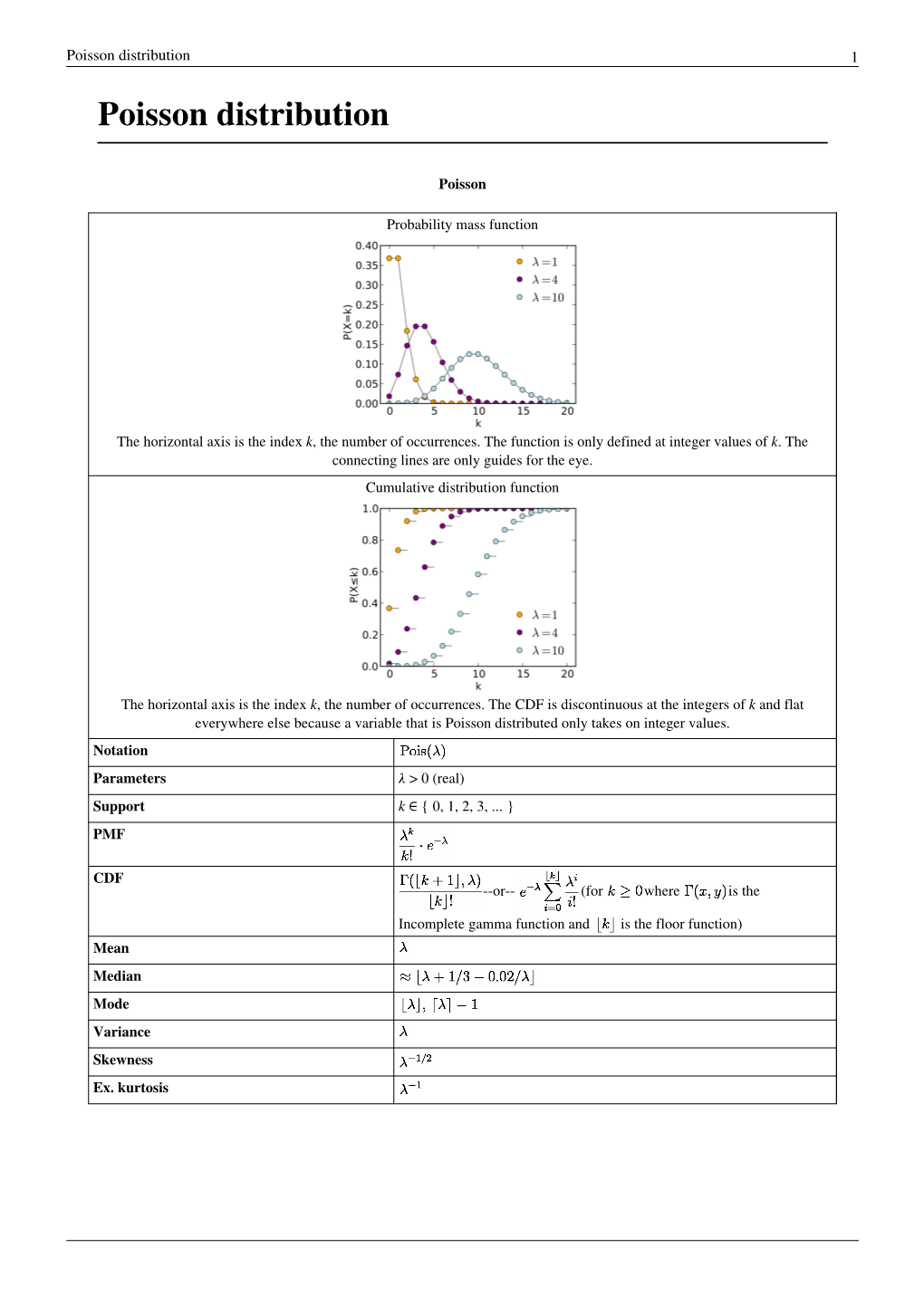
Poisson Distribution 1 Poisson Distribution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![Arxiv:2004.02679V2 [Math.OA] 17 Jul 2020](https://docslib.b-cdn.net/cover/3997/arxiv-2004-02679v2-math-oa-17-jul-2020-33997.webp)
Arxiv:2004.02679V2 [Math.OA] 17 Jul 2020
THE FREE TANGENT LAW WIKTOR EJSMONT AND FRANZ LEHNER Abstract. Nevanlinna-Herglotz functions play a fundamental role for the study of infinitely divisible distributions in free probability [11]. In the present paper we study the role of the tangent function, which is a fundamental Herglotz-Nevanlinna function [28, 23, 54], and related functions in free probability. To be specific, we show that the function tan z 1 ´ x tan z of Carlitz and Scoville [17, (1.6)] describes the limit distribution of sums of free commutators and anticommutators and thus the free cumulants are given by the Euler zigzag numbers. 1. Introduction Nevanlinna or Herglotz functions are functions analytic in the upper half plane having non- negative imaginary part. This class has been thoroughly studied during the last century and has proven very useful in many applications. One of the fundamental examples of Nevanlinna functions is the tangent function, see [6, 28, 23, 54]. On the other hand it was shown by by Bercovici and Voiculescu [11] that Nevanlinna functions characterize freely infinitely divisible distributions. Such distributions naturally appear in free limit theorems and in the present paper we show that the tangent function appears in a limit theorem for weighted sums of free commutators and anticommutators. More precisely, the family of functions tan z 1 x tan z ´ arises, which was studied by Carlitz and Scoville [17, (1.6)] in connection with the combinorics of tangent numbers; in particular we recover the tangent function for x 0. In recent years a number of papers have investigated limit theorems for“ the free convolution of probability measures defined by Voiculescu [58, 59, 56]. -

