 1971 S DION FRASER UNNE'ItS ITY July 1971 APPROVAL Name : Jutta Peucker Degree : Master of Arts Title of Thesis: A comparison of five Andalusian varieties based on the "Atlas Lingiifstico-Etnogrbfico de Andalucia" Examining Committee: Chairman : J . Wahlgren T. W. Kim. Senior Supervisor H. Hammerly P. Wagner Date Approved :w ii. AES TRACT The thesis is an investigation of the"~t1as~ing;'<stico - EknogrLfico de Andalucla/* by 14anuel Alvar and co-authors. The main objective of the study is the comparison of several dialects on the basis of a diasystem. For this purpose five varieties were chosen, four of them spoken in a restricted region of Andalucl/s and the fifth in the extreme eastern corner of the province. The system of partial dissimilarities was discussed on the basis of 4 tables of correspondences which led to questions of interdialectal communication. Inferences were made from the tables as to when communi- cation problems might arise between speakers of different varieties of Andaluc<a. The latter inferences should be tested in primary research. iii. I wish to thank at this point my graduate advisors, especially Dr. T.W. Kim,for assistance in the production of my thesis. I would also like to thank Miss Jill Brady and Mr. -

Do You Speak Chinese, Mandarin, Or Cantonese? an Explanation Based on a Native Chinese Speaker’S Early Experience
The Morning Watch: Educational and Social Analysis Vol 46. No 1-2, Fall (2018) Do You Speak Chinese, Mandarin, or Cantonese? An Explanation Based on a Native Chinese Speaker’s Early Experience Cheng Li Yunnan Normal University, China [email protected] Abstract This article reports on my early experiences with learning and speaking varieties of Chinese, responding to the curious questions on the power relationship between Mandarin and other dialects in China today. A series of important life events and experiences are presented and discussed with regard to the historical and cultural context within which I learned Mandarin, Cantonese and other dialects at an early age. I argue that different varieties of Chinese are not only integral to Chinese history and culture, but also constituent of my identity as a native Chinese speaker. This study emphasizes that the dominance of Mandarin in contemporary China needs to be discussed under the umbrella of Chinese civilization and in consideration of rural- urban migrants’ benefits. Keywords: Native Chinese speaker; Mandarin; Cantonese; language policy; dialect As a native Chinese speaker , I was asked many curious questions on the language(s) spoken in China during the years I lived in St. John’s, Canada as an international Ph.D. student. The most frequently received questions concerned Chinese, Mandarin, and Cantonese. “Do you speak Chinese, Mandarin or Cantonese?”, “Is the Chinese class in your school, in fact, a Mandarin class?” “Do the Cantonese people in Chinatown speak Cantonese or Chinese?” I was shocked when I first received these questions since my Canadian friends knew more about varieties of Chinese than I had expected. -

Livret Des Résumés Booklet of Abstracts
34èmes Journées de Linguistique d’Asie Orientale JLAO34 34th Paris Meeting on East Asian Linguistics 7–9 juillet 2021 / July, 7th–9th 2021 Colloque en ligne / Online Conference LIVRET DES RÉSUMÉS BOOKLET OF ABSTRACTS Comité d’organisation/Organizing committee Raoul BLIN, Ludovica LENA, Xin LI, Lin XIAO [email protected] *** Table des matières / Table of contents *** Van Hiep NGUYEN (Keynote speaker): On the study of grammar in Vietnam Julien ANTUNES: Description et analyse de l’accent des composés de type NOM-GENITIF-NOM en japonais moderne Giorgio Francesco ARCODIA: On ‘structural particles’ in Sinitic languages: typology and diachrony Huba BARTOS: Mandarin Chinese post-nuclear glides under -er suffixation Bianca BASCIANO: Degree achievements in Mandarin Chinese: A comparison between 加 jiā+ADJ and 弄 nòng+ADJ verbs Etienne BAUDEL: Chinese and Sino-Japanese lexical items in the Hachijō language of Japan Françoise BOTTERO: Xu Shen’s graphic analysis revisited Tsan Tsai CHAN: Cartographic fieldwork on sentence-final particles – Three challenges and some ways around them Hanzhu CHEN & Meng CHENG: Corrélation entre l’absence d’article et la divergence lexicale Shunting CHEN, Yiming LIANG & Pascal AMSILI: Chinese Inter-clausal Anaphora in Conditionals: A Linear Regression Study Zhuo CHEN: Differentiating two types of Mandarin unconditionals: Their internal and external syntax Katia CHIRKOVA: Aspect, Evidentiality, and Modality in Shuhi Anastasia DURYMANOVA: Nouns and verbs’ syntactic shift: some evidences against Old Chinese parts-of- speech -

