ONE SAMPLE TESTS the Following Data Represent the Change
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Effect of Probability Distribution of the Response Variable in Optimal Experimental Design with Applications in Medicine †
mathematics Article Effect of Probability Distribution of the Response Variable in Optimal Experimental Design with Applications in Medicine † Sergio Pozuelo-Campos *,‡ , Víctor Casero-Alonso ‡ and Mariano Amo-Salas ‡ Department of Mathematics, University of Castilla-La Mancha, 13071 Ciudad Real, Spain; [email protected] (V.C.-A.); [email protected] (M.A.-S.) * Correspondence: [email protected] † This paper is an extended version of a published conference paper as a part of the proceedings of the 35th International Workshop on Statistical Modeling (IWSM), Bilbao, Spain, 19–24 July 2020. ‡ These authors contributed equally to this work. Abstract: In optimal experimental design theory it is usually assumed that the response variable follows a normal distribution with constant variance. However, some works assume other probability distributions based on additional information or practitioner’s prior experience. The main goal of this paper is to study the effect, in terms of efficiency, when misspecification in the probability distribution of the response variable occurs. The elemental information matrix, which includes information on the probability distribution of the response variable, provides a generalized Fisher information matrix. This study is performed from a practical perspective, comparing a normal distribution with the Poisson or gamma distribution. First, analytical results are obtained, including results for the linear quadratic model, and these are applied to some real illustrative examples. The nonlinear 4-parameter Hill model is next considered to study the influence of misspecification in a Citation: Pozuelo-Campos, S.; dose-response model. This analysis shows the behavior of the efficiency of the designs obtained in Casero-Alonso, V.; Amo-Salas, M. -

Lecture.7 Poisson Distributions - Properties, Normal Distributions- Properties
Lecture.7 Poisson Distributions - properties, Normal Distributions- properties Theoretical Distributions Theoretical distributions are 1. Binomial distribution Discrete distribution 2. Poisson distribution 3. Normal distribution Continuous distribution Discrete Probability distribution Bernoulli distribution A random variable x takes two values 0 and 1, with probabilities q and p ie., p(x=1) = p and p(x=0)=q, q-1-p is called a Bernoulli variate and is said to be Bernoulli distribution where p and q are probability of success and failure. It was given by Swiss mathematician James Bernoulli (1654-1705) Example • Tossing a coin(head or tail) • Germination of seed(germinate or not) Binomial distribution Binomial distribution was discovered by James Bernoulli (1654-1705). Let a random experiment be performed repeatedly and the occurrence of an event in a trial be called as success and its non-occurrence is failure. Consider a set of n independent trails (n being finite), in which the probability p of success in any trail is constant for each trial. Then q=1-p is the probability of failure in any trail. 1 The probability of x success and consequently n-x failures in n independent trails. But x successes in n trails can occur in ncx ways. Probability for each of these ways is pxqn-x. P(sss…ff…fsf…f)=p(s)p(s)….p(f)p(f)…. = p,p…q,q… = (p,p…p)(q,q…q) (x times) (n-x times) Hence the probability of x success in n trials is given by x n-x ncx p q Definition A random variable x is said to follow binomial distribution if it assumes non- negative values and its probability mass function is given by P(X=x) =p(x) = x n-x ncx p q , x=0,1,2…n q=1-p 0, otherwise The two independent constants n and p in the distribution are known as the parameters of the distribution. -

1 One Parameter Exponential Families
1 One parameter exponential families The world of exponential families bridges the gap between the Gaussian family and general dis- tributions. Many properties of Gaussians carry through to exponential families in a fairly precise sense. • In the Gaussian world, there exact small sample distributional results (i.e. t, F , χ2). • In the exponential family world, there are approximate distributional results (i.e. deviance tests). • In the general setting, we can only appeal to asymptotics. A one-parameter exponential family, F is a one-parameter family of distributions of the form Pη(dx) = exp (η · t(x) − Λ(η)) P0(dx) for some probability measure P0. The parameter η is called the natural or canonical parameter and the function Λ is called the cumulant generating function, and is simply the normalization needed to make dPη fη(x) = (x) = exp (η · t(x) − Λ(η)) dP0 a proper probability density. The random variable t(X) is the sufficient statistic of the exponential family. Note that P0 does not have to be a distribution on R, but these are of course the simplest examples. 1.0.1 A first example: Gaussian with linear sufficient statistic Consider the standard normal distribution Z e−z2=2 P0(A) = p dz A 2π and let t(x) = x. Then, the exponential family is eη·x−x2=2 Pη(dx) / p 2π and we see that Λ(η) = η2=2: eta= np.linspace(-2,2,101) CGF= eta**2/2. plt.plot(eta, CGF) A= plt.gca() A.set_xlabel(r'$\eta$', size=20) A.set_ylabel(r'$\Lambda(\eta)$', size=20) f= plt.gcf() 1 Thus, the exponential family in this setting is the collection F = fN(η; 1) : η 2 Rg : d 1.0.2 Normal with quadratic sufficient statistic on R d As a second example, take P0 = N(0;Id×d), i.e. -