Generalized Factorial Cumulants Applied to Coulomb-Blockade Systems Signal
Generalized factorial cumulants applied to Coulomb-blockade systems signal time Von der Fakultät für Physik der Universität Duisburg-Essen genehmigte Dissertation zur Erlangung des Grades Dr. rer. nat. von Philipp Stegmann aus Bottrop Tag der Disputation: 05.07.2017 Referent: Prof. Dr. Jürgen König Korreferent: Prof. Dr. Christian Flindt Korreferent: Prof. Dr. Thomas Guhr Summary Tunneling of electrons through a Coulomb-blockade system is a stochastic (i.e., random) process. The number of the transferred electrons per time interval is determined by a prob- ability distribution. The form of this distribution can be characterized by quantities called cumulants. Recently developed electrometers allow for the observation of each electron transported through a Coulomb-blockade system in real time. Therefore, the probability distribution can be directly measured. In this thesis, we introduce generalized factorial cumulants as a new tool to analyze the information contained in the probability distribution. For any kind of Coulomb-blockade system, these cumulants can be used as follows: First, correlations between the tunneling electrons are proven by a certain sign of the cumulants. In the limit of short time intervals, additional criteria indicate correlations, respectively. The cumulants allow for the detection of correlations which cannot be noticed by commonly used quantities such as the current noise. We comment in detail on the necessary ingredients for the presence of correlations in the short-time limit and thereby explain recent experimental observations. Second, we introduce a mathematical procedure called inverse counting statistics. The procedure reconstructs, solely from a few experimentally measured cumulants, character- istic features of an otherwise unknown Coulomb-blockade system, e.g., a lower bound for the system dimension and the full spectrum of relaxation rates. -