Besluit Van Het College Van Burgemeester En Wethouders Van
Nr. 264601 31 oktober GEMEENTEBLAD 2019 Officiële uitgave van de gemeente Waadhoeke Besluit van het college van burgemeester en wethouders van de gemeente Waadhoeke houdende regels omtrent de afvalstoffenverordening (Uitvoeringsbesluit Afvalstoffenverordening gemeente Waadhoeke) Burgemeester en wethouders van de gemeente Waadhoeke overwegende; dat de Afvalstoffenverordening gemeente Waadhoeke 2018 de aanwijzing van de inzameldienst en andere inzamelaars, het gebruik van inzamelmiddelen en –voorzieningen en plaats en wijze van inzameling overlaat aan een regeling bij uitvoeringsbesluit; dat het in het belang van een doelmatige verwijdering van afvalstoffen wenselijk is nadere regels te stellen omtrent plaats en wijze waarop afvalstoffen kunnen worden overgedragen of ter inzameling aangeboden aan de bij dit besluit aan te wijzen inzameldienst en andere inzamelaars, als bedoeld in de Afvalstoffenverordening gemeente Waadhoeke 2018; gelet op het bepaalde in artikel 3, lid 1, artikel 4, lid 1a, artikel 5, artikel 7, lid 1, artikel 9 en artikel 10, lid 1 van de Afvalstoffenverordening gemeente Waadhoeke 2018, vastgesteld door de gemeenteraad op 2 januari 2018; Besluiten: vast te stellen de navolgende aanwijzingsregeling van de inzameldienst, inzamelplaats en andere inzamelaars voor de inzameling van bepaalde categorieën afvalstoffen en hieraan regels voor het gebruik te verbinden: Artikel 1 Aanwijzing inzameldienst Als inzameldienst belast met de inzameling van huishoudelijke afvalstoffen wordt aangewezen: B.V. Fryslân Miljeu Noordwest onderdeel van N.V. Fryslân Miljeu (opererend onder handelsnaam Omrin) statutair gevestigd te Leeuwarden. Artikel 2 Aanwijzing andere inzamelaars Als inzamelaars belast met de inzameling van bepaalde bestanddelen van huishoudelijke afvalstoffen worden aangewezen: a. Gemeentelijke buitendienst van de gemeente Waadhoeke voor het op afroep separaat inzamelen van grof huishoudelijk afval en grof tuinafval; b. -

Websitebijenpact Gemeente Waadhoekedef
BIJENPACT Gemeente Waadhoeke 1. Bermbeheer De 1200 kilometer bermen van de gemeente willen we zo veel mogelijk maaien en afvoeren in plaats van twee keer per jaar klepelen. 2. Dorpsbosjes Veel dorpsgroen/bosjes kunnen biodiverser worden ingericht en beheerd. Bijvoorbeeld met jaarrond bloeiende inheemse planten en gefaseerde snoei. 3. Grote aaneengesloten stedelijke groengebieden De grote aaneengesloten stedelijke groengebieden worden op dit moment nog intensief beheerd. Mede voor het ‘nette’ straatbeeld. Hier willen we een extensiever beheer toepassen. Om dergelijke gebieden visueel plezierig te maken denken we wel aan het inzaaien van inheemse, jaarrond bloeiende bloemenmengsels. 4. Stedelijk water en oevers Ons stedelijk water en de bijbehorende oevers worden momenteel intensief beheerd. Ook deze intensieve beheermethode willen we aanpassen. Zo willen we bijvoorbeeld per keer de helft van de sloten baggeren in plaats van hele sloten. We denken ook aan het veranderen van hellingshoeken van oevers om de groei van meer verschillende vegetatie mogelijk te maken. Waar mogelijk optimaliseren we de oevers om nestgelegenheid voor bijen* te verbeteren. 5. Communicatie We willen de burgers het belang van biodiversiteit leren. Hiermee willen we bijvoorbeeld het belang van een minder ‘net’ straatbeeld legitimeren (zie punt 4). Daarnaast willen we vertellen wat we doen en waarom we doen wat we doen. We denken aan de inzet van nieuwsbrieven, communicatie op social media, informatie op onze website etc. 1 6. Burgers activeren We willen burgers handvatten geven om zelf aan de slag te gaan. Bijvoorbeeld met biodiversiteit verhogende tips and tricks voor het eigen erf - hierbij willen we gebruik maken van bestaande campagnes en beschikbare informatie. -