Poisson Versus Negative Binomial Regression
Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Poisson versus Negative Binomial Regression Randall Reese Utah State University [email protected] February 29, 2016 Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Overview 1 Handling Count Data ADEM Overdispersion 2 The Negative Binomial Distribution Foundations of Negative Binomial Distribution Basic Properties of the Negative Binomial Distribution Fitting the Negative Binomial Model 3 Other Applications and Analysis in R 4 References Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Data whose values come from Z≥0, the non-negative integers. Classic example is deaths in the Prussian army per year by horse kick (Bortkiewicz) Example 2 of Notes 5. (Number of successful \attempts"). Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Poisson Distribution Support is the non-negative integers. (Count data). Described by a single parameter λ > 0. When Y ∼ Poisson(λ), then E(Y ) = Var(Y ) = λ Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Acute Disseminated Encephalomyelitis Acute Disseminated Encephalomyelitis (ADEM) is a neurological, immune disorder in which widespread inflammation of the brain and spinal cord damages tissue known as white matter. -

6.1 Definition: the Density Function of Th
CHAPTER 6: Some Continuous Probability Distributions Continuous Uniform Distribution: 6.1 Definition: The density function of the continuous random variable X on the interval [A; B] is 1 A x B B A ≤ ≤ f(x; A; B) = 8 − < 0 otherwise: : Application: Some continuous random variables in the physical, management, and biological sciences have approximately uniform probability distributions. For example, suppose we are counting events that have a Poisson distribution, such as telephone calls coming into a switchboard. If it is known that exactly one such event has occurred in a given interval, say (0; t),then the actual time of occurrence is distributed uniformly over this interval. Example: Arrivals of customers at a certain checkout counter follow a Poisson distribution. It is known that, during a given 30-minute period, one customer arrived at the counter. Find the probability that the customer arrived during the last 5 minutes of the 30-minute period. Solution: As just mentioned, the actual time of arrival follows a uniform distribution over the interval of (0; 30). If X denotes the arrival time, then 30 1 30 25 1 P (25 X 30) = dx = − = ≤ ≤ Z25 30 30 6 Theorem 6.1: The mean and variance of the uniform distribution are 2 B 2 2 B 1 x B A A+B µ = A x B A = 2(B A) = 2(B− A) = 2 : R − h − iA − It is easy to show that (B A)2 σ2 = − 12 Normal Distribution: 6.2 Definition: The density function of the normal random variable X, with mean µ and variance σ2, is 2 1 (1=2)[(x µ)/σ] n(x; µ, σ) = e− − < x < ; p2πσ − 1 1 where π = 3:14159 : : : and e = 2:71828 : : : Example: The SAT aptitude examinations in English and Mathematics were originally designed so that scores would be approximately normal with µ = 500 and σ = 100. -

Statistical Inference
GU4204: Statistical Inference Bodhisattva Sen Columbia University February 27, 2020 Contents 1 Introduction5 1.1 Statistical Inference: Motivation.....................5 1.2 Recap: Some results from probability..................5 1.3 Back to Example 1.1...........................8 1.4 Delta method...............................8 1.5 Back to Example 1.1........................... 10 2 Statistical Inference: Estimation 11 2.1 Statistical model............................. 11 2.2 Method of Moments estimators..................... 13 3 Method of Maximum Likelihood 16 3.1 Properties of MLEs............................ 20 3.1.1 Invariance............................. 20 3.1.2 Consistency............................ 21 3.2 Computational methods for approximating MLEs........... 21 3.2.1 Newton's Method......................... 21 3.2.2 The EM Algorithm........................ 22 1 4 Principles of estimation 23 4.1 Mean squared error............................ 24 4.2 Comparing estimators.......................... 25 4.3 Unbiased estimators........................... 26 4.4 Sufficient Statistics............................ 28 5 Bayesian paradigm 33 5.1 Prior distribution............................. 33 5.2 Posterior distribution........................... 34 5.3 Bayes Estimators............................. 36 5.4 Sampling from a normal distribution.................. 37 6 The sampling distribution of a statistic 39 6.1 The gamma and the χ2 distributions.................. 39 6.1.1 The gamma distribution..................... 39 6.1.2 The Chi-squared distribution.................. 41 6.2 Sampling from a normal population................... 42 6.3 The t-distribution............................. 45 7 Confidence intervals 46 8 The (Cramer-Rao) Information Inequality 51 9 Large Sample Properties of the MLE 57 10 Hypothesis Testing 61 10.1 Principles of Hypothesis Testing..................... 61 10.2 Critical regions and test statistics.................... 62 10.3 Power function and types of error.................... 64 10.4 Significance level............................ -