Efficient Estimation of Parameters of the Negative Binomial Distribution
E±cient Estimation of Parameters of the Negative Binomial Distribution V. SAVANI AND A. A. ZHIGLJAVSKY Department of Mathematics, Cardi® University, Cardi®, CF24 4AG, U.K. e-mail: SavaniV@cardi®.ac.uk, ZhigljavskyAA@cardi®.ac.uk (Corresponding author) Abstract In this paper we investigate a class of moment based estimators, called power method estimators, which can be almost as e±cient as maximum likelihood estima- tors and achieve a lower asymptotic variance than the standard zero term method and method of moments estimators. We investigate di®erent methods of implementing the power method in practice and examine the robustness and e±ciency of the power method estimators. Key Words: Negative binomial distribution; estimating parameters; maximum likelihood method; e±ciency of estimators; method of moments. 1 1. The Negative Binomial Distribution 1.1. Introduction The negative binomial distribution (NBD) has appeal in the modelling of many practical applications. A large amount of literature exists, for example, on using the NBD to model: animal populations (see e.g. Anscombe (1949), Kendall (1948a)); accident proneness (see e.g. Greenwood and Yule (1920), Arbous and Kerrich (1951)) and consumer buying behaviour (see e.g. Ehrenberg (1988)). The appeal of the NBD lies in the fact that it is a simple two parameter distribution that arises in various di®erent ways (see e.g. Anscombe (1950), Johnson, Kotz, and Kemp (1992), Chapter 5) often allowing the parameters to have a natural interpretation (see Section 1.2). Furthermore, the NBD can be implemented as a distribution within stationary processes (see e.g. Anscombe (1950), Kendall (1948b)) thereby increasing the modelling potential of the distribution. -

Use of Statistical Tables
TUTORIAL | SCOPE USE OF STATISTICAL TABLES Lucy Radford, Jenny V Freeman and Stephen J Walters introduce three important statistical distributions: the standard Normal, t and Chi-squared distributions PREVIOUS TUTORIALS HAVE LOOKED at hypothesis testing1 and basic statistical tests.2–4 As part of the process of statistical hypothesis testing, a test statistic is calculated and compared to a hypothesised critical value and this is used to obtain a P- value. This P-value is then used to decide whether the study results are statistically significant or not. It will explain how statistical tables are used to link test statistics to P-values. This tutorial introduces tables for three important statistical distributions (the TABLE 1. Extract from two-tailed standard Normal, t and Chi-squared standard Normal table. Values distributions) and explains how to use tabulated are P-values corresponding them with the help of some simple to particular cut-offs and are for z examples. values calculated to two decimal places. STANDARD NORMAL DISTRIBUTION TABLE 1 The Normal distribution is widely used in statistics and has been discussed in z 0.00 0.01 0.02 0.03 0.050.04 0.05 0.06 0.07 0.08 0.09 detail previously.5 As the mean of a Normally distributed variable can take 0.00 1.0000 0.9920 0.9840 0.9761 0.9681 0.9601 0.9522 0.9442 0.9362 0.9283 any value (−∞ to ∞) and the standard 0.10 0.9203 0.9124 0.9045 0.8966 0.8887 0.8808 0.8729 0.8650 0.8572 0.8493 deviation any positive value (0 to ∞), 0.20 0.8415 0.8337 0.8259 0.8181 0.8103 0.8206 0.7949 0.7872 0.7795 0.7718 there are an infinite number of possible 0.30 0.7642 0.7566 0.7490 0.7414 0.7339 0.7263 0.7188 0.7114 0.7039 0.6965 Normal distributions. -

Effect of Probability Distribution of the Response Variable in Optimal Experimental Design with Applications in Medicine †
mathematics Article Effect of Probability Distribution of the Response Variable in Optimal Experimental Design with Applications in Medicine † Sergio Pozuelo-Campos *,‡ , Víctor Casero-Alonso ‡ and Mariano Amo-Salas ‡ Department of Mathematics, University of Castilla-La Mancha, 13071 Ciudad Real, Spain; [email protected] (V.C.-A.); [email protected] (M.A.-S.) * Correspondence: [email protected] † This paper is an extended version of a published conference paper as a part of the proceedings of the 35th International Workshop on Statistical Modeling (IWSM), Bilbao, Spain, 19–24 July 2020. ‡ These authors contributed equally to this work. Abstract: In optimal experimental design theory it is usually assumed that the response variable follows a normal distribution with constant variance. However, some works assume other probability distributions based on additional information or practitioner’s prior experience. The main goal of this paper is to study the effect, in terms of efficiency, when misspecification in the probability distribution of the response variable occurs. The elemental information matrix, which includes information on the probability distribution of the response variable, provides a generalized Fisher information matrix. This study is performed from a practical perspective, comparing a normal distribution with the Poisson or gamma distribution. First, analytical results are obtained, including results for the linear quadratic model, and these are applied to some real illustrative examples. The nonlinear 4-parameter Hill model is next considered to study the influence of misspecification in a Citation: Pozuelo-Campos, S.; dose-response model. This analysis shows the behavior of the efficiency of the designs obtained in Casero-Alonso, V.; Amo-Salas, M. -