Your Paper's Title Starts Here
2020 International Conference on Economic Development and Education Innovation (EDEI 2020) An Analysis on the Evolutionary Path of Scattered Clusters of Commercial Space around Sea Ports Xiaoliang Xiong, Wan Shao, Huxiao Li Wuhan Technology And Business University, Wuhan, Hubei China [email protected] Keywords: Sea Ports, Commerce and Trade, Clusters, Evolution. Abstract: The scattered villages and town communities around sea ports are the window of modern Chinese economic changes, and the changes in the economic spatial structure of the country’s economic development reflect the spatial pattern of the country’s economic development, -promoting the channel optimization of the rural economy and the optimization of the spatial structure of urban clusters. Based on the evolution trajectory of the economic space of sea ports, this paper studies the characteristics and systems of the evolution of the economic space of tea ports, and analyses the dynamic mechanism of the evolution of the economic space of tea ports, trying to demonstrate the spatial optimization principles of the sea ports and clusters from the system and structure aspects. 1. Introduction Organizations of regional traffic function have a great influence on the formation and development of the town and city. In the ancient era of traffic shortage, clusters often become the first choice for the development of the market city. By virtue of the location advantage as the intersection of the river and sea, the port town has become an important local trade distribution centre with the flow of people and logistics, where all kinds of cultural collision and fusion give birth to the regional economic modernization transformation. -

Monograph Series on Languages and Linguistics 20Th Annual Round Table
Monograph Series on Languages and Linguistics lumber 22, 1969 edited by James E. Alatis 20th Annual Round Table Linguistics and the Teaching of Standard English To Speakers of Other Languages or Dialects Georgetown University School of Languages and Linguistics REPORT OF THE TWENTIETH ANNUAL ROUND TABLE MEETING ON LINGUISTICS AND LANGUAGE STUDIES JAMES E. ALATIS EDITOR GEORGETOWN UNIVERSITY PRESS Washington, D.C. 20007 © Copyright 1970 GEORGETOWN UNIVERSITY PRESS SCHOOL OF LANGUAGES AND LINGUISTICS GEORGETOWN UNIVERSITY Library of Congress Catalog Card Number 58-31607 Lithographed in U.S.A. by EDWARDS BROTHERS, INC. Ann Arbor, Michigan CONTENTS Introduction vii WELCOMING REMARKS Reverend Frank Fadner, S. J. Regent, School of Languages and Linguistics xi Dean Robert Lado Dean, School of Languages and Linguistics xiii FIRST SESSION Theoretical Linguistics and Its Implications for Teaching SESOLD Chairman: Charles W. Kreidler, Georgetown University William Labov The Logic of Nonstandard English 1 Raven I. McDavid, Jr. A Theory of Dialect 45 Rudolph C. Troike Receptive Competence, Productive Competence, and Performance 63 Charles T. Scott Transformational Theory and English as a Second Language/Dialect 75 David W. Reed Linguistics and Literacy 93 FIRST LUNCHEON ADDRESS Harold B. Allen The Basic Ingredient 105 iv / CONTENTS SECOND SESSION Applied Linguistics and the Teaching of SESOLD: Materials, Methods, and Techniques Chairman: David P. Harris, Georgetown University Peter S. Rosenbaum Language Instruction and the Schools 111 Betty W. Robinett Teacher Training for English as a Second Dialect and English as a Second Language: The Same or Different? 121 Eugene J. Briere Testing ESL Skills among American Indian Children 133 Bernard Spolsky Linguistics and Language Pedagogy—Applications or Implications ? 143 THIRD SESSION Sociolinguistics: Sociocultural Factors in Teaching SESOLD Chairman: A. -