Likelihood-Based Inference
The score statistic Inference Exponential distribution example Likelihood-based inference Patrick Breheny September 29 Patrick Breheny Survival Data Analysis (BIOS 7210) 1/32 The score statistic Univariate Inference Multivariate Exponential distribution example Introduction In previous lectures, we constructed and plotted likelihoods and used them informally to comment on likely values of parameters Our goal for today is to make this more rigorous, in terms of quantifying coverage and type I error rates for various likelihood-based approaches to inference With the exception of extremely simple cases such as the two-sample exponential model, exact derivation of these quantities is typically unattainable for survival models, and we must rely on asymptotic likelihood arguments Patrick Breheny Survival Data Analysis (BIOS 7210) 2/32 The score statistic Univariate Inference Multivariate Exponential distribution example The score statistic Likelihoods are typically easier to work with on the log scale (where products become sums); furthermore, since it is only relative comparisons that matter with likelihoods, it is more meaningful to work with derivatives than the likelihood itself Thus, we often work with the derivative of the log-likelihood, which is known as the score, and often denoted U: d U (θ) = `(θjX) X dθ Note that U is a random variable, as it depends on X U is a function of θ For independent observations, the score of the entire sample is the sum of the scores for the individual observations: X U = Ui i Patrick Breheny Survival -

(Introduction to Probability at an Advanced Level) - All Lecture Notes
Fall 2018 Statistics 201A (Introduction to Probability at an advanced level) - All Lecture Notes Aditya Guntuboyina August 15, 2020 Contents 0.1 Sample spaces, Events, Probability.................................5 0.2 Conditional Probability and Independence.............................6 0.3 Random Variables..........................................7 1 Random Variables, Expectation and Variance8 1.1 Expectations of Random Variables.................................9 1.2 Variance................................................ 10 2 Independence of Random Variables 11 3 Common Distributions 11 3.1 Ber(p) Distribution......................................... 11 3.2 Bin(n; p) Distribution........................................ 11 3.3 Poisson Distribution......................................... 12 4 Covariance, Correlation and Regression 14 5 Correlation and Regression 16 6 Back to Common Distributions 16 6.1 Geometric Distribution........................................ 16 6.2 Negative Binomial Distribution................................... 17 7 Continuous Distributions 17 7.1 Normal or Gaussian Distribution.................................. 17 1 7.2 Uniform Distribution......................................... 18 7.3 The Exponential Density...................................... 18 7.4 The Gamma Density......................................... 18 8 Variable Transformations 19 9 Distribution Functions and the Quantile Transform 20 10 Joint Densities 22 11 Joint Densities under Transformations 23 11.1 Detour to Convolutions...................................... -

Compound Zero-Truncated Poisson Normal Distribution and Its Applications
Compound Zero-Truncated Poisson Normal Distribution and its Applications a,b, c d Mohammad Z. Raqab ∗, Debasis Kundu , Fahimah A. Al-Awadhi aDepartment of Mathematics, The University of Jordan, Amman 11942, JORDAN bKing Abdulaziz University, Jeddah, SAUDI ARABIA cDepartment of Mathematics and Statistics, Indian Institute of Technology Kanpur, Kanpur, Pin 208016, INDIA dDepartment of Statistics and OR, Kuwait University, Safat 13060, KUWAIT Abstract Here, we first propose three-parameter model and call it as the compound zero- truncated Poisson normal (ZTP-N) distribution. The model is based on the random sum of N independent Gaussian random variables, where N is a zero truncated Pois- son random variable. The proposed ZTP-N distribution is a very flexible probability distribution function. The probability density function can take variety of shapes. It can be both positively and negatively skewed, moreover, normal distribution can be obtained as a special case. It can be unimodal, bimodal as well as multimodal also. It has three parameters. An efficient EM type algorithm has been proposed to compute the maximum likelihood estimators of the unknown parameters. We further propose a four-parameter bivariate distribution with continuous and discrete marginals, and discuss estimation of unknown parameters based on the proposed EM type algorithm. Some simulation experiments have been performed to see the effectiveness of the pro- posed EM type algorithm, and one real data set has been analyzed for illustrative purposes. Keywords: Poisson distribution; skew normal distribution; maximum likelihood estimators; EM type algorithm; Fisher information matrix. AMS Subject Classification (2010): 62E15; 62F10; 62H10. ∗Corresponding author. E-mail addresses: [email protected] (M. -

1 IEOR 6711: Notes on the Poisson Process
Copyright c 2009 by Karl Sigman 1 IEOR 6711: Notes on the Poisson Process We present here the essentials of the Poisson point process with its many interesting properties. As preliminaries, we first define what a point process is, define the renewal point process and state and prove the Elementary Renewal Theorem. 1.1 Point Processes Definition 1.1 A simple point process = ftn : n ≥ 1g is a sequence of strictly increas- ing points 0 < t1 < t2 < ··· ; (1) def with tn−!1 as n−!1. With N(0) = 0 we let N(t) denote the number of points that fall in the interval (0; t]; N(t) = maxfn : tn ≤ tg. fN(t): t ≥ 0g is called the counting process for . If the tn are random variables then is called a random point process. def We sometimes allow a point t0 at the origin and define t0 = 0. Xn = tn − tn−1; n ≥ 1, is called the nth interarrival time. th We view t as time and view tn as the n arrival time (although there are other kinds of applications in which the points tn denote locations in space as opposed to time). The word simple refers to the fact that we are not allowing more than one arrival to ocurr at the same time (as is stated precisely in (1)). In many applications there is a \system" to which customers are arriving over time (classroom, bank, hospital, supermarket, airport, etc.), and ftng denotes the arrival times of these customers to the system. But ftng could also represent the times at which phone calls are received by a given phone, the times at which jobs are sent to a printer in a computer network, the times at which a claim is made against an insurance company, the times at which one receives or sends email, the times at which one sells or buys stock, the times at which a given web site receives hits, or the times at which subways arrive to a station. -

Poisson Approximations
Page 1 Chapter 8 Poisson approximations The Bin(n, p) can be thought of as the distribution of a sum of independent indicator random variables X1 + ...+ Xn, with {Xi = 1} denoting a head on the ith toss of a coin. The normal approximation to the Binomial works best√ when the variance np(1 p) is large, for then each of the standardized summands (Xi p)/ np(1 p) makes a relatively small contribution to the standardized sum. When n is large but p is small, in such a way that np is not large, a different type of approximation to the Binomial is better. < > Poisson distribution 8.1 Definition. A random variable Y is said to have a with parame- Poisson distribution ter , abbreviated to Poisson(), if it can take values 0, 1, 2,... with probabilities ek P{Y = k}= for k = 0, 1, 2,... k! The parameter must be positive. The Poisson() appears as an approximation to the Bin(n, p) when n is large, p is small, and = np: n n(n 1)...(nk+1) k n k pk(1 p)nk = 1 k k! n n k n 1 if k small relative to n k! n k e if n is large k! The exponential factor comes from: n 1 2 log 1 = n log 1 = n ... if /n 0. n n n 2 n2 By careful consideration of the error terms, one can give explicit bounds for the er- ror of approximation. For example, there exists a constant C, such that, if X is distributed Bin(n, p) and Y is distributed Poisson(np) then X∞ |P{X = k}P{Y =k}| Cp k=0 Le Cam1 has sketched a proof showing that C can be taken equal to 4. -
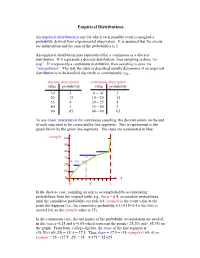
Discrete Distributions: Empirical, Bernoulli, Binomial, Poisson
Empirical Distributions An empirical distribution is one for which each possible event is assigned a probability derived from experimental observation. It is assumed that the events are independent and the sum of the probabilities is 1. An empirical distribution may represent either a continuous or a discrete distribution. If it represents a discrete distribution, then sampling is done “on step”. If it represents a continuous distribution, then sampling is done via “interpolation”. The way the table is described usually determines if an empirical distribution is to be handled discretely or continuously; e.g., discrete description continuous description value probability value probability 10 .1 0 – 10- .1 20 .15 10 – 20- .15 35 .4 20 – 35- .4 40 .3 35 – 40- .3 60 .05 40 – 60- .05 To use linear interpolation for continuous sampling, the discrete points on the end of each step need to be connected by line segments. This is represented in the graph below by the green line segments. The steps are represented in blue: rsample 60 50 40 30 20 10 0 x 0 .5 1 In the discrete case, sampling on step is accomplished by accumulating probabilities from the original table; e.g., for x = 0.4, accumulate probabilities until the cumulative probability exceeds 0.4; rsample is the event value at the point this happens (i.e., the cumulative probability 0.1+0.15+0.4 is the first to exceed 0.4, so the rsample value is 35). In the continuous case, the end points of the probability accumulation are needed, in this case x=0.25 and x=0.65 which represent the points (.25,20) and (.65,35) on the graph.