Lecture.7 Poisson Distributions - Properties, Normal Distributions- Properties
Lecture.7 Poisson Distributions - properties, Normal Distributions- properties Theoretical Distributions Theoretical distributions are 1. Binomial distribution Discrete distribution 2. Poisson distribution 3. Normal distribution Continuous distribution Discrete Probability distribution Bernoulli distribution A random variable x takes two values 0 and 1, with probabilities q and p ie., p(x=1) = p and p(x=0)=q, q-1-p is called a Bernoulli variate and is said to be Bernoulli distribution where p and q are probability of success and failure. It was given by Swiss mathematician James Bernoulli (1654-1705) Example • Tossing a coin(head or tail) • Germination of seed(germinate or not) Binomial distribution Binomial distribution was discovered by James Bernoulli (1654-1705). Let a random experiment be performed repeatedly and the occurrence of an event in a trial be called as success and its non-occurrence is failure. Consider a set of n independent trails (n being finite), in which the probability p of success in any trail is constant for each trial. Then q=1-p is the probability of failure in any trail. 1 The probability of x success and consequently n-x failures in n independent trails. But x successes in n trails can occur in ncx ways. Probability for each of these ways is pxqn-x. P(sss…ff…fsf…f)=p(s)p(s)….p(f)p(f)…. = p,p…q,q… = (p,p…p)(q,q…q) (x times) (n-x times) Hence the probability of x success in n trials is given by x n-x ncx p q Definition A random variable x is said to follow binomial distribution if it assumes non- negative values and its probability mass function is given by P(X=x) =p(x) = x n-x ncx p q , x=0,1,2…n q=1-p 0, otherwise The two independent constants n and p in the distribution are known as the parameters of the distribution. -

1 One Parameter Exponential Families
1 One parameter exponential families The world of exponential families bridges the gap between the Gaussian family and general dis- tributions. Many properties of Gaussians carry through to exponential families in a fairly precise sense. • In the Gaussian world, there exact small sample distributional results (i.e. t, F , χ2). • In the exponential family world, there are approximate distributional results (i.e. deviance tests). • In the general setting, we can only appeal to asymptotics. A one-parameter exponential family, F is a one-parameter family of distributions of the form Pη(dx) = exp (η · t(x) − Λ(η)) P0(dx) for some probability measure P0. The parameter η is called the natural or canonical parameter and the function Λ is called the cumulant generating function, and is simply the normalization needed to make dPη fη(x) = (x) = exp (η · t(x) − Λ(η)) dP0 a proper probability density. The random variable t(X) is the sufficient statistic of the exponential family. Note that P0 does not have to be a distribution on R, but these are of course the simplest examples. 1.0.1 A first example: Gaussian with linear sufficient statistic Consider the standard normal distribution Z e−z2=2 P0(A) = p dz A 2π and let t(x) = x. Then, the exponential family is eη·x−x2=2 Pη(dx) / p 2π and we see that Λ(η) = η2=2: eta= np.linspace(-2,2,101) CGF= eta**2/2. plt.plot(eta, CGF) A= plt.gca() A.set_xlabel(r'$\eta$', size=20) A.set_ylabel(r'$\Lambda(\eta)$', size=20) f= plt.gcf() 1 Thus, the exponential family in this setting is the collection F = fN(η; 1) : η 2 Rg : d 1.0.2 Normal with quadratic sufficient statistic on R d As a second example, take P0 = N(0;Id×d), i.e. -

Computer Routines for Probability Distributions, Random Numbers, and Related Functions
COMPUTER ROUTINES FOR PROBABILITY DISTRIBUTIONS, RANDOM NUMBERS, AND RELATED FUNCTIONS By W.H. Kirby Water-Resources Investigations Report 83 4257 (Revision of Open-File Report 80 448) 1983 UNITED STATES DEPARTMENT OF THE INTERIOR WILLIAM P. CLARK, Secretary GEOLOGICAL SURVEY Dallas L. Peck, Director For additional information Copies of this report can write to: be purchased from: Chief, Surface Water Branch Open-File Services Section U.S. Geological Survey, WRD Western Distribution Branch 415 National Center Box 25425, Federal Center Reston, Virginia 22092 Denver, Colorado 80225 (Telephone: (303) 234-5888) CONTENTS Introduction............................................................ 1 Source code availability................................................ 2 Linkage information..................................................... 2 Calling instructions.................................................... 3 BESFIO - Bessel function IQ......................................... 3 BETA? - Beta probabilities......................................... 3 CHISQP - Chi-square probabilities................................... 4 CHISQX - Chi-square quantiles....................................... 4 DATME - Date and time for printing................................. 4 DGAMMA - Gamma function, double precision........................... 4 DLGAMA - Log-gamma function, double precision....................... 4 ERF - Error function............................................. 4 EXPIF - Exponential integral....................................... 4 GAMMA -

The Q-Factorial Moments of Discrete Q-Distributions and a Characterization of the Euler Distribution
3 The q-Factorial Moments of Discrete q-Distributions and a Characterization of the Euler Distribution Ch. A. Charalambides and N. Papadatos Department of Mathematics, University of Athens, Athens, Greece ABSTRACT The classical discrete distributions binomial, geometric and negative binomial are defined on the stochastic model of a sequence of indepen- dent and identical Bernoulli trials. The Poisson distribution may be defined as an approximation of the binomial (or negative binomial) distribution. The cor- responding q-distributions are defined on the more general stochastic model of a sequence of Bernoulli trials with probability of success at any trial depending on the number of trials. In this paper targeting to the problem of calculating the moments of q-distributions, we introduce and study q-factorial moments, the calculation of which is as ease as the calculation of the factorial moments of the classical distributions. The usual factorial moments are connected with the q-factorial moments through the q-Stirling numbers of the first kind. Several ex- amples, illustrating the method, are presented. Further, the Euler distribution is characterized through its q-factorial moments. Keywords and phrases: q-distributions, q-moments, q-Stirling numbers 3.1 INTRODUCTION Consider a sequence of independent Bernoulli trials with probability of success at the ith trial pi, i =1, 2,.... The study of the distribution of the number Xn of successes up to the nth trial, as well as the closely related to it distribution of the number Yk of trials until the occurrence of the kth success, have attracted i−1 i−1 special attention. -

Univariate and Multivariate Skewness and Kurtosis 1
Running head: UNIVARIATE AND MULTIVARIATE SKEWNESS AND KURTOSIS 1 Univariate and Multivariate Skewness and Kurtosis for Measuring Nonnormality: Prevalence, Influence and Estimation Meghan K. Cain, Zhiyong Zhang, and Ke-Hai Yuan University of Notre Dame Author Note This research is supported by a grant from the U.S. Department of Education (R305D140037). However, the contents of the paper do not necessarily represent the policy of the Department of Education, and you should not assume endorsement by the Federal Government. Correspondence concerning this article can be addressed to Meghan Cain ([email protected]), Ke-Hai Yuan ([email protected]), or Zhiyong Zhang ([email protected]), Department of Psychology, University of Notre Dame, 118 Haggar Hall, Notre Dame, IN 46556. UNIVARIATE AND MULTIVARIATE SKEWNESS AND KURTOSIS 2 Abstract Nonnormality of univariate data has been extensively examined previously (Blanca et al., 2013; Micceri, 1989). However, less is known of the potential nonnormality of multivariate data although multivariate analysis is commonly used in psychological and educational research. Using univariate and multivariate skewness and kurtosis as measures of nonnormality, this study examined 1,567 univariate distriubtions and 254 multivariate distributions collected from authors of articles published in Psychological Science and the American Education Research Journal. We found that 74% of univariate distributions and 68% multivariate distributions deviated from normal distributions. In a simulation study using typical values of skewness and kurtosis that we collected, we found that the resulting type I error rates were 17% in a t-test and 30% in a factor analysis under some conditions. Hence, we argue that it is time to routinely report skewness and kurtosis along with other summary statistics such as means and variances. -

Functions of Random Variables
Names for Eg(X ) Generating Functions Topic 8 The Expected Value Functions of Random Variables 1 / 19 Names for Eg(X ) Generating Functions Outline Names for Eg(X ) Means Moments Factorial Moments Variance and Standard Deviation Generating Functions 2 / 19 Names for Eg(X ) Generating Functions Means If g(x) = x, then µX = EX is called variously the distributional mean, and the first moment. • Sn, the number of successes in n Bernoulli trials with success parameter p, has mean np. • The mean of a geometric random variable with parameter p is (1 − p)=p . • The mean of an exponential random variable with parameter β is1 /β. • A standard normal random variable has mean0. Exercise. Find the mean of a Pareto random variable. Z 1 Z 1 βαβ Z 1 αββ 1 αβ xf (x) dx = x dx = βαβ x−β dx = x1−β = ; β > 1 x β+1 −∞ α x α 1 − β α β − 1 3 / 19 Names for Eg(X ) Generating Functions Moments In analogy to a similar concept in physics, EX m is called the m-th moment. The second moment in physics is associated to the moment of inertia. • If X is a Bernoulli random variable, then X = X m. Thus, EX m = EX = p. • For a uniform random variable on [0; 1], the m-th moment is R 1 m 0 x dx = 1=(m + 1). • The third moment for Z, a standard normal random, is0. The fourth moment, 1 Z 1 z2 1 z2 1 4 4 3 EZ = p z exp − dz = −p z exp − 2π −∞ 2 2π 2 −∞ 1 Z 1 z2 +p 3z2 exp − dz = 3EZ 2 = 3 2π −∞ 2 3 z2 u(z) = z v(t) = − exp − 2 0 2 0 z2 u (z) = 3z v (t) = z exp − 2 4 / 19 Names for Eg(X ) Generating Functions Factorial Moments If g(x) = (x)k , where( x)k = x(x − 1) ··· (x − k + 1), then E(X )k is called the k-th factorial moment. -

A Guide on Probability Distributions
powered project A guide on probability distributions R-forge distributions Core Team University Year 2008-2009 LATEXpowered Mac OS' TeXShop edited Contents Introduction 4 I Discrete distributions 6 1 Classic discrete distribution 7 2 Not so-common discrete distribution 27 II Continuous distributions 34 3 Finite support distribution 35 4 The Gaussian family 47 5 Exponential distribution and its extensions 56 6 Chi-squared's ditribution and related extensions 75 7 Student and related distributions 84 8 Pareto family 88 9 Logistic ditribution and related extensions 108 10 Extrem Value Theory distributions 111 3 4 CONTENTS III Multivariate and generalized distributions 116 11 Generalization of common distributions 117 12 Multivariate distributions 132 13 Misc 134 Conclusion 135 Bibliography 135 A Mathematical tools 138 Introduction This guide is intended to provide a quite exhaustive (at least as I can) view on probability distri- butions. It is constructed in chapters of distribution family with a section for each distribution. Each section focuses on the tryptic: definition - estimation - application. Ultimate bibles for probability distributions are Wimmer & Altmann (1999) which lists 750 univariate discrete distributions and Johnson et al. (1994) which details continuous distributions. In the appendix, we recall the basics of probability distributions as well as \common" mathe- matical functions, cf. section A.2. And for all distribution, we use the following notations • X a random variable following a given distribution, • x a realization of this random variable, • f the density function (if it exists), • F the (cumulative) distribution function, • P (X = k) the mass probability function in k, • M the moment generating function (if it exists), • G the probability generating function (if it exists), • φ the characteristic function (if it exists), Finally all graphics are done the open source statistical software R and its numerous packages available on the Comprehensive R Archive Network (CRAN∗).