Phonology of Kunming Chinese
Phonology of Kunming Chinese Ruolan Li [email protected] University of Rochester 1. Introduction Yunnan is a province in Southern China. Although the province is ethnically and linguistically diverse, the variant from standard Mandarin, Yunnanese, is spoken at many, if not most places. As one of Southwestern Guanhua (lit. court language), it diverged from a common ancestor of Mandarin in early Ming dynasty (14–15th century). When soldiers and government officials were sent from Nanjing to Yunnan, at that time relatively remote and undeveloped, they carried Nanjing Mandarin to the province (Hammarström, Forkel, and Martin, 2017; Zeng, 2018). Over the several hundred years, the Yunnan dialect became mutually unintelligible with modern standard Mandarin (Gui, 1990) and diverse locally in many difference cities and counties. In this project, I will focus on Kunming Chinese, a branch of Yunnanese. Kunming is the capital city of Yunnan province, and Kunming Chinese is used everywhere on the street. The choice of Kunming Chinese, rather than other Yunnanese sub-dialects, is made not because of any prestige reasons, but only because it is more accessible to me. The Kunming dialect has a speaker population of about 650, 000 (Gui, 1990). It is highly analytic, and belongs to the Sino-Tibetan language family. Syntactically, it has some grammatical particles (/gə31/, /gɑ53/, both question particles, and /nə44/, as a possessive particle) that is distinct from standard Mandarin (Gao, 2004). Lexically, Kunming Chinese also has many unique nouns and verbs. It has several different phonological contrast from other branches of Yunnanese, but is overall unified within the dialect. -

Yichang–Wanzhou Railway Project
GOVERNMENT OF THE PEOPLE’S REPUBLIC OF CHINA MINISTRY OF RAILWAYS PRC: Yichang–Wanzhou Railway Project RESETTLEMENT PLAN Jointly prepared by Foreign Capital and Technical Import Center of the Ministry of Railways, Railway Construction Support Office of Yichang City, Railway Construction Support Office of Enshi Prefecture, and Railway Construction Support Office of Wanzhou District 15 August 2003 THIS IS NOT AN ADB BOARD APPROVED DOCUMENT. TABLE OF CONTENTS ABBREVIATION iv I. INTRODUCTION 5 II. SUMMARY OF THE RESETTLEMENT PLAN 5 A. Introduction 5 B. Socioeconomic Analysis 6 C. Resettlement Plan 7 D. Cost Estimates 8 E. Organization, Implementation, and Monitoring 8 III. SCOPE OF LAND ACQUISITION AND RESETTLEMENT 10 A. Scope and Necessity of Land Acquisition 10 B. Alignment Design 12 C. Summary of Key Effects 14 D. Primary Responsibilities for Land Acquisition and Resettlement 19 E. Station Access Roads 20 IV. SOCIOECONOMIC INFORMATION 21 A. Affected People 21 B. Socioeconomic Survey of Affected Villages and Households 22 C. Property Ownership and Compensation Structure 29 D. Likely Impact of Land Acquisition on Affected Persons 31 E. Losses for People Affected by Land Acquisition 33 F. Impact on the Poor, Indigenous People, Ethnic Minorities, and Other Vulnerable Groups 34 G. The Da-Wan Railway Experience 34 V. OBJECTIVES, POLICY FRAMEWORK, AND ENTITLEMENTS 36 A. Purpose and Objectives of Land Acquisition and Resettlement 36 B. Applicable Land Policies, Laws, and Guidelines 36 C. Principles, Legal and Policy Commitments from MOR and Local Government 41 D. Entitlements and Compensation Standards 42 E. Eligibility and Rights of Affected Persons 49 F. Disbursement of Compensation Funds 50 G. -
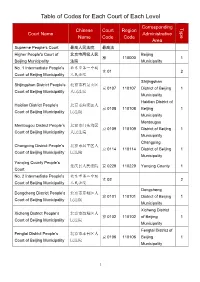
